

在本教程中,我将向你展示如何使用Sklearn Linear Regression函数来在Python中创建线性回归模型。
我将快速回顾什么是线性回归,解释Sklearn LinearRegression的语法,并将逐步向你展示如何使用该技术的例子。
如果你需要特定的东西,只需点击以下任何一个链接。 该链接将带你到教程中的相应章节。
目录
线性回归的快速介绍
为了理解Sklearn线性回归函数的作用,知道什么是一般的线性回归是有帮助的。
在这里,我将快速解释什么是线性回归,然后再解释Sklearn线性回归。
线性回归是机器学习技术的一种类型
许多机器学习任务大致可分为两类:回归和分类。
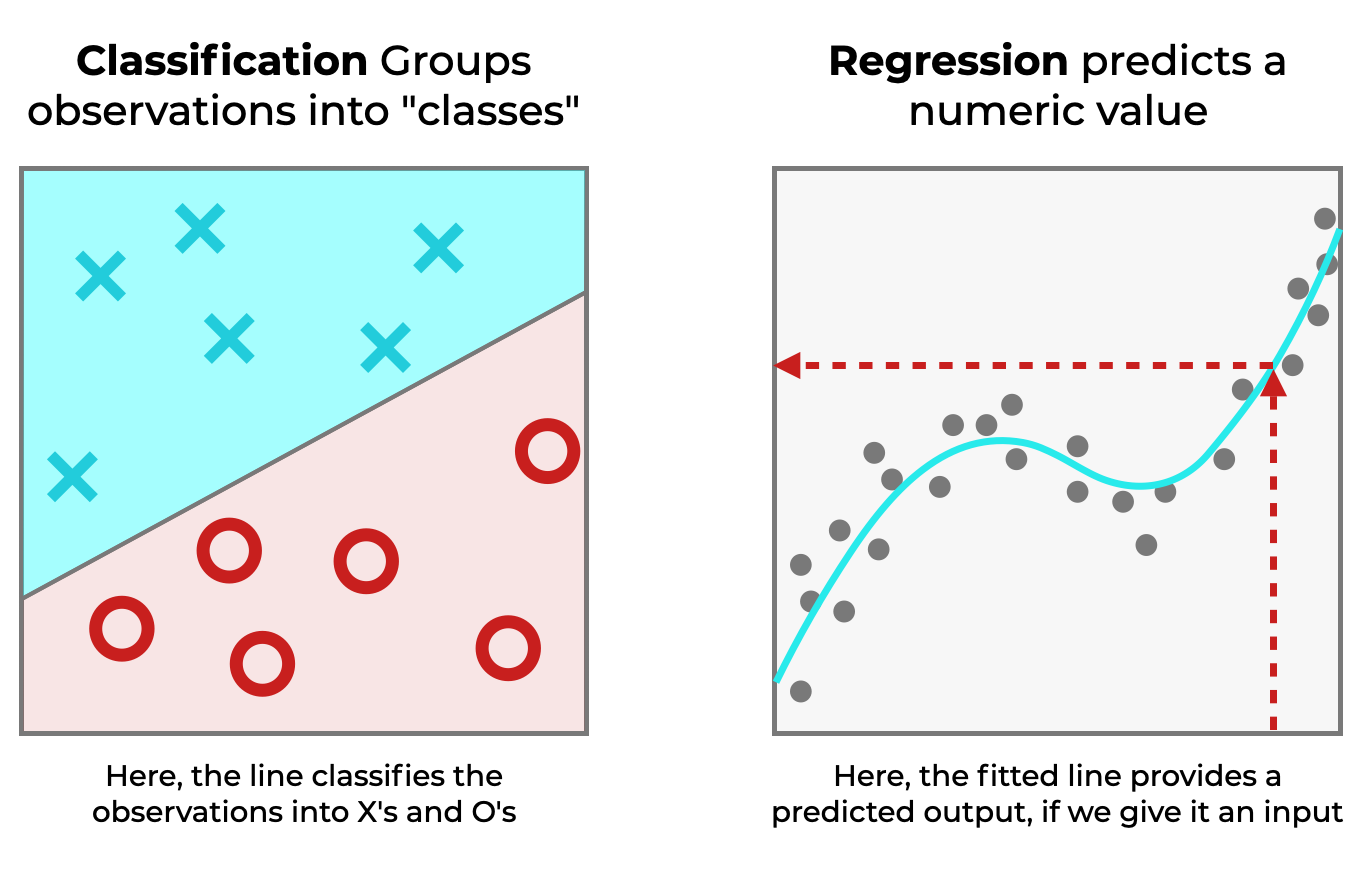
粗略地说,在回归中,我们试图预测数字值。
线性回归是一种特殊的回归方式
有许多类型的机器学习技术可以解决回归任务,包括决策树、K-近邻回归和神经网络的回归。
但可以说,最常见的回归技术是线性回归。
在线性回归中,我们假设我们所处理的数据符合线性模式。
更准确地说,我们假设数据符合方程式。
(1 ) 
...其中 是一些随机噪声。
是一些随机噪声。
因此,通过线性回归,我们假设输出 是输入变量X的线性函数,并且我们对训练数据拟合出一条直线。
是输入变量X的线性函数,并且我们对训练数据拟合出一条直线。
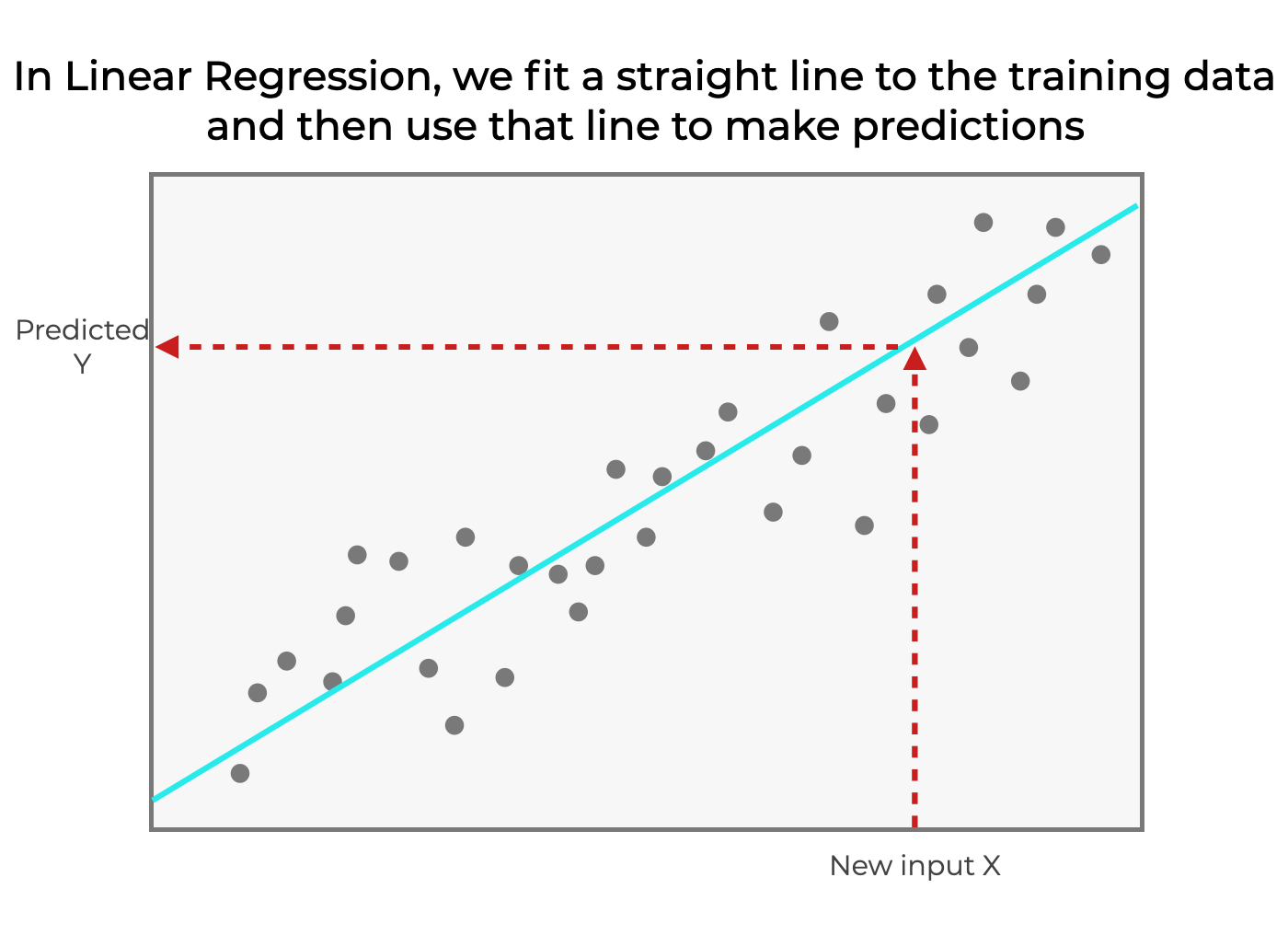
然后,我们可以用这条直线作为模型来预测新的数值。 如果我们把一个新的X值插入到方程 ,就会产生一个输出Y值。
,就会产生一个输出Y值。
(注意:这是一个X变量的 "简单 "线性回归的情况。 在多元线性回归的情况下,这可以推广到多个X变量)。
Sklearn LinearRegression在Python中构建线性回归模型
现在,让我们把这个问题带回Scikit Learn。
SklearnLinearRegression 函数是一个在Python中建立线性回归模型的工具。
使用这个函数,我们可以训练线性回归模型,为模型 "打分",并利用它们进行预测。
然而,我们如何使用这个函数的细节取决于语法。
让我们看一下语法。
Sklearn线性回归方法的语法
现在我们已经回顾了Sklearn线性回归方法的作用,让我们看看其语法。
LinearRegression的步骤
当我们使用Scikit LearnLinearRegression 函数来创建一个线性回归模型时,通常有多个步骤。
- 初始化模型
- 用训练数据训练模型
- 进行预测
为了公平起见,这只是对事物的一种简化看法。 在机器学习的工作流程中,我们可能还需要做其他事情,比如给模型打分,使用正则化,等等。
但从高层次来看,上面的步骤代表了你在使用Sklearn LinearRegression时的工作流程。
初始化Sklearn LinearRegression
因此,使用Sklearn LinearRegression的第一步是简单地初始化模型对象。
为了初始化模型,你首先需要用代码导入它。
from sklearn.linear_model import LinearRegression
一旦函数被导入,你可以以LinearRegression() 的方式调用它。

在括号内,有一些可选的参数,你可以用它们来修改函数的工作方式。我将在后面讨论这些。
当我们调用这个函数时,我们通常用一个名字来保存Sklearn模型对象,就像我们可以用名字来保存其他Python对象一样,比如整数或列表。
所以在上面的语法中,我使用了变量名my_linear_regressor 来存储LinearRegression 模型对象。但是,你可以使用任何你想要的名字,只要它符合 Python 的变量命名规则。
拟合和训练语法
在我们初始化模型之后,我们用训练数据训练模型,然后我们可以用它来进行预测。

要了解更多关于机器学习的训练和预测,请阅读我们关于Sklearn Fit方法和Sklearn Predict方法的教程。
Sklearn线性回归的参数
让我们快速浏览一下Sklearn线性回归函数的一些可选参数。
fit_interceptcopy_Xn_jobspositive
让我们来回顾一下每一个参数。
fit_intercept
fit_intercept 参数指定了模型是否应该为模型拟合一个截距。
默认情况下,它被设置为fit_intercept = True 。
如果你把这个参数设置为fit_intercept = True ,那么数据应该是居中的。
copy_X
copy_X 参数指定了在建立模型时是否应该复制X数据。
如果你设置copy_X = True ,X数据将被复制。(这是默认的)。
如果你设置copy_X = False ,X数据可能会被覆盖。
n_jobs
n_jobs 参数指定了用于计算的作业数,如果你正在处理大型数据集。
默认情况下,它被设置为n_jobs = None 。
positive
positive 参数指定模型的所有拟合系数是否必须为正值。
默认情况下,这被设置为positive = False 。
如果你设置positive = True ,它将强制所有的参数都是正数。
(这个参数只对密集数组有效)。
例子。如何在Python中使用Sklearn线性回归来建立线性回归模型
现在我们已经看了Sklearn线性回归的语法,让我们看看如何用Scikit Learn建立一个线性回归模型的例子。
我将尝试向你展示一个清晰的例子,这将涉及几个步骤。
步骤
导入软件包和函数
在你运行示例代码之前,你需要导入我们将使用的函数和工具。
我们将导入Numpy,它将提供我们可以用来为我们的训练和测试数据创建一个数字阵列的函数。
我们将导入Seaborn,它将给我们一些数据可视化工具来绘制数据。
我们将导入Scikit Learn LinearRegression函数,我们将需要它来建立模型本身。
我们将导入train_test_split,我们将用它来把我们的数据分成训练数据和测试数据。
import numpy as np
import seaborn as sns
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
创建数据
接下来,我们将创建一个我们可以使用的线性数据集。
我们将创建一个数据集,其中的x和y变量是线性相关的,并内置一点随机噪声。
从数学上讲,我们将创建x和y,以便。
(2 ) 
其中 代表正态分布的噪声。
为了做到这一点,我们将同时使用Numpy linspace和Numpy random normal。
- 使用Numpy linspace,我们将创建一个由51个均匀间隔的数字组成的数组。 这将是我们的 "X "变量
- 然后我们将设置
 ,但用Numpy随机正态加入一些随机正态噪声。
,但用Numpy随机正态加入一些随机正态噪声。
我们将把这两个变量称为x_var 和y_var 。
observation_count = 51
x_var = np.linspace(start = 0, stop = 10, num = observation_count)
np.random.seed(22)
y_var = x_var + np.random.normal(size = observation_count, loc = 1, scale = 2)
此外,请注意,我正在使用Numpy随机种子来设置伪随机数发生器的种子,当我们调用np.random.normal时,Numpy会使用它。
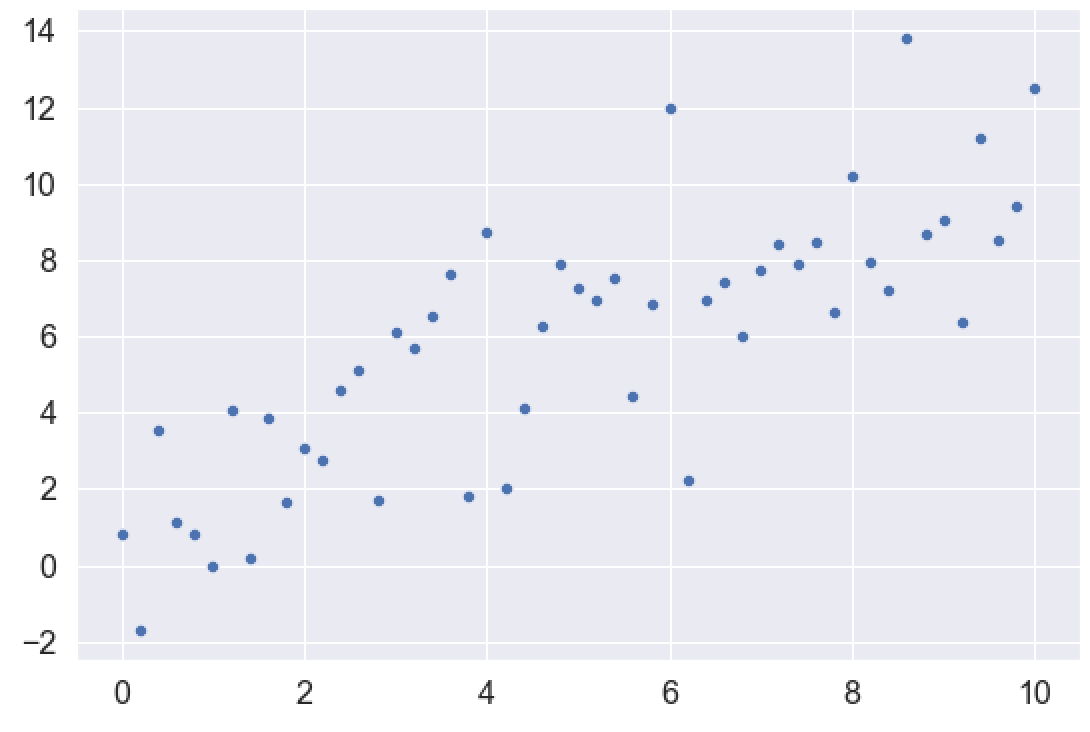
绘制数据
让我们用Seaborn的sns.scatterplot函数绘制数据。
sns.scatterplot(x = x_var, y = y_var)
输出
分割数据
接下来,让我们把这些数据分成训练数据和测试数据。
为了分割数据,我们将使用Sklearn训练-测试分割函数。
from sklearn.model_selection import train_test_split
(X_train, X_test, y_train, y_test) = train_test_split(x_var.reshape(-1,1), y_var, test_size = .2)
注意,我还使用Numpy reshape将x_var重塑为二维格式,因为当我们在Scikit Learn fit和predict中使用X数据时,X数据需要是二维的。
这个数据分割操作给了我们4个数据集。
- 训练特征(X_train)
- 训练目标(y_train)
- 测试特征(X_test)
- 测试目标(y_test)
初始化模型
接下来,我们将初始化LinearRegression模型。
from sklearn.linear_model import LinearRegression
linear_regressor = LinearRegression()
在你运行这段代码后,你将初始化linear_regressor ,这是一个sklearn模型对象。 从这个对象中,我们可以调用fit 方法和其他scikit learn方法。
拟合模型
让我们来拟合这个模型。
在这里,我们将在训练数据上拟合模型,X_train 和y_train 。
linear_regressor.fit(X_train, y_train)
在这段代码中,我们使用Sklearn fit方法来训练训练数据上的线性回归模型。
预测
现在我们已经训练了我们的线性回归模型,我们可以用它来做一些预测。
我们将在X_test 集的X 值的基础上,使用该模型来预测新的y 值。
让我们快速完成这个任务。
linear_regressor.predict(X_test)
输出
array([ 4.08428825, 6.15948972, 10.49854733, 10.30989265, 5.02756165,
2.57505083, 7.29141779, 2.00908679, 7.66872715, 3.32966954,
3.89563358])
在这里,模型正在为X_test 的每个值预测输出Y值。
在本教程中,我已经向你展示了如何使用sklearn LinearRegression方法。
但是如果你想掌握Python中的机器学习,还有很多东西需要学习。
