

本教程将告诉你如何使用Plotly Express在Python中创建一个Plotly boxplot。 它解释了语法,并将逐步向你展示如何用Plotly创建箱形图的例子。
目录。
好吧,让我们从快速回顾一下boxplots开始。
快速回顾一下boxplots
在我们具体研究Plotly boxplots之前,让我们快速回顾一下boxplot是什么。
膨胀图是数字数据汇总统计的可视化。
膨胀图是数据的可视化,显示数据的汇总统计。
更具体地说,boxplots绘制的是通常被称为 "五个数字的汇总"。
- 最小值
- 第一个四分位数(第25个百分点)
- 中位数
- 第三四分位数(第75百分位数)
- 最大值
这些指标一起告诉我们很多关于数字变量的总体分布情况。
当你把5个数字的汇总绘制成一个boxplot时,它看起来是这样的。
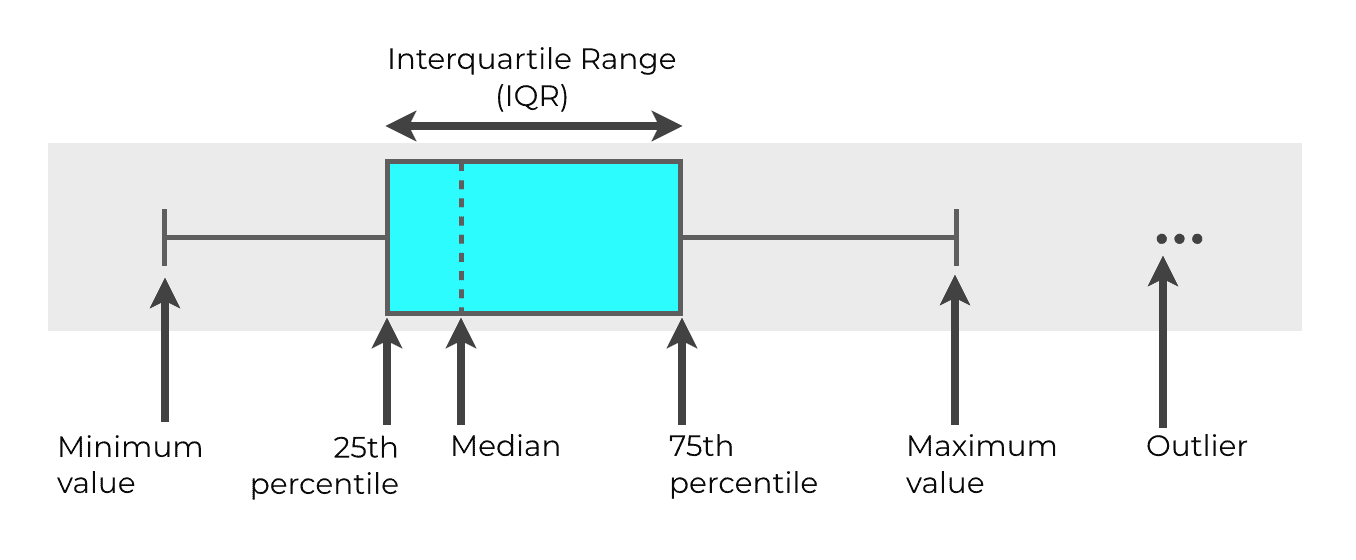
在上面的视觉效果中,你可以在boxplot的不同部分看到5个数字总结的不同部分。
让我们快速讨论一下这些部分。
盒子
博列表中的实际方框代表我们所说的四分位数范围(或简称IQR)。 IQR是指从数据的第25个百分点到第75个百分点的范围。
所以方框的左端代表第25个百分点,方框的右端代表第75个百分点。 盒子的宽度代表四分位数范围。
穿过盒子中间的那条线(虚线)代表数据的中位数。
晶须
在盒子外面,我们有两条线从盒子里延伸出去。 两边各一条。 我们称这些为 "晶须"。
这些晶须的两端代表最小值和最大值。 虽然我们称这些为 "最小和最大",但它们往往不完全是绝对的最小/最大值。 相反,晶须两端所代表的这些数值通常是根据一个公式计算出来的。最小值计算为Q1 - 1.5*IQR。 最大值计算为Q3 + 1.5*IQR。
离群值
最后,我们有离群值......你可以看到晶须以外的点。
这些离群值是存在于计算的 "最小 "和 "最大 "值之外的极端值。 它们是如此极端,以至于我们认为它们有点不寻常,所以它们通常被单独绘制成点。
正如你所看到的,膨胀图是一种有用的可视化,因为它们简洁地显示了几个重要的指标,都在同一个图表中。 它们可以让你在同一个可视化中看到中位数、IQR、最小值、最大值和离群值。
Plotly Boxplot的介绍
现在我们已经谈了一些关于膨胀图的情况,让我们来看看Plotly的膨胀图。
你可能知道Plotly是一个用于Python的数据可视化工具包。 PlotlyExpress是一个更专业的工具包,它为我们提供了一套高级的数据可视化功能。 Plotly Express为我们提供了创建简单的柱状图、线状图、直方图和散点图的工具。
Plotly Express:一种在Python中创建boxplots的快速方法
除了许多用于其他基本可视化的函数外,Plotly Express还有一个用于创建boxplots的简单函数:px.box 函数。
你可能想知道为什么你会使用Plotly Express,而不是其他选项。 例如,在Python中,你可以用Matplotlib来创建boxplots,你也可以用Seaborn来创建boxplots。
一个优点是,Plotly Express被设置为可以与数据框架一起工作。 尽管Seaborn能很好地与数据框架一起工作,但Matplotlib却不能(这是我喜欢Plotly和Seaborn而不是Matplotlib的原因之一)。
但是Plotly也有一个强大且易于使用的数据可视化语法,使你能够修改你的图表。 Matplotlib非常强大,但它通常被视为非常复杂。 而Seaborn实际上是建立在Matplotlib之上的,所以如果你想对你的Seaborn图表进行大的修改,你仍然只能使用Matplotlib语法。
Plotly是两个世界的最佳选择
通过Plotly,你可以得到Matplotlib的强大功能,以及Seaborn的简单性。
这算是两个世界中最好的了。
这就是为什么在我的许多Python数据可视化任务中,我开始偏爱Plotly而不是Matplotlib和Seaborn。
一般来说是这样,对于像boxplots这样简单的东西也是如此。
px.box的语法
现在我们已经谈了一点关于boxplots的问题,以及Plotly boxplots的具体优势,让我们看看它的语法。
在最简单的形式下,Plotly boxplot的语法看起来像这样。
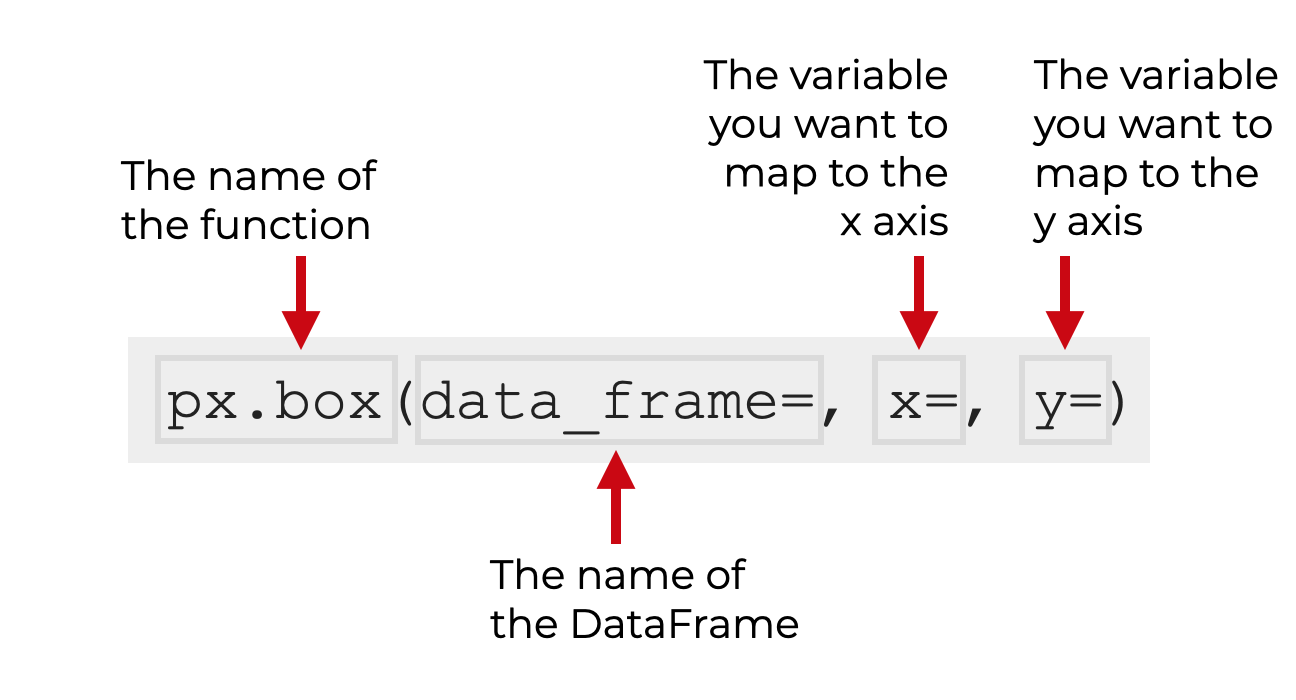
请记住,当我们以px.box 的方式调用函数时,我假设你已经用别名px (这是通用的惯例)导入了Plotly Express。
所以你以px.box() 的方式调用该函数。
在括号内,有几个参数,你可以用来修改生成的boxplot。
让我们看一下其中的几个参数。
px.box的参数
坏消息是,px.box函数有几十个参数。
好消息是,你只会经常使用其中的几个参数。 为了简单起见,我们将应用80/20规则,把重点放在我认为最重要的几个参数上。
所以在这里,我们将涵盖5个最基本的参数。
data_framexycolor_discrete_sequencecolor
让我们分别看一下这些参数。
data_frame
data_frame 参数使你能够指定一个你想要绘制的DataFrame。
这个参数是可选的。
如果使用这个参数,你将提供一个Pandas Dataframe的名称作为参数。
此外,如果你使用这个参数,你也将改变你使用x 和y 参数的方式。
x
x 参数使你能够指定你想映射到X轴的变量。
这个参数将接受数字变量或分类变量。 这取决于你要建立的boxplot的结构(我会在例子部分给你看例子)。
注意,如果你用data_frame 参数指定一个DataFrame,那么x 参数的参数将是DataFrame的一个列的名称。 当你以这种方式使用参数时,DataFrame列的名称应该在引号内。
另外,如果你不使用data_frame 参数,那么你可以提供一个Python列表、Numpy数组或者一个类似数组的对象作为x 参数的参数。 如果你这样使用x 参数 (没有 DataFrame),那么就不需要加引号了。 你只需提供列表或类似列表对象的名称。
y
y 参数与x 参数非常相似。
y 参数使你能够指定你想映射到Y轴的变量。
这个参数将接受数字变量或分类变量。 同样,这取决于博列表的确切类型和你要建立的博列表的结构。
如果你用data_frame 参数指定一个DataFrame,那么y 参数的参数将是DataFrame的一个列的名称,在引号内显示。
或者,如果你不使用data_frame 参数,那么你可以提供一个Python列表、Numpy数组或者一个类似数组的对象作为y 参数的参数。 如果你这样使用y 参数 (没有 DataFrame),那么就不需要加引号了。 你只需提供列表或类似列表对象的名称。
color_discrete_sequence
color_discrete_sequence 使你可以改变博列表中方框的颜色。
这个参数的参数是一个颜色名称的列表。 颜色名称可以是 "命名 "的颜色,也可以是十六进制的颜色(或其他几种格式之一)。
颜色名称应在引号内。
你可以提供一种颜色,或者在列表中提供几种颜色。
实际上,这个参数使你能够指定用于盒子的调色板。
color
color 参数使你能够将一个变量映射到盒子的颜色上。
因此,例如,如果你想根据数据中的不同类别对方框进行颜色编码,那么你可以将一个分类变量映射到color 参数。 如果你这样做,那么不同的盒子的颜色将对应于你数据中的不同类别。
这可能很难理解,所以我将在例子3中向你展示如何使用color 参数的例子。
例子。如何用Plotly Express创建箱形图
好了。现在你已经了解了px.box 的语法,让我们来看看如何用Plotly创建箱形图的一些例子。
例子
先运行这段代码
在你运行这些例子之前,你需要运行一些初步代码来设置一切。
具体来说,你需要导入一些重要的包并创建我们将要使用的DataFrame。
导入软件包
首先,让我们导入我们将要使用的 Python 包。
我们需要导入Numpy和Pandas。 我们将使用它们来创建我们要绘制的数据。
我们还需要导入 Plotly Express,因为那是我们用来创建 Plotly boxplots 的工具箱。
#----------------
# IMPORT PACKAGES
#----------------
import pandas as pd
import numpy as np
import plotly.express as px
创建数据框架
接下来,我们需要用一些变量创建我们的DataFrame,这些变量可以在boxplot中使用。
在这里,我们将创建一些模拟的 "考试分数 "数据。 该数据将有三个变量。score,class, 和gender 。 所以想象一下,有一群学生,分成几个不同的班级,有男有女,他们都参加了一个测试。 这个数据集将包含这些不同学生的考试分数信息。
为了创建这个数据集,我们将使用几个Numpy和Pandas函数。
我们将用正态分布的数据创建3个Numpy数组。 我们将这些数组称为score_array_A ,score_array_B ,和score_array_C 。
当我们使用np.random.normal来创建这些正态分布数据时,我们将使用loc 和scale 参数来赋予数组中的数据不同的平均值和标准差。(当我们绘制这些数据时,我们会看到不同的平均值和标准差)。
还要注意的是,在我们使用np.random.normal来创建我们的正态分布数据之前,我们要使用np.random.seed函数来设置Numpy的随机数发生器。 我们这样做是为了可重复性(也就是说,当你运行这段代码时,你的 "随机 "数字将与你在博文中看到的 "随机 "数字相同)。
如果你不明白我们为什么使用种子,你应该阅读我们关于numpy.random.seed的教程。
好的,让我们运行这段代码。
# set seed
np.random.seed(41)
#create three different normally distributed datasets
score_array_A = np.random.normal(size = 300, loc = 85, scale = 3)
score_array_B = np.random.normal(size = 300, loc = 80, scale = 7)
score_array_C = np.random.normal(size = 300, loc = 73, scale = 4)
所以在这一点上,我们有了3个带有正态分布数据的Numpy数组。
接下来,我们将把这些Numpy数组合并成一个Pandas DataFrame。
要做到这一点,我们要把每个Numpy数组都变成一个单独的DataFrame,然后把它们组合在一起。
首先,让我们把Numpy数组做成DataFrame。
#turn normal arrays into dataframes
score_df_A = pd.DataFrame({'score':score_array_A,'class':'Class A'})
score_df_B = pd.DataFrame({'score':score_array_B,'class':'Class B'})
score_df_C = pd.DataFrame({'score':score_array_C,'class':'Class C'})
请注意,这些DataFrame中的每一个都有一个叫做score 的变量。 这个score 变量包含我们之前创建的正态分布的 "测试分数"。
每个DataFrame也有一个名为class 的变量。 这个class 变量在每个数据框架中都有不同的值。'Class A' 'Class B' 'Class C'同样:你可以想象有三个独立的学生班级。 这个class 变量编码了这些信息。 当我们把这些数据合并成一个DataFrame时,这个类变量将包含这3个类别。
将数据合并到数据框中
现在,让我们把这3个独立的DataFrame结合在一起,成为一个单一的DataFrame。 要做到这一点,我们将使用pd.concat() 函数。
#concat dataframes together
score_data = pd.concat([score_df_A,score_df_B,score_df_C])
运行这个函数后,我们将有一个名为score_data 的DataFrame 。
添加变量
最后,我们要创建一个 "性别 "变量,对学生的不同性别(男性和女性)进行编码。
要做到这一点,我们需要使用Pandas的assign方法和Numpy的where技术。
score_data = score_data.assign(gender = np.where(score_data.score%3 > 1, "Male","Female"))
最后的DataFrame,score_data ,包含了3个班级和两个不同性别的测试分数数据(正态分布)。
(请记住,这只是一些简单的虚拟数据,我们可以在我们的boxplots中使用。 为了创建这个,我们只是使用了一些数据处理工具。 做这样的事情是你应该掌握Pandas和Numpy的原因之一)。
设置Plotly图像渲染
在我们绘制图表之前,还有最后一件事。
如果你在像Spyder这样的IDE中使用Plotly,你需要运行一些代码来使可视化的东西在IDE中显示。
如果你正在使用Spyder(或你的IDE),你可以运行以下代码。
import plotly.io as pio
pio.renderers.default = 'svg'
说了这么多,如果你使用的是Jupyter,可能就不需要这些代码了。
好了我们所有的设置都应该完成了。 我们已经准备好做一些图表了。
例子1:创建一个简单的Plotly boxplot
首先,让我们创建一个非常简单的boxplot。
这将是一个只有一个方框的boxplot。 这次我们将不按类别来划分数据。
为了做到这一点,我们将调用px.box() 函数。
在括号内,我们将用data_frame参数设置DataFrame,我们将用代码x = 'score' 将score 变量映射到x轴。
让我们看一下。
px.box(data_frame = score_data
,x = 'score'
)
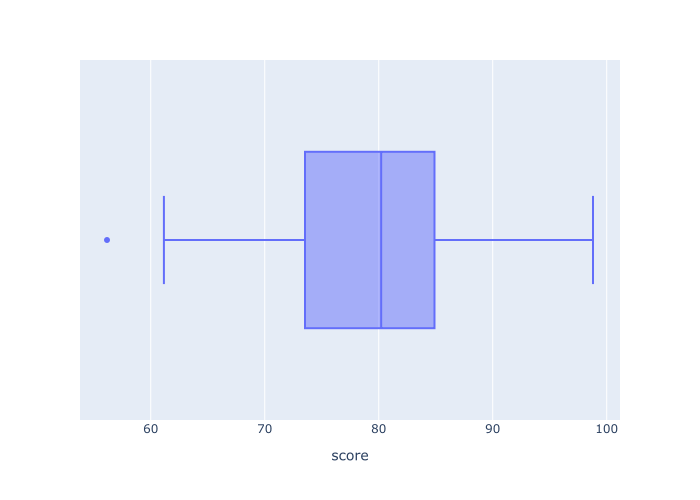
输出
解释
这个boxplot是非常简单的。
它为score_data 数据框架中score 变量中的所有数据绘制了 "五个数字摘要"。
你可以看到数据的平均值在80左右(这是在方框的中间划过的线)。
框的左端显示第一四分位数,框的右端显示第三四分位数。
两个晶须显示了计算出来的最小值和最大值,分别为62和92。
你还可以看到左手边的一个离群点(单点),大约是56。
如果你看一下这个可视化图,你会对分数变量的分布有一个大致的了解。 一目了然,你可以看到中位数、最小值、最大值和其他几个指标。
说了这么多,这只是一个相当简单的boxplot,我们可以通过修改它来改变或改善它。
让我们来看看一些修改。
实例2:通过一个分类变量来划分博列表
下一步,我们将通过分类变量class 来分解数据。
为了做到这一点,我们将把class 变量映射到y 参数上。
px.box(data_frame = score_data
,x = 'score'
,y = 'class'
)
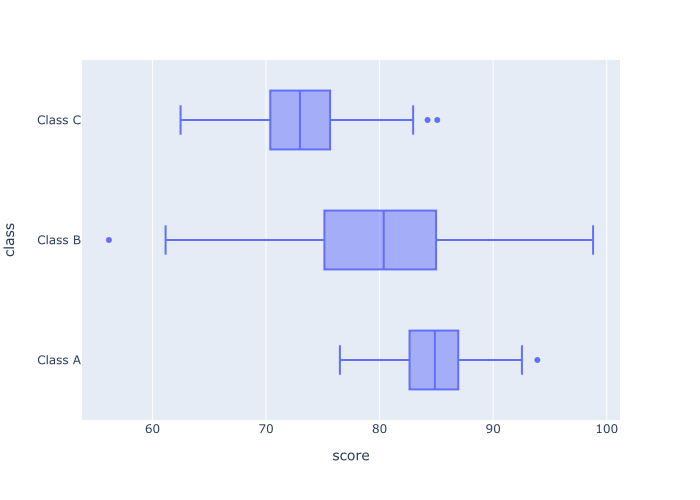
输出
解释
这里,我们有一个score 变量的boxplot。
但是这个数字变量已经被分类变量class 进一步分解。 为了做到这一点,我们使用了代码y = 'class' 。 通过这样做,Plotly为每个类别(A类、B类、C类)显示一个单独的方框。
这使我们能够检查每个班级的分数分布,并将它们相互比较。
例子3:改变Plotly boxplot的颜色
现在,让我们来改变方框的颜色。
注意,默认情况下,方框的颜色是中等的蓝色。
出于审美原因,我们可能想改变方框的颜色。
在这个例子中,我们将改变颜色为'red'。
要做到这一点,我们需要使用color_discrete_sequence 参数。具体来说,我们将把color_discrete_sequence 参数设置为color_discrete_sequence = ['red'] 。
让我们看一下。
px.box(data_frame = score_data
,x = 'score'
,y = 'class'
,color_discrete_sequence = ['red']
)
输出
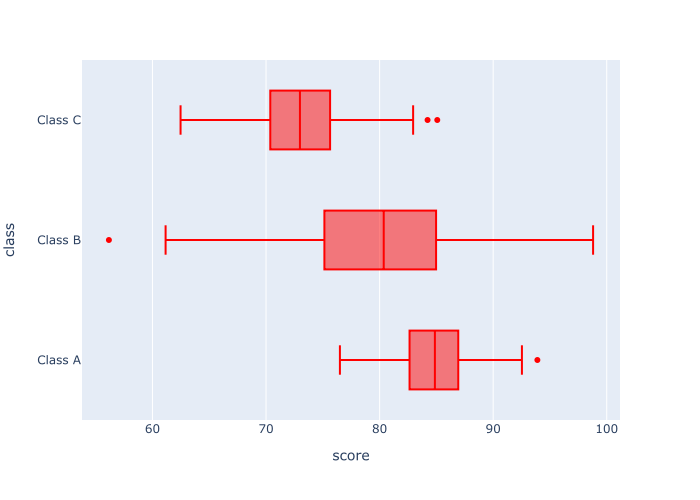
解释
那么这里发生了什么?
这是很直接的问题。 这是与例2中的boxplot相同的boxplot,但是我们把颜色改成了 "红色"。
注意,color_discrete_sequence 参数的参数是一个包含颜色名称的 Python 列表。 而且颜色名称是在引号内。 这很重要。 颜色名称需要在引号内,并且在一个 Python 列表内。
还要记住:你可以使用Python "命名 "的颜色,如red,green, 和blue ,但你也可以使用十六进制的颜色。 试一试,看看什么对你来说是好的。
例子 4:通过第二个分类变量(使用颜色)来分解boxplot的内容
接下来,我们要在第二个分类变量上对数据进行细分。 具体来说,我们要通过颜色将数据分成更多的类别。
为了做到这一点,我们将把我们的gender 变量映射到color 参数上。
px.box(data_frame = score_data
,x = 'score'
,y = 'class'
,color= 'gender'
)
输出
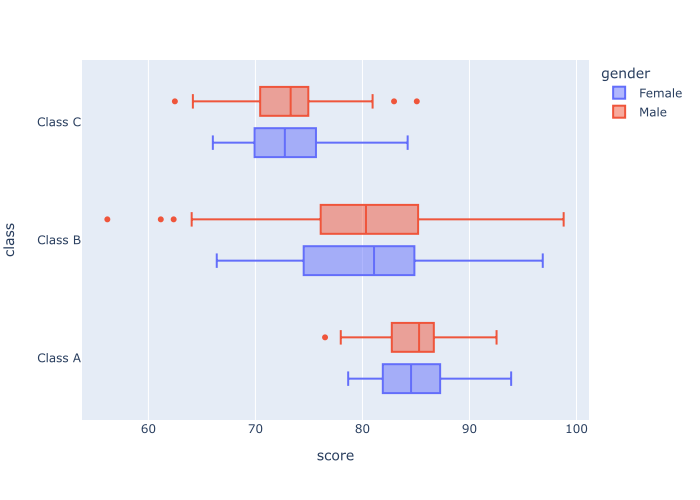
解释
请注意,这里的数据已经被两个分类变量分割开来。
我们把class 变量映射到y轴上。 这就形成了一个分类的分离。
我们还将gender 变量映射到color 参数上。 这在可视化中创造了第二个分类分离。
通过将多个分类变量映射到不同的参数,我们创建了一个多变量的可视化,帮助我们在不同的类别和类别的组合之间进行更多的比较。
例子5:创建一个垂直的boxplot
最后,让我们创建一个垂直的boxplot。
这将是我们在例子2中制作的简单的boxplot的一个变体。 但是,那个可视化是水平方向的,而这个将是垂直方向的。
实现这一目标的最好方法是将变量映射到x 参数和y 参数中去。你可以直接交换你映射到x 参数和y 参数的变量。
所以在这个例子中,我们要把class 映射到x轴上,把score 映射到y轴上。
px.box(data_frame = score_data
,x = 'class'
,y = 'score'
)
输出
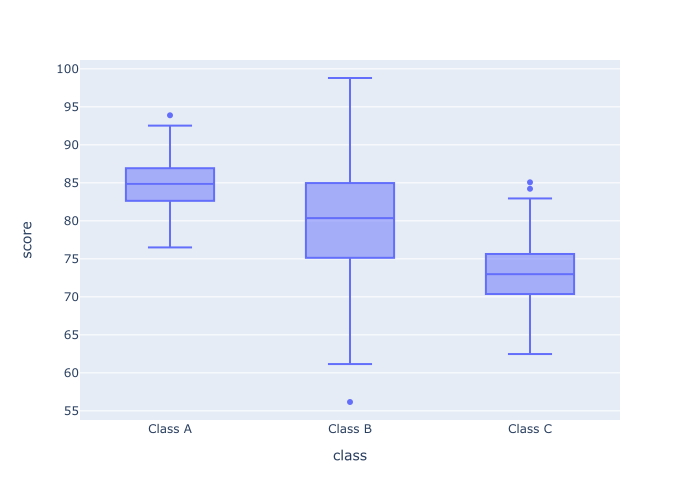
解释
你可以在输出中看到,现在我们在x轴上有不同类别的"class"。 而数字score 变量则沿y轴呈现。
通过改变我们将score 和class 变量映射到我们的坐标轴上的方式,我们有效地改变了绘图的方向。
