

当涉及到负载平衡器和反向代理时,HAProxy是最受欢迎的软件之一。当你把它用于这些目的时,监测可用性和性能尤为重要,这将影响你的SLI和SLOs。
在这篇文章中,我们将讨论你应该监测的主要HAProxy指标,以及你可以用来测量它们的最佳监测工具。
什么是HAProxy?
HAProxy是一个高可用性的服务器,用于负载平衡和作为TCP和HTTP应用程序的代理。它可以做TLS卸载,基于头和基于路由的路由,以及对后端进行健康检查。它支持像WebSocket、gRPC、HTTP等协议。
HAProxy也是目前最快的代理之一,这是因为它的事件驱动架构。它可以快速执行对I/O操作的行动,其对称多处理和轻量级多线程提供了一个任务调度器,专注于高吞吐量和低延迟。它还支持ACL,让你根据请求者的IP、URL参数、头文件等来控制谁可以访问什么资源。
当你在反向代理模式下工作时,HAProxy提供了很多其他知名代理,如NGINX,不提供的免费功能,包括TCP和TCP SSL。
启用HAProxy状态页来收集性能指标
在其默认配置中,HAProxy并没有暴露指标。要开始监视HAProxy,你首先要启用对HAProxy指标的访问,以便其他应用程序可以读取这些指标。有两种方法可以做到这一点:HTTP接口和UNIX套接字接口。
启用HTTP接口
要启用HAProxy统计页面,请在你的HAProxy配置文件的末尾添加下面的片段,你一般可以在/etc/haproxy.cfg找到:
listen stats # Define a listen section called "stats"
bind :9000 # Listen on port 9000
mode http
stats enable # Enable stats page
stats hide-version # Hide HAProxy version
stats realm Haproxy\ Statistics # Title text for popup window
stats uri /haproxy_stats # Stats URI
stats auth Username:Password # Authentication credentials
在上面代码的最后一行,你会看到你可以设置你的用户名和密码来访问该页面。这个设置需要你重新启动HAProxy服务。之后,你就可以在http://haproxy_dns_or_ip:9000/haproxy_stats,访问你的统计信息页面。
启用UNIX套接字接口
在haproxy.cfg中加入以下代码,启用UNIX套接字接口:
global
stats socket /run/haproxy/haproxy.sock mode 660 level admin
有了这个套接字,你就可以使用UNIX套接字访问HAProxy的统计信息。但首先,你需要了解套接字通信是如何工作的。尝试用Netcat连接到这个HAProxy UNIX套接字。
当通过网络提取指标时,你可以使用HTTP模式,如果你的代理在本地系统中运行,可以使用套接字模式。
要监控的重要HAProxy指标
HAProxy可以对你的后端端点进行健康检查,并公布它们的指标。你可以通过在你的后端配置中添加http-check选项来启用这些指标。监测前端、后端和系统指标是很重要的。
前台监控指标
你可以使用前端指标来跟踪从客户端到HAProxy的连接情况。前端指标的问题意味着你的应用程序与HAProxy的连接有问题。
请确保监控以下内容:
请求率 [req_rate]
前端请求率代表请求进入的速度。它表明流量的突然增加或减少,这可以帮助你做出扩展的决定。
阈值:如果你看到请求率的增加,你可能要扩大你的HAProxy集群的规模,因为可能有更多的人在试图访问你的应用程序。
会话速率[rate]
这是HAProxy在前端和客户端之间建立连接的速率。一个会话可以被映射到一个唯一的客户端。这些是由每个客户端创建的TCP会话,通过它可以发送多个HTTP请求。
阈值:会话速率的突然增加会很快给你的系统带来沉重的负担,并使其崩溃。请求率(req_rate)的增加而会话率没有增加,可能意味着有大量的重试。
错误请求 [ereq]
这表示HTTP请求中的错误数量。它可能由许多因素引起,包括客户端在发送请求前终止连接,客户端超时,客户端的读取错误,以及在攻击情况下被发送到蜜罐服务器的请求。
阈值:HAProxy错误请求的增加意味着客户端不能连接到你的服务器。你可能要检查客户机超时和你的HAProxy集群中的资源使用情况。
被拒绝的请求[dreq]
这指的是由于客户端到HAProxy的权限问题,由于错误的ACL而被拒绝的请求。
阈值:如果你收到很多被拒绝的请求,要么你的客户有错误的证书,要么有人试图用暴力或其他方法来猜测证书。
HTTPS响应代码4xx和5xx [hrsp_4xx, hrsp_5xx] 。
这些是对客户端的HTTP状态代码响应,意味着HAProxy向客户端返回了大量的4xx或5xx代码。
阈值:这些数值的任何异常增加都表明应用程序有问题。4xx代码表明客户端发送的东西是错误的,而5xx代码表明后端服务器在服务请求时崩溃了。大量的408代码意味着有一个请求超时。
网络I/O [bin, bout]
这些是网络输入和网络输出的指标,表示流量,你必须跟踪这些指标,以预测你在什么时候会有多少流量。
阈值:网络IO的任何突然增加都可能是危险的,会扼杀你的网络。网络I/O的任何减少意味着总流量减少或流量的性质发生了变化。历史趋势可以帮助你扩大和缩小服务器的规模。
后台监控指标
后端指标用于跟踪从你的HAProxy到后端服务器的连接情况。它们提供的信息可以帮助你检查HAProxy是否能与后端正常对话,以及后端的响应是否达到了性能要求。
这里有一些重要的HAProxy后端指标需要监控。
响应时间 [rtime]
这是过去1,024个请求的平均后端响应时间。较高的rtime意味着你的后端花了比它应该花的更多的时间来响应,表明可能有一个性能问题或退化。
阈值:响应时间大于200-500ms,表明服务器性能不佳。如果你的后端调用需要500ms,你的客户会感觉到滞后。注意,如果你不使用HTTP,rtime指标将保持为零。
错误连接 [econ]
这指向一个后端连接错误,意味着HAProxy不能连接到后端服务,你的服务可能会出现故障。这个指标也包括后端错误,例如后端没有活动连接。为了确定后端连接错误增加的原因,将这个指标与你的后端和前端的eresp和响应代码相关联。
阈值:如果你的监控工具提醒你econ的突然增加,检查你的HAProxy和后端服务器之间的连接问题。这个数字应该是最小的。
被拒绝的响应 [dresp]
拒绝响应是当HAProxy试图连接到后端时,从后端到HAProxy的权限错误。在大多数情况下,权限错误会出现在前端和HAProxy之间。
阈值:异常数量的拒绝请求意味着你的HAProxy中存在凭证问题。由于ACL而被限制的后端响应将返回HTTP代码502。如果你的应用ACL配置正确,这些值应该等于零。
错误响应 [eresp]
这是由你的后端产生的错误响应。错误响应包括数据传输错误、ACL错误、套接字连接错误,等等。这个指标可以帮助你理解为什么你会看到后端错误。将其与后端错误响应率结合起来有助于确定确切的问题。
阈值:这些数字的任何增加意味着错误增加了,你需要检查你的后端。如果错误响应率很高,而且拒绝响应也增加了,那么错误是在ACL,你的客户端没有配置好。
在队列中花费的平均时间[qtime]
这是过去1,024个请求的平均响应时间。
阈值:为 了获得更好的性能,qtime应该尽可能的低。较高的qtime意味着你的请求需要更长的时间来处理。注意任何逐渐或突然的增加,并对这些事件采取扩大规模的行动。
队列中的请求数 [qcur]
顾名思义,这是在队列中等待的请求的数量。当达到最大连接限制时,HAProxy将开始在内核套接字队列中排队请求。请求将停留在那里,直到达到队列的超时。
阈值:糟糕的qcur值意味着你的HAProxy处理请求的能力已经达到饱和,你的后端需要开始更快地提供请求。高的qcur会导致高的qtime。这是因为队列中的请求数量越多,每个请求在队列中花费的时间就越多。
系统指标
监控你的系统资源也很重要,因为管理不善会引起HAProxy服务器的错误或延迟。
有几个系统指标你应该监测,包括:
平均负荷
这是你的系统正在运行的平均负荷。简单地说,它是等待CPU时间的进程数量。负载平均数有1分钟、5分钟和15分钟的平均数。
阈值:负载平均值在CPU数量的1.5-2倍范围内就可以了。如果该值超过该限制,则有很多进程没有得到CPU时间。如果你的CPU处于负载状态,你可能需要垂直扩展你的机器,或者在你的集群中添加更多的HAProxy服务器。
内存
内存是你的应用程序或服务器所使用的RAM数量。
阈值:高内存使用率会影响你的系统性能,迫使系统交换或抛出内存不足(OOM)的错误。
网络I/O
这是在你的系统的网络堆栈中传输和接收数据的速度。
阈值:网络I/O不应该达到你的机器支持的网络带宽的极限。
存储
这是你系统中的磁盘消耗量。
阈值:如果存储达到100%,你系统中运行的很多进程就会停止。你应该设置一个警报,当存储达到90%左右时通知你。
顶级HAProxy监控工具
现在我们已经确定了需要测量的最重要的HAProxy指标,让我们来看看你可以用来跟踪它们的最好的HAProxy监控工具。
1.Sematext监控
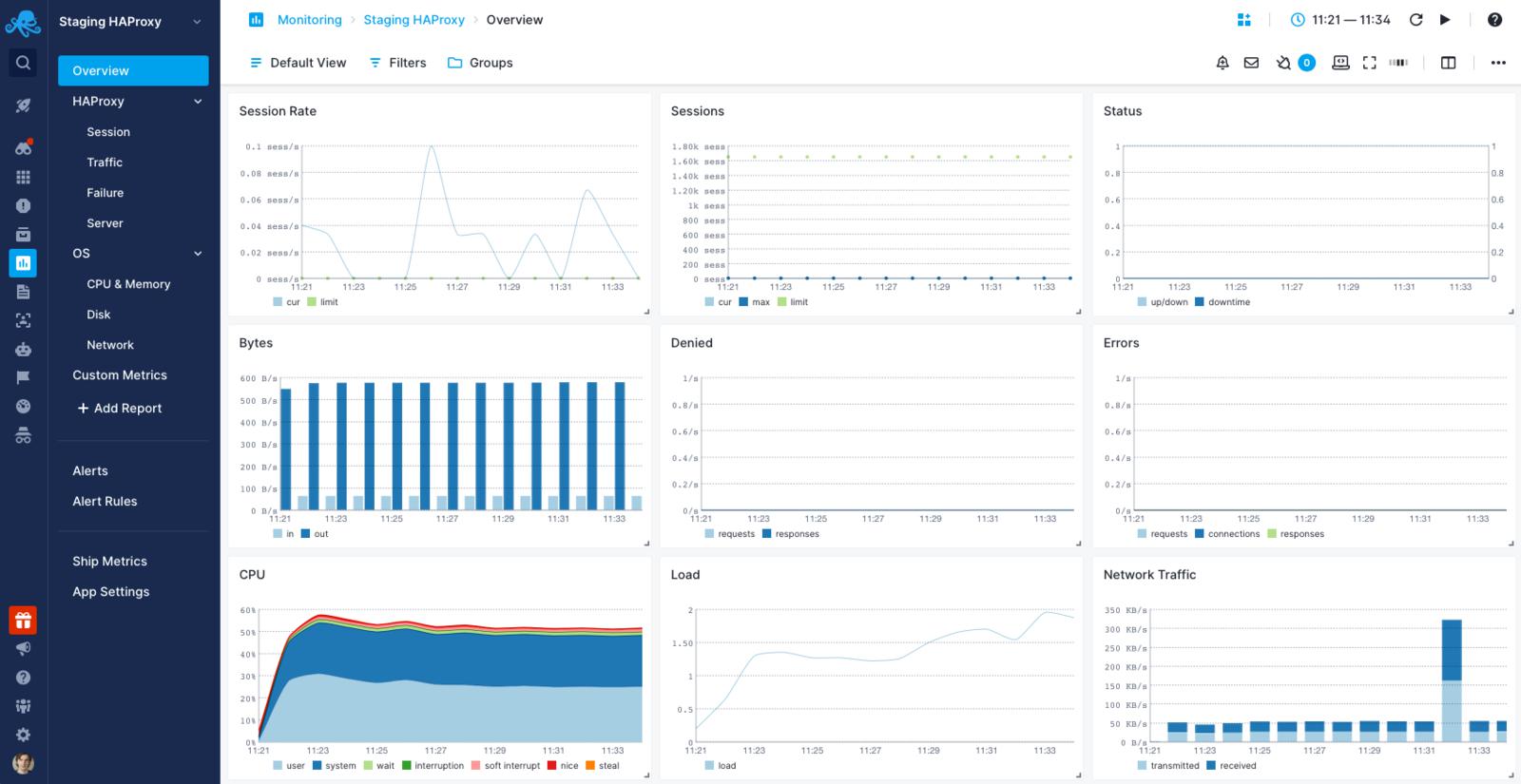
Sematext Monitoring是一个SaaS解决方案,提供一套全面的HAProxy监控工具,以确保最佳系统性能。它提供HAProxy前端、后端和健康检查指标,包括请求率、错误、拒绝的请求和HTTP错误代码。
Sematext的异常检测功能使你能够找出HAProxy指标中任何突然变化的原因。它提供与容器化环境和一些通知渠道的整合,包括电子邮件、Slack、PagerDuty等。该工具允许你将HAProxy的统计数据与基础设施的其他组件相关联,包括服务器和数据库,让你对你的IT环境有一个全面的了解。
优点
- 开箱即用,为HAProxy预制了仪表板
- 自动发现HAProxy
- 支持HAProxy的日志记录
- 支持AWS、Azure和Amazon ECS上的Kubernetes。
缺点
- 没有自我托管的解决方案
- 没有年度定价模式,尽管你可以创建一个捆绑包以节省费用
定价
监测的标准价格是每个代理、每个主机每月3.60美元。专业级的费用是每个代理,每个主机,每月5.76美元。还有14天的免费试用,你可以免费使用5台主机,保留30分钟。
2.普罗米修斯和Grafana
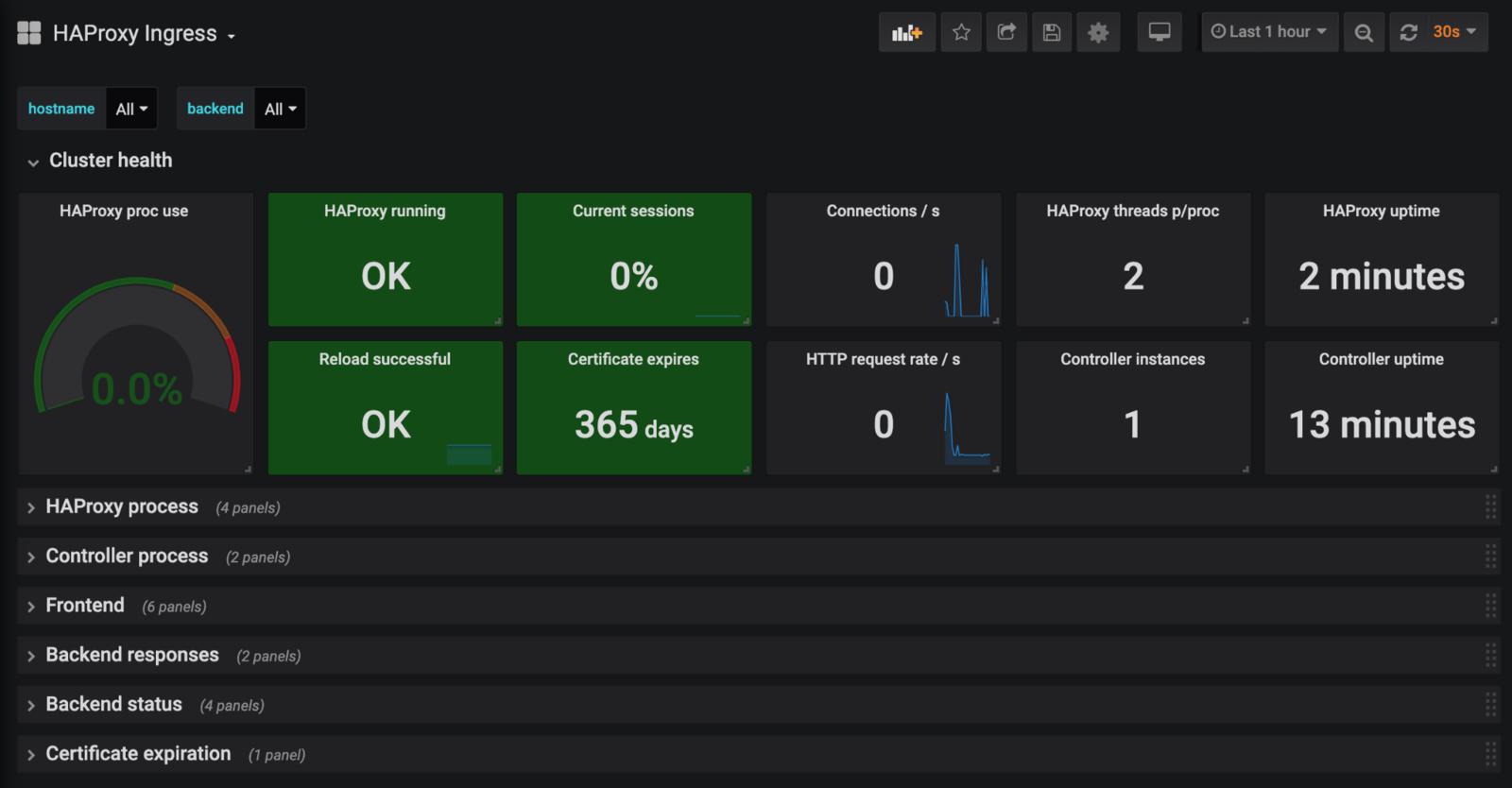
Prometheus是一个时间序列数据库,通常与可视化工具Grafana结合,为各种系统(包括HAProxy)创建一个强大的开源监控解决方案。普罗米修斯的主要优势在于它周围的生态系统和工具。还有一个巨大的Prometheus社区,大多数工具都输出Prometheus支持的指标,包括HAproxy。
Prometheus为你提供前端、后端和健康检查的HAProxy指标,而Grafana有一个预建的仪表盘,你可以用来绘制这些指标。虽然有HAProxy的导出器可以暴露指标,但HAProxy也有对Prometheus指标的本地支持。通过Prometheus,你可以提取任何支持导出器的基础设施组件的指标,或者自己编写一个导出器。
优点
- 强大的普罗米修斯查询语言;可以用警报管理器定制这些查询的警报
- 开源社区提供预建和定制的仪表板
- 识别HAProxy盒子的服务发现机制
缺点
- 难以管理多个组件
- 不支持HAProxy日志关联、异常检测等。
价格
Prometheus + Grafana是免费和开源的,但你必须为运行它们的机器,以及学习、实施和维护费用付费。
3.3.Dynatrace
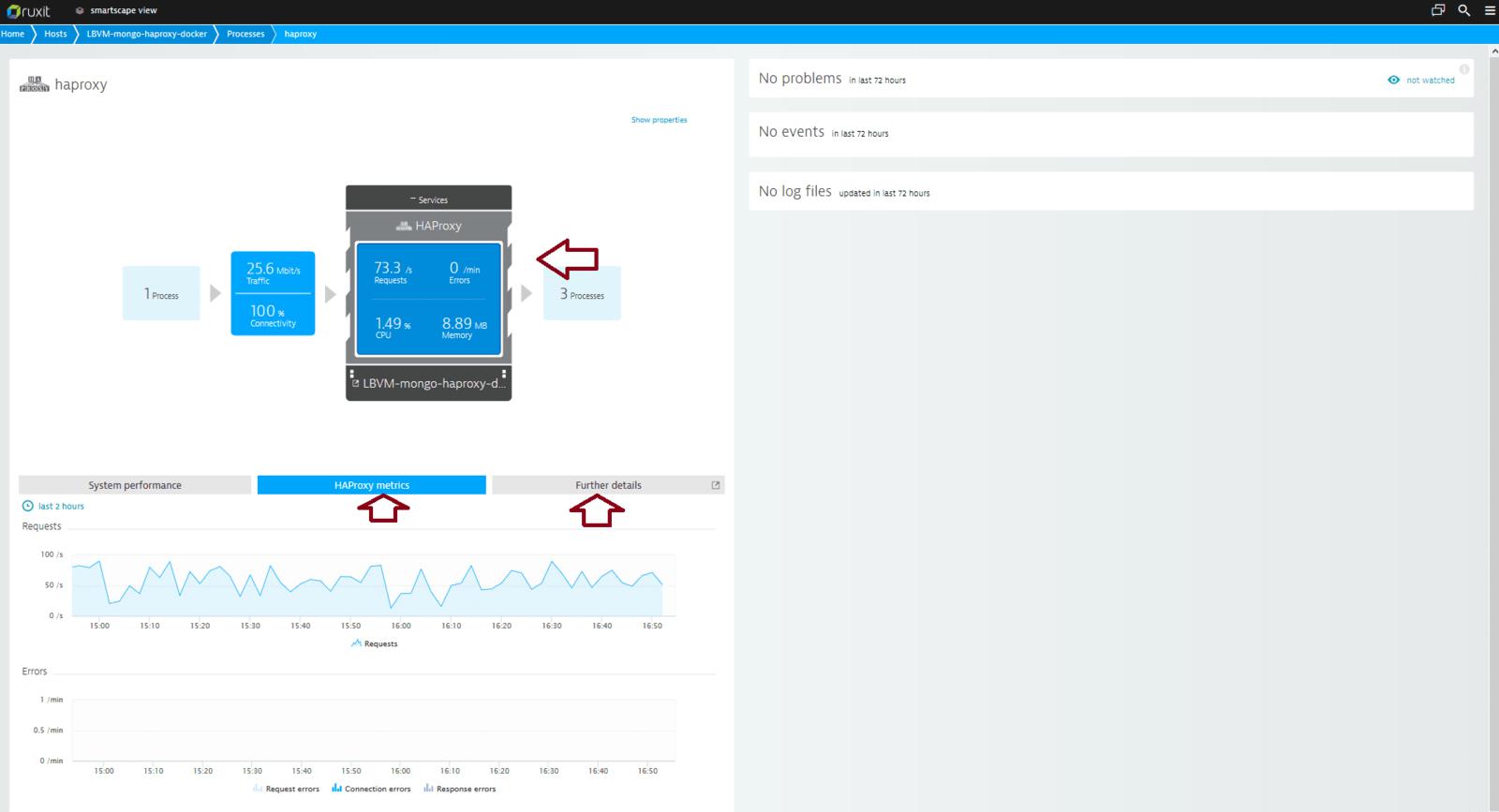
Dynatrace[c][d][e]是一个基础设施监控软件,包括一个集成插件,用于监控不同工具的健康和性能,包括HAProxy。Dynatrace可以监控你的基础设施、网络和进程。它还有一个移动应用程序,这在监控工具中是独一无二的,即使你在移动中,也很容易看到。
Dynatrace支持所有HAProxy指标,包括请求率、错误连接和HTTPS状态代码。它具有HAProxy异常检测功能,如果发生意外事件,它将向你发出警报,以及用于查看指标和警报的仪表盘。它可以向电子邮件、Slack、PagerDuty等发送警报,并支持容器。如果你不想要一个托管的解决方案,你也可以将Dynatrace托管在企业内部。
优点
- 支持HTTP以及Socket模式的指标收集
- 预先为HAProxy的指标建立仪表盘
- 自动发现HAProxy盒子
缺点
- 支持容器,但缺乏基于Kubernetes部署的文档
- 没有关于HAProxy的指标和日志相关性的文档
价格
基础设施监测费用为每月21美元,每台主机8GB的数据。全栈监控费用为每月69美元,每台主机8GB数据。还有一个15天的免费试用,以及一个按主机定价的模式。
4.4.Datadog
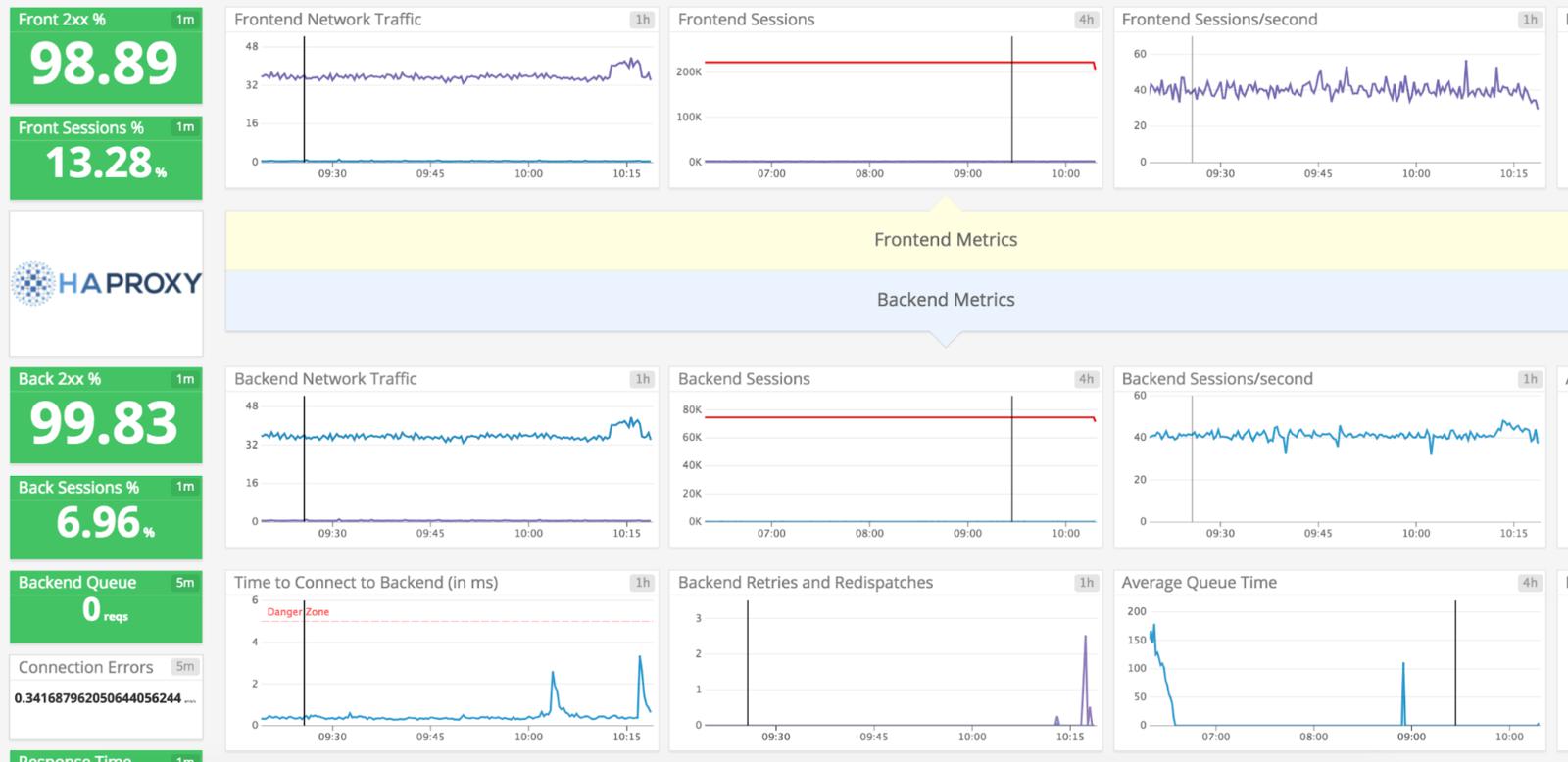
Datadog是一个基于SaaS的应用程序和基础设施监控解决方案,可以从HAProxy Prometheus端点、HTTP接口或套接字接口提取指标。它可以存储、可视化和关联各种HAProxy指标,如请求率、错误连接、状态代码、拒绝请求和HAproxy日志。
Datadog支持监控部署在Kubernetes、Amazon ECS、物理主机或基于Docker环境的HAProxy。你将会得到基于自定义指标的警报,并可以将警报转发给电子邮件、Slack、PagerDuty和其他平台。
优点
- 自动发现HAProxy盒子
- HAProxy的指标和日志的相关性
- 在一个地方对所有HAProxy盒子进行全景观察
缺点
- 相对来说比较昂贵
- 与HAProxy的整合有多个步骤(你必须首先在代理中进行修改,然后在仪表盘上启用它)
价格
专业级的价格是每个主机每月15美元。Datadog还提供14天的免费试用。
5.Zabbix
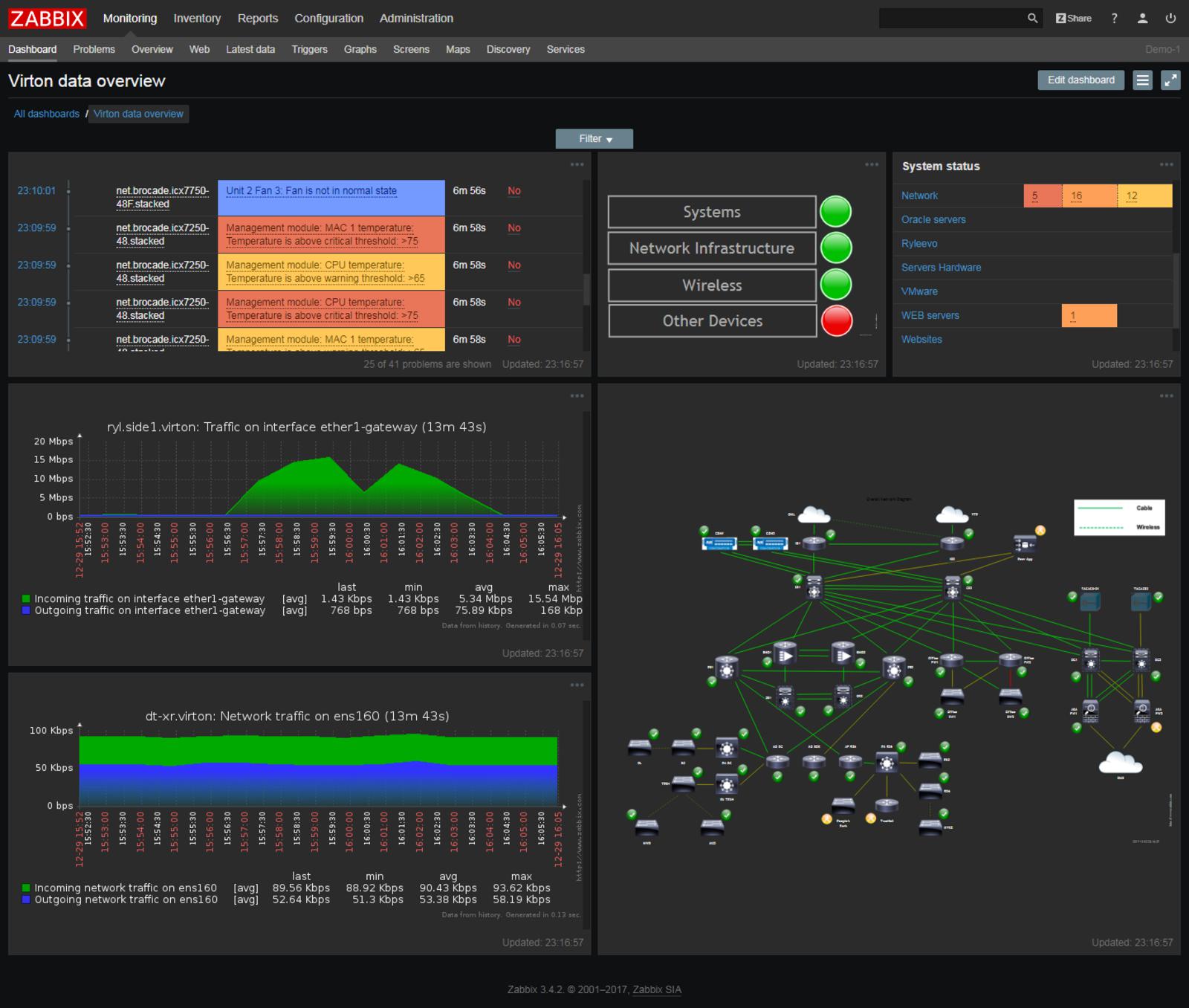
Zabbix是一个开源的网络和基础设施监控工具,支持HAProxy监控。它是非常可定制的,允许你编写自己的脚本,以更详细和细化的方式执行监测任务。该解决方案使你能够测量使用HTTP以及套接字接口发出的HAProxy指标。所有的指标都可以被消耗并用于绘制仪表盘。
因为Zabbix是一个开源的解决方案,你必须自己运行和管理它。在大规模运行时,你可能会看到与Prometheus和Grafana相同的限制,而且你需要决定使用哪种仪表盘,因为有很多选择。
优点
- 支持趋势预测,这有助于你决定何时扩展你的基础设施
- HAProxy的第三方模板和仪表盘
- 使用脚本定制的许多选项
缺点
- 没有对容器化环境(Kubernetes、Amazon ECS等)的本地支持
- 没有日志和指标的相关性
价格
Zabbix是免费的,但你确实需要时间来学习、部署和维护它。你还需要为你要部署的机器付费。
6.管理引擎
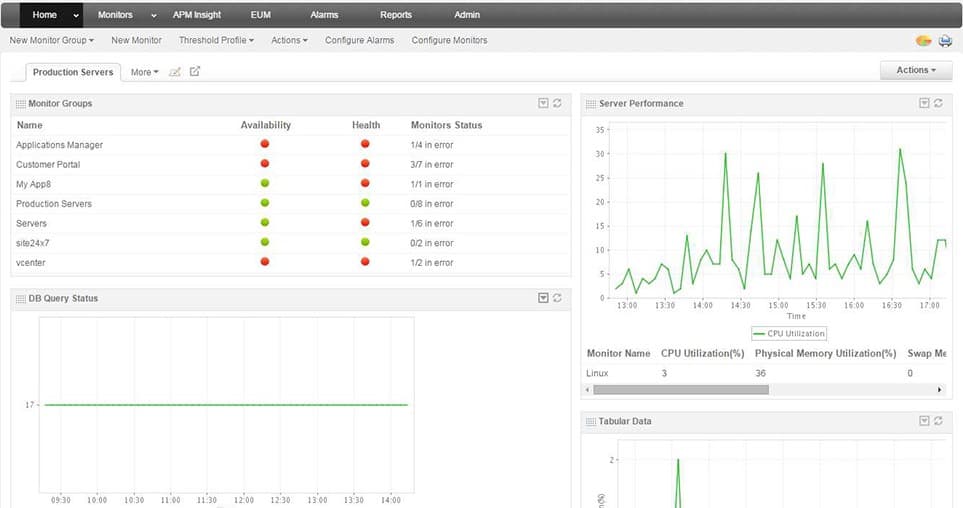
ManageEngine是一个用于管理基础设施的企业工具。它提供了各种各样的服务,包括支持监控HAProxy性能指标和跟踪问题的票据系统。它还可以促进自动补丁管理。你可以使用ManageEngine来跟踪和关联后端和前端的HAProxy指标,如ECON、请求率和HTTPS状态代码。
ManageEngine允许你为异常情况设置警报,并向电子邮件和许多其他渠道发送通知。为了对你的基础设施有一个全面的了解,你可以汇总健康指标。
优点
- 支持可定制的仪表板
- 热点检测
- 支持与REST APIs的良好整合
缺点
- 不支持与日志相关的指标
- 提供对Kubernetes的支持,但不支持HAProxy监控,因为如果作为入口控制器使用,对Kubernetes的监控尤为重要。
价格
ManageEngine每年的费用为395美元,用于10个服务监控。企业版起价为每年9595美元,用于250个监控器,并随着你增加监控器的数量而增加。
7.7.Site24x7
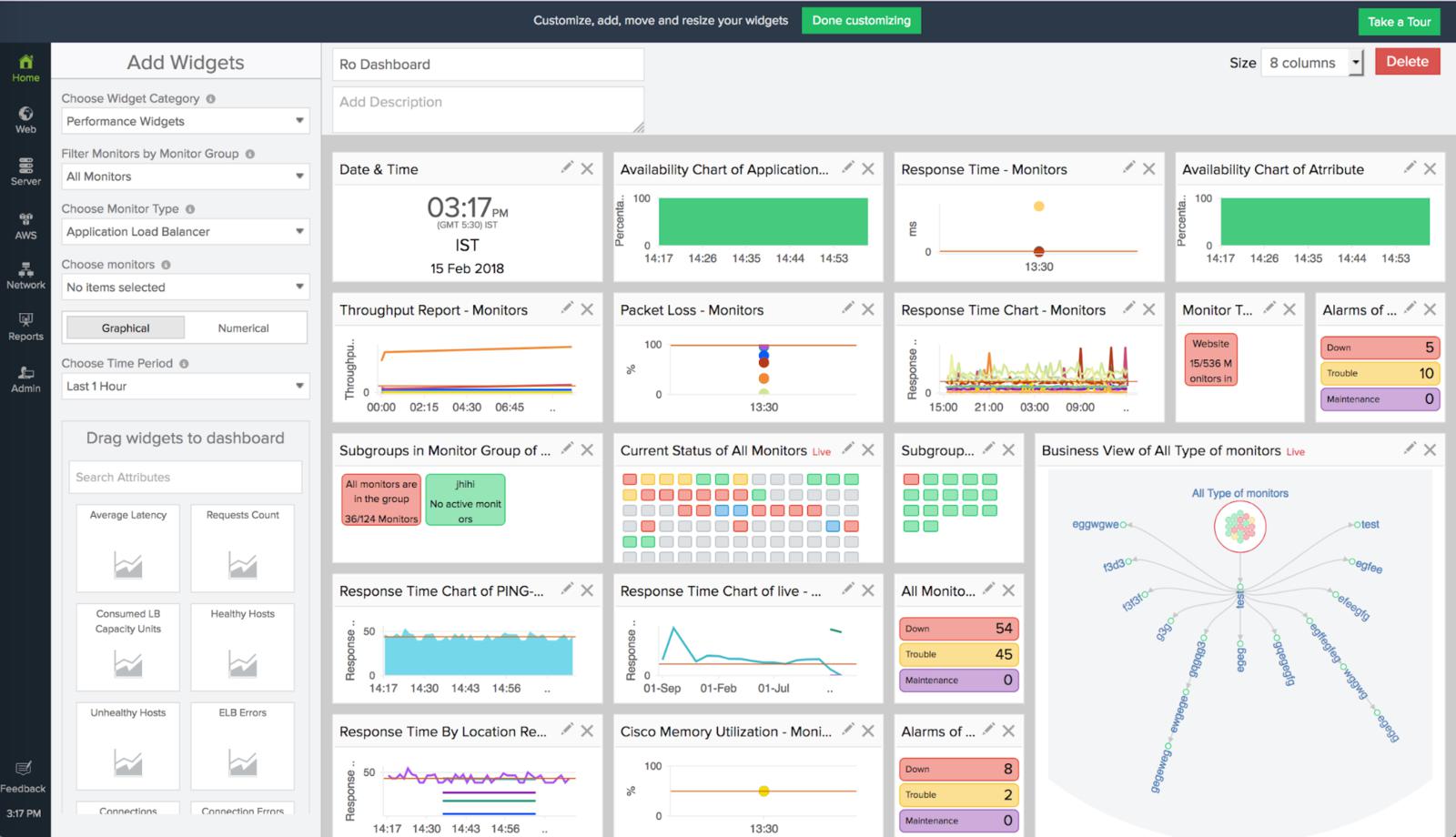
Site24x7是一个SaaS工具,具有使用Socket模式或HTTP模式监测HAProxy指标的高级功能。它还提供有用的功能,如网页诊断,SSL/TLS证书监控,以及FTP、POP、SMTP和IMAP监控。你可以使用Site 24×7来提取和绘制包括请求率、平均响应时间、HTTP状态代码等指标的仪表板。
Site24x7可以对不同的指标发出警报,并将这些通知发送到电子邮件、PagerDuty等渠道。你也可以用它来监控你的网络和其他基础设施组件。
优点
- 预先建立的仪表板和对自定义仪表板的支持
- 自动发现HAProxy盒子
- 支持HAProxy日志管理和监控
- 与本列表中的其他工具相比,试用期最长。
缺点
- 没有支持Kubernetes或Amazon ECS等容器化环境的文档
- 需要安装Python才能使代理工作
价格
Site24x7十台服务器的价格为10美元。你可以以10、50和500的倍数添加更多的服务器到你的软件包。也有30天的免费试用。
哪种HAProxy监控方案最适合你?
本文讨论的所有解决方案都支持HAProxy所提供的几乎所有指标。区别在于成本、发现机制和对容器化环境的支持等因素。在选择HAProxy监控工具时,需要寻找的主要功能之一是日志与指标的关联性。这让你有能力更快排除问题并提出解决方案。
如果你正在寻找一个开源的解决方案,Prometheus + Grafana是一个不错的选择。然而,Prometheus + Grafana和Zabbix都缺乏异常检测以及日志和指标关联等功能。Datadog和Dynatrace提供大部分功能,但都是非常昂贵的企业解决方案。
