

常见场景
假如我们要做一个商城,商城有一个分类功能,结构如下
0-3岁
益智
游戏
国学部落(应用)
小小艺术家(应用)
语文
小小文豪(应用)
3~6岁
6岁以上
小小艺术家的直接分类是游戏,同时也属于0-3岁,益智,当我们查询益智类下的所有应用的时候,应该要返回国学部落,小小艺术家,小小文豪,这个数据结构该怎么设计呢?
方案一
一说到层级,我们这一反应肯定是树


pid用来记录父类的ID,我们现在想查0~3岁下的所有应用,看下查询步骤
- 先用
pid=1,查询所有第一级子节点的ID,结果是[2, 3] - 遍历上一步骤的所有
ID,查询所有子节点的ID - 最后用
分类ID IN (2,3,4)做条件来查询应用
假如我们的分类再多一层,就要再执行一次步骤2,层级越多,就一直在重复执行步骤2,循环查库肯定不是一个优雅的方案
优化一下
我们能不能给每个分类划定一个范围,比如:
`1~10000`属于0~3岁
`10~1000`属于益智
`100~200`属于游戏
`201~300`属于语文
`10001~20000`属于3~6岁
我们现在想查0~3岁下的所有应用,看下查询步骤
- 先用
pid=1,查询分类的区间 min>1 AND max<10000, 查询所有子节点的ID- 最后用
分类ID IN (2,3,4)做条件来查询应用
确实可以,关键不会随着层级的增加,导致查询步骤越来越多,始终就这3步


SELECT
group2.*
FROM
`group2`,
( SELECT * FROM `group2` WHERE id = 1 ) parent
WHERE
`group2`.min > parent.min
AND `group2`.max < parent.max
这种模式适合那种业务比较稳定,基本不会有太多变动那种,不然可能会出现区间重叠的问题
日常生活中我们所用的邮编其实就是用的这种方式,51开头表示是广东省的,5190开头表示是广东珠海的,519080就是广东珠海唐家
再优化一下
上一个方案带来的新的问题是区间可能会重叠的问题,那么能不能设计一个区间可动态扩展的呢,我们把分类表的改一下
CREATE TABLE `group2` (
`id` int unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(32) NOT NULL, //分类 名
`pid` int NOT NULL DEFAULT '0', // 父类ID
`left` int DEFAULT NULL, //树的左节点值,相当于上面的min
`right` int DEFAULT NULL,//树的右节点值,相当于上面的max
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
left用来记录最小值,right用来记录最大值,right一定要比left大,所有的子节点要在父节点的区间内
添加根结点,这个要注意,我们要取表中的IFNULL(MAX(right), 0),假设为max_right,知道已经最大的区间取值,然后加1
新节点的:
left = max_right+1
right = max_right+2

添加子结点的时候,先取父节点的right,假设为parent_right,先记录下来,
因为parent_right和pareng_right+1这两个位置已经被占用了,我们要先腾出来,再执行插入操作
位置腾出来的SQL:
// 所有大于parent_right大的最小值要加2
UPDATE group SET left=left+2 WHERE left>parent_right
// 所有大于等于parent_right大的最大值要加2,如下所示:right=2 -> right=4
UPDATE group SET right=right+2 WHERE right>=parent_right
现在 已经腾出了2,3,这两个位置,就可以放心插入了

同上

同上
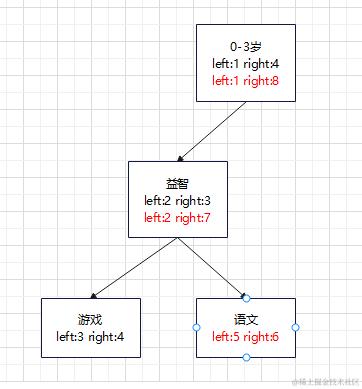
你以为这个数据结构只能往下查?不好意思,没有这么弱的,它还可以查找某个子结点的所有父节点
SELECT
group2.*
FROM
`group2`,
( SELECT * FROM `group2` WHERE id = xxx ) child
WHERE
`group2`.min < child.min
AND `group2`.max > child.max
