

这篇博文讲述了我们为什么以及如何从Node Redis客户端库迁移到Ioredis的故事。
什么是Redis?
Redis是一个分布式内存数据库,支持按键存储简单和结构化的值。作为一个内存数据库,它的速度非常快,但也是短暂的:关闭Redis服务器或它所运行的机器将抹去所有存储的数据。它确实提供了一些快照功能,但作为内存意味着它被设计为快速,而不是一个永久的数据存储。因此,这是一种你会为连接到你的网站的用户存储令牌的数据库,但不是你心爱的猫的照片。
我们如何在Ably使用Redis
在Ably,我们使用Redis来短期存储各种实体,如认证令牌和短暂的通道状态。我们在处理消息时,会短暂地存储这些消息,所以这样的数据库很适合我们。Redis是我们工具箱中一个非常重要的工具。我们的大部分后端代码都是用Node.js编写的,使用推荐的Node Redis客户端是很自然的,所以我们在过去的几年里一直依赖它。它为我们提供了很好的服务,但我们遇到了一些性能问题,认为是时候寻找替代方案了。
开始使用Node Redis
来自github.com/NodeRedis/n…的Node Redis客户端既是Redis背后的人正式推荐的,也是最古老的客户端之一,这就是为什么我们最初选择它。
我们与Redis交互的代码使用了一个抽象层,增加了一些功能,如队列操作、延迟操作、错误重试、事务等。其中一些功能现在是由客户端库本身提供的,但在当时是没有的。我们还广泛地使用Lua脚本来支持跨多个键的复杂原子操作。
我们在我们的一个托管pub-sub通道的服务器角色上做了一些性能分析,以便了解为什么具有高比率的消息处理的集群使用了比它们应该使用的更多的CPU资源--我们注意到一些意想不到的事情。
下面是火焰图的摘录,显示了在每个函数调用上花费的时间。
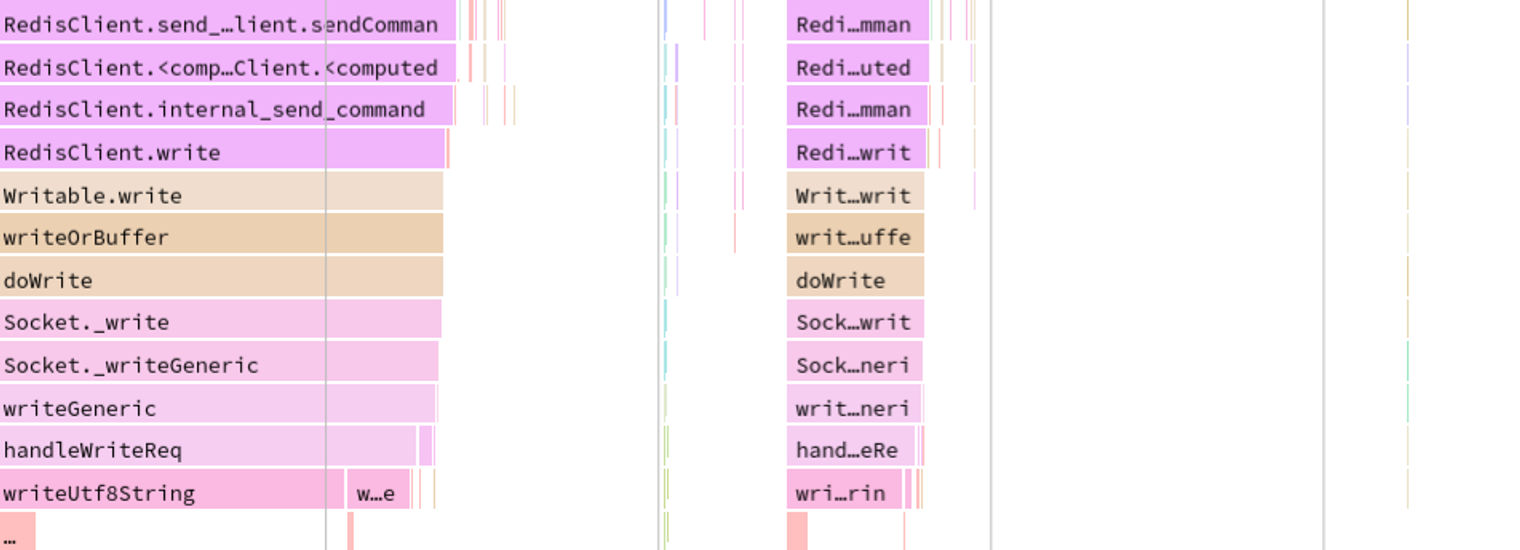
火焰图显示了在每个操作上花费的时间
14%的服务器CPU使用量(20s配置文件中的2.7s)被用于向套接字写入,作为向Redis发送命令的一部分。这似乎有点过头了。我们发现,如果Redis命令的参数之一是一个缓冲区,Node Redis每次都会对每个参数进行三次单独的套接字写入,外加一次命令字符串。对于一个有10个参数的脚本,这将是31次套接字写入。
这个设计选择的动机是合理的:避免了组装一个缓冲区来发送可能导致的数据拷贝的成本。然而,至少对于我们的用例(有大量相对较小参数的脚本)来说,优化复制数据来构建一个单一的缓冲区将是一个很大的改进。在堆栈的所有低层分别处理如此多的小写的成本太高了。
这一分析促使我们去寻找替代方案。我们通常尝试修复我们的开源依赖的问题,但我们首先环顾四周,看看是否有一个现有的替代Redis客户端,其设计更适合我们的用例。其他两个推荐的客户端是Ioredis和Tedis。Tedis似乎没有被维护(自2018年以来没有提交),所以我们决定投入一些时间来评估Ioredis。
对Ioredis的调查
Ioredis将自己描述为一个 "强大的、全功能的Redis客户端,被用于世界上最大的在线商务公司 阿里巴巴和许多其他令人敬畏的公司"。根据npmcompare,它从2015年开始出现,所以它比Node Redis年轻5年,但似乎工作更积极。
看一下它的源代码,我们看到它准备了要在缓冲区中发送的命令,并且只执行了一次套接字写入。与Node Redis所做的相比,这看起来很有希望。这促使我们对Ioredis的套接字写入进行了非常快速的测试。请注意,这个测试只是有效的,因为我们试图剖析的工作在两种情况下都是与send_command 同步进行的。结果如下。
只使用字符串
$ node redis_bench.js
ready
nrclient 1475
ioclient 1769
主要使用字符串和一个缓冲区
$ node redis_bench.js
ready
nrclient 15368
ioclient 2733
只用字符串的测试是我们的控制测试。我们预计使用Node Redis会很快,因为在这种情况下它只执行一次套接字写入。当使用大部分字符串和一个缓冲区时,我们可以看到花费的时间差异是明显的。这种差异促使我们进行实验性迁移和更深入的负载测试。
迁移到Ioredis
我们通常喜欢用迭代的方式来实现新的功能,而不是一下子全部实现。这使我们能够在问题出现时进行调试,而且每次测试的代码块也比较小。然而,随着从Node Redis到Ioredis的迁移,这带来了一些障碍,因为我们使用了一些抽象的东西,使得同时运行两个Redis客户端变得困难。
我们的方法是使用方便的Ioredis指南从node_redis迁移开始,替换/重命名所有函数和参数。这第一步很简单,因为Ioredis的API与Node Redis的很接近。不过翻译交易调用就有点难度了,因为我们使用的是一个继承自Node Redis的Multi类的类,而Ioredis只提供了multi(),这是一个函数。其余的迁移工作相对简单,包括删除多余的功能,比如我们不再需要的操作队列和重试机制。
我们的内部持续集成(CI)让我们发现了一些问题。首先,有几个地方Ioredis和Node Redis的API是不同的。API的 "兼容 "版本会自动将所有缓冲区的结果强制为字符串,这是我们不想要的。这确实导致了一些难以发现的错误,并要求我们迁移到使用不执行这种转换的API。第二,特别是对于脚本评估来说,在实现上存在一些错误。这个问题之前已经被发现了,并且做了一个PR,但这还没有被合并。
一旦我们的Typescript代码编译成功,本地测试也通过了,就该在我们的专用环境中进行一些负载测试了。
负载测试Ioredis
在Ably,我们通常先在开发者的电脑上进行本地测试。我们维护一套广泛的测试,可以在本地运行。这样做可以确保工程师在工作时可以快速测试他们的代码,而不是等待代码通过CI。一旦所有东西都通过了本地测试,我们就把代码发送到一个新的Git分支,让CI通过测试来运行它。
一旦通过,我们就在测试环境中运行代码:我们按照一些模式模拟一些流量,这取决于正在测试的功能。然后我们测量CPU和内存的使用情况(包括其他指标),以评估新功能会产生什么影响。
在这个测试中,我们决定模拟每秒由16个客户发出的128个请求。每个消息包含100字节的有效载荷。下图显示了我们一个实例的CPU使用率。最初的增加是由于测试的开始,CPU使用率稳定在65%左右。
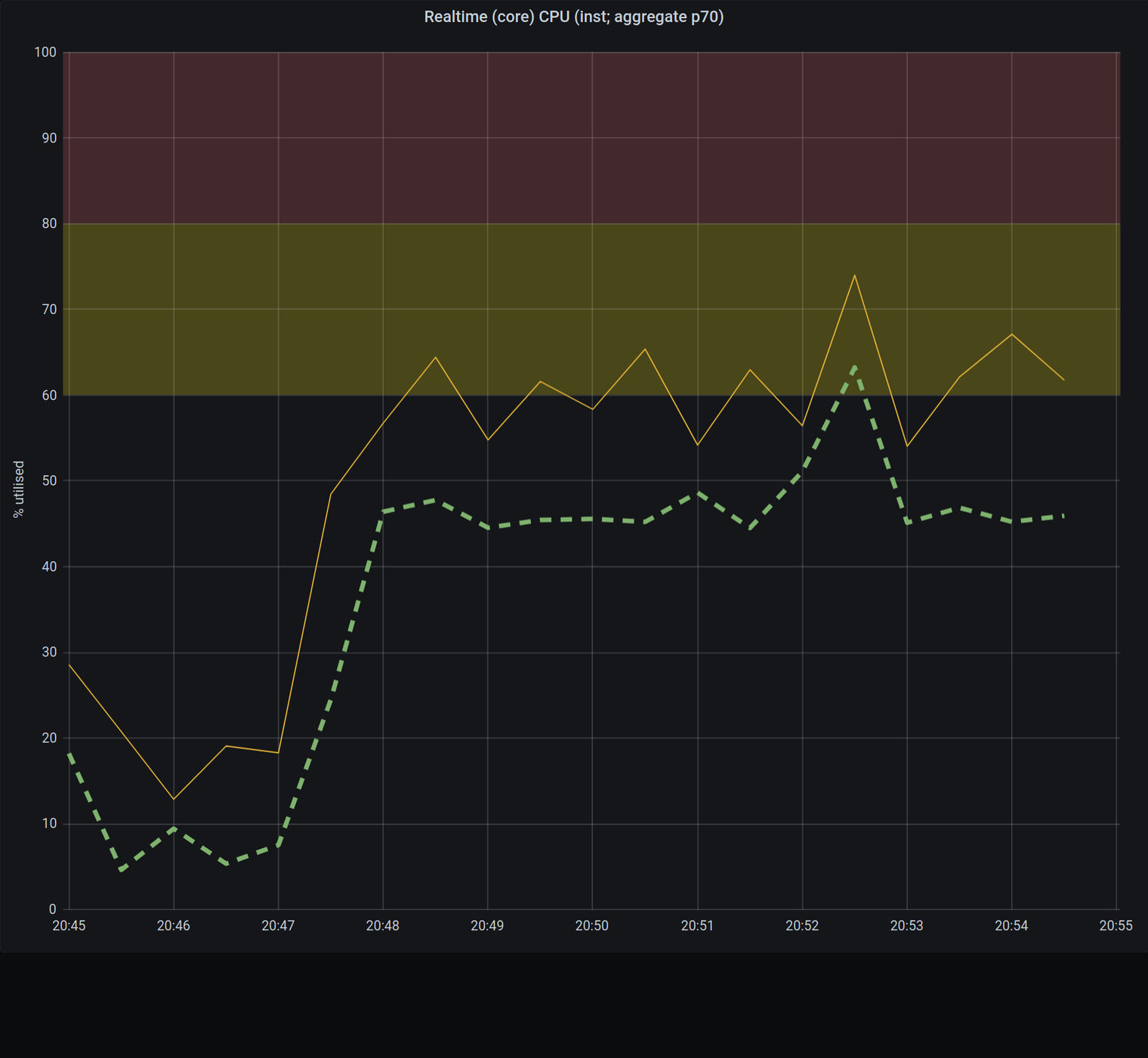
Node Redis上一个实例的CPU使用率
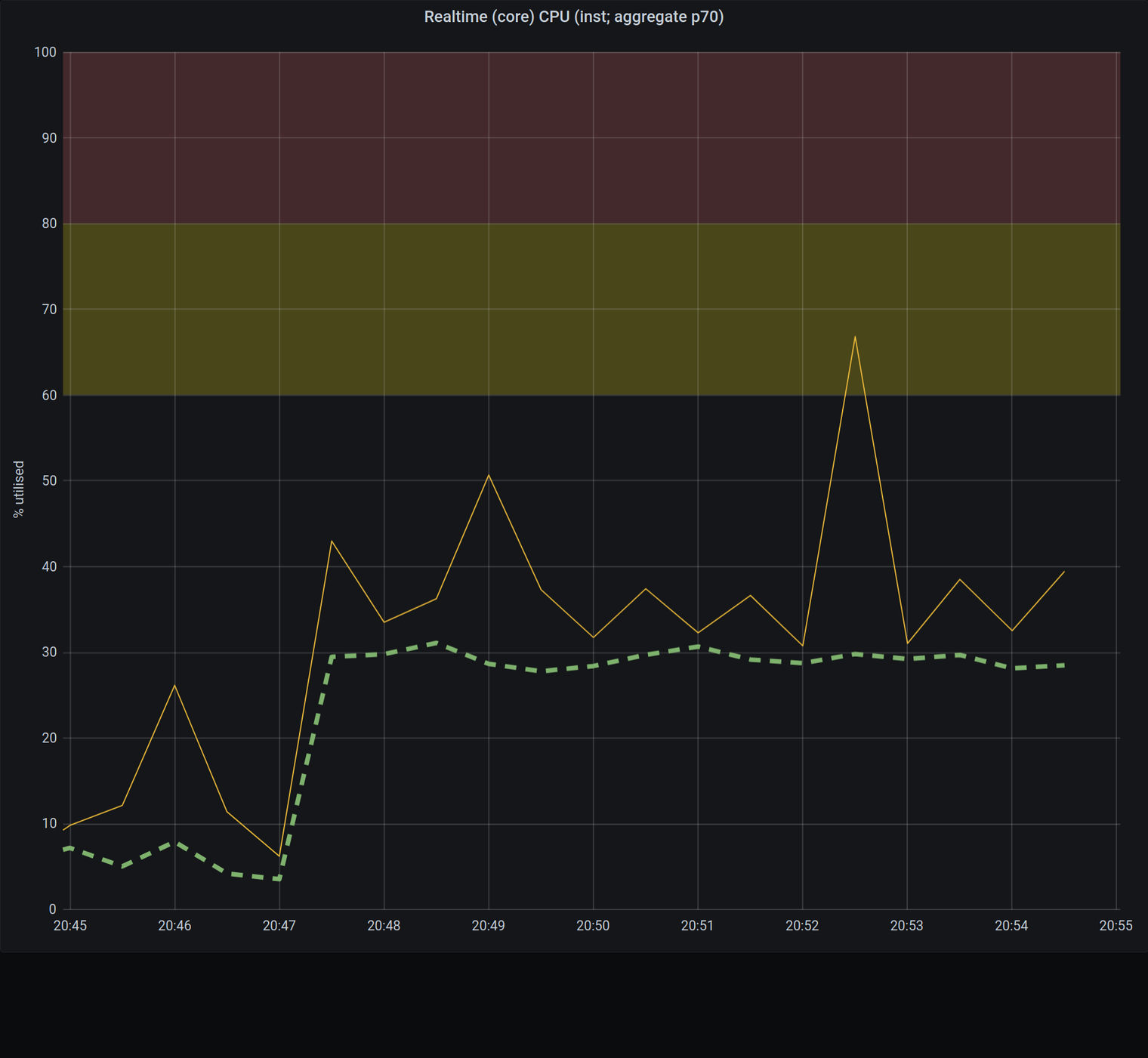
Ioredis上的一个实例的CPU使用率
上面的两个数字显示了迁移前后的CPU使用率。我们可以清楚地看到,对于同样的消息流,CPU使用率减少了30%。
这个负载测试的结果告诉我们,这个迁移应该会对CPU的使用产生重大影响。生产统计数据进一步证实了这一点。
最后的想法
最初的Node Redis作者曾试图在处理缓冲区时做正确的事情(即避免数据拷贝),但这实际上导致了性能大大降低的情况。这对我们来说不是最理想的,因为我们正在调用Redis函数,这些函数有许多小尺寸的参数,因此执行许多套接字写入。
我们对Node Redis和Ioredis进行了一些独立的测试,Ioredis表现出了明显的性能改进,主要是因为它在发送批处理之前将所有参数复制到一个缓冲区。这意味着更少的套接字写入和更多的拷贝。幸运的是,后者对我们来说并不重要,因为我们的参数从未达到令人担忧的大小。此外,结果延伸到了生产中的性能改进,有了完整的工作负载。
我们在迁移过程中遇到了一些障碍,但这是可以预期的(很遗憾)。一旦我们迁移了代码,我们就对CPU的使用进行了一些实际的负载测试。结果是令人鼓舞的。
至于Node Redis,我们注意到大多数的依赖性仍然是正在积极工作的活代码,而且成熟度并不统一:一些功能被广泛采用并经过良好的测试,但另一些则没有。这是可行的,只要。
- 你预测到这些问题,并确保你评估和测试你打算使用的特定功能或配置;以及
- 采用者对社区做出贡献,帮助成熟和维护软件。
因此,虽然Node Redis和它的底层架构选择对于特定的用例来说是一个很好的选择,但这些用例并不适合我们,Ioredis更适合。
 hbspt.cta.load(6939709, 'e3ba758f-66f2-4e49-baa9-a4c89803cb99', {"region":"na1"});
hbspt.cta.load(6939709, 'e3ba758f-66f2-4e49-baa9-a4c89803cb99', {"region":"na1"});
阅读更多Ably Engineering的博文
关于Ably
Ably是一个完全管理的平台即服务(PaaS),提供快速、高效的消息交换和交付,以及状态同步。我们每天都在解决实时领域的艰巨工程问题,并为之感到高兴。如果你在尝试大规模、可预测、安全地扩展你的实时消息系统时遇到了问题,请联系我们,我们将帮助你为你的客户提供无缝的实时体验。
