

1. 分治法 D&C
1.1 什么是分治法?
分治法(divide and conquer,D&C)是一种算法思想,面对许多有一定规模的问题时,我们很难直接对其进行求解,这时候就需要考虑能否对其分而治之。
通过把一个复杂的问题,分解成有限个相同的子问题,再把分解的子问题继续分解,经过不断地缩小问题的规模,子问题的规模已经被缩小到能被我们直接求解,把所有子问题的解合并起来,就是原问题的解。
1.2 分治法如何解决问题?
分治法的基本思想:把一个大规模的问题化成有限个易求解的子问题,再把子问题的解合并,就得到了原问题的解。
这里我们通过一个问题,来更好地理解这段话。这个问题就是如何将一块1680x640长方形,分成若干个正方形,并且这些正方形要足够地大。
如何将一块地均匀地分成正方形,并确保分出的正方形是最大的呢?这里就可以使用分治法来解决。
使用分治法解决问题包括两个步骤:
- 找出基线条件。基线条件就意味着问题在这种条件下已经容易求解,可以直接计算出答案。
- 不断将问题分解,缩小问题的规模,直到符合基线条件。
下面我们就遵循这两个步骤,使用分治法来对这个问题进行求解:
首先,找出基线条件。
想要找出基线条件,我们需要思考的是,在什么情况下,能够非常容易地求出问题的答案?对于这个问题,很明显,当矩形的一边是另一边的整数倍时,我们能够非常容易地得到解。例如,矩形的一条边长为nx,另一条边为x,显然此时的解就是将这个矩形分成边长为x的正方形。
找出基线条件后,我们需要做的就是不断缩小问题的规模。我们把需要继续分解时的条件称为递归条件。对于这个问题,我们如何缩小问题的规模呢?首先,我们可以找出这个矩形可以容纳的最大正方形。
现在,我们就只需要找出640x400这个矩形可以容纳的最大正方形,就能够得到整个矩形的解,也就是说,我们已经将问题的规模从1680缩小到了640。接下来,我们只需要继续对640x400这个矩形重复这个过程,就可以将规模不断缩小,直到符合基线条件,也就是矩形长是宽的整数倍,最后这个基线条件的解,就是整个矩形的解。
这个问题的代码实现如下:
package com.frontend.day41;
/**
* @Classname Demo1
* @Description 分解矩形
* @Date 2022/7/17 19:30
* @Created by Yang Yi-zhou
*/
public class Demo1 {
public static int findMaxSquare(int l, int aol) {
int length = Math.max(l, aol);
int width = Math.min(l, aol);
//基线条件
if (length % width == 0) {
return width;
}
//递归条件
return findMaxSquare(length % width, width);
}
public static void main(String[] args) {
System.out.println(findMaxSquare(1680, 640));
}
}
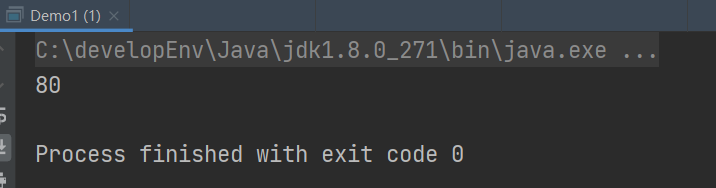
可以求出,最后的解为80,也就是这个1680x640的矩形可以均匀分解成若干个正方形的最大的边长的是80。
总之,分治法的解决问题的步骤就是:
- 找出简单的基线条件。
- 确定如何缩小问题的规模,使其符合基线条件。
1.3 分治法适用于什么问题?
分治法对于解决一些大规模问题十分有效,但他也不是万能的,当我们要使用分治法解决问题时,应该要满足一下几点:
- 当问题缩小到一定程度时,就可以很容易的求解。
- 该问题可以分解成若干个子问题,并且该问题和子问题应该时相同的问题。
- 子问题的解,可以得出原问题的解。
- 子问题应该是独立的。
第一条特征是绝大多数问题都可以满足的,因为问题的计算复杂性一般是随着问题规模的增加而增加。
第二条特征是应用分治法的前提它也是大多数问题可以满足的,此特征反映了递归思想的应用。
第三条特征是关键,能否利用分治法完全取决于问题是否具有第三条特征,如果具备了第一条和第二条特征,而不具备第三条特征,则可以考虑用贪心法或动态规划法。
第四条特征涉及到分治法的效率,如果各子问题是不独立的则分治法要做许多不必要的工作,重复地解公共的子问题,此时虽然可用分治法,但一般用动态规划法较好。
注:常用的算法还有动态规划算法、贪心算法、回溯法、分支限界算法等。
2. 快速排序
2.1 快速排序的思想
有一个整数类型的数组,我们要对它进行排序,该怎么进行呢?
根据分治法的思想,首先,我们先找到对一个数组进行排序的基线条件。很明显,只有一个元素或者没有元素的时候,对一个数组排序时最容易的,因为它根本不需要排序。
- **基线条件1:**如果数组没有元素,或者只有一个元素,数组排序完成。
我们继续增加一个元素,要对有2个元素的数组进行排序同样很简单,只需要判断哪个元素比较大,大的元素排在小的元素之后,就完成了排序。
- **基线条件2:**如果数组有2个元素,直接比较排序。
现在继续增加一个元素,对于一个有3个元素的数组该怎么进行排序呢?似乎情况就有点复杂起来了,我们不能通过一次简单的计算就把数组排序好。回想前面分治法的思想,对于3个元素的数组,我们无法简单的就完成对它的排序,所以我们不如思考如何将它的问题规模缩小。
只要我们能够缩小问题的规模,直到符合基线条件,我们就可以很容易地对数组进行排序了。现在,对于3个元素的数组,只要我们能够把它转换成排序2个、1个或者没有元素的数组,我们就可以对其完成排序。快速排序正是基于这一理念来实现的。
2.2 快速排序的步骤
快速排序的原理就是,首先,从数组中选取一个元素,这个元素被叫做基准值(pivot)。
然后,找出所有比基准值小以及比基准值大的值,这个步骤叫做分区(partitioning)。
现在,你就有了:
- 一个所有元素都比基准值小的数组
- 基准值
- 一个所有元素都比基准值大的数组
注意这里我们只是进行了分区,两个子数组仍然是无序的,但是我们假设这两个子数组是有序的,那么现在对整个子数组的排序就十分容易了——只需要把合并两个子数组和基准值,我们就完成了对于整个数组的排序。
如何对子数组进行排序呢?
- 对于元素小于等于2个的数组,也就是符合基线条件的数组,快速排序已经知道了如何对它进行排序
- 对于元素大于2个的数组,快速排序也知道了如何将它的规模缩小
因此,只要对这两个子数组进行快速排序,再合并结果,我们完成了对于整个数组的排序了。
2.3 快速排序的代码实现
实现步骤
快速排序的实现重点在于partitioning部分,这里我们采用双指针双向遍历的方式来实现,这种方式并不高效,但是易于理解。
我们以**{-1, 0, 4, -7, 14, 9}**这个整型数组为例,来模拟一下partitioning的过程。
这里,我们定义两个指针,一个low指针从左向右遍历,一个high指针从右向左遍历。
-
先使用数组的第一个元素作为pivot,pivot=-1,low指针指向数组第一个元素,high指针指向数组的最后一个元素
-
low、high指针开始遍历,找到比pivot大、小的值
-
交换low和high的值
-
再将low指针指向的值与pivot交换,就完成了一次分区。两个子数组分别为**{-7, 0}和{4, 14, 9}**,只需要再对这两个子数组进行快速排序,整个数组的排序就完成了。
代码细节
这里需要注意一个细节,low指针和high指针相遇时(没有重叠)遍历实际上就已经结束,但是在代码实现中,我们需要通过判断指针是否重叠来判断遍历是否结束,这里的问题就在于,是让low向右边多走一步与high重叠,还是让high向左多走一步与low重叠呢?(代码层面上,就是low指针和high指针谁先开始遍历)
事实上,low指针和high指针谁先开始遍历,要取决于我们的pivot取值,因为在low与high重叠后,最后一步就是要将low/high指针指向的元素与pivot元素交换,来实现分区。所以可以有如下两个逻辑:
- 如果pivot的值取的是数组的第一个元素,而这个位置最后属于偏小子数组,所以low/high指针,最后也应该指向小数组的最右端,也就是应该让high指针先走,才能够保证最后pivot左边的值都比pivot小
- 如果pivot的值取得是数组得最后一个元素,同理,这个位置最后属于偏大子数组,所以最后low/high指针应该指向大数组得最左端,也就是应该让low指针先走
总结一下就是:
- 左端作pivot,先从右端开始遍历
- 右端作pivot,先从左端开始遍历
代码实现
package com.frontend.day41.demo;
import java.util.Arrays;
/**
* @Classname QuickSort
* @Description
* @Date 2022/7/17 21:27
* @Created by Yang Yi-zhou
*/
public class QuickSort {
public static void main(String[] args) {
int[] arr = {-1, 0, 4, -7, 14, 9};
System.out.println(Arrays.toString(arr));
sort(arr);
System.out.println(Arrays.toString(arr));
}
public static void sort(int[] arr) {
partitioning(arr, 0, arr.length - 1);
}
public static void partitioning(int[] arr, int low, int high) {
//基线条件
if (high - low < 1) {
return;
}
if (high - low == 1) {
if (arr[low] > arr[high]) {
swap(arr, low, high);
}
return;
}
//标记头、尾
int left = low;
int right = high;
int pivot = arr[left];
//递归条件
while (low < high) {
while (low < high && arr[high] >= pivot) {
high--;
}
while (low < high && arr[low] <= pivot) {
low++;
}
swap(arr, low, high);
}
swap(arr, left, low);
partitioning(arr, left, low - 1);
partitioning(arr, low + 1, right);
}
private static void swap(int[] arr, int low, int high) {
int temp = arr[low];
arr[low] = arr[high];
arr[high] = temp;
}
}
运行结果:
3. 总结
- 分治算法的步骤:
- 找出简单的基线条件。
- 确定如何缩小问题的规模,使其符合基线条件。
- 分治算法的核心:
- 如何分,也就是如何缩小问题的规模
- 分治法的重要应用:
- 快速排序是如何实现的
- 双指针双向遍历中,哪个指针先走?
- 左端作pivot,先从右端开始遍历
- 右端作pivot,先从左端开始遍历
