

简介
在这篇文章中,我将向你展示使用Spring Data JpaRepsotiory的最佳方式,而这一方式往往被用错了。
默认的Spring DataJpaRepostory 的最大问题是,它扩展了通用的CrudRepository ,这与JPA规范并不兼容。
JpaReposiotry保存方法的悖论
在JPA中没有所谓的save 方法,因为JPA实现的是ORM范式,而不是Active Record模式。
JPA基本上是一个实体状态机,如下图所示。
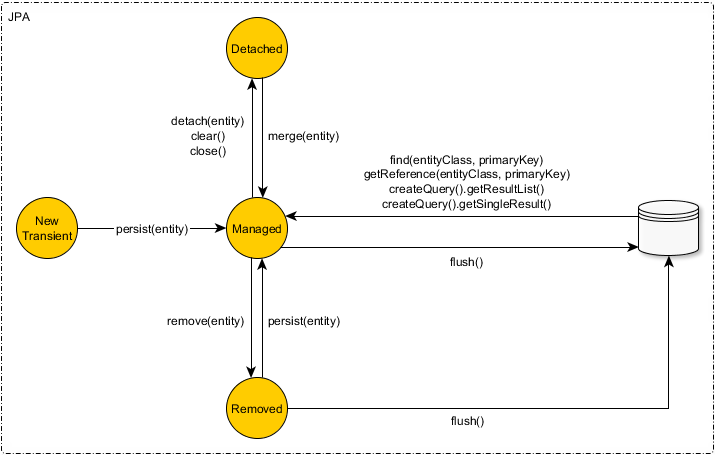
而且,Hibernate增加了一些特殊的方法,这些方法也非常有用,比如说 update一个。

但是,你可以清楚地看到,这里没有save 方法。
如果你创建了一个新的实体,你必须调用persist ,这样实体就会变成被管理的,而flush ,就会产生INSERT 语句。
如果实体变成了分离的,并且你改变了它,你必须将改变传播回数据库,在这种情况下,你可以使用merge 或update 。前一种方法,merge ,将分离的实体状态复制到一个已经被当前持久化上下文加载的新实体,并且让flush 来计算是否有必要进行UPDATE 。后一种方法,update ,强迫flush ,以当前的实体状态触发一个UPDATE 。
remove 方法安排了移除,而flush 将触发DELETE 语句。
但是,JpaReposiory 从CrudRepository 继承了一个save 方法,就像 MongoRepository或 SimpleJdbcRepository.
然而,MongoRepository 和SimpleJdbcRepository 采取了Active Record的方法,而JPA没有。
事实上,JpaReposiory 的save 方法是这样实现的。
@Transactional
public <S extends T> S save(S entity) {
if (this.entityInformation.isNew(entity)) {
this.em.persist(entity);
return entity;
} else {
return this.em.merge(entity);
}
}
在幕后没有任何魔法。它只是在现实中调用了persist 或merge 。
保存方法的反模式
因为JpaRepository 的特点是有一个save 方法,所以绝大多数的软件开发者都把它当作一个方法来对待,结果你就会碰到下面这种反模式。
@Transactional
public void saveAntiPattern(Long postId, String postTitle) {
Post post = postRepository.findById(postId).orElseThrow();
post.setTitle(postTitle);
postRepository.save(post);
}
这有多熟悉?你看到这种 "模式 "被采用了多少次?
问题在于save 行,虽然没有必要,但也不是没有成本。在一个被管理的实体上调用merge ,通过触发一个MergeEvent ,燃烧CPU周期,这可能会在实体层次结构中进一步级联,最终导致一个黑色的实体出现这种情况。
protected void entityIsPersistent(MergeEvent event, Map copyCache) {
LOG.trace( "Ignoring persistent instance" );
final Object entity = event.getEntity();
final EventSource source = event.getSession();
final EntityPersister persister = source.getEntityPersister(
event.getEntityName(),
entity
);
//before cascade!
( (MergeContext) copyCache ).put( entity, entity, true );
cascadeOnMerge( source, persister, entity, copyCache );
copyValues( persister, entity, entity, source, copyCache );
event.setResult( entity );
}
不仅如此,merge 调用并没有提供任何好处,而且它实际上给你的响应时间增加了额外的开销,并使云提供商在每一个这样的调用中更加富有。
所以,不要这样做!
最好的Spring Data JpaRepository替代品
如果save 方法,人们就会错过使用它。这就是为什么最好不要有它,并为开发者提供更好的JPA友好的替代方案。
下面的解决方案使用了客户Spring Data JPA Repository的习语。
因此,我们从自定义的HibernateRepository 接口开始,该接口定义了传播实体状态变化的新契约。
public interface HibernateRepository<T> {
//Save methods will trigger an UnsupportedOperationException
<S extends T> S save(S entity);
<S extends T> List<S> saveAll(Iterable<S> entities);
<S extends T> S saveAndFlush(S entity);
<S extends T> List<S> saveAllAndFlush(Iterable<S> entities);
//Persist methods are meant to save newly created entities
<S extends T> S persist(S entity);
<S extends T> S persistAndFlush(S entity);
<S extends T> List<S> persistAll(Iterable<S> entities);
<S extends T> List<S> peristAllAndFlush(Iterable<S> entities);
//Merge methods are meant to propagate detached entity state changes
//if they are really needed
<S extends T> S merge(S entity);
<S extends T> S mergeAndFlush(S entity);
<S extends T> List<S> mergeAll(Iterable<S> entities);
<S extends T> List<S> mergeAllAndFlush(Iterable<S> entities);
//Update methods are meant to force the detached entity state changes
<S extends T> S update(S entity);
<S extends T> S updateAndFlush(S entity);
<S extends T> List<S> updateAll(Iterable<S> entities);
<S extends T> List<S> updateAllAndFlush(Iterable<S> entities);
}
HibernateRepository 接口中的方法由HibernateRepositoryImpl 类实现,具体如下。
public class HibernateRepositoryImpl<T>
implements HibernateRepository<T> {
@PersistenceContext
private EntityManager entityManager;
@Override
public <S extends T> S save(
S entity) {
return unsupported();
}
@Override
public <S extends T> List<S> saveAll(
Iterable<S> entities) {
return unsupported();
}
@Override
public <S extends T> S saveAndFlush(
S entity) {
return unsupported();
}
@Override
public <S extends T> List<S> saveAllAndFlush(
Iterable<S> entities) {
return unsupported();
}
public <S extends T> S persist(
S entity) {
entityManager.persist(entity);
return entity;
}
public <S extends T> S persistAndFlush(
S entity) {
persist(entity);
entityManager.flush();
return entity;
}
public <S extends T> List<S> persistAll(
Iterable<S> entities) {
List<S> result = new ArrayList<>();
for(S entity : entities) {
result.add(persist(entity));
}
return result;
}
public <S extends T> List<S> peristAllAndFlush(
Iterable<S> entities) {
return executeBatch(() -> {
List<S> result = new ArrayList<>();
for(S entity : entities) {
result.add(persist(entity));
}
entityManager.flush();
return result;
});
}
public <S extends T> S merge(
S entity) {
return entityManager.merge(entity);
}
@Override
public <S extends T> S mergeAndFlush(
S entity) {
S result = merge(entity);
entityManager.flush();
return result;
}
@Override
public <S extends T> List<S> mergeAll(
Iterable<S> entities) {
List<S> result = new ArrayList<>();
for(S entity : entities) {
result.add(merge(entity));
}
return result;
}
@Override
public <S extends T> List<S> mergeAllAndFlush(
Iterable<S> entities) {
return executeBatch(() -> {
List<S> result = new ArrayList<>();
for(S entity : entities) {
result.add(merge(entity));
}
entityManager.flush();
return result;
});
}
public <S extends T> S update(
S entity) {
session().update(entity);
return entity;
}
@Override
public <S extends T> S updateAndFlush(
S entity) {
update(entity);
entityManager.flush();
return entity;
}
@Override
public <S extends T> List<S> updateAll(
Iterable<S> entities) {
List<S> result = new ArrayList<>();
for(S entity : entities) {
result.add(update(entity));
}
return result;
}
@Override
public <S extends T> List<S> updateAllAndFlush(
Iterable<S> entities) {
return executeBatch(() -> {
List<S> result = new ArrayList<>();
for(S entity : entities) {
result.add(update(entity));
}
entityManager.flush();
return result;
});
}
protected Integer getBatchSize(
Session session) {
SessionFactoryImplementor sessionFactory = session
.getSessionFactory()
.unwrap(SessionFactoryImplementor.class);
final JdbcServices jdbcServices = sessionFactory
.getServiceRegistry()
.getService(JdbcServices.class);
if(!jdbcServices.getExtractedMetaDataSupport().supportsBatchUpdates()) {
return Integer.MIN_VALUE;
}
return session
.unwrap(AbstractSharedSessionContract.class)
.getConfiguredJdbcBatchSize();
}
protected <R> R executeBatch(
Supplier<R> callback) {
Session session = session();
Integer jdbcBatchSize = getBatchSize(session);
try {
if (jdbcBatchSize == null) {
session.setJdbcBatchSize(10);
}
return callback.get();
} finally {
session.setJdbcBatchSize(null);
}
}
protected Session session() {
return entityManager.unwrap(Session.class);
}
protected <S extends T> S unsupported() {
throw new UnsupportedOperationException(
"There's no such thing as a save method in JPA, so don't use this hack!"
);
}
}
首先,所有的save 方法都会触发一个UnsupportedOperationException ,迫使你评估你实际上应该调用哪个实体状态转换。
与假的saveAllAndFlush 不同,persistAllAndFlush,mergeAllAndFlush, 和updateAllAndFlush 可以从自动批处理机制中受益,即使你之前忘记了配置它,正如本文所解释的。
测试时间
要使用HibernateRepository ,你所要做的就是在标准的JpaRepository 旁边扩展它,像这样。
@Repository
public interface PostRepository
extends JpaRepository<Post, Long>, HibernateRepository<Post> {
}
就是这样!
这一次,你不可能再碰到臭名昭著的save 调用反模式了。
try {
transactionTemplate.execute(
(TransactionCallback<Void>) transactionStatus -> {
postRepository.save(
new Post()
.setId(1L)
.setTitle("High-Performance Java Persistence")
.setSlug("high-performance-java-persistence")
);
return null;
});
fail("Should throw UnsupportedOperationException!");
} catch (Exception expected) {
}
相反,你可以使用persist,merge, 或update 方法。所以,如果我想持久化一些新的实体,我可以这样做。
postRepository.persist(
new Post()
.setId(1L)
.setTitle("High-Performance Java Persistence")
.setSlug("high-performance-java-persistence")
);
postRepository.persistAndFlush(
new Post()
.setId(2L)
.setTitle("Hypersistence Optimizer")
.setSlug("hypersistence-optimizer")
);
postRepository.peristAllAndFlush(
LongStream.range(3, 1000)
.mapToObj(i -> new Post()
.setId(i)
.setTitle(String.format("Post %d", i))
.setSlug(String.format("post-%d", i))
)
.collect(Collectors.toList())
);
而且,把一些被分离的实体的变化推送回数据库的方法是这样的。
List<Post> posts = transactionTemplate.execute(transactionStatus ->
entityManager.createQuery("""
select p
from Post p
where p.id < 10
""", Post.class)
.getResultList()
);
posts.forEach(post ->
post.setTitle(post.getTitle() + " rocks!")
);
transactionTemplate.execute(transactionStatus ->
postRepository.updateAll(posts)
);
而且,与merge 不同,update 允许我们避免一些不必要的SELECT 语句,而且只有一个UPDATE 被执行。
Query:["
update
post
set
slug=?,
title=?
where
id=?"
],
Params:[
(high-performance-java-persistence, High-Performance Java Persistence rocks!, 1),
(hypersistence-optimizer, Hypersistence Optimizer rocks!, 2),
(post-3, Post 3 rocks!, 3),
(post-4, Post 4 rocks!, 4),
(post-5, Post 5 rocks!, 5),
(post-6, Post 6 rocks!, 6),
(post-7, Post 7 rocks!, 7),
(post-8, Post 8 rocks!, 8),
(post-9, Post 9 rocks!, 9)
]
厉害吧?
结论
JPA没有所谓的save 方法。它只是一个不得不在JpaRepository 中实现的黑客,因为这个方法是从CrudRepository 中继承的,它是一个几乎被Spring Data项目共享的基础接口。
使用HibernateRepository ,不仅可以更好地推理出你需要调用的方法,而且还可以从update 方法中获益,该方法为批处理任务提供了更好的性能。
