

预测客户行为、消费者需求或股票价格波动、识别欺诈和诊断病人--这些是随机森林(RF)算法的一些流行应用。用于分类和回归任务,它可以显著提高业务流程和科学研究的效率。
这篇博文将介绍随机森林算法、其工作原理、能力和局限性以及现实世界的应用。
什么是随机森林?
随机森林是一种有监督的机器学习算法,其中许多决策树的计算被结合起来产生一个最终结果。它之所以受欢迎是因为它简单而有效。
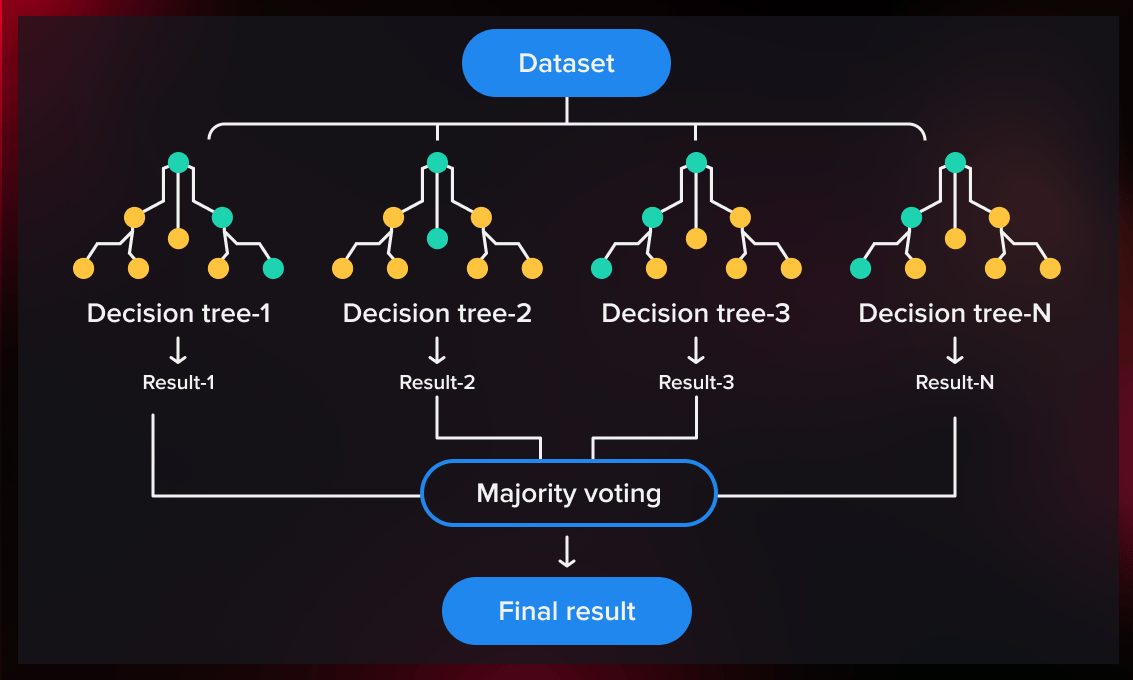
随机森林是一种集合方法--一种我们采取许多基础级模型并将其结合起来以获得改进结果的技术。因此,为了了解它是如何运作的,我们首先需要看一下它的组成部分--决策树--以及它们是如何工作的。
决策树:随机森林的树
决策树是一类机器学习算法,用于分类和回归等任务。这些算法获取数据并创建模型,与你在其他领域可能遇到的决策树类似。
决策树模型采取一些输入数据,并遵循一系列的分支步骤,直到它达到预定的输出值之一。
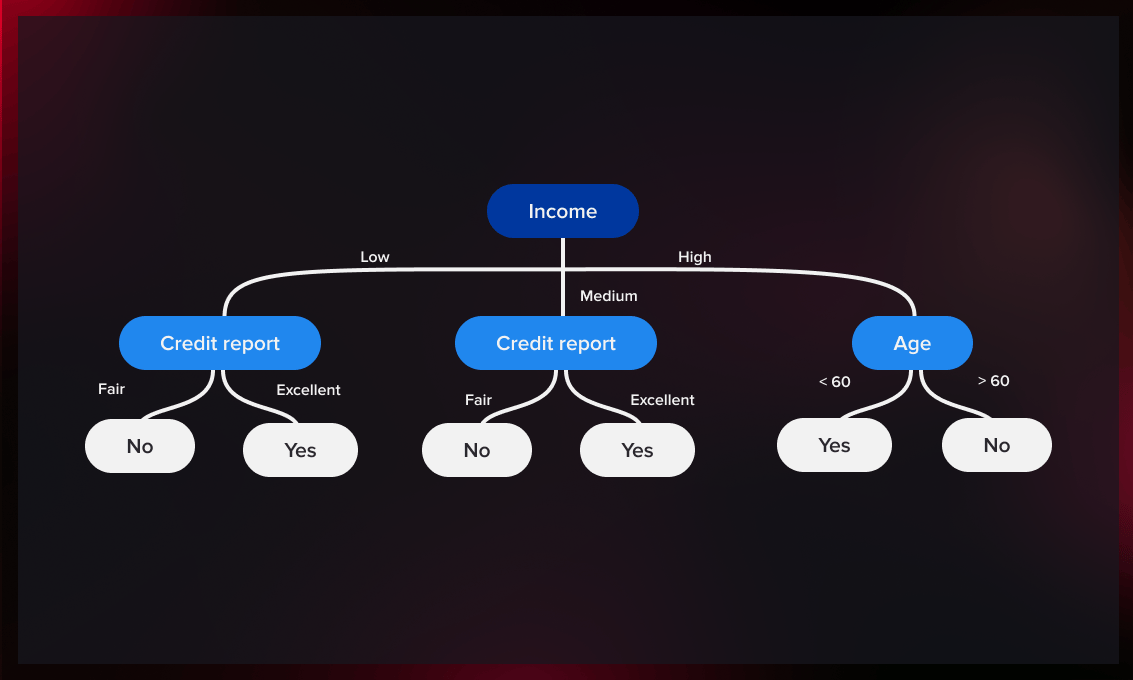
这种算法的一些最常见的类型是分类树和回归树。
分类树
该技术用于确定一个目标变量最可能属于哪个 "类"。因此,你可以确定谁会或不会订阅一个流媒体平台,或者谁会从大学辍学,以及谁会成功完成学业。
回归树
回归树是一种算法,其目标变量不是一个预定义的值。回归问题的一个例子是对房价的预测--一个连续变量。这是由连续参数(如平方英尺)和分类因素(如房屋类型、房产位置等)决定的。
当数据集必须被分成相互排斥的类别时,如黑人或白人,是或不是,分类树通常被利用。当响应变量是连续的,如销售量或每日温度,则采用回归树。
要了解更多关于这个主题的信息,你可以观看下面的视频。
训练一棵决策树
为了让我们知道首先对哪个特征进行分割以及如何分割,必须确定每个特征的相关性和重要性。
这是由我们选择的分割函数完成的。从广义上讲,它通常试图使信息增益最大化--通过对数据集的每一次分割获得的信息(或熵值减少)。
如果你不熟悉这些术语,你可以认为该算法试图分割数据,以便在每次分割时创建最均匀的组。
之后,我们递归地分割数据集,直到我们达到某个停止条件。通常,这个条件是最小计数--我们想要创建的叶子在数据集中的条目数量。
由此产生的树就是我们的模型。
在这段视频中,你会发现关于决策树如何训练的更详细的解释。
随机森林算法是如何工作的?
现在我们知道了什么是单一的决策树以及如何训练它,我们已经准备好训练整个森林了。
让我们看看这个过程是如何一步步发生的。
1.将数据集分成子集
随机森林是一个决策树的集合体。为了创建许多决策树,我们必须将我们拥有的数据集分成子集。
主要有两种方法:你可以随机选择哪些特征来训练每棵树(随机特征子空间),并从所选的特征中抽取一个带替换的样本(引导样本)。
2.训练决策树
在我们将数据集分割成子集后,我们在这些子集上训练决策树。训练的过程和训练单个树的过程是一样的--我们只是多做了很多。
也许你有兴趣知道,这个训练过程是非常可扩展的:由于树是独立的,你可以很容易地将训练过程并行化。
3.汇总结果
每个单独的树都包含一个结果,它取决于树的初始数据。为了摆脱对初始数据的依赖并产生更准确的估计,我们将它们的输出合并为一个结果。
可以使用不同的方法来汇总结果。例如,在分类的情况下,经常使用按性能投票的方法,而对于回归,则应用平均模型。
4.验证模型
在我们用训练数据完成训练过程并用测试数据集运行测试后,我们要进行保留验证过程。这涉及到用相同的超参数训练一个新的模型。特别是,这些参数包括树的数量、剪枝和训练程序、分割函数等。
请注意,训练的目的不是为了找到最适合我们的特定模型实例。我们的目标是开发一个没有预训练参数的通用模型,并在指标方面找到最合适的训练程序:准确性、抗过拟合性、记忆力和其他通用参数。
憋屈的验证程序只需要用于模型评估目的。另一种避免过拟合的常用方法是k-fold交叉验证。它基于同样的原则:使用度量衡和过拟合阻力验证超参数,然后在整个数据集上训练一个新模型。
在我们训练好模型之后,我们就可以预测尚未发生的新事件的结果(例如,金融业的贷款或医学的疾病)。
射频超参数
在训练过程中,你很可能会对随机森林算法的不同超参数进行试验,看看哪个参数能带来最佳结果。
随机森林可以由各种元素来定义,如森林中的树木数量或数据子集创建程序。
其他RF超参数涉及森林中使用的决策树。例如,用于划分节点的最大特征数,算法的停止条件,或使用的分割函数(吉尼杂质或熵) 。
决策树与随机森林
决策树模型需要一些输入数据,并遵循一系列的if-then步骤,直到它达到预定的输出值之一。
相比之下,随机森林模型是许多单独的决策树的组合,在初始数据的子集上训练。
举个例子,如果你想用一棵决策树来预测某些客户使用银行提供的某项服务的频率,你会收集客户过去访问银行的频率以及他们使用过哪些服务的数据。你将指定决定客户选择的某些特征。决策树将创建规则,帮助你预测客户是否会使用这些服务。
如果你把同样的数据放入随机森林,该算法将从随机选择的客户群中创建几棵树。森林的输出将是所有这些树的个别结果的组合。
| 决策树 | 随机森林 |
|---|---|
| 一种算法,为分类或回归生成树状规则集。 | 一种算法,结合许多决策树以产生更准确的结果。 |
| 当具有某些特征的数据集被摄入决策树时,它就会产生一套预测的规则。 | 在数据的随机样本上建立决策树,并对结果进行平均。 |
| 对初始数据集的依赖性很高;因此,在现实世界中预测的准确性很低。 | 精度高,结果偏差小。 |
| 容易出现过度拟合,因为有可能过度适应初始数据集。 | 使用许多树可以使算法避免和/或防止过拟合。 |
随机森林算法的好处和挑战
随机森林有其优点和缺点。然而,前者要比后者更重要。
优点
- 成本效益高。与神经网络相比,RF的训练成本更低,速度更快。同时,它在准确性方面也没有什么损失。由于这个原因,随机森林建模被用于移动应用,例如。
- 对过度拟合的鲁棒性。如果一棵树由于其训练集中的一个离群点而做出了不准确的预测,另一棵树很可能会用相反的离群点来补偿这个预测。 因此,一组不相关的树比任何单独的树表现得更好。
- 高覆盖率和低偏差。上述情况使随机森林分类器成为可能在你的数据集中存在一些缺失值的情况下的理想选择,或者如果你想了解不同类型的数据输出之间有多少差异(例如,大学本科生有可能完成学业后离开,继续攻读硕士学位,或辍学)。
- 适用于分类和回归。事实证明,RF对这两类任务的结果同样准确。
- 可以处理特征中的缺失值,而不在预测中引入偏差。
- 易于解释。森林中的每棵树都独立地进行预测,因此你可以查看任何一棵树来了解它的预测。
挑战
随机森林分类器也有一些挑战。
- 随机森林比决策树更复杂,在决策树中,只需遵循树的路线就足以做出决定。
- 随机森林分类器往往比其他一些类型的机器学习模型要慢,所以它们可能不适合某些应用。
- 它们在大数据集和有足够训练数据的情况下效果最好。
随机森林的应用
这种算法被用于预测一些部门的行为和结果,包括银行和金融、电子商务和医疗保健。由于其易于应用、适应性强以及能够执行分类和回归任务,它已被越来越多地采用。
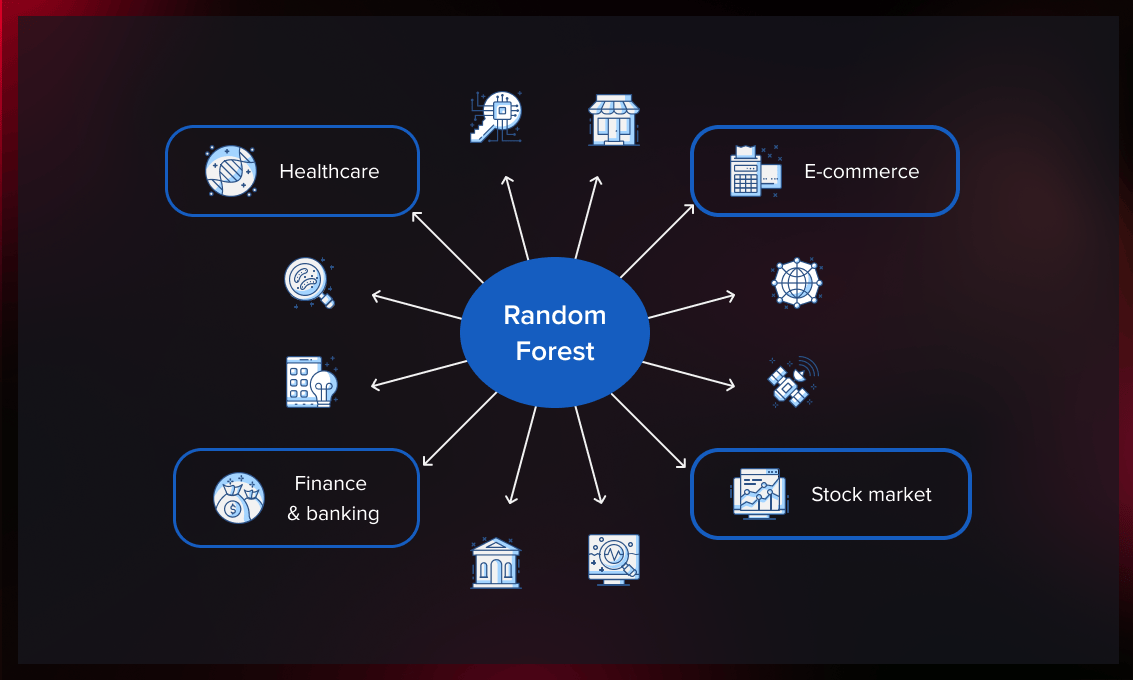
医疗保健
在医疗保健领域,射频为早期诊断提供了许多可能性,不仅比神经网络更便宜,而且还解决了与神经网络相关的伦理问题。尽管神经网络在大多数临床预测测试中的表现令人印象深刻,但由于它们是黑箱模型,因此缺乏可解释性,很难在实际的临床世界中实施。
虽然神经网络的决策是不可追踪的,但在随机森林的情况下,它是完全透明的。医学专家可以理解为什么随机森林会做出这样的决定。例如,如果有人出现不良的副作用或因治疗而死亡,他们可以解释为什么算法会做出这个决定。
金融和银行业
在金融领域,可以采用随机森林分析来预测抵押贷款违约,并识别或防止欺诈。因此,该算法决定了客户是否有可能违约。为了检测欺诈,它可以分析一系列的交易,并确定它们是否可能是欺诈性的。
另一个例子。可以根据交易历史和规律性,训练射频来估计客户终止账户的概率。如果我们将这个模型应用于所有现有用户的群体,我们可以预测未来几个月的流失率。这为公司提供了极其有用的商业信息,有助于识别瓶颈并与客户建立长期的伙伴关系。
股票市场
根据历史数据预测未来的股票价格是金融市场中一个重要的射频应用。事实证明,在股票定价、期权定价和信用价差预测方面,随机森林的表现比任何其他预测工具都好。
你如何在这些情况下应用RF?例如,如果你正在分析各种股票的盈利能力,你可能会根据它们的市场价值将它们分成几组,然后比较它们的投资回报率。你会不断地分割这些组,直到每个组只包含一个项目或没有项目。这个过程被称为递归分割。阅读这篇文章,了解用Python编写的预测股票价格的算法的实际实现。
电子商务
该算法已被越来越多地用于电子商务,以预测销售。
比方说,你试图预测一个网上购物者在看到Facebook上的广告后是否会购买一件商品。在这种情况下,可能只有少数购物者在看到广告后最终购买(可能有5%购买),但有更多的购物者最终没有购买(可能有95%没有)。
在客户数据上使用随机森林分类器,如年龄、性别、个人喜好和兴趣,就可以预测哪些客户会购买,哪些不会,准确率相对较高。而通过针对可能的买家进行广告宣传,你将优化你的营销支出并增加销售。
随机森林的历史
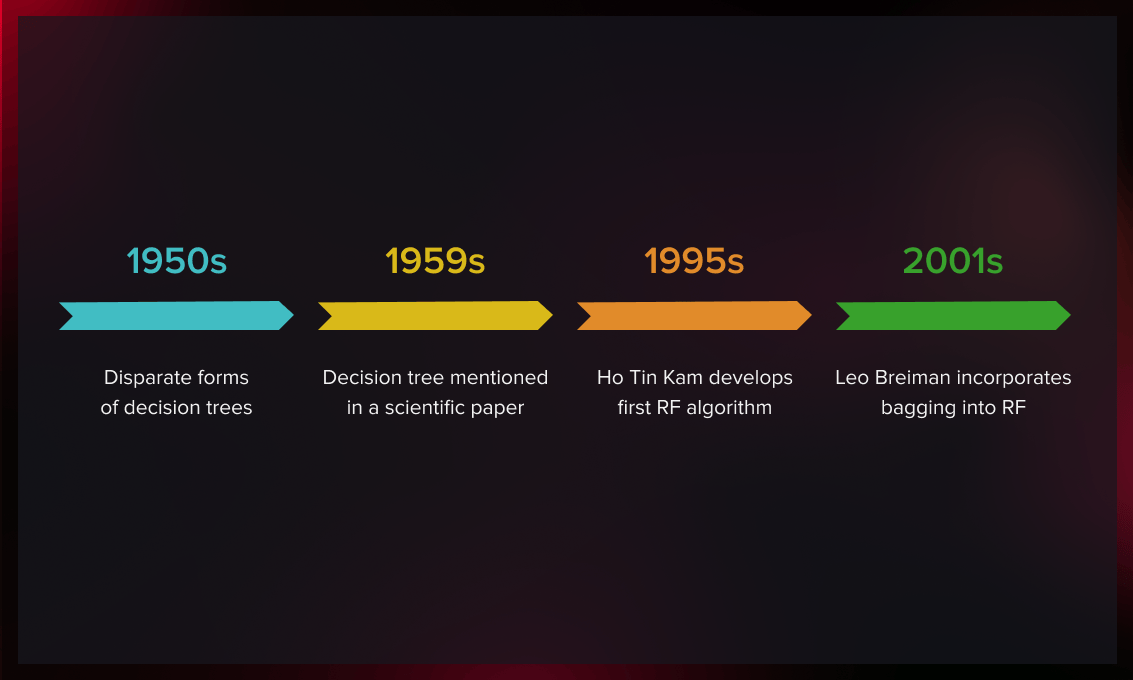
自20世纪50年代以来,非集合决策树已经以各种形式存在。然而,没有一个研究者能因其发现而受到表彰。1959年,一位英国统计学家在一篇论文中提到了决策树作为生物体分类的工具。
在接下来的几十年里,统计学界逐渐发展了这种算法。
直到1995年,香港和美国的研究人员Tin Kam Ho才开发了第一个随机森林算法。为了减少估算器之间的相关性,她采用了一种方法,即每棵树只接触到全部特征集的一部分,但仍用整个训练集进行训练。
2001年,美国计算机科学家Leo Breiman通过加入袋法改进了Ho的算法。Breiman建议使用原始训练集的子样本来训练每个估计器。
现在,布雷曼的版本被用于随机森林方法的大多数最新实现中。你可以在这里阅读Leo Breiman的论文。
在过去的几年里,随机森林已经有了一些改进。
2004年,Robnik-Šikonja通过使用几个属性评估措施而不是只有一个,在不损失解释力的情况下降低了树之间的相关性。他还引入了另一项改进,将投票方法从多数投票改为加权投票。在这个投票过程中,内部估计被用来寻找与被标记的案例最相似的案例。然后,相关树的投票强度对这些接近的情况进行加权。
后来Xu等人想出了一种混合加权RF算法来识别高维数据。由于几种决策树算法,如C4.5、CART和CHAID,都被用来生成RF中的树,所以被称为混合算法。八个高维数据集被用来评估混合RF。与传统的RF相比,混合技术的表现经常优于旧方法。因此,随机森林分类器不仅被广泛使用,而且也是一种不断发展的方法,其效率正在日渐提高。
主要启示
- 随机森林是一种基于几个决策树聚集的ML集合算法。它准确、高效,而且创建速度相对较快。
- RF克服了决策树算法的缺点,减少了数据集的过拟合,提高了准确性。
- 由于其使用的简单性和结果的准确性,几十年来它一直是数据科学家中最受欢迎的分类算法之一。
- 它被用于各种领域,如金融和银行、电子商务、医疗保健等。该算法被用来预测诸如消费者活动、风险、股票价格和出现疾病症状的可能性。
随机森林分类器处理大型数据集。由于不是所有的数据都需要处理,它们在不牺牲准确性的情况下与数据的随机样本一起工作。另外,你可以很容易地从模型中添加或删除对预测结果变量无用的特征。
