

在这篇文章中,我们要看一下最广泛使用的机器学习算法。它们的种类繁多,当你听到 "基于实例的学习算法 "和 "感知器 "等术语时,很容易感到困惑。
通常情况下,所有的机器学习算法都会根据它们的学习风格、功能或者它们解决的问题而被分成几组。在这篇文章中,你会发现一个基于学习风格的分类。我还会提到这些算法帮助解决的常见任务。
今天使用的机器学习算法的数量很大,我不会提到100%的算法。但是,我想对最常用的算法做一个概述。
监督学习算法

如果你不熟悉 "监督学习 "和 "无监督学习 "这样的术语,请查看我们的AI vs. ML帖子,那里详细介绍了这个话题。现在,让我们来熟悉一下这些算法。
1.分类算法
Naive Bayes

贝叶斯算法是ML中使用的基于应用贝叶斯定理的概率性分类器家族。
Naive Bayes分类器是最早用于机器学习的算法之一。它适用于二类和多类分类,可以根据历史结果进行预测和预报数据。一个典型的例子是垃圾邮件过滤系统,直到2010年都在使用Naive Bayes,并显示出令人满意的结果。然而,当贝叶斯中毒法被发明后,程序员们开始思考其他方法来过滤数据。
使用贝叶斯定理,可以知道一个事件的发生是如何影响另一个事件的概率的。
例如,这种算法根据所使用的典型词汇来计算某封电子邮件是或不是垃圾邮件的概率。常见的垃圾邮件词汇是 "报价"、"立即订购 "或 "额外收入"。如果该算法检测到这些词,则该邮件有很大可能是垃圾邮件。
Naive Bayes假设特征是独立的。因此,该算法被称为天真的算法。
多项式奈何贝叶斯
除了奈何贝叶斯分类器,这一组中还有其他算法。例如,多项式奈何贝叶斯,它通常被应用于基于文档中存在的某些词的频率的文档分类。
贝叶斯算法仍然被用于文本分类和欺诈检测。它们也可以应用于机器视觉(例如人脸检测)、市场细分和生物信息学。
逻辑回归
尽管这个名字可能看起来很不直观,但逻辑回归实际上是分类算法的一种。
Logistic回归是一种使用logistic函数进行预测的模型,以找到输出和输入变量之间的依赖关系。 Statquest制作了一个很好的视频,他们以肥胖小鼠为例解释了线性回归和逻辑回归之间的区别。
决策树
决策树是一种简单的方式,以树的形式可视化决策模型。决策树的优点是它们易于理解、解释和可视化。而且,它们对数据准备的要求不高。
然而,它们也有一个很大的缺点。由于数据中最小的变化(差异),树可能是不稳定的。也有可能创建过于复杂的树,不能很好地概括。这就是所谓的过度拟合。装袋、提升和正则化有助于解决这个问题。我们将在后面的文章中讨论这些问题。
每一棵决策树的元素是:
- 根节点,提出主要问题。它有指向下的箭头,但没有指向它的箭头。例如,想象一下你正在建立一棵树,用于决定晚餐应该吃哪种意大利面。
- 分支。一棵树的一个分支被称为分支,有时也被称为子树。
- 决策节点。这些是根节点的子节点,也可以分割成更多的节点。你的决策节点可以是 "carbonara?"或 "与蘑菇?"。
- 叶子或终端节点。这些节点不会分裂。它们代表最终决定或预测。
另外,有必要提到分裂。这是将一个节点分成子节点的过程。例如,如果你不是一个素食主义者,carbonara是可以的。但如果你是,就吃蘑菇意大利面。还有一个去除节点的过程,叫做修剪。
决策树算法被称为CART(分类和回归树)。决策树可以与分类或数字数据一起工作。
- 当变量有数值时,回归树就会被使用。
- 当数据是分类的(类别)时,可以应用分类树。
决策树是相当直观的理解和使用。这就是为什么树状图通常被应用于广泛的行业和学科。GreyAtom对不同类型的决策树及其实际应用进行了广泛的介绍。
SVM(支持向量机)
支持向量机是另一组用于分类的算法,有时还用于回归任务。SVM很好,因为它以最小的计算能力给出相当准确的结果。
支持向量机的目标是在N维空间中找到一个超平面(其中N与特征的数量相对应),对数据点进行明确的分类。结果的准确性与我们选择的超平面直接相关。我们应该找到一个在两个类别的数据点之间具有最大距离的平面。
这个超平面在图形上表示为一条线,将一个类别与另一个类别分开。落在超平面不同边上的数据点被归于不同的类别。
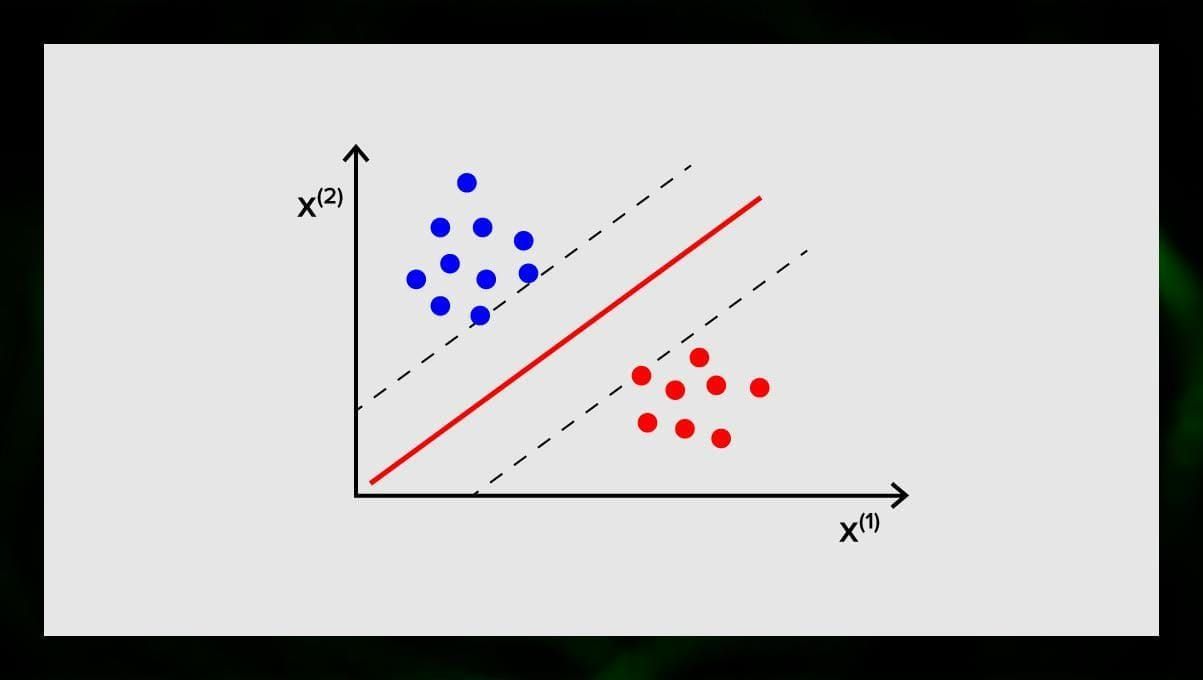
请注意,超平面的维度取决于特征的数量。如果输入特征的数量是2,那么超平面就只是一条线。如果输入特征的数量是3,那么超平面就变成了一个二维的平面。当特征的数量超过3时,在图上画出一个模型就变得很困难。因此,在这种情况下,你将使用内核类型将其转化为一个3维空间。
为什么这被称为支持向量机?支持向量是最接近超平面的数据点。它们直接影响超平面的位置和方向,使我们能够最大化分类器的边际。删除支持向量将改变超平面的位置。这些是帮助我们建立SVM的点。
现在,SVM被积极用于医疗诊断以发现异常,用于空气质量控制系统,用于股票市场的金融分析和预测,以及工业的机器故障控制。
2.回归算法
回归算法在分析中非常有用,例如,当你试图预测证券的成本或特定产品在特定时间的销售时。
线性回归
线性回归试图通过对观察到的数据拟合一个线性方程来模拟变量之间的关系。
有解释变量和因变量。因变量是我们想要解释或预测的东西。解释型的,正如它的名字一样,解释一些东西。如果你想建立线性回归,你假设因变量和自变量之间存在线性关系。例如,房子的平方米数和它的价格或该地区的人口密度和烤肉店之间存在关联。
一旦你做出这个假设,你接下来需要弄清楚具体的线性关系。你需要为一组数据找到一个线性回归方程。最后一步是计算残差。
注意: 当回归画出一条直线时,它被称为线性,当它是一条曲线时--多项式。
无监督学习算法

现在让我们来谈谈能够在无标签数据中找到隐藏模式的算法。
1.聚类
聚类是指我们根据输入的相似程度将其分为不同的组。聚类通常是建立一个更复杂的算法的步骤之一。分别研究每一组,并根据它们的特征建立一个模型,而不是一次性处理所有东西,这样做更简单。同样的技术在市场和销售中不断被使用,将所有的潜在客户分成几组。
非常常见的聚类算法是K-means聚类和K-nearest neighbor。
K-means聚类
K-means聚类将向量空间的元素集合分成预定数量的聚类k。虽然聚类的数量不正确会使整个过程失效,但用不同数量的聚类进行尝试是很重要的。k-means算法的主要思想是,数据被随机地划分为群组,之后,在上一步中获得的每个群组的中心被反复重新计算。然后,向量再次被划分为群组。当在某一点上,经过一次迭代后集群没有变化时,该算法就会停止。
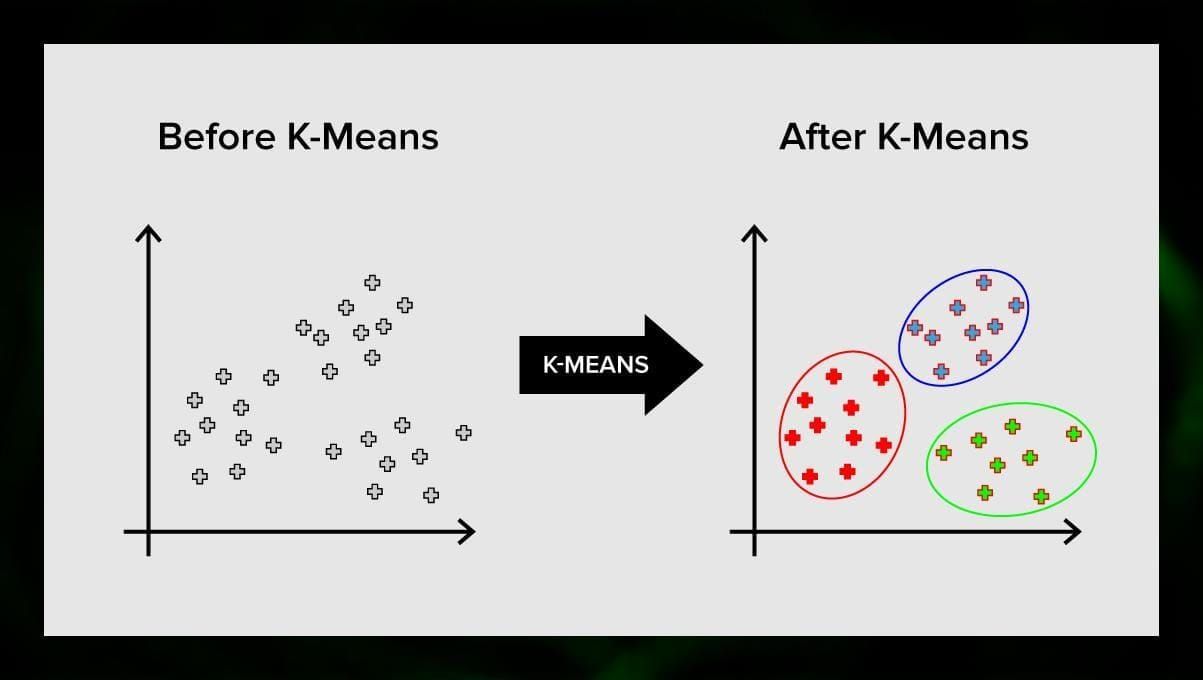
这种方法可以应用于解决当集群是不同的或可以很容易地相互分离,没有重叠数据的问题。
K-近邻
kNN是k-nearest neighbor的缩写。这是最简单的分类算法之一,有时用于回归任务。
为了训练分类器,你必须有一组具有预定义类别的数据。标记是由研究领域的专家手动完成的。使用这种算法,有可能处理多个类别或清除输入属于一个以上类别的情况。
该方法是基于这样的假设:类似的标签对应于属性向量空间中的接近对象。
现代软件系统使用kNN进行视觉模式识别,例如,扫描和检测结账时购物车底部的隐藏包裹(例如AmazonGo)。K-近邻也被用于银行业,以检测信用卡使用的模式。K-近邻算法分析所有的数据,并发现表明可疑活动的异常模式。
2.降维
主成分分析(PCA)是一项重要的技术,为了有效地解决与ML有关的问题,需要了解它。
想象一下,你有很多的变量需要考虑。例如,你需要将城市分为三组:适合居住的、不适合居住的和一般的。你要考虑多少个变量?也许,很多。你了解它们之间的关系吗?不太了解。那么,你怎样才能把你收集到的所有变量,只关注其中最重要的几个?
用技术术语来说,你要 "减少你的特征空间的维度"。通过降低你的特征空间的维度,你设法获得更少的变量之间的关系来考虑,你就不太可能过度拟合你的模型。
有很多方法可以实现降维,但大多数技术都属于两类中的一类。
- 特征消除。
- 特征提取。
特征消除意味着你通过消除一些特征来减少特征的数量。这种方法的优点是,它很简单,并且保持了你的变量的可解释性。不过,作为一个缺点,你从你决定放弃的变量中得到的信息为零。
特征提取避免了这个问题。应用这种方法时的目标是从给定的数据集中提取一组特征。特征提取的目的是通过在现有特征的基础上创建新的特征(然后抛弃原来的特征)来减少数据集中的特征数量。新的减少的特征集的创建方式必须能够概括原始特征集中包含的大部分信息。
主成分分析是一种提取特征的算法。它以一种特定的方式组合输入变量,然后有可能放弃 "最不重要 "的变量,同时仍然保留所有变量中最有价值的部分。
PCA的可能用途之一是当数据集中的图像太大。一个缩小的特征表示有助于快速处理图像匹配和检索等任务。
3.关联规则学习
Apriori是最流行的关联规则搜索算法之一。它能够在相对较短的时间内处理大量的数据。
问题是,今天许多项目的数据库都非常大,达到几千兆字节和几万兆字节。而且它们将继续增长。因此,人们需要一种有效的、可扩展的算法来在短时间内找到关联规则。Apriori就是这些算法中的一种。
为了能够应用该算法,有必要对数据进行准备,将其全部转换为二进制形式并改变其数据结构。
通常,你在一个包含大量交易的数据库上操作这个算法,例如,在一个包含顾客在超市购买的所有商品信息的数据库上。
强化学习

强化学习是机器学习的方法之一,有助于教机器如何与某个环境互动。在这种情况下,环境(例如,在一个视频游戏中)充当了老师。它为计算机做出的决定提供反馈。基于这种奖励,机器学会了采取最佳行动方案。这让人想起儿童学习不碰热煎锅的方式--通过试验和感受痛苦。
将这一过程分解开来,它涉及这些简单的步骤。
- 计算机观察环境。
- 选择一些策略。
- 按照这个策略行事。
- 接受奖励或惩罚。
- 从这个经验中学习并完善策略。
- 重复进行,直到找到最佳策略。
Q-Learning
有几种算法可用于强化学习。其中最常见的是Q-learning。
Q-learning是一种无模型的强化学习算法。Q-learning是基于从环境中获得的报酬。代理人形成一个效用函数Q,随后给它一个选择行为策略的机会,并考虑到以前与环境互动的经验。
Q-learning的优点之一是,它能够在不形成环境模型的情况下比较可用行动的预期效用。
集合学习

集合学习是通过建立多个ML模型并将其结合起来来解决问题的方法。集合学习主要用于提高分类、预测和函数近似模型的性能。集合学习的其他应用包括检查模型做出的决定,为建立模型选择最佳特征,增量学习和非平稳学习。
下面是一些比较常见的集合学习算法。
装袋法
Bagging是bootstrap aggregating的缩写。它是最早的集合算法之一,具有令人惊讶的良好性能。为了保证分类器的多样性,你使用训练数据的自举副本。这意味着从训练数据集中随机抽取不同的训练数据子集--带替换。每个训练数据子集都被用来训练同一类型的不同分类器。然后,各个分类器可以被合并。要做到这一点,你需要对它们的决定进行简单的多数投票。由大多数分类器分配的类别就是集合决定。
提升算法
这组合集算法与bagging相似。Boosting也使用各种分类器对数据进行重新取样,然后通过多数投票选择最佳版本。在boosting中,你反复训练弱分类器,将它们组合成一个强分类器。当分类器被加入时,它们通常被归入一些权重,这些权重描述了它们预测的准确性。在一个弱分类器被添加到集合中后,权重被重新计算。错误分类的输入会获得更多的权重,而正确分类的实例会降低权重。因此,系统更加关注获得错误分类的实例。
随机森林
随机森林或随机决策森林是一种用于分类、回归和其他任务的集合学习方法。为了建立随机森林,你需要在训练数据的随机样本上训练众多的决策树。随机森林的输出是各个树中最频繁的结果。由于算法的随机性,随机决策森林成功地对抗了过度拟合。
堆叠
堆叠是一种集合学习技术,它通过元分类器或元回归器结合多个分类或回归模型。基层模型是基于一个完整的训练集进行训练的,然后元模型是以基层模型的输出为特征进行训练。
神经网络
神经网络是一个由突触连接的神经元序列,这让人想起人脑的结构。然而,人类的大脑甚至更加复杂。
神经网络的伟大之处在于,它们基本上可以用于任何任务,从垃圾邮件过滤到计算机视觉。然而,它们通常被应用于机器翻译、异常检测和风险管理、语音识别和语言生成、人脸识别等等。
一个神经网络由神经元,或节点组成。这些神经元中的每一个都接收数据,处理数据,然后将其转移到另一个神经元中。
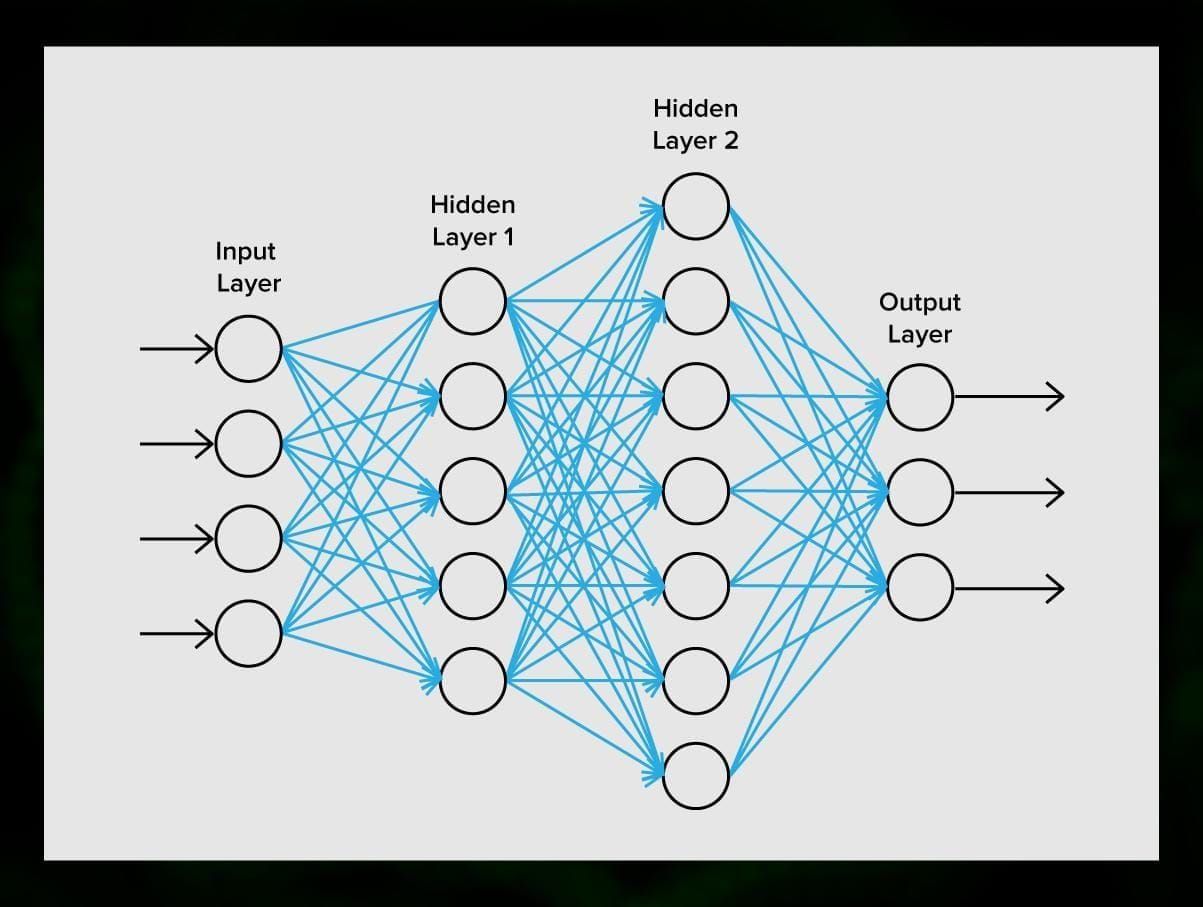
每个神经元处理信号的方式都一样。但是,那么我们如何得到不同的结果呢?将神经元相互连接的突触负责这一点。每个神经元都能有许多突触,这些突触能减弱或放大信号。另外,神经元能够随着时间的推移改变其特性。通过选择正确的突触参数,我们将能够在输出端获得输入信息转换的正确结果。
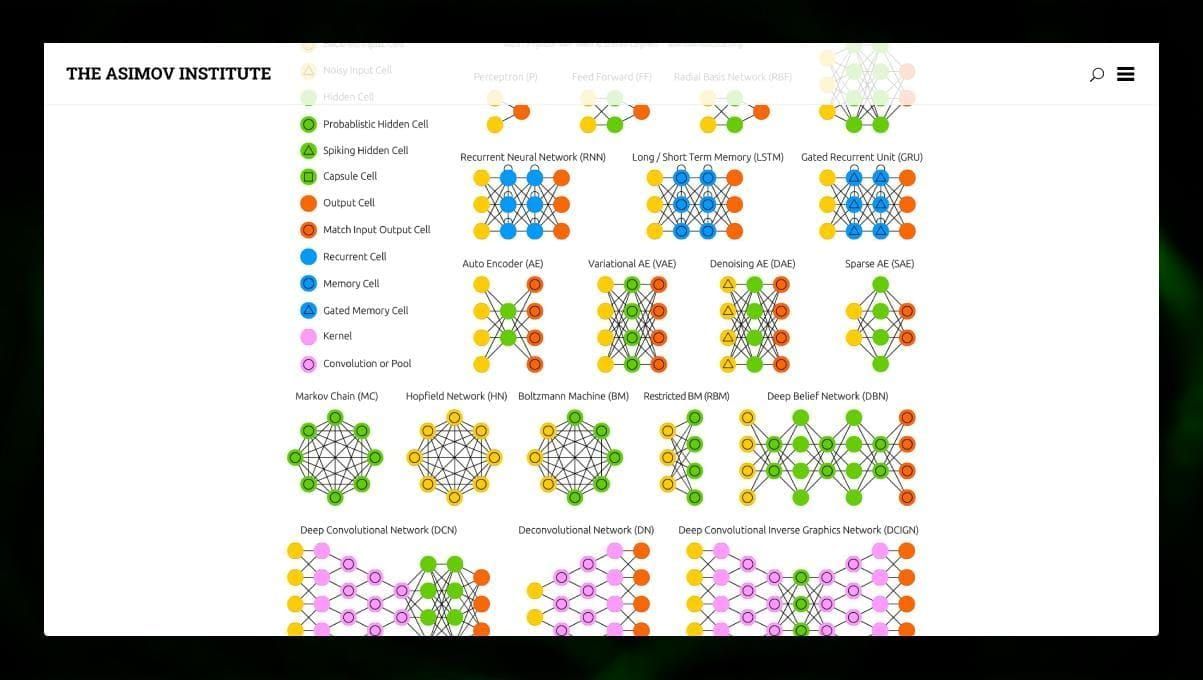
有许多不同类型的NN。
- 前馈神经网络(FF或FFN)和感知器§是非常直接的,网络中没有循环或周期。在实践中,这种网络很少被使用,但它们经常与其他类型的网络相结合,以获得新的网络。
- 霍普菲尔德网络(HN)是一个具有对称链接矩阵的全连接神经网络。这样的网络通常被称为联想记忆网络。就像一个人看到桌子的一半,就能想象出另一半一样,这种网络在接收到一个嘈杂的桌子后,会将其恢复为完整的。
- 卷积神经网络(CNN)和深度卷积神经网络(DCNN)与其他类型的网络非常不同。它们通常被用于图像处理、音频或视频相关的任务。应用CNN的一个典型方式是对图像进行分类。
观察许多不同类型的神经网络是很有趣的。在NN动物园里就可以做到这一点。
总结
这篇文章是对不同ML算法的广泛概述,但仍有很多东西要讲。
