

简介
在这篇文章中,我们将学习在Python的Sklearn(又名Scikit learn)库中实现KNN分类器的教程。我们将首先了解KNN分类器的工作,然后是它的特点。然后,我们将向你展示一个在Sklearn中使用GRidSearchCV实现KNN分类器的端到端例子,在这个分类问题中,我们将根据某些面部特征将性别分类为男性或女性。
什么是机器学习中的KNN算法?
KNN算法是一种监督学习算法,KNN代表K-Nearest Neighbor。通常,在大多数监督学习算法中,我们使用训练数据集来训练模型,以创建一个能很好地概括预测未见数据的模型。但是KNN算法是一种懒惰的算法,这意味着完全不涉及训练阶段。该算法只是存储初始训练数据集,并在分类时使用它。(因此,它是一种懒惰的执行方式)。
同时,KNN是一种非参数算法,这意味着它不需要假设任何数据分布就能正常工作。
KNN分类是如何工作的?
KNN分类算法本身是非常简单和直观的。当一个数据点被提供给该算法,并给定一个K值,它就会搜索该数据点的K个最近的邻居。最近的邻居是通过计算给定的数据点和初始数据集中的数据点之间的距离找到的。你可以使用欧几里得距离、曼哈顿距离、余弦距离等算法。
一旦确定了K个最近的邻居,接下来就要确定大多数邻居属于哪个类别。例如,如果大多数邻居属于 "绿色 "类,那么给定的数据点也会被归为 "绿色 "类。下面的插图应该能帮助你更好地理解它。
实施KNN算法时的考虑要点
-
KNN的计算成本很高,因为它在内存中加载整个数据集进行分类。当数据集的特征数量非常多时,它可能会受到维度诅咒的影响而表现不佳。
-
还有一个方面是选择 "K "的值,不同的K值会产生不同的结果。
-
还可以阅读 - K近邻分类 - 初学者的动画解释
SKlearn中的KNN分类器实例
在SKlearn中实现KNN分类器可以在KNeighborsClassifier()模块的帮助下轻松完成。在这个例子中,我们将使用一个性别数据集,用Sklearn中的KNN分类器根据面部特征来分类为男性或女性。
i) 导入必要的库
我们首先加载建立模型所需的库。
在[1]中:
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix,plot_confusion_matrix
二)关于性别数据集
性别数据集由4981行和7个特征以及一个类标签组成:
- long_hair:如果他/她有长发,则为1;如果他/她没有,则为0。
- forehead_width_cm : 额头宽度,单位为cm
- forehead_height_cm : 额头的高度,单位是cm
- nose_long : 如果他/她有一个长鼻子,它是1,如果他/她没有,它是0
- nose_wide : 如果他/她有一个宽大的鼻子,它是1,如果他/她没有,它是0。
- lips_thin : 如果他/她有薄嘴唇,则为1,如果没有,则为0。
- distance_nose_to_lip_long:如果嘴唇和鼻子之间有很长的距离,则为1,如果没有这么长的距离则为0。
- 性别(目标列)。我们将使用数据集的其他7个特征,以便对任何特定个体的性别进行推断和预测。
iii) 读取数据集
- 我们将把数据集读入Pandas数据框架,并快速浏览。
- 用info()函数获取数据集的高级信息。
- 检查有多少条记录属于男性和女性这两个类标签。我们可以看到,这是一个相当平衡的数据集。
在[2]中:
df=pd.read_csv(r"C:\Users\Veer Kumar\Downloads\gender_classification_v7.csv")
在[3]中:
df.head()
Out[3]:
| 长发 | 额头宽度_cm | 额头_高度_cm | 鼻子宽 | 鼻子_长 | 嘴唇_薄 | 鼻子到嘴唇的距离_长 | 性别 | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 11.8 | 6.1 | 1 | 0 | 1 | 1 | 男性 |
| 1 | 0 | 14.0 | 5.4 | 0 | 0 | 1 | 0 | 女性 |
| 2 | 0 | 11.8 | 6.3 | 1 | 1 | 1 | 1 | 男性 |
| 3 | 0 | 14.4 | 6.1 | 0 | 1 | 1 | 1 | 男性 |
| 4 | 1 | 13.5 | 5.9 | 0 | 0 | 0 | 0 | 女 |
进[4]:
df
出[4]:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 4981 entries, 0 to 4980
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 long_hair 4981 non-null int64
1 forehead_width_cm 4981 non-null float64
2 forehead_height_cm 4981 non-null float64
3 nose_wide 4981 non-null int64
4 nose_long 4981 non-null int64
5 lips_thin 4981 non-null int64
6 distance_nose_to_lip_long 4981 non-null int64
7 gender 4981 non-null object
dtypes: float64(2), int64(5), object(1)
memory usage: 291.9+ KB
In [6]:
df['gender'].value_counts()
Out[6]:
Male 2492
Female 2489
Name: gender, dtype: int64
iv) 探索性数据分析
在加载数据集后,我们将做一些探索性的数据分析来更好地理解我们的数据。
我们首先将我们的数据集中存在的不同特征之间的相关性可视化。然后,我们将使用线图来了解强(正)相关的特征,接着是周相关的特征,最后将查看负相关的特征。
在[9]:
#correlation matrix and the heatmap
plt.subplots(figsize=(12,5))
gender_correlation=df.corr()
sns.heatmap(gender_correlation,annot=True,cmap='RdPu')
plt.title('Correlation between the variables')
plt.xticks(rotation=45)
Out[9]:
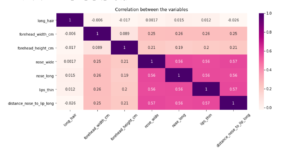
(array([0.5, 1.5, 2.5, 3.5, 4.5, 5.5, 6.5]),
[Text(0.5, 0, 'long_hair'),
Text(1.5, 0, 'forehead_width_cm'),
Text(2.5, 0, 'forehead_height_cm'),
Text(3.5, 0, 'nose_wide'),
Text(4.5, 0, 'nose_long'),
Text(5.5, 0, 'lips_thin'),
Text(6.5, 0, 'distance_nose_to_lip_long')])
在[10]中:
sns.lineplot(data=df, x="distance_nose_to_lip_long", y="lips_thin")
Out[10]:
<AxesSubplot:xlabel='distance_nose_to_lip_long', ylabel='lips_thin'>
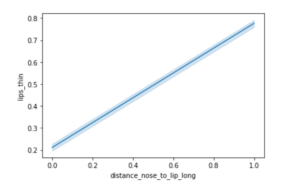
在上面的线图中,我们观察到 "lips_thin "和 "distance_nose_to_lip_long "是正相关的,它们几乎以线性方式增长。
在[11]中:
sns.lineplot(data=df, x="forehead_width_cm", y="forehead_height_cm")
出[11]:
<AxesSubplot:xlabel='forehead_width_cm', ylabel='forehead_height_cm'>
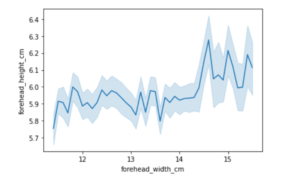
在上面的线图中,我们观察到一个杂乱无章的之字形图形,这说明 "额头_宽度_厘米 "和 "额头_高度_厘米 "不可能是相关的,因为它们的正相关度非常小,我们不能通过观察这条曲线做出任何确定的预测。
在[12]:
sns.lineplot(data=df, x="long_hair", y="forehead_width_cm")
出[12]:
<AxesSubplot:xlabel='long_hair', ylabel='forehead_width_cm'>
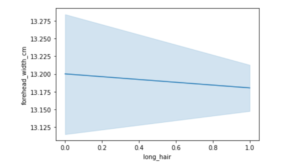
在上面介绍的这个线图中,我们看到了一个负相关的例子,可以从绘制 "长发 "和 "额头宽度_厘米 "等数量时的负斜率观察到。
在这里,我们将比较一个叫做 "鼻宽 "的重要特征,它可以用来明确地识别男性和女性,反之亦然。
在[13]:
males = df.query(" gender == 'Male' ")
males.groupby('nose_wide')['nose_wide'].describe()
Out[13]:
| 数 | 平均数 | 中位数 | 最小值 | 25% | 50% | 75% | 最大 | |
|---|---|---|---|---|---|---|---|---|
| 鼻子宽 | ||||||||
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 0 | 316.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 1 | 2176.0 | 1.0 | 0.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
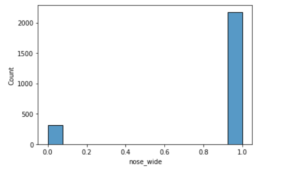
2176名男性有一个宽鼻子,这意味着大约87%的男性有这种宽鼻子,只有316名男性没有宽鼻子。
在[14]:
sns.histplot(data = males , x = 'nose_wide')
出[14]:
<AxesSubplot:xlabel='nose_wide', ylabel='Count'>
在[15]中:
females = df.query(" gender == 'Female' ")
females.groupby('nose_wide')['nose_wide'].describe()
Out[15]:
| 数 | 平均数 | std | 最小值 | 25% | 50% | 75% | 最大 | |
|---|---|---|---|---|---|---|---|---|
| 鼻子宽 | ||||||||
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 0 | 2202.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 1 | 287.0 | 1.0 | 0.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
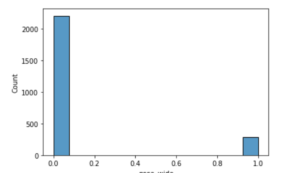
在这里我们看到,2202名女性没有宽鼻,而287名女性有宽鼻。这意味着大约88%的女性没有宽鼻子,这与男性在同一特征上显示的特征有很大的不同。
在[16]:
sns.histplot(data = females , x = 'nose_wide')
Out[16]:
<AxesSubplot:xlabel='nose_wide', ylabel='Count'>
v) 数据预处理
在这里,我们要把特征和目标标签分离成不同的数据帧x和y。
在[8]中:
#preprocessing data
x = df.drop('gender', axis=1)
y = df['gender']
vi) 将数据集分割成训练集和测试集
我们在train_test_split()函数的帮助下将训练集和测试集分开。
在[17]中:
#splitting the dataset
from sklearn.model_selection import train_test_split
# Split dataset into training set and test set
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2,random_state=100)
在[18]中:
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score, plot_confusion_matrix
vii) 用K-交叉验证和GridSearchCV进行模型拟合
我们首先创建一个KNN分类器实例,然后准备一个超参数K的取值范围,从1到31,这将被GridSearchCV用来寻找K的最佳值。
此外,我们设置了交叉验证的批次大小cv=10,并将评分指标设置为我们喜欢的准确性。
在[19]:
knn = KNeighborsClassifier()
from sklearn.model_selection import GridSearchCV
k_range = list(range(1, 31))
param_grid = dict(n_neighbors=k_range)
# defining parameter range
grid = GridSearchCV(knn, param_grid, cv=10, scoring='accuracy', return_train_score=False,verbose=1)
# fitting the model for grid search
grid_search=grid.fit(x_train, y_train)
出[19]:
Fitting 10 folds for each of 30 candidates, totalling 300 fits
[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 300 out of 300 | elapsed: 22.6s finished
一旦模型被拟合,我们就可以找到K的最佳参数和通过GridSearchCV得到的最佳分数。我们可以看到,K的最佳值是26,相应的准确率是97.64%。
在[24]:
print(grid_search.best_params_)
Out[24]
{'n_neighbors': 26}
在[20]中:
accuracy = grid_search.best_score_ *100
print("Accuracy for our training dataset with tuning is : {:.2f}%".format(accuracy) )
Out[20]: Out[20]
Accuracy for our training dataset with tuning is : 97.64%
viii)在测试数据上检查准确度
由于现在我们有最佳的超参数K=26,这可以用来拟合KNN模型,并在未见过的测试数据集上检查其准确性。
在[21]中:
knn = KNeighborsClassifier(n_neighbors=26)
knn.fit(X, y)
y_test_hat=knn.predict(x_test)
test_accuracy=accuracy_score(y_test,y_test_hat)*100
print("Accuracy for our testing dataset with tuning is : {:.2f}%".format(test_accuracy) )
输出[21]:
Accuracy for our testing dataset with tuning is : 96.49%
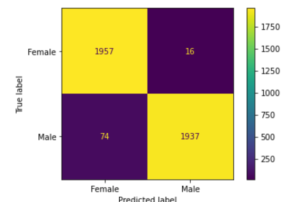
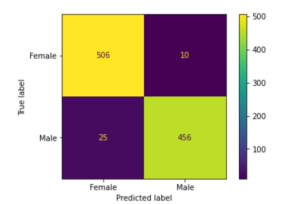
xi) 绘制混淆矩阵
现在我们使用测试数据来评估模型,为此我们建立了一个混淆矩阵来帮助我们找出真阳性、真阴性、假阳性和假阴性。
In[22]:
plot_confusion_matrix(grid,x_train, y_train,values_format='d' )
Out[22]:
<sklearn.metrics._plot.confusion_matrix.ConfusionMatrixDisplay at 0x1ca1b2b0>
在[23]中:
plot_confusion_matrix(grid,x_test, y_test,values_format='d' )
Out[23]:
<sklearn.metrics._plot.confusion_matrix.ConfusionMatrixDisplay at 0x1c9a7178>
- 还可以阅读 - K近邻分类 - 初学者的动画解释
结论
我们希望你喜欢我们的教程,现在能更好地理解如何在Python中使用Sklearn(Scikit Learn)实现K-近邻(KNN)算法。在这里,我们展示了一个端到端的例子,即使用数据集建立一个KNN模型,以便利用KNeighborsClassifier模块将我们的数据点分类到各自的性别。
