

深度学习模型在计算机视觉任务中的成功,如图像分类、语义分割、物体检测等,归功于利用了大量用于训练网络的标记数据--这种方法被称为监督学习。尽管在这个信息技术时代有大量的非结构化数据,但标注的数据却很难得到。
由于这个原因,数据标注占据了计算机视觉机器学习项目的大部分时间,而且也是一项昂贵的工作。此外,在医疗保健等领域,只有专业的医生才能对数据进行分类--例如,看看下面这两张宫颈细胞学的图片,你能明确地说哪张是癌症吗?

来源。SIPaKMeD数据集
大多数未经训练的医学专家不会知道答案--(a)是癌症,而(b)是良性。所以,在这种情况下,数据标签是比较困难的。在最好的情况下,我们只有少数几个有注释的样本,这还不足以训练监督学习模型。
另外,较新的数据可能会随着时间的推移而逐渐获得--比如新识别的鸟类物种的数据可能会被获得。在大型数据集上训练深度神经网络会消耗大量的计算能力(例如,ResNet-200在8个GPU上花了大约三周时间来训练)。因此,在大多数情况下,不得不重新训练模型以适应新的可用数据是不可行的。
这就是相对较新的 "少量学习 "概念的由来。
什么是Few-Shot学习?
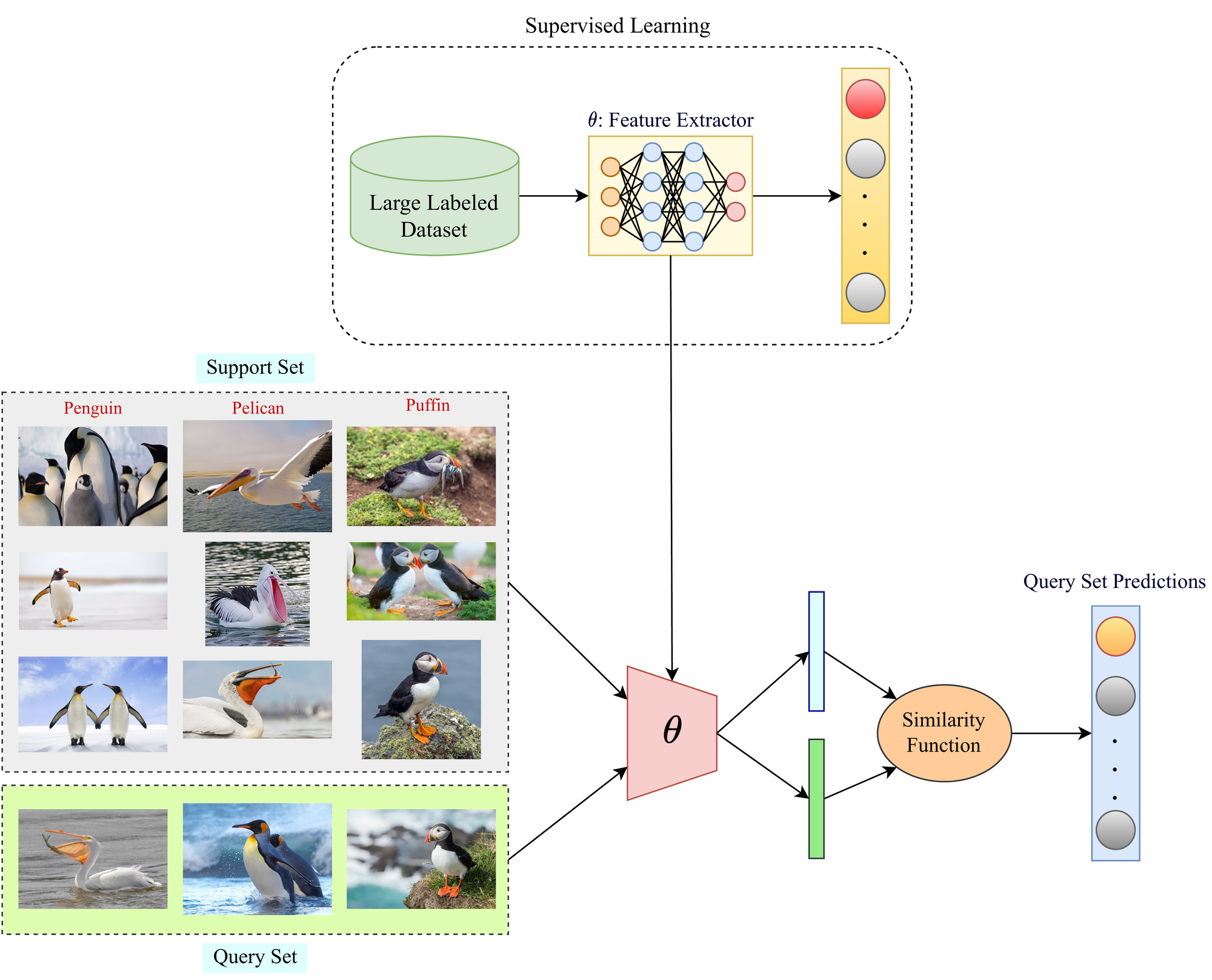
Few-Shot Learning(FSL)是一个机器学习框架,它使预先训练好的模型能够在新的数据类别(预先训练好的模型在训练期间没有见过)上进行泛化,每个类别只使用几个标记的样本。它属于元学习的范式(元学习意味着学习学习)。
Few-Shot学习框架的总体概况。图片由作者提供
我们人类能够利用以前学到的知识,只用几个例子就能轻松识别新的数据类别。FSL旨在模仿同样的情况。这被称为元学习,用一个例子可以更好地理解它。
假设你第一次去一个外来的动物园,你看到了一种你以前从未见过的特殊鸟类。现在,你得到了一套三张卡片,每张卡片包含两张不同种类的鸟的图像。通过看到卡片上每个物种的图像和动物园里的鸟,你就能很容易地推断出鸟的种类,使用的信息包括羽毛的颜色、尾巴的长度,等等。在这里,你通过使用一些辅助信息,自己学会了鸟的种类。这就是元学习试图模仿的东西。
与少数人学习有关的重要术语
让我们讨论一下与FSL文献相关的几个常用术语,这将有助于对该主题的进一步讨论。
**支持集。**支持集由每个新的数据类别的少数标记样本组成,预先训练好的模型将使用这些新的类别进行归纳。
**查询集。**查询集由新旧两类数据的样本组成,模型需要利用以前的知识和从支持集获得的信息对其进行归纳。
N-way K-shot学习方案。这是FSL文献中的一个常用短语,它基本上描述了一个模型将要处理的少量问题陈述。"N-way"表示有 "N"个新的类别,一个预先训练好的模型需要对其进行概括。K"-shot定义了支持集中每个 "N"个新类别的可用标记样本的数量。K"值越低,少量的任务就越困难(也就是说,准确率越低),因为可用于推断的支持信息越少。
"K"值通常在1到5的范围内。K=1的任务被命名为 "一次性学习",因为它们特别难以解决。我们将在本文的后面讨论它们。K=0也是可能的,这被称为 "零枪学习"。零枪学习与所有其他的零枪学习方法有很大不同(因为它属于无监督学习范式)。因此,我们将不在本文中讨论它们。
为什么是 "少许 "学习?
传统的监督学习方法使用大量的标记数据进行训练。此外,测试集包括的数据样本不仅与训练集属于同一类别,而且必须来自类似的统计分布。例如,由手机拍摄的图像创建的数据集与由先进的单反相机拍摄的图像创建的数据集在统计学上是不同的。这就是俗称的领域转移。
Few-Shot Learning通过以下方式缓解了上述问题。
- 训练模型时不需要大量昂贵的标记数据,因为顾名思义,其目的是只用少数标记的样本来进行泛化。
- 由于一个预先训练好的模型(一个在广泛的数据集上训练过的模型,例如在ImageNet上)可以扩展到新的数据类别,因此不需要从头开始重新训练一个模型,这就节省了大量的计算能力。
- 使用FSL,模型也可以在只接触到有限的先验信息的情况下学习稀有类别的数据。例如,来自濒危或新发现的动物/植物物种的数据很稀少,这就足以训练FSL模型了。
- 即使该模型已经使用统计学上不同的数据分布进行了预训练,只要支持集和查询集的数据是一致的,它也可以用来扩展到其他数据领域。
Few-Shot学习是如何工作的?
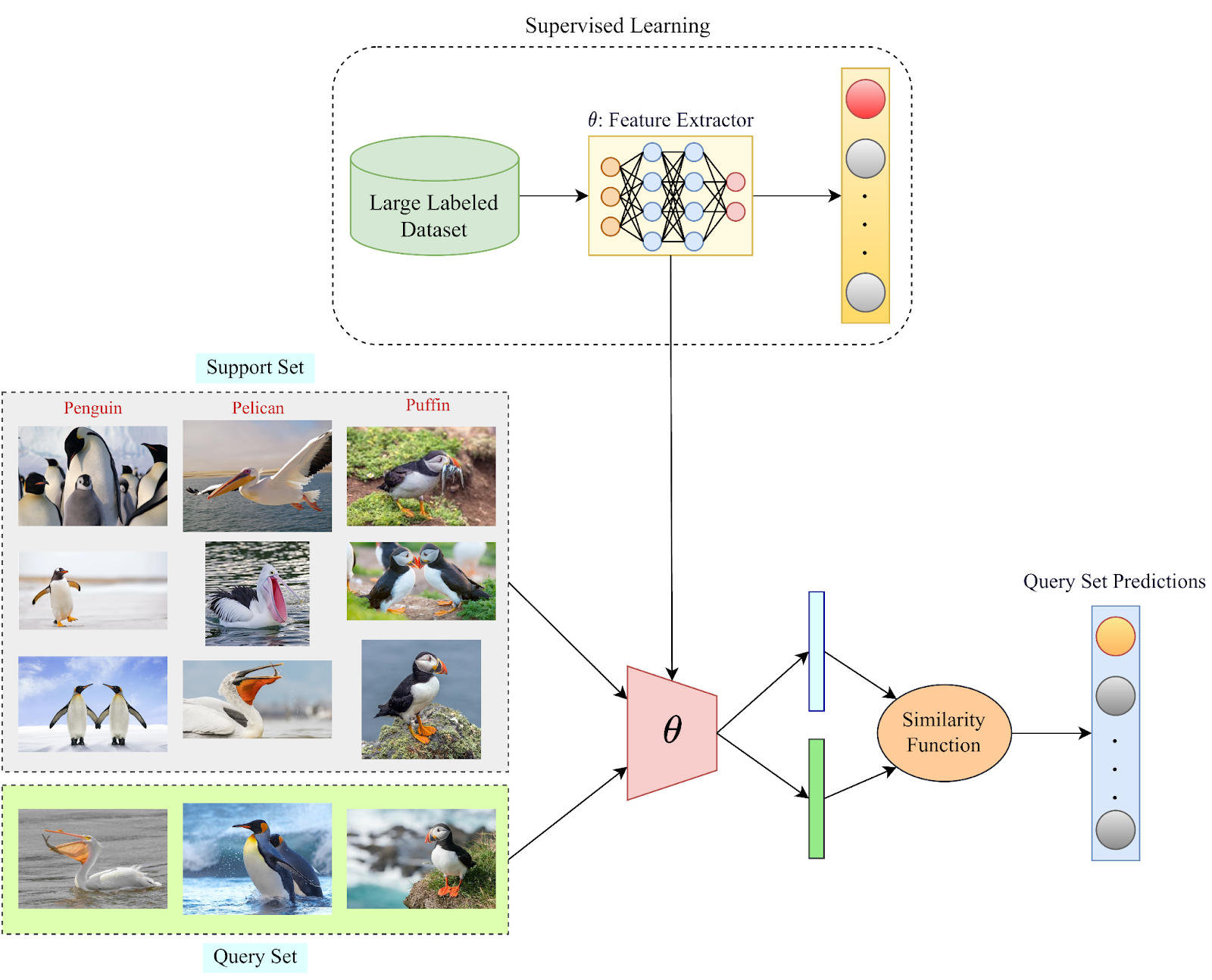
传统的Few-Shot框架的主要目标是学习一个相似性函数,该函数可以映射支持集和查询集中的类之间的相似性。相似性函数通常为相似性输出一个概率值。

Few-Shot学习中相似性测量的理想场景。图片由作者提供
例如,在下面的图片中,一个完美的相似性函数在比较两张猫的图片(I1和I2)时应该输出1.0的值。对于另外两种情况,即猫的图像与猫的图像相比较,相似度输出应该是0.0。然而,这只是一个理想的情况。在现实中,I1和I2的值可能是0.95,而其他两种情况下的值可能比0大一些(比如0.02和0.03)。
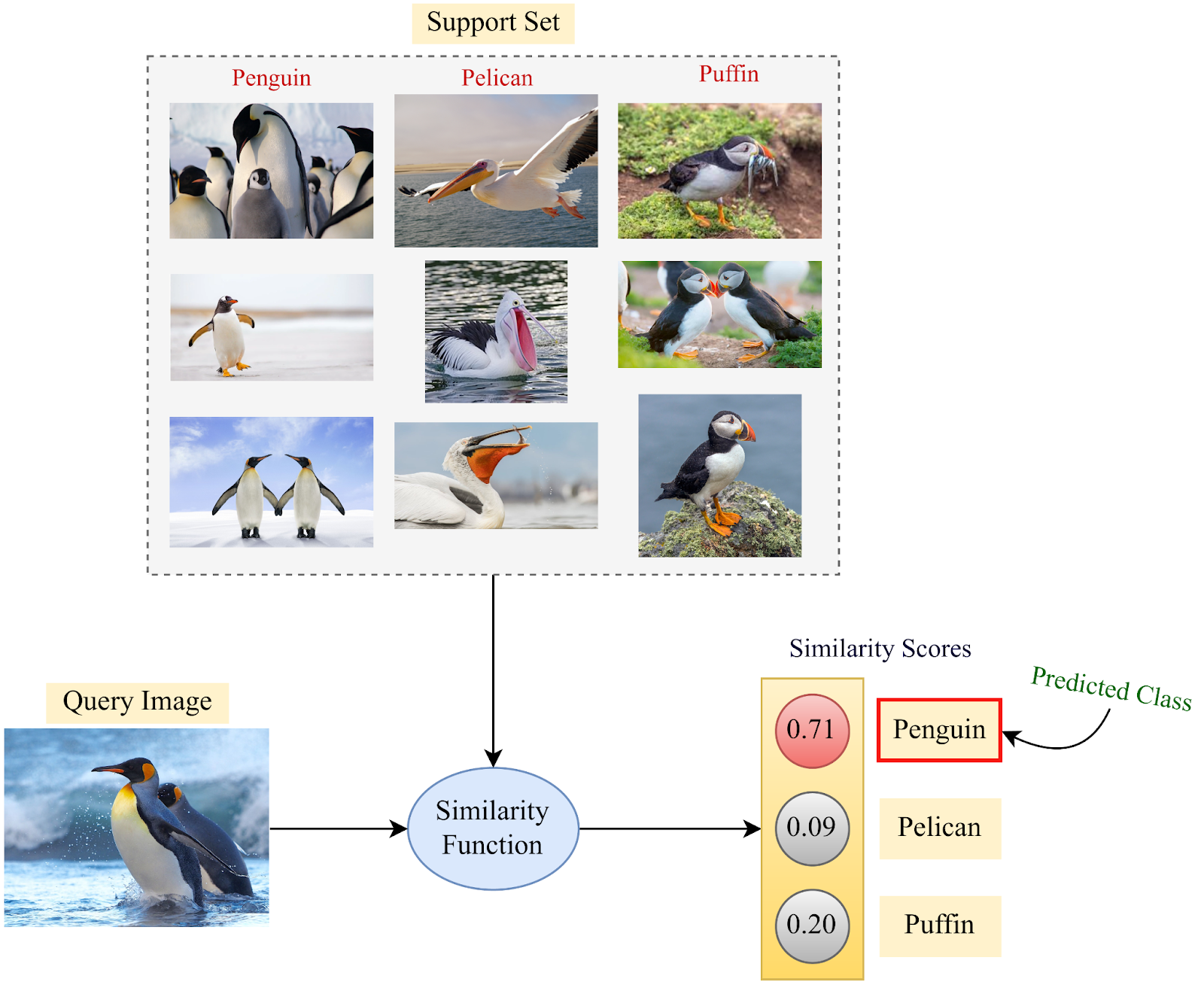
Few-Shot模型如何进行预测的概述。图片由作者提供
现在,我们使用一个大规模的标记数据集来训练这样一个相似性函数的参数。用于以监督的方式预训练深度模型的训练集可用于此目的。一旦相似性函数的参数被训练出来,它就可以被用于 "少数人学习 "阶段,通过使用支持集信息来确定查询集的相似性概率。然后,对于每个查询集样本,支持集中相似度最高的类别将被推断为Few-Shot模型的类别标签预测。上面就是这样一个例子。
连体网络
在Few-Shot学习文献中,相似性函数根本不需要是 "函数"。它们也可以是,而且通常是神经网络:其中最流行的例子是连体网络。这个名字来自于 "连体婴儿 "在物理上相连的事实。与传统的神经网络不同,它有一个输入分支和一个输出分支,连体网络有两个或三个输入分支(基于训练方法)和一个输出分支。
有两种方法来训练连体网络,我们接下来将讨论。
方法一:配对相似性
在这种方法中,一个连体网络被赋予两个输入以及它们相应的标签(采用用于预训练特征提取器的训练集)。在这里,首先,我们从数据集中随机选择一个样本(例如,我们选择一只狗的图像)。然后,我们再次从数据集中随机选择一个样本。如果第二个样本与第一个样本属于同一类别,也就是说,如果第二个图像又是一只狗,那么我们就为连体婴网络分配一个 "1.0 "的标签作为基础事实。对于所有其他类别,则指定 "0.0 "的标签作为基础事实。

连体网络中学习配对相似性的概述。图片由作者提供
因此,这个网络本质上是通过标记的例子学习相似性匹配标准。上面已经用一个例子说明了这一点。图像首先分别通过相同的预训练的特征提取器(通常是卷积神经网络),以获得其相应的表示。然后,将获得的两个表征串联起来,通过密集层和一个sigmoid激活函数来获得相似度分数。我们已经知道样本是否属于同一类别,所以该信息被用作计算损失和计算反向传播的基础真实相似度分数。
在Python3中,两个样本之间的余弦相似度可以通过以下方式计算。
import torch
import torch.nn as nn
input1 = torch.randn(100, 128)
input2 = torch.randn(100, 128)
cos = nn.CosineSimilarity(dim=1, eps=1e-6)
output = cos(input1, input2)
为了得到图像以及它们是否属于同一类别的相应信息,需要在Python3中实现以下自定义数据集。
import random
from PIL import Image
import torchvision
import torchvision.datasets as datasets
import torchvision.transforms as transforms
from torch.utils.data import DataLoader, Dataset
import torchvision.utils
import torch
import torch.nn as nn
class SiameseDataset(Dataset):
def __init__(self,folder,transform=None):
self.folder = folder #type: torchvision.datasets.ImageFolder
self.transform = transform #type: torchvision.transforms
def __getitem__(self,index):
#Random image set as anchor
image0_tuple = random.choice(self.folder.imgs)
random_val = random.randint(0,1)
if random_val: #If random_val = 1, output a positive class sample
while True:
#Find "positive" Image
image1_tuple = random.choice(self.folder.imgs)
if image0_tuple[1] == image1_tuple[1]:
break
else: #If random_val = 0, output a negative class sample
while True:
#Find "negative" Image
image1_tuple = random.choice(self.folder.imgs)
if image0_tuple[1] != image1_tuple[1]:
break
image0 = Image.open(image0_tuple[0])
image1 = Image.open(image1_tuple[0])
image0 = image0.convert("L")
image1 = image1.convert("L")
if self.transform is not None:
image0 = self.transform(image0)
image1 = self.transform(image1)
#Return the two images along with the information of whether they belong to the same class
return image0, image1, int(random_val)
def __len__(self):
return len(self.folder.imgs)
把这个项目带入生活
方法-2:Triplet Loss
这个方法是基于 "三重损失 "标准的,可以认为是方法-1的延伸,尽管这里使用的训练策略不同。首先,我们从数据集(训练集)中随机选择一个数据样本,我们称之为 "锚 "样本。接下来,我们选择另外两个数据样本--一个来自与 "锚 "样本相同的类别,称为 "正 "样本,另一个来自与 "锚 "不同的类别,称为 "负 "样本。
一旦这三个样本被选中,它们就会通过同一个神经网络,以获得它们在嵌入空间中的相应表示。然后,我们计算锚和正面样本的表征之间的L2归一化距离(我们称之为 "d+"),以及锚和负面样本的嵌入之间的L2归一化距离(我们称之为 "d-")。这些参数允许我们定义一个需要最小化的损失函数,如下图所示。

连体网络训练的三重损失法概述。图片由作者提供
这里,">0 "是一个防止最大函数的两个项相等的余量。这里的目的是在嵌入空间中尽可能地推动锚和负样本的表示,同时尽可能地拉近锚和负样本的表示,如下所示。

嵌入空间中的数据样本的表征是如何对齐的例子。图片由作者提供
使用PyTorch,Triplet Loss可以非常容易地实现,如下所示(使用一个随机锚、正和负样本的例子)。
import torch
import torch.nn as nn
triplet_loss = nn.TripletMarginLoss(margin=1.0, p=2)
anchor = torch.randn(100, 128, requires_grad=True)
positive = torch.randn(100, 128, requires_grad=True)
negative = torch.randn(100, 128, requires_grad=True)
output = triplet_loss(anchor, positive, negative)
output.backward()
要使用PyTorch从图像数据集中生成锚、正和负样本,需要编写以下自定义数据集类。
import random
from PIL import Image
import torchvision
import torchvision.datasets as datasets
import torchvision.transforms as transforms
from torch.utils.data import DataLoader, Dataset
import torchvision.utils
import torch
import torch.nn as nn
class SiameseDataset(Dataset):
def __init__(self,folder,transform=None):
self.folder = folder #type: torchvision.datasets.ImageFolder
self.transform = transform #type: torchvision.transforms
def __getitem__(self,index):
#Random image set as anchor
anchor_tuple = random.choice(self.folder.imgs)
while True:
#Find "positive" Image
positive_tuple = random.choice(self.folder.imgs)
if anchor_tuple[1] == positive_tuple[1]:
break
while True:
#Find "negative" Image
negative_tuple = random.choice(self.folder.imgs)
if anchor_tuple[1] != negative_tuple[1]:
break
anchor = Image.open(anchor_tuple[0])
positive = Image.open(positive_tuple[0])
negative = Image.open(negative_tuple[0])
anchor = anchor.convert("L")
positive = positive.convert("L")
negative = negative.convert("L")
if self.transform is not None:
anchor = self.transform(anchor)
positive = self.transform(positive)
negative = self.transform(negative)
return anchor, positive, negative
def __len__(self):
return len(self.folder.imgs)
上述代码可以在Gradient中轻松实现。只需打开一个笔记本,在高级选项 "工作区URL "栏中填入以下URL即可。
[
GitHub - gradient-ai/few-shot-learning
通过在GitHub上创建一个账户,为gradient-ai/few-shot-learning的开发做出贡献。
GitHubgradient-ai
少数派学习的方法
寥寥无几的学习方法可以大致分为四类,我们将在接下来讨论。
数据层面
数据层面的FSL方法有一个简单的概念。如果一个FSL模型的训练由于缺乏训练数据而受阻(为了防止过拟合或欠拟合),可以添加更多的数据--这些数据可能是结构化的,也可能不是。也就是说,假设我们在支持集中每类有两个标记的样本,这可能是不够的,所以我们可以尝试使用各种技术来增加样本。
虽然数据增强本身并不提供全新的信息,但它仍然可以对FSL训练有所帮助。另一种方法是将未标记的数据添加到支持集中,使FSL问题变得半监督化。FSL模型甚至可以使用非结构化的数据来收集更多的信息,这已被证明可以提高几率的性能。
其他方法也旨在使用生成网络(如GAN模型),从现有的数据分布中合成全新的数据。然而,对于基于GAN的方法,需要大量的标记训练数据来首先训练模型的参数,然后才能利用少数支持集样本来生成新的样本。
参数层面
在FSL中,样本的可用性是有限的;因此,由于样本具有广泛和高维的空间,过度拟合是很常见的。参数级的FSL方法涉及到元学习的使用,控制模型参数的利用,以智能地推断出哪些特征对手头的工作是重要的。
限制参数空间和使用正则化技术的FSL方法属于参数级方法的范畴。模型被训练来寻找参数空间中的最佳路线,以提供目标预测。
度量级
度量级的FSL方法旨在学习数据点之间的距离函数。从图像中提取特征,并在嵌入空间中计算图像之间的距离。这个距离函数可以是欧几里得距离、地球移动距离、基于余弦相似度的距离等。这是我们在讨论连体网络时已经涉及的内容。
这种方法使距离函数能够使用训练集数据来调整其参数,这些数据已经被用于训练特征提取器模型。然后,距离函数将根据支持集和查询集之间的相似度分数(样本在嵌入空间中的接近程度)进行推断。
基于梯度的元学习
基于梯度的元学习方法使用两个学习者--一个教师模型(基础学习者)和一个使用知识提炼的学生模型(元学习者)。教师模型引导学生模型通过高维的参数空间。
使用来自支持集的信息,教师模型首先被训练来对查询集样本进行预测。来自教师模型的分类损失然后被用来训练学生模型,使其精通分类任务。
一次性学习
正如到此为止的讨论所表明的,单次学习是一项任务,支持集只包括每个类别的一个数据样本。你可以想象,在支持信息较少的情况下,这项任务会更加复杂。现代智能手机中使用的人脸识别技术就使用了单次学习。
其中一个例子是Shaban等人在本文中探讨的单次语义分割方法。作者提出了一种新颖的双分支方法,其中第一分支将标记的图像作为输入,并产生一个参数矢量作为输出。第二个分支将这些参数以及新的图像作为输入,并产生一个新类别的图像分割掩码作为输出。它们的结构图如下所示。
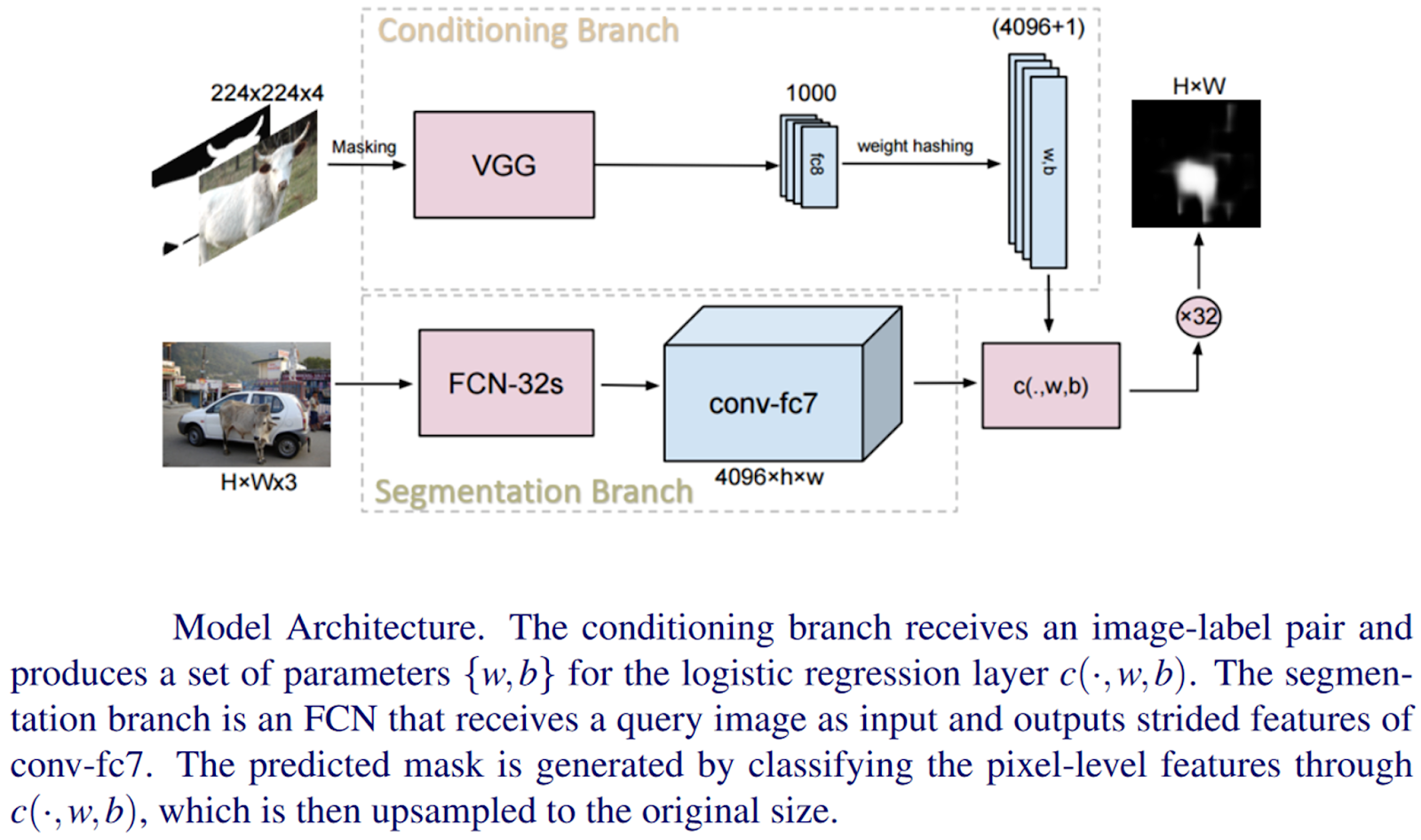
资料来源。论文
与单次学习的微调方法不同,可能需要多次迭代来学习分割网络的参数,该网络的第一个分支在一次正向传递中计算参数。这有几个优点。1)单次前向传递使得所提出的方法速度很快;2)单次学习的方法是完全可微分的,允许该分支与网络的分割分支联合训练;3)最后,参数的数量与图像的大小无关,所以单次方法在缩放方面没有问题。
少数派学习的应用
在深度学习文献中,Few-Shot学习已经被广泛用于多个领域,从计算机视觉任务,如图像分类和物体检测到遥感、自然语言处理等。让我们在本节中简单讨论一下。
图像分类
Few-Shot Learning已经被广泛用于图像分类,其中一些例子我们已经探讨过了。
Zhang等人在他们的论文中提出了一种有趣的Few-Shot图像分类的方法。比较两个复杂的结构化表征的一个自然方法是比较它们的构建块。困难在于,我们没有它们的对应监督来进行训练,而且不是所有的构建元素都能在其他结构中找到对应的内容。为了解决上述问题,作者在本文中把几张照片的分类形式化为最优匹配的一个实例。作者提出用两个结构之间的最优匹配成本来表示它们的相似性。

源于此。论文
鉴于两幅图像产生的特征表示,作者采用地球移动者距离(EMD)来计算它们的结构相似度。EMD是计算结构表征之间距离的指标,最初是为图像检索提出的。考虑到所有元素对之间的距离,EMD可以获得两个结构之间成本最小的最佳匹配流。它也可以被解释为用另一个结构表征重建的最小成本。
物体检测
对象检测是一个计算机视觉问题,即在图像或视频序列中识别和定位对象。一幅图像可能包含众多的物体。因此,它与简单的图像分类任务不同,后者是给整个图像贴上一个类别标签。
本文提出了OpeN-ended Centre nEt(ONCE)模型,以解决增量的Few-Shot Detection物体检测的问题。作者采取了基于特征的知识转移策略,将以前的模型CentreNet分解为类属和类属的组成部分,以实现增量式的少数镜头学习。更具体地说,ONCE首先使用丰富的基础类训练数据来训练一个类属特征提取器。随后是元学习,一个具有模拟几次学习任务的特定类别代码生成器。一旦训练完成,给定一个新的物体类别的少量图像,元训练的类别代码生成器优雅地使ONCE检测器在元测试阶段(新的类别注册)以有效的前馈方式渐进地学习新的类别。

资料来源。论文
语义分割
语义分割是一项任务,图像中的每个像素都被分配一个类别--要么是一个或多个物体,要么是背景。在文献中,Few-Shot Learning已经被用来进行二元和多标签语义分割。
Liu等人在本文中提出了一个新颖的基于原型的半监督式少数镜头语义分割框架,其主要思想是在两个方向上丰富语义类别的原型表示。首先,他们将常用的整体原型表征分解为一小部分意识到的原型集,这能够捕捉到多样化和细粒度的物体特征,并在语义物体区域产生更好的空间覆盖。此外,作者在他们的支持集中加入了一组未标记的图像,这样就可以从标记的和未标记的数据源中学习部分意识原型。这使他们能够超越有限的小型支持集,更好地模拟物体特征的类内变化。他们的模型的概述如下所示。

资料来源。论文
机器人学
机器人学领域也使用了Few-Shot学习方法,使机器人模仿人类只用几个示范就能概括任务的能力。
为了减少学习中的试验次数,Wu等人在本文中提出了一种算法来解决模仿中的 "如何 "问题。作者介绍了一种通过模仿学习路径规划的新型计算模型,该模型利用计划适应中的一个基本想法--在示范和给定情况下都存在不变的特征点--来为新的场景生成运动路径。
自然语言处理
少量学习最近在自然语言处理任务中也变得很流行,因为语言处理的标签本身就很难得到。
例如,Yu等人在他们的论文中,使用少数次学习,特别是元学习方法,解决了一个文本分类问题。他们的元学习器使用元训练任务的任务聚类,为学习目标任务选择并结合多种度量。在元训练过程中,作者建议将元训练任务划分为几个群组,使每个群组中的任务都可能是相关的。

然后在每个集群中,作者训练一个深度嵌入函数作为度量。这确保了共同的度量只在同一集群内的任务之间共享。此外,在元测试期间,每个目标FSL任务被分配到一个特定的任务度量,这是不同集群定义的度量的线性组合。通过这种方式,不同的几项任务可以从以前的学习经验中获得不同的度量。
总结
深度学习已经成为解决复杂的计算机视觉和模式识别任务的一个事实选择。然而,对大量标记的训练数据的需求和训练深度架构所产生的计算成本阻碍了此类任务的进展。
Few-Shot Learning是解决这个问题的一个办法,它允许将预先训练好的深度模型扩展到新的数据上,只需要几个标记的例子,而且不需要重新训练。由于其可靠的性能,像图像分类和分割、物体识别、自然语言处理等任务,已经看到了FSL架构的使用。
关于更好的FSL模型的研究仍在积极进行中,以使其与完全监督学习方法一样准确甚至更好。像One-Shot或Zero-Shot学习这样明显更复杂的问题,正在被广泛研究,以缩小人工智能和人类学习者之间的差距。
今天就为你的机器学习工作流程增加速度和简单性吧
