之前工作项目上也处理过几次慢SQL的问题,但都只停留在了处理的层面,将问题解决后就没后续了。最终应该有所沉淀,也有助于后续回顾。
项目背景
最近到了一个新环境,参与到项目后开始熟悉项目的业务,代码模块,数据库表设计等。
一天早上,项目组长在群里发了一份慢日志文件说谁有空处理下。在其他小伙伴们都有迭代任务的情况,我作为新人就主动的把问题给接了下来。
分析步骤
首先,根据文件信息确定这份文件是属于哪个服务对应的数据库,在借助工具连接上数据库服务,开始对slowlog文件进行分析。
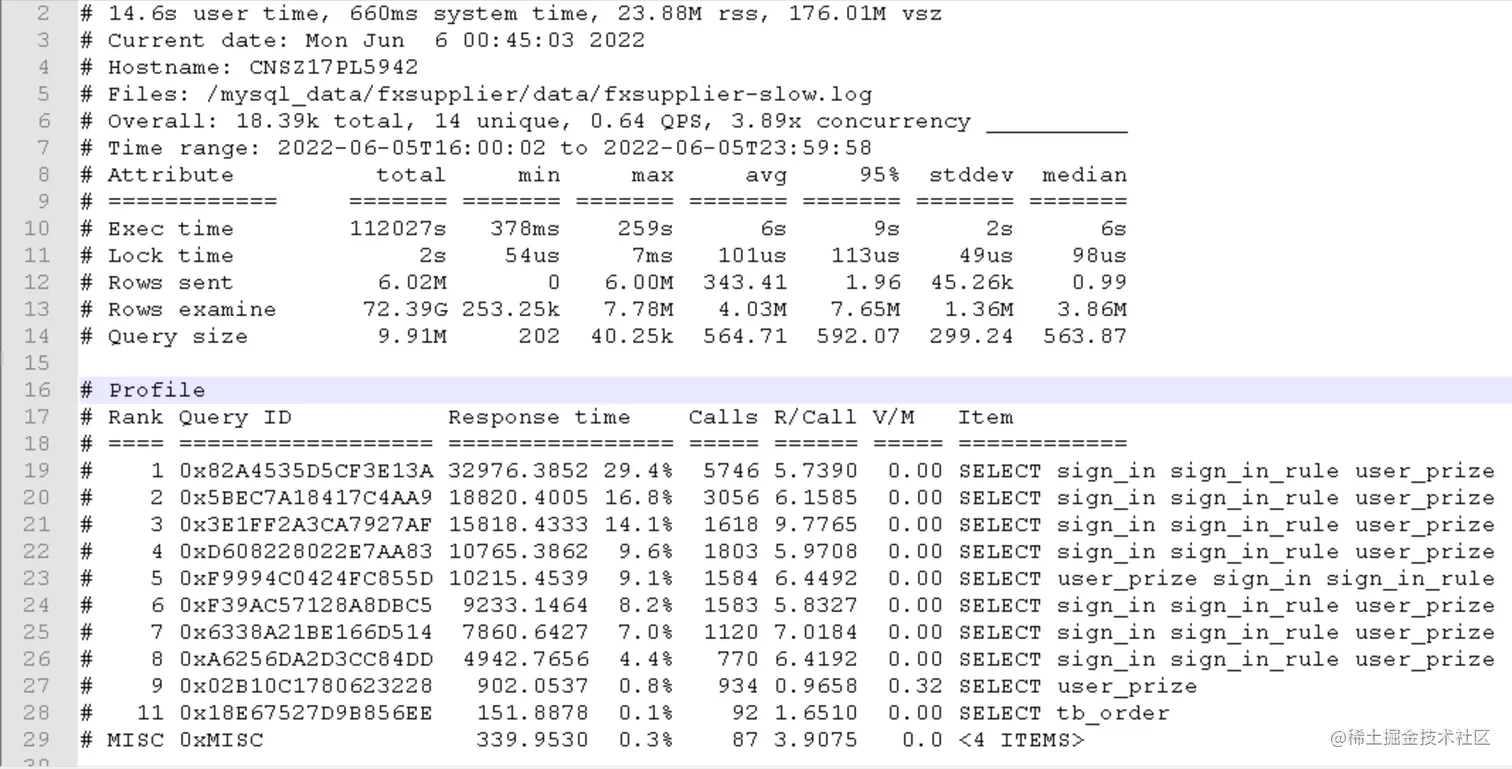
首先,从文件的前部分可以看到文件中有10个Query ID,分别代表10个慢日志查询。并且包含了每条查询的响应时间、查询项等。
截图信息中对DB的名称、DB的用户名称、DB的主机地址做了处理。
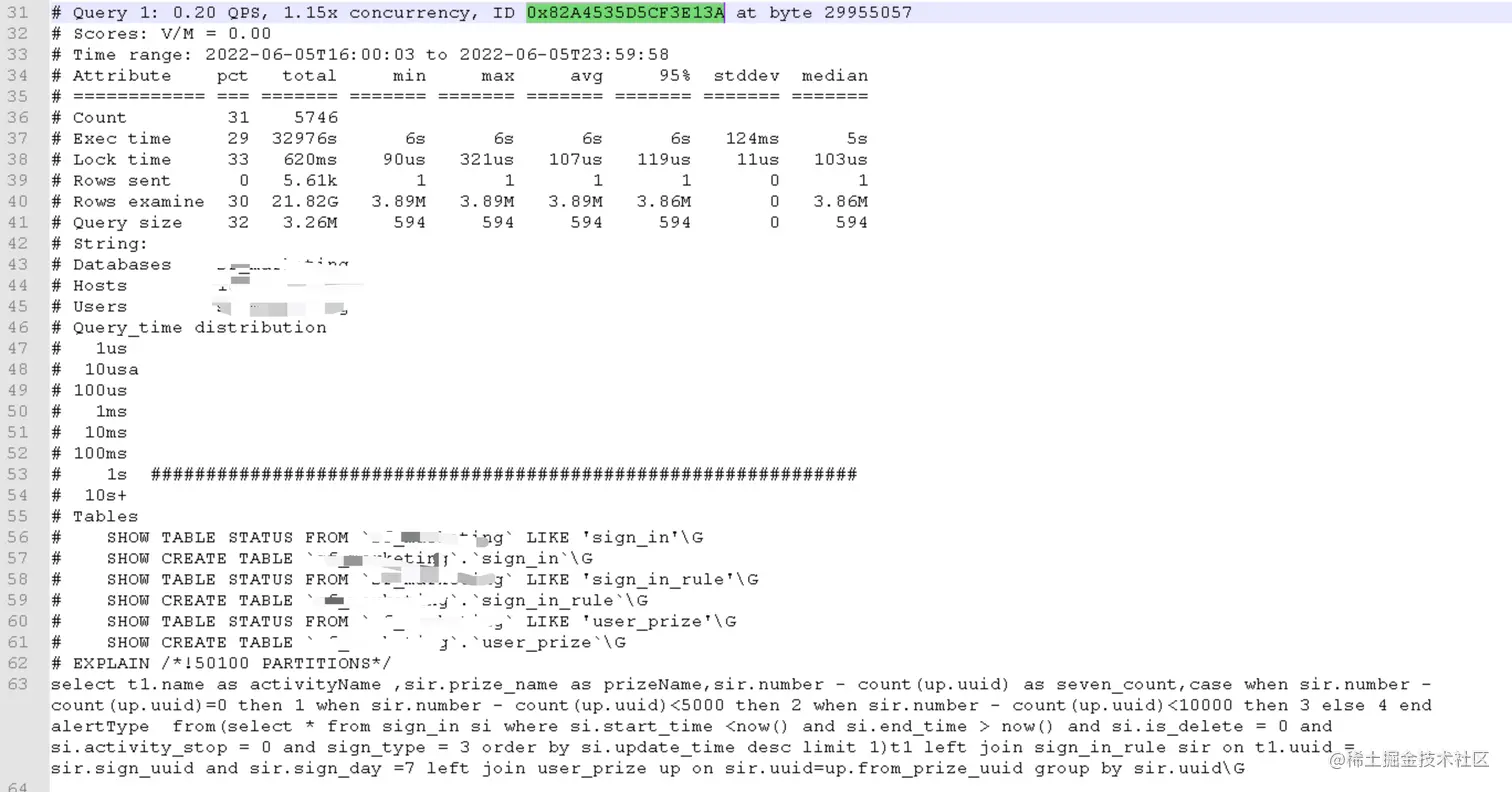
从截图中可以看到,Query ID为 0x82A4535D5CF3E13A 语句的相关信息:最少耗时6s、最大耗时6s、平均耗时6s、95%的查询耗时6s,可以说这条sql语句的查询耗时一直很平稳保持在6s的水平。
通过对表数据及索引状况的分析:
1、签到表:sign_in 数据量少:23笔;
索引情况:主键索引
2、签到规则:sign_in_rule 数据量:310笔;
索引情况:主键索引
3、用户抽奖奖品表:user_prize 数据量高达:420w+
索引情况:包含主键索引,另外还有部分字段组合而成的复合索引。
通过结合查询语句发现,**表 user_prize 表的 from_prize_uuid 字段做为 sign_in_rule 的外键,没有创建索引**,于是通过使用explain对语句的执行情况进行分析,发现对表user_prize查询时确实没有走索引,查询的type为:index。我们知道,索引的类型按照效率排序依次为:system > const > eq_ref > ref > range > index > All ,显然这里还有优化的空间,决定在此字段上新增一个索引:
CREATE INDEX idx_user_prize_from_prize_uuid USING BTREE ON DB_NAME.user_prize (from_prize_uuid); (DB_NAME为实际的数据库名称)
对from_prize_uuid字段建立索引后,在通过explain对语句进行分析,发现type值已经是ref了,查询的时间也从之前的6s提升为3s。
另外,在处理查询这几张表的情况时发现,测试环境跟生产环境的索引情况不一致,这也是一个项目组之前同事留下来的坑,一些处理问题不好的习惯。
根据上面同样的分析思路,在结合语句的实际业务场景,对剩下的慢SQL依次进行优化处理。
评审发布
依次在测试环境对慢SQL进行处理并组内分析评审后,决定发布到生产环境。由于为改动实际的表结构等信息,所以就通过grafana在线连接到对应的数据库,将脚本在正式环境进行执行,然后依次验证效果。


