网络传输问题本质上是对网络资源的共享和复用问题,因此拥塞控制是网络工程领域的核心问题之一,并且随着互联网和数据中心流量的爆炸式增长,相关算法和机制出现了很多创新,本系列是免费电子书《TCP Congestion Control: A Systems Approach》的中文版,完整介绍了拥塞控制的概念、原理、算法和实现方式。原文: TCP Congestion Control: A Systems Approach

第3章 设计空间
有了TCP/IP的架构基础,就可以准备探索解决拥塞的设计空间了。但要做到这一点,首先需要退一步考虑一些更宏观的问题。互联网是计算、存储和通信资源的复杂组合,数百万用户共享这些资源,主要问题在于如何将这些资源(特别是交换容量、缓冲区空间和链路带宽)分配给端到端数据流。
由于互联网最初采用了尽力而为服务模式,用户(或者更准确的说,为用户服务的TCP)可以自由向网络发送尽可能多的数据包,因此互联网最终也必然会面临公地悲剧(tragedy of the commons) 。随着用户开始体验到拥塞崩溃,自然反应是试图加上更多控制。因此,术语拥塞控制(congestion control) 可以被视为一种分配资源的隐式机制。当控制机制发现资源变得稀缺时,就会做出反应,努力缓解拥堵。
在网络服务模型中,一种明显的替代方案是将资源显式的分配给数据流。例如,应用程序可以在发送流量之前显式请求资源。IP的尽力而为假设意味着,当拥塞成为严重问题时,这种方法并不能够立即奏效。随后的工作是将更明确的资源分配机制用来改造互联网的尽力而为模型,包括提供QoS保证的能力。通过这种角度思考应对互联网拥堵的方式很有好处。本书的第一部分探讨了构成控制机制基础的一系列设计决策,然后我们定义了定量评估和比较不同拥塞控制机制的标准。
3.1 实现选择
我们首先介绍拥塞控制机制面临的四种实现选择,以及TCP/IP决策背后的设计原理。考虑到所处环境,有些决定是"显而易见的",但因为互联网的持续发展造成的环境变化,我们需要谨慎考虑所有这些决定。
3.1.1 集中式和分布式
原则上,第一个设计决策是网络的资源分配是集中式还是分布式的。在实践中,互联网的规模以及所连接的组织的自主权,决定了应该采取分布式方法。事实上正如Dave Clark所阐述的那样,分布式资源管理是互联网设计的明确目标,但承认这一默认决定之所以重要,有两个原因。
延伸阅读:
D. Clark, The Design Philosophy of the DARPA Internet Protocols. ACM SIGCOMM, 1988.
首先,虽然互联网控制拥塞的方法是分布在数百万主机和路由器上的,但可以认为它们将合作尝试实现全局最优解决方案的。从这个角度来看,存在一个共享的目标函数,所有组件都实现某个分布式算法来优化该函数。本书所描述的各种机制只是简单定义了不同的目标函数,其中一个长久的挑战是,当部署了多种机制时,如何协调目标函数之间的竞争。
其次,虽然集中式方法对整个互联网来说并不实用,但可以适用于有限的领域。例如,逻辑上集中的控制器可以收集有关网络链路和交换机状态信息,计算全局最优资源分配,然后建议(甚至监督)终端主机所提供的可用容量。这种方法当然会受到集中式控制器响应网络变化的时间尺度的限制,但当前已经成功应用于B4和SWAN等流量工程机制做出的粗粒度分配决策。现在还没有办法明确的在粗粒度的流量工程决策和细粒度的拥塞控制决策之间划一条线,但最好对所有可能的选择保持开放的心态。
延伸阅读:
S. Jain, et al. B4: Experience with a Globally-Deployed Software Defined WAN. ACM SIGCOMM, August 2013.
集中式控制在数据中心也得到了有效应用,这对于拥塞控制来说是一个有趣的环境。首先,数据中心的RTT非常低(不考虑进出数据中心的流,只考虑数据中心服务器之间的通信)。其次,很多情况下数据中心可以被视为一个新领域,这提高了尝试新方法的可能性,这些新方法不必与现有算法平等共存。由麻省理工学院和Facebook研究人员合作开发的Fastpass就是这种集中式方式的很好的例子。
延伸阅读:
J. Perry, et al. Fastpass: A Centralized “Zero-Queue” Datacenter Network. ACM SIGCOMM, August 2014.
3.1.2 以路由器为中心还是以主机为中心(Router-Centric versus Host-Centric)
给定某个分布式资源分配方法,下一个问题是,应该在网络内部(即在路由器或交换机上)实现该机制,还是在网络边缘(即在主机中作为传输协议的一部分)实现该机制。这不是严格意义上的非此即彼的情况,实践中这两个地方都需要涉及,真正的问题是哪个组件需要承担主要责任。路由器总是负责决定哪些包要转发,哪些包要丢弃。但是,在路由器介入终端主机的决策并学习如何做出决定时,其介入的程度有很多不同的选项。
在这些选项的一端,路由器允许为主机预留容量,确保每个流的数据包得到相应的传递。路由器可以利用类似公平队列这样的机制实现某个信令协议,仅在有足够容量时接受新的流,并监督主机确保创建的流不超过资源预留范围。这就是基于预留的QoS保证机制,具体细节超出了本书范围。
另一端是以主机为中心的方法。路由器对可用容量不做任何保证,也不提供任何明确的反馈(当缓冲区满时,会默默的将包丢弃),而观察网络状况(例如,有多少包成功通过了网络)并相应调整其行为是主机的责任。
在两个极端的中间,路由器可以采取更主动的行动来协助终端主机完成工作,但不是通过预留缓冲区空间的方式,而是需要路由器在缓冲区满时向终端主机发送反馈。我们将在第6章介绍某些形式的主动队列管理(AQM, Active Queue Management) ,但在接下来的两章中介绍的以主机为中心的机制假设路由器在缓冲区满时只是静默丢包。
过去,在传输层实现了以主机为中心的方法,通常是TCP或其他一些模仿TCP算法的传输协议,比如DCCP(数据报拥塞控制协议, datagram congestion control protocol)或QUIC(一种相对较新的为基于HTTP的应用程序设计的传输协议)。然而,也可以在应用程序本身实现拥塞控制。DASH(基于HTTP的动态自适应流, Dynamic Adaptive Streaming over HTTP) 就是一个例子,尽管严格来说应该被视为传输层(因为运行在TCP上)和应用层拥塞控制的组合。根据测量到的网络性能,向客户端传输视频的服务器在一系列不同的视频编码之间切换,从而改变向HTTP流发送数据的速率。实际上,TCP试图为流找到一个可持续的带宽,然后应用程序调整其发送速率,以充分利用该带宽,避免发送超过当前网络条件下所能支持的数据。拥塞控制的主要责任落在TCP上,但应用程序的目标是保持流水线满,同时保证良好的用户体验。
3.1.3 基于窗口 vs 基于速率(Window-Based versus Rate-Based)
确定了以主机为中心的方法之后,下一个实现选择是基于窗口的机制还是基于速率的机制。TCP使用基于窗口的机制来实现流量控制,因此TCP拥塞控制的设计决策似乎显而易见。事实上,在第四章中介绍的拥塞控制机制是围绕计算拥塞窗口(congestion window) 的算法展开的,其中发送方被较小的流量控制窗口或计算拥塞控制窗口所限制。
但也可以计算出网络能够支持的数据包传输速率,并相应调整传输速度。观察到的速率只是在一段时间内(例如测量的RTT)交付的字节数。我们指出速率和窗口之间的这种二元性,是因为基于速率的方法更适合以某种平均速率生成数据的多媒体应用,而且至少需要某种最小吞吐量才能发挥作用。例如,某个视频编解码器可以生成平均速率为1 Mbps的视频,峰值速率为2 Mbps。
在支持不同QoS级别的基于预留的系统中,基于速率的方法是合理选择,但即使在像互联网这样的尽力而为网络中,也可以实现某种自适应的基于速率的拥塞控制机制,可以在应用程序需要调整传输速率时(例如通过调整其编解码器)通知应用程序。这是TCP友好速率控制(TFRC, TCP-friendly rate control)的核心思想,它将TCP避免拥塞的概念扩展到更自然的以特定速率(例如,视频编解码器在给定质量水平上产生的比特率)发送数据包的应用程序。TFRC通常与RTP一起使用,RTP是一种为实时应用设计的传输协议,我们将在第7章中看到这种机制的例子。
最后,TCP拥塞控制的最新进展之一是BBR(瓶颈带宽和RTT, Bottleneck Bandwidth and RTT),它结合使用了基于窗口和基于速率的控制,从而尽量限制网络队列的堆积。我们将在第5章详细介绍这种方法。
3.1.4 基于控制 vs 基于回避(Control-based versus Avoidance-based)
我们要注意,最后的实现选择可能有些微妙。终端主机面临的挑战是,根据反馈和观察,计算网络中有多少可用容量,并相应调整其发送速率。有两种实现此目的的通用策略: 一种是积极的方法,故意以某个会产生丢包的速率发包,然后对其进行响应;另一种是保守的方法,尝试检测队列开始出现堆积的时间点,并在溢出之前降低速率。我们将第一种类型的机制称为基于控制(control-based) 的机制,第二种类型的机制称为基于回避(avoidance-based) 的机制。
延伸阅读:
R. Jain and K. K. Ramakrishnan. Congestion Avoidance in Computer Networks with a Connectionless Network Layer: Concepts, Goals and Methodology. Computer Networking Symposium, April 1988.
Raj Jain和K.K. Ramakrishnan Jain在1988年首次提出了这种区分,但经常被忽略,而人们通常只有"拥塞控制"这个术语来指代这两种方式。但我们认为这两者的区别非常重要,因此在适当的时候我们就会指出这一不同之处。不过,如果两者的区别对讨论不是很重要的话,我们还是只用"拥塞控制"这一个术语。
还需要注意,我们称为"基于控制"和"基于回避"的方法有时分别被称为基于丢包(loss-based) 和基于延迟(delay-based) 的方法,这是因为两者对拥塞窗口进行调整的信号不一样,前者在检测到丢包时调整窗口,后者在检测到延迟梯度变化时调整窗口。从这个角度来看,在接下来的四章中介绍的每一种算法都以某种方式有效改进了这些信号的保真度。
3.2 评估标准
在确定构建拥塞控制机制所需的设计决策集之后,下一个问题是,如何判断给定解决方案是好是坏。回想一下,第一章中我们提出了网络如何有效(effectively) 、公平(fairly) 分配其资源的问题,这表明至少有两种广泛的指标可以用来评估资源分配方案,接下来我们依次考虑。
3.2.1 有效性(Effectiveness)
考虑吞吐量和延迟这两个网络的主要指标是评估拥塞控制机制有效性的很好的起点。显然,我们想要尽可能高的吞吐量和尽可能低的延迟,但不幸的是,这两个目标可能彼此冲突。增加吞吐量的方法是允许尽可能多的数据包进入网络,从而将所有链路的利用率提高到100%。这样做是为了避免链路空闲从而影响吞吐量。这一策略的问题在于,增加网络中包的数量也会增加每个路由器上队列的长度,从而意味着数据包在网络中的延迟会增加,更糟的是,多余的包有可能会被丢弃。在网络中丢弃数据包不仅会影响延迟,而且会损害吞吐量,因为上游链路带宽被浪费在了一个无法成功发送到目的地的数据包上[1]。
[1] 我们有时使用术语goodput而不是吞吐量来强调我们关心的是通过网络成功发送到接收方的数据,而不仅仅是发送方发送的数据。
吞吐量与延迟的比率是评估资源分配方案有效性的通用指标。这个比率有时被称为系统指数(power):
Power=Throughput/Delay
我们的目标是最大化这个比率,这个函数表示我们的系统可以支持多少负载,而负载由资源分配机制设置。图11给出了典型的指数曲线,理想情况下,资源分配机制将在曲线的峰值处运行。峰值左边,机制过于保守,也就是说,不允许发送足够多的数据包来保持链路繁忙。峰值右边,过多的包进入网络,要么(a)由于排队导致延迟增加(分母),要么(b)由于丢包造成吞吐量(分子)实际上开始下降。
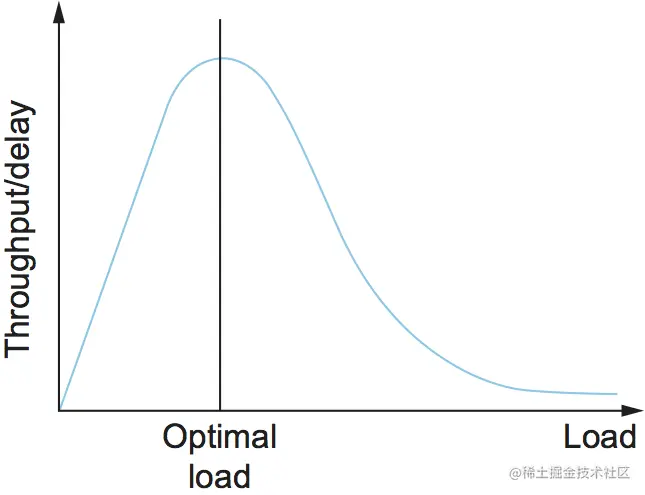
此外,我们需要关注的是,即使系统在沉重的负载下运行(图11中曲线的右端),会发生什么情况。我们希望避免系统吞吐量接近于零的情况,目标是使机制保持稳定,即使在网络负载过重时,数据包也能继续通过网络。如果某个机制在过载情况下不稳定,网络就会发生拥塞崩溃(congestion collapse) 。
注意,虽然"持久队列"和"拥塞崩溃"都需要避免,但对于网络遭受这两种情况的阈值没有精确的定义。它们都是关于算法行为的主观判断,总之,延迟和吞吐量是两个重要的性能指标。
3.2.2 公平性(Fairness)
网络资源的有效利用并不是判断资源分配方案的唯一标准,我们还必须考虑公平性问题。然而,当我们试图定义什么是公平的资源分配时,很快就会陷入了混乱。例如,基于预留的资源分配方案提供了一种显式的方法来创建受控的不公平,在这种方案中,我们可以通过预留使视频流通过某些链接接收1 Mbps的数据,而同一链接上的文件传输流只能接收10 Kbps的数据。
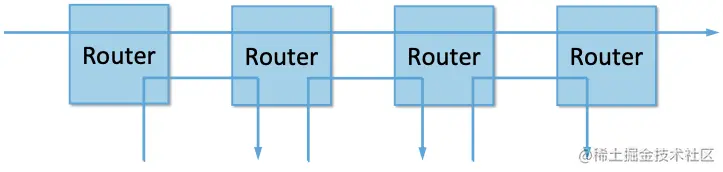
另一方面,在没有明确信息的情况下,如果几个流共享某个特定链路,我们希望每个流都能使用相同份额的带宽。这个定义假定公平的带宽份额意味着平等使用带宽。但是,即使没有预留,平等也不一定等于公平。我们是否也应该考虑路径的长度?例如图12所示,当一个四跳流与三个单跳流竞争时,什么才是公平?
假设最公平的情况是所有流都使用相同的带宽,网络研究员Raj Jain提出了一个可以用来量化拥塞控制机制公平性的度量指标。Jain公平指数的定义如下:
给定一组流吞吐量
(x1,x2,…,xn)
(以bps为单位衡量),下面的函数为流分配一个公平索引:
)^{2}} {n \sum_{i=1}^{n} x_{i}^{2}}$$
公平指数的结果总是在0到1之间,其中1表示最大的公平。下面我们尝试理解一下这个指标背后的含义。考虑所有n个流每秒接收1个数据单位的吞吐量的情况,可以看到,本例中的公平指数为
$$\frac{n^2}{n \times n} = 1$$
假设一个流接收的吞吐量为 $1 + \Delta$,现在公平指数为
$$\frac{((n - 1) + 1 + \Delta)^2}{n(n - 1 + (1 + \Delta)^2)}
= \frac{n^2 + 2n\Delta + \Delta^2}{n^2 + 2n\Delta + n\Delta^2}$$
注意,分母比分子大 $(n-1)\Delta^2$,因此,无论奇数流的流量比其他所有流的流量多还是少(多或少 $\Delta$ 单位),公平指数现在都降到了1以下。另一种需要考虑的简单情况是,*n*个流中只有*k*个流量的吞吐量相等,其余*n-k*个用户的吞吐量为零,在这种情况下公平指数下降到*k/n*。
>延伸阅读:\
>R. Jain, D. Chiu, and W. Hawe. [A Quantitative Measure of Fairness and Discrimination for Resource Allocation in Shared Computer Systems](https://www.cse.wustl.edu/~jain/papers/ftp/fairness.pdf "A Quantitative Measure of Fairness and Discrimination for Resource Allocation in Shared Computer Systems"). DEC Research Report TR-301, 1984.
下一节我们将重新讨论适用于新拥塞控制算法的公平概念,正如上面所提到的,它并不像最初看起来那样明确。
TCP友好速率控制(TFRC)也使用了公平的概念。TFRC使用TCP吞吐量方程(在第1.3节中讨论)来估计由实现TCP拥塞控制方案的流所获得的拥塞链路带宽份额,并将其设置为应用程序发送数据的目标速率。然后应用程序可以做出决定,帮助它达到目标速率。例如,视频流应用程序可能会在一组不同的编码质量级别中进行选择,以尝试在由TFRC确定的"公平"级别上保持平均速率。
#### 3.3 比较分析
评估任何拥塞控制机制的第一步是单独衡量其性能,包括:
- 流能够达到平均吞吐量(goodput)。
- 流的平均端到端延迟体验。
- 机制应该避免跨一系列运维场景的持久化队列。
- 机制应该在一系列运维场景中都是稳定的。
- 流获得公平的可用容量份额的程度。
第二步是比较两种或更多机制。考虑到互联网的分布式特性,没有办法确保统一采用一种机制。比较吞吐量等量化指标很容易,问题是如何评估可能共存的、相互竞争网络资源的多种机制。
问题不在于某个给定机制是否能够公平对待所有流,而在于机制A是否能公平对待机制B管理的流。如果机制A能够提供比B更好的吞吐量,但也许是通过更积极的方式来做到这一点,因此,A会从B窃取带宽,那么A的改进就不是公平的,效果可能会大打折扣。很明显,互联网的高度分散的拥塞控制方法是有效的,大量的流以合作的方式响应拥塞,为更激进的流打开了大门,牺牲了那些实施了不那么激进的算法的流的性能。
>延伸阅读:\
>R. Ware, et al. [Beyond Jain’s Fairness Index: Setting the Bar for the Deployment of Congestion Control Algorithms](https://www.cs.cmu.edu/~rware/assets/pdf/ware-hotnets19.pdf "Beyond Jain’s Fairness Index: Setting the Bar for the Deployment of Congestion Control Algorithms"). ACM SIGCOMM HotNets. November 2019.
在过去30年里,这样的争论已经发生了很多次,这为部署新算法设置了很高的门槛。即使新算法的全球部署会产生净积极效果,增量部署(这是唯一的实际选择)仍然可能会对使用现有算法的流产生负面影响,导致大家不愿部署新方法。但正如Ranysha Ware及其同事所指出的那样,这种分析存在三个问题:
- **理想驱动的目标(Ideal-Driven Goalposting):** 基于公平的门槛决定了新机制B应该与当前部署的机制A平等共享瓶颈链接。这个目标在实践中太理想化了,特别是当A有时对自己的流也无法完全公平的时候。
- **以吞吐量为中心(Throughput-Centricity):** 基于公平的门槛关注新机制B如何通过关注A已实现的吞吐量来影响使用机制A的竞争流。然而,这忽略了其他重要的性能指标,如延迟、流完成时间或丢包率。
- **平衡假设(Assumption of Balance):** 机制间的相互作用通常具有某些偏见,但公平指标不能告诉我们结果是偏向于现状还是反对现状。就可部署性而言,新机制B比老机制A占用更大的带宽份额还是留给A更大的带宽份额是有区别的: 前者可能会引起老机制A用户的抱怨,而后者却不会。Jain公平指数对两种情况的打分基本一样。
相对于简单计算Jain公平指数,Ware主张使用基于丢包的阈值,以吞吐量的减少或延迟或抖动的增加来衡量。直观的说,如果使用新机制B的流对使用现有机制A的流造成的伤害在一个范围内,这个范围来源于A管理的某个流对其他流造成的伤害,我们可以认为B与A一起部署不会造成更多伤害。Ware继续提出了可接受伤害的具体测量方法,结果证明这比乍看起来要复杂得多。即使使用单一拥塞控制算法,一个流对另一个流造成的伤害也取决于RTT、启动时间和持续时间等因素。因此,对伤害的衡量需要考虑到在现有机制下,不同的流动对彼此的影响,并力求在新算法中没有变得更糟。
#### 3.4 实验方法
评估拥塞控制机制的方法是测量真实系统的性能,正如我们在第一章中指出的,Linux中实现的版本是各个机制的实际规范。我们现在介绍一种执行这些度量的广泛应用的具体方法,该方法使用了*Netesto(网络测试工具包, Network Test Toolkit)* ,这是GitHub上的一个软件工具集。此外还有基于模拟的方法,NS-3是最流行的开源工具。
>延伸阅读:\
>[Netesto](https://github.com/facebook/fbkutils/tree/master/netesto "Netesto")\
>[NS-3 Network Simulator](https://www.nsnam.org "NS-3 Network Simulator")
请注意,虽然本节介绍的实验测量了真正的拥塞控制算法(当然,我们还没有详细描述),目的是概述如何评估算法,而不是得出任何关于具体机制的结论。
##### 3.4.1 实验设置
我们在Linux主机上运行真正的TCP发送者/接收者,并使用```netem```和```tbf qdisc```等内核包来研究一系列行为,然后使用```tcpdump```收集性能数据。连接终端主机的网络是由一组真实的交换机和仿真组件构成的,可以支持如广域延迟和低带宽链路等场景。
实验沿着两个正交维度进行。一个是网络拓扑结构,包括链路带宽、RTT、缓冲区大小等。另一个维度是我们在网络上运行的流量负载,包括流的数量和持续时间,以及每个流的特征(例如,stream vs RPC)。
针对网络拓扑结构,我们评估了三种特定配置下的算法:
- 具有20μs RTT和10 Gbps链路带宽的局域网。这个场景表示同一数据中心机架中的服务器。
- 具有10ms RTT和10 Gbps链路带宽的广域网,通过配置一个20000个包的发送队列从而在接收端引入延迟。瓶颈是一个具有浅缓冲区(1-2 MB)的真实交换机。当观察两到三个流时,这是一个很好的可视化算法动态的场景。
- 具有40ms RTT和10/100 Mbps瓶颈带宽的广域网,通过引入中间路由器将链路带宽降低到10或100 Mbps。这个场景反映了终端用户在现代网络上可能体验到的连接。
图13展示了前两个场景的拓扑结构,其中发送方和接收方通过单个交换机连接。在第二个场景中,使用接收器中的```netem```实现延迟,只影响被发送回的ACK。
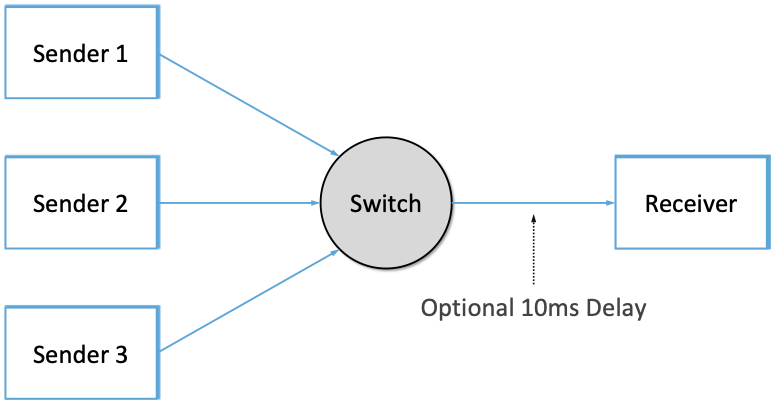
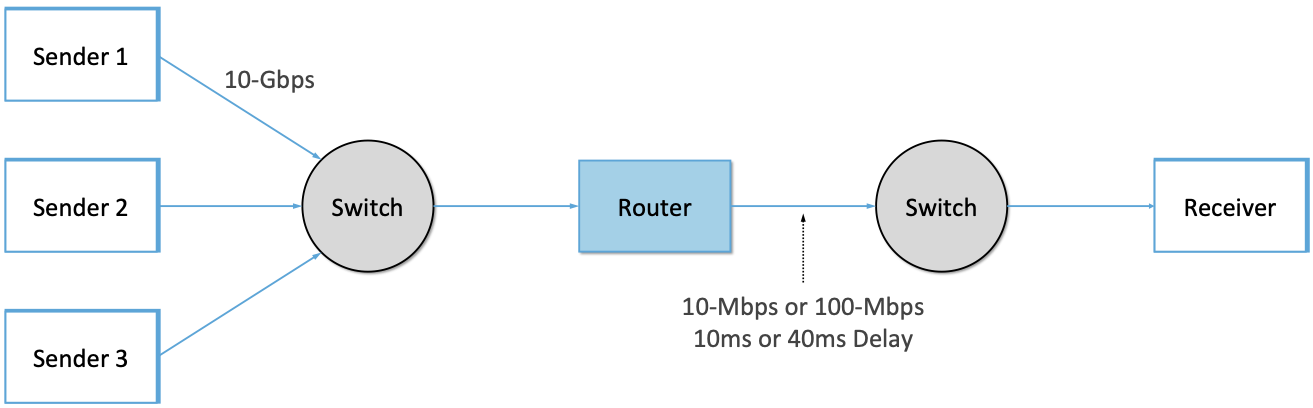
图14显示了第三种场景的拓扑结构,其中路由器由基于服务器的转发器实现,该转发器使用```tbf qdisc```限制出口链路带宽。
对于流量负载,我们通过以下测试来评估算法的动态性和公平性:
- 2-flow测试: 第一条流持续60秒,第二条流持续20秒并比第一条晚22秒开始。
- 3-flow测试: 第一条流60秒,第二条流40秒并比第一条流晚12秒开始,第三条流20秒并比第一条流晚26秒开始。
这些测试使下列工作成为可能:
- 检查现有流对新流的适应速度有多快。
- 检查流终止并释放的带宽被新流使用的速度有多快。
- 度量使用相同(或不同)拥塞算法的流之间的公平性。
- 度量拥堵程度。
- 识别性能发生突然变化的情况,显示可能的不稳定性。
其他测试包括组合流,外加10 KB和1 MB的RPC。这些测试允许我们查看较小的RPC流是否会受到影响,如果是的话,会受到多少影响。这些测试使下列工作成为可能:
- 研究在不断增加的负荷下的行为。
- 测量1 MB和10 KB流的性能(吞吐量和延迟),以及在它们之间分配可用带宽的公平程度。
- 识别重传或延迟发生突然变化时的情况,这是不稳定的信号。
##### 3.4.2 结果示例
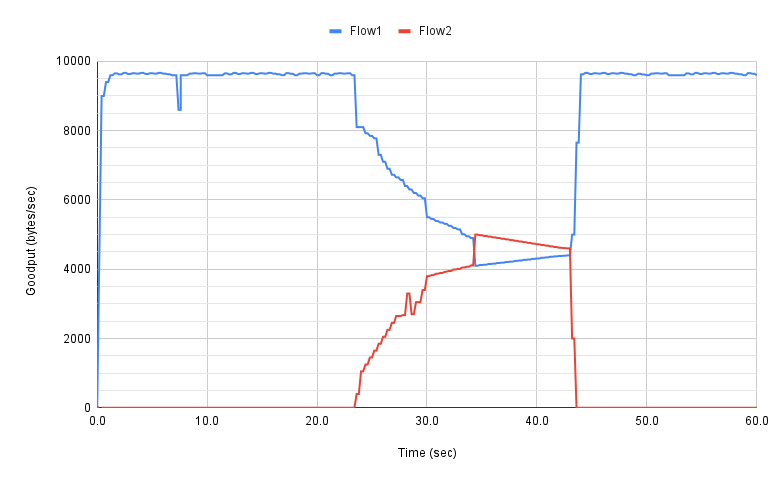
下面展示了一些示例结果,我们选取这些结果来说明评估过程。从一个简单的2-flow实验开始,其中两个流都由相同的拥塞控制算法管理。图15显示了生成的goodput图。正如人们所希望的那样,一旦第二个流(红色部分)在20秒后开始,两个流的就会收敛到几乎使用相等的可用带宽。这种收敛不会立即发生(两个图在第二个流开始大约10秒后交叉),其他算法试图纠正这种行为(例如,通过使用来自路由器的显式反馈)。有利的一面是,一旦第二个流结束,第一个流会很快使用释放的带宽。
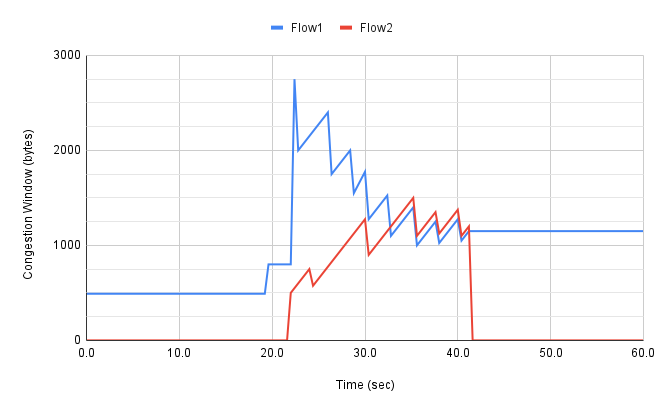
也可以更仔细观察这两个流,例如跟踪每个流的拥塞窗口。相应的图表如图16所示。毫不奇怪,随着时间的推移,不同的算法会有不同的"模式"来应对拥塞窗口,我们将在下一章中看到更多细节。
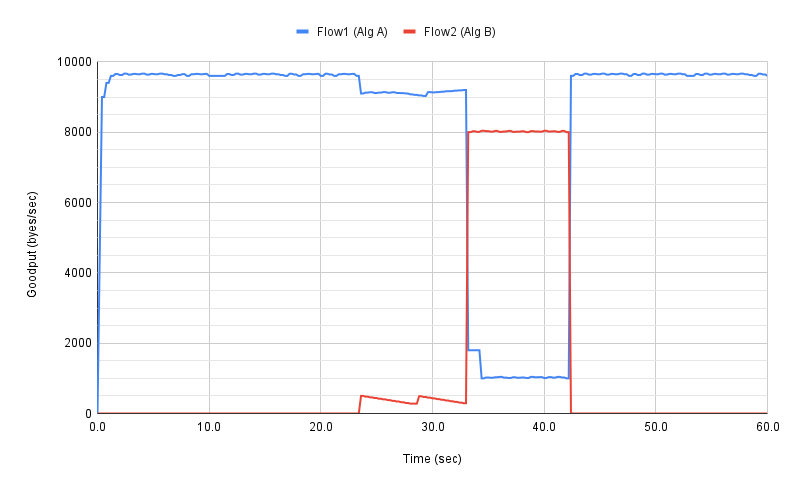
我们可以改变其中一个流程使用的算法来重复这些实验,从而可视化这两种算法是如何相互作用的。如果两者都是公平算法,我们将期望看到类似于图15的结果。如果没有,可能会看到类似于图17的结果,其中第二个流(算法B)积极的从第一个流(算法A)夺走带宽。
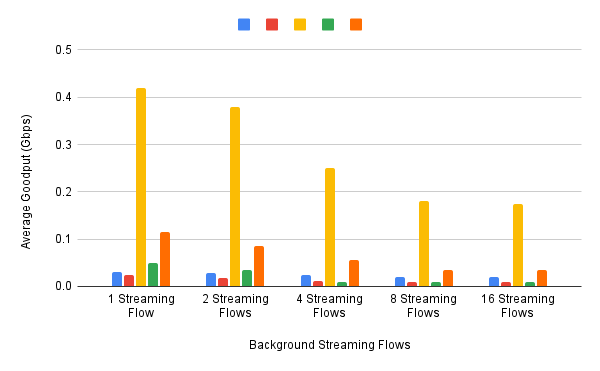
可以在三个并发流中重复实验,但我们接下来要评估各种算法如何处理不同的工作负载。特别的,我们对*大小公平(size fairness)* 问题感兴趣,也就是说,当给定算法必须与正在进行的流竞争时,如何处理连续的10 KB或1 MB RPC调用。图18 (1 MB的RPC)和图19 (10 KB的RPC)显示了一些示例结果。图中显示了五种不同算法(用不同颜色表示)的性能,测试了1、2、4、8和16个并发流。
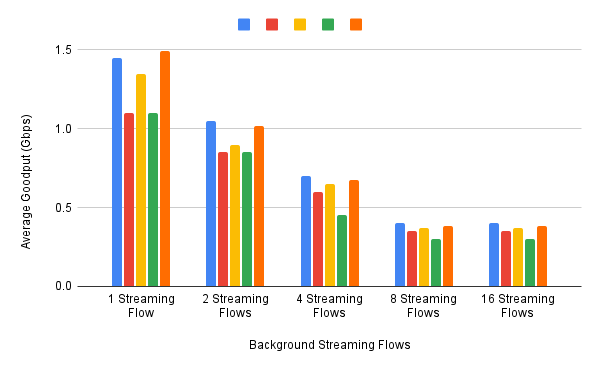
1 MB的结果并不令人惊讶,在五种算法中没有显著的异常值,并且随着rpc与越来越多的流竞争,平均goodput越来越低。虽然图18没有显示,但当所有流都基于stream时,第四个算法(绿色)的性能最好,避免了在RPC调用之间共享可用带宽时会发生的大量重传。
10 KB的结果有一个显著的异常值,第三个算法(黄色)的性能明显更好,差不多有4倍的优势。如果我们绘制延迟而不是带宽(这是和小消息RPC调用更相关的指标),则会发现第三种算法实现了最低的延迟,其P99和P999基本相同。
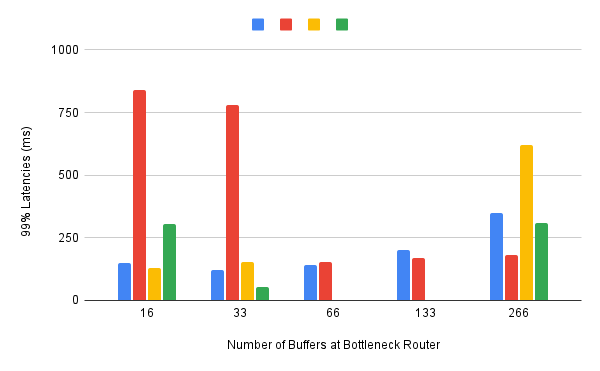
最后,可以在包含广域RTT的网络拓扑上重复上述所有实验。当然,流之间的公平性和流大小的公平性仍然值得关注,但排队延迟也可能成为问题。例如,图20显示了当网络拓扑包含10 Mbps瓶颈链路和40ms RTT时,四种不同算法的P99延迟。关于这个结果的重要结论是,当瓶颈路由器上可用的缓冲的带宽时延积小于一个单位时,第二种算法(红色)的性能很差,这引起了对另一个可能影响结果的变量的注意。
最后我们通过一个总结结束对实验方法的讨论。当观察一组算法和一系列拓扑/流量场景时,可以得出结论: *没有任何一种算法在所有条件下优于所有其他算法*。这些例子证明了,有很多因素需要考虑。这也解释了为什么拥塞控制一直是网络研究者和实践者都感兴趣的话题。
>你好,我是俞凡,在Motorola做过研发,现在在Mavenir做技术工作,对通信、网络、后端架构、云原生、DevOps、CICD、区块链、AI等技术始终保持着浓厚的兴趣,平时喜欢阅读、思考,相信持续学习、终身成长,欢迎一起交流学习。 \
>微信公众号:DeepNoMind


