

前言
使用npm install这个条命令对于我们前端开发者来说应该是形成“肌肉记忆”,之前一直对 npm 的相关知识停留在“会用”的阶段,但是内部的原理却不甚了解。直到项目中出现了一次由 npm 包引起的问题后,才开始下决心对 npm 包其中的工作流程做一个详细的梳理。
npm install 大概会经过以下图例中的几个阶段,下文将会梳理各个流程的实现细节,以及设计背景。
检查 Config
这是执行npm install之后的第一个阶段,这个阶段主要做的工作是根据当前项目中 NPM 的 Config 作为启动安装的配置,在终端中输入npm config ls -l后即可查看当前的 npm config 如下图,这其中包括了我们常用的 npm 包安装源、npm 包的命名空间、缓存以及缓存的行为等
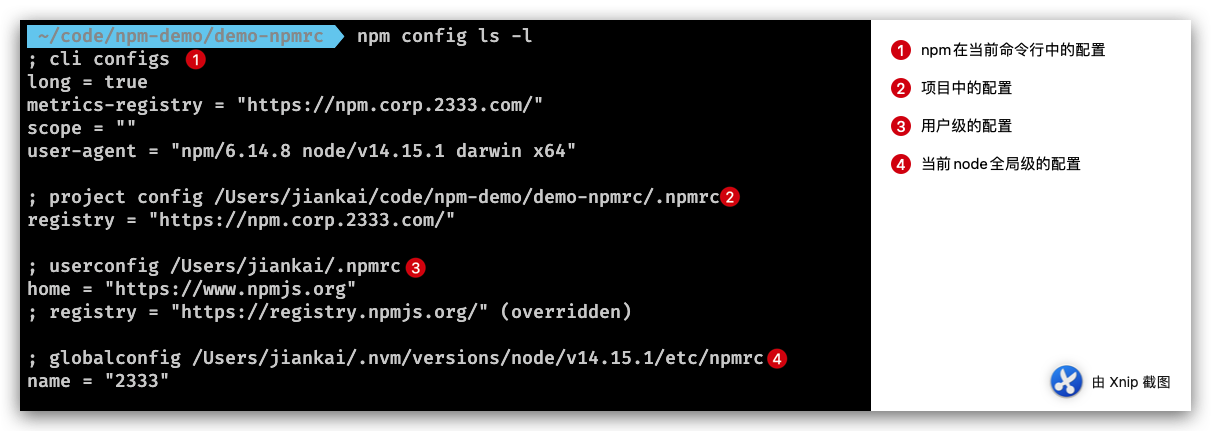
Npm 支持在不同层级中使用配置项,并且具备不同的优先级。例如上图中显示的四个层级的配置项(按照优先级从高到低逐个解释):
-
cli configs(优先级最高): 指的是当前 npm 执行命令中加入的 一些配置(和一些默认值),例如在执行时设置了 registry 后,对应配置项便会在这里输出。 -
project config: 如果当前目录中存在.npmrc文件,则会显示 Project config 即项目配置。例如团队内部存在私有 npm 源,为了在项目中统一配置,则可以在项目中添加配置了registry的.npmrc 文件 -
userconfig: 系统用户层级的配置,一般执行npm config set命令默认修改的都是这一层级的配置。另外补充上图,由于 userconfig 与 project config 的 registry 产生了冲突,且由于前者优先级较低,所以在上图中 userconfig 配置项的 registry 为 overridden,未生效被重写的状态。 -
globalconfig: 当前 Node 环境中的全局配置,一般通过npm config set xx --global修改,该配置的“全局”并不是当前操作系统的全局,而是当前 Node 环境,为什么强调这一点呢,这是因为多数情况我们会安装 nvm 切换多个版本的 Node, 而这里的配置项在各个版本的 Node 中是隔离的,很容易被字面意思上的“全局”给误导。
除了cli configs之外,其他所有层级的配置都存放在对应目录下的.npmrc 文件中,读取.npmrc文件的优先级为:项目级的 .npmrc 文件 > 用户级的 .npmrc 文件 > Node 全局 .npmrc 文件。当 npm 将各个层级的配置项检查并整理完毕后,便进入下一步——检查 Package- lock 文件。
Package-lock.json
从文章开头的说明图里其实可以看出,是否存在有效的 package-lock 文件将会决定从npm服务端获取包信息和构建依赖树这两步工作是否要执行
Package-lock 文件实际上是npm 5.x 版本新增文件,它的作用是锁定依赖结构,即只要你目录下有 package-lock.json 文件,那么你每次执行 npm install 后生成的 node_modules 目录结构一定是完全相同的。
例如当前需要安装的依赖包如下
{
"name": "npm-demo",
"dependencies": {
"buffer": "^6.0.3",
"ignore": "^5.1.9"
}
}
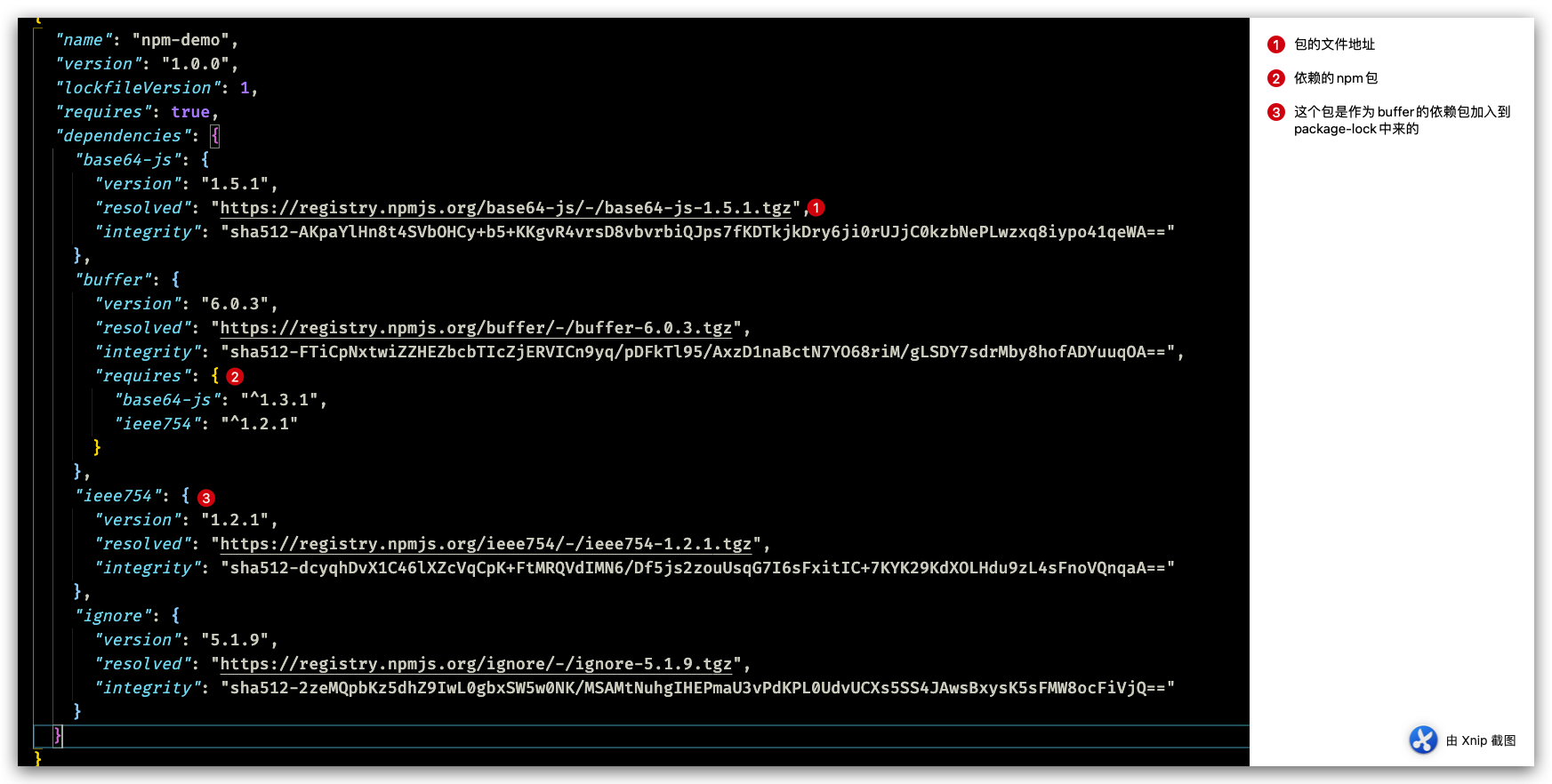
其中ignore没有其他依赖项,而buffer还依赖base64-js和ieee754:
安装时的请求如下图,可以看到总共发起了 8 次请求。
当存在 package-lock.json 后,可以看到网络请求如下图,总共仅发送了 4 个安包的请求:
生成的 package-lock.json 如下
除此之外,我们还知道npm包 中的模块版本都需要遵循 SemVer规范, 因此我们安装依赖包的时候版本很多时候是不固定的,这就导致某些时候会由于版本的原因出现一些意料之外的报错。
semver规范 semver.org/
但是在使用 package-lock 后,这个问题得以解决。一旦执行npm install 后, 所有依赖包的完整性信息(版本、包的下载地址、sha512 文件摘要)都将会保存在这个文件中,后续如果需要重新安装依赖,则会直接从 package-lock 文件中读取,极大的提升了安装的效率。
构建依赖树
所谓依赖树就是 npm 包与其依赖包之间的关系,主要体现在node_modules内部的目录结构上。这里根据 NPM 在不同时期的表现上,可以分为两种·嵌套结构和扁平结构
嵌套模式
在早期的 npm1、npm2 中呈现出的是嵌套结构,就是说了每个依赖项自己的依赖都是存放自己的 node_modules 文件夹下。例如上面上面的例子中,执行 npm install 后,得到的 node_modules 中模块目录结构就是下面这样的:
这样的方式优点很明显, node_modules 的结构和 package.json 结构一一对应,层级结构明显,并且保证了每次安装目录结构都是相同的。
但是,试想一下如果 base64-js 当中又有依赖,那么又会继续嵌套下去,这样的设计存在一些问题:
- 依赖层级太深,会导致文件路径过长的问题,尤其在 window 系统下(文件路径最大长度为 260 个字符)。
- 大量重复的包被安装,文件体积超级大。比如上例中的
buffer同级目录下的ignore如果也依赖相同版本的base64-js,那么 base64-js 会分别在两者的 node_modules 中被安装,也就是重复安装。
扁平模式
为了解决以上问题,NPM 在 3.x 版本做了一次较大更新。其将早期的嵌套结构改为扁平结构:
- 安装模块时,不管其是直接依赖还是子依赖的依赖,优先将其安装在
node_modules根目录。
还是上面的依赖结构,我们在执行 npm install 后将得到下面的目录结构:
可以看出buffer的两个依赖包都被安装到了 node_modules 根目录下。这确实缓解了嵌套模式的两个问题,减少了包的冗余
此时我们若在模块中又依赖了 base64-js@1.0.1 版本:
{
"name": "npm-demo",
"dependencies": {
"base64-js": "1.0.1",
"buffer": "^6.0.3",
"ignore": "^5.1.9"
}
}
- 当安装到相同模块时,判断已安装的模块版本是否符合新模块的版本范围,如果符合则跳过,不符合则在当前模块的
node_modules下安装该模块。
此时,我们在执行 npm install 后将得到下面的目录结构:
由于 buffer 依赖的 base64-JS 与当前项目依赖的 base64-JS 版本范围并不一致,因此前者被安装在了 buffer 文件夹下。
对应的,如果我们在项目代码中引用了一个模块,模块查找也进行了调整,流程如下:
- 在当前模块路径下搜索
- 在当前模块
node_modules路径下搜素 - 在上级模块的
node_modules路径下搜索 - ...
- 直到搜索到全局路径中的
node_modules
假设我们又依赖了一个包 buffer2@^6.0.3,而它也依赖了包 base64-js@^1.3.1,则此时的安装结构是下面这样的:
不难看出,由于项目存在base64-js@1.0.1不满足其他模块依赖的版本范围,因此仍然出现了冗余。所以 npm 3.x 版本并未完全解决老版本的模块冗余问题——甚至还会带来新的问题。
这里梳理了一下扁平化主要的问题:
- 依赖结构的不确定性。
- 扁平化算法本身的复杂性很高,耗时较长。
- 项目中可以非法访问没有声明过依赖的包
后两个其实比较好理解,至于第一个依赖结构的不确定性这里可以举个例子解释下
假设两个不同的模块分别依赖了同一个模块,但是版本范围不一致
当项目用依赖了这两个模块,在构建依赖树时是这样的?
又或是这样?
答案是都有可能,这两种形式完全取决于buffer和 buffer2 在 package.json 中的声明顺序。
另外,为了让开发者在安全的前提下使用最新的依赖包,我们在 package.json 通常只会锁定大版本,这意味着在某些依赖包小版本更新后,同样可能造成依赖结构的改动,依赖结构的不确定性可能会给程序带来不可预知的问题。
这就是为什么会产生依赖结构的不确定问题,也是 package-lock 文件诞生的原因——为了保证 install 之后都产生确定的node_modules结构。
缓存
为了加快 npm 安装的效率,在执行 npm install 或 npm update命令下载依赖后,会存放到本地的缓存目录中,然后再将对应的的依赖复制到项目的node_modules 目录下。
通过 npm config get cache 命令可以查询到:在 Linux 或 Mac 默认是用户主目录下的 .npm/_cacache 目录。
在这个目录下又存在两个目录:content-v2、index-v5,content-v2 目录用于存储 tar包的缓存,而index-v5目录用于存储tar包的 hash。
npm(5.x) 在执行安装时,可以根据 package-lock.json 中存储的 integrity、version、name 生成一个唯一的 key 对应到 index-v5 目录下的缓存记录,从而找到 tar包的 hash,然后根据 hash 再去找缓存的 tar包直接使用。
我们可以找一个包在缓存目录下搜索测试一下,在 index-v5 搜索一下包路径:
grep https://npm.corp.kuaishou.com/base64-js/-/base64-js-1.0.1.tgz -r index-v5
命令执行后会返回对应的 hash 存放路径,这里是0d/dd目录下
打开文件,并格式化为 JSON 后,可以看到存在_shasum 字段,该字段表示这个库的缓存 hash,该值的前四位便表示在 content-v2/sha1 中的路径,例如这里是 6926,则表示content-v2/sha1/69/26目录下
基于缓存数据,npm 提供了离线安装模式,分别有以下几种:
--prefer-offline: 优先使用缓存数据,如果没有匹配的缓存数据,则从远程仓库下载(默认)。--prefer-online: 优先使用网络数据,如果网络数据请求失败,再去请求缓存数据,这种模式可以及时获取最新的模块。--offline: 不请求网络,直接使用缓存数据,一旦缓存数据不存在,则安装失败。
文件完整性
上面我们多次提到了文件完整性,那么什么是文件完整性校验呢?
在下载依赖包之前,我们一般就能拿到 npm 对该依赖包计算的 hash 值,例如我们执行 npm info 命令,紧跟 tarball(下载链接) 的就是 shasum(hash) :
用户下载依赖包到本地后,需要确定在下载过程中没有出现错误,所以在下载完成之后需要在本地在计算一次文件的 hash 值,如果两个 hash 值是相同的,则确保下载的依赖是完整的,如果不同,则进行重新下载。
整体流程梳理
-
检查 config
-
检查项目中有无
lock文件。 -
无
lock文件:-
从
npm远程仓库获取包信息 -
根据 package.json 构建依赖树,构建过程:
- 构建依赖树时,不管其是直接依赖还是子依赖的依赖,优先将其放置在
node_modules根目录。 - 当遇到相同模块时,判断已放置在依赖树的模块版本是否符合新模块的版本范围,如果符合则跳过,不符合则在当前模块的
node_modules下放置该模块。 - 注意这一步只是确定逻辑上的依赖树,并非真正的安装,后面会根据这个依赖结构去下载或拿到缓存中的依赖包
- 构建依赖树时,不管其是直接依赖还是子依赖的依赖,优先将其放置在
-
在缓存中依次查找依赖树中的每个包
-
不存在缓存:
-
从
npm远程仓库下载包 -
校验包的完整性
-
校验不通过:
- 重新下载
-
校验通过:
- 将下载的包复制到
npm缓存目录 - 将下载的包按照依赖结构解压到
node_modules
- 将下载的包复制到
-
-
存在缓存:将缓存按照依赖结构解压到
node_modules
-
-
将包解压到
node_modules -
生成
lock文件
-
看见未来
除了 npm 之外,还有还有第三方包管理工具值得推荐,这里介绍两款分别是yarn和pnpm
YARN
yarn 是在 2016 年发布的,那时 npm 还处于 V3 时期,那时候还没有 package-lock.json 文件,就像上面我们提到的:不稳定性、安装速度慢等缺点经常会受到广大开发者吐槽。此时,yarn 诞生:
上面是官网提到的 yarn 的优点,在那个时候还是非常吸引人的。当然,后来 npm 也意识到了自己的问题,进行了很多次优化,在后面的优化(lock文件、缓存、默认-s...)中,我们多多少少能看到 yarn 的影子,可见 yarn 的设计还是非常优秀的。
yarn 也是采用的是 npm v3 的扁平结构来管理依赖,执行yarn安装依赖后默认会生成一个 yarn.lock 文件,还是上面的依赖关系,我们看看 yarn.lock 的结构:
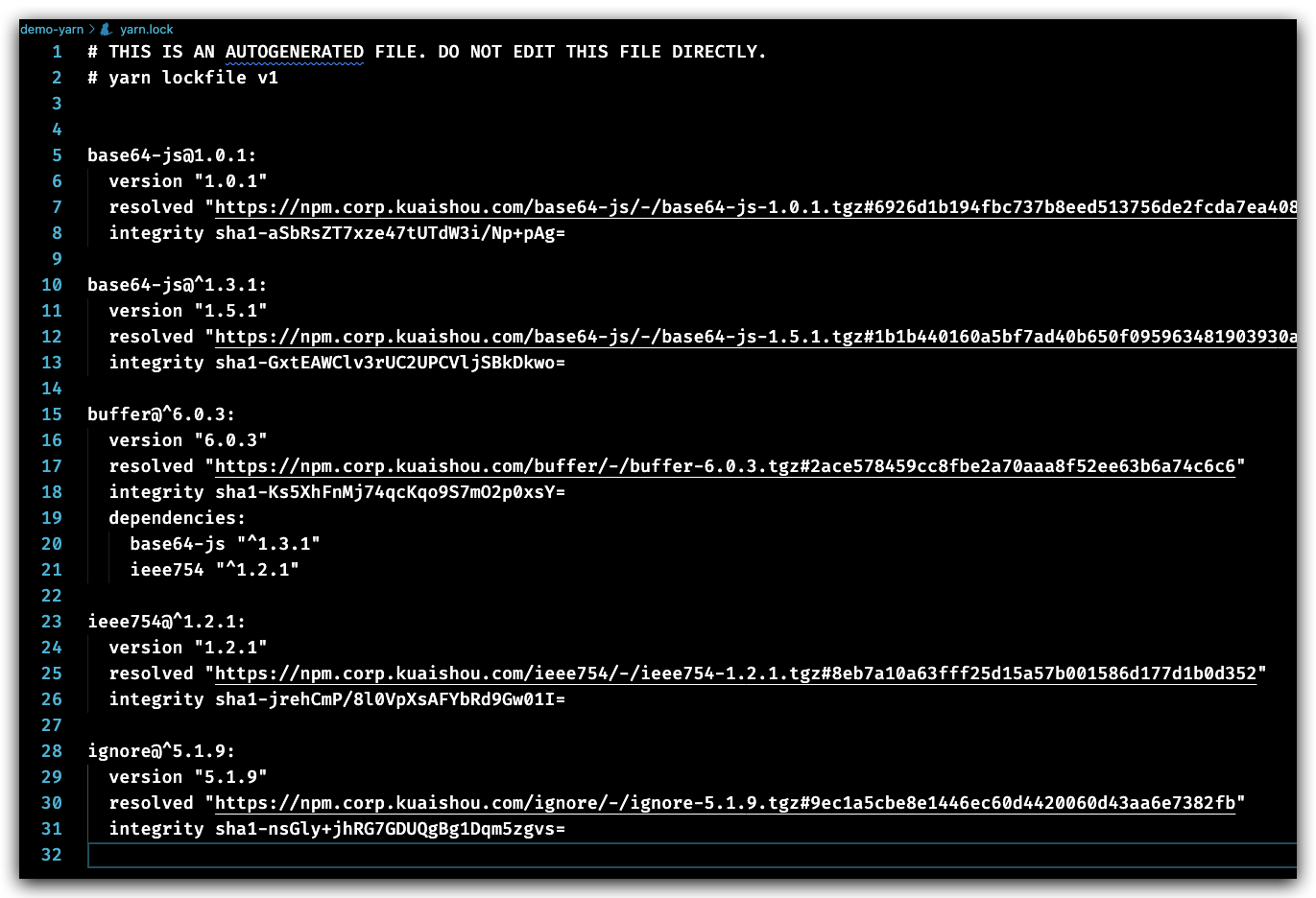
可见其和 package-lock.json 文件还是比较类似的。
yarn 的缓存结构和 npm v5 之前的比较像,每个缓存的模块被存放在独立的文件夹,文件夹名称包含了模块名称、版本号以及 hash 等信息。使用命令 yarn cache dir 可以查看缓存数据的目录:
在缓存策略上和 npm 相反,yarn 默认使用 prefer-online 模式,即优先使用网络数据,如果网络数据请求失败,再去请求缓存数据。
除此之外,Yarn 还具有 pnp 的一个特性 「classic.yarnpkg.com/en/docs/pnp…」
按照普通的按照流程, npm/yarn 会生成一个 node_modules 目录, 然后 Node 按照它的模块查找规则在 node_modules 目录中查找. 但实际上 Node 并不知道这个模块是什么, 它在 node_modules 查找, 没找到就在父目录的 node_modules 查找, 以此类推. 这个效率是非常低下的.
但是 Yarn 作为一个包管理器, 它知道你的项目的依赖树. 那能不能让 Yarn 告诉 Node? 让它直接到某个目录去加载模块. 这样即可以提高 Node 模块的查找效率, 也可以减少 node_modules 文件的拷贝. 这就是Plug'n'Play的基本原理.
简单来说在 pnp 模式下, Yarn 不会创建 node_modules 目录, 取而代之的是一个.pnp.js文件, 这是一个 node 程序, 这个文件包含了项目的依赖树信息, 模块查找算法等等。
yarn 默认并不会使用Pnp,需要在 package.json 中加入下面的配置后,重新安装依赖即可
"installConfig": {
"pnp": true
}
PNPM
pnpm 是新一代的现代化包管理工具,它的**官方文档**是这样说的:
Fast, disk space efficient package manager
- 包安装速度极快;
- 磁盘空间利用高效。
安装:
npm i pnpm -g
速度快
这里放一张社区上的数据对比图,作为黄色部分的 pnpm,在绝多大数场景下,包安装的速度都是明显优于 npm/yarn/yarn PNP,绝大部分场景下速度甚至比他们快 2-3 倍。
依赖树(高效利用磁盘空间)
之前不论是 NPM 还是 YARN(非 PNP 模式),都没有彻底解决规避非法访问依赖和重复安装的风险,pnpm 的作者Zoltan Kochan发现 yarn 并没有打算去解决上述的这些问题,于是另起炉灶,写了全新的包管理器,开创了一套新的依赖管理机制。
还是以上面的依赖举例,执行安装
pnpm i
我们再去看看node_modules:
我们直接就看到那三个熟悉的依赖包,但值得注意的是这三个依赖后面都有小箭头,表示他们都只是软链接,指向的地址实际在.Pnpm 文件夹中
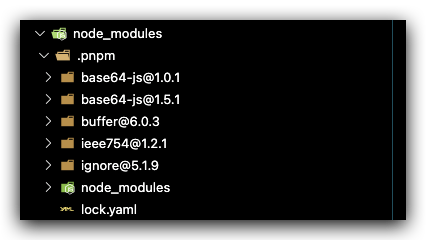
例如 buffer@6.0.3,存放的实际位置为
注意这里有三个文件,其中 base64-js/ieee754 是软链,被指向了.pnpm 目录下的对应包地址。
而项目根目录下 node_module 中指向的 buffer 即指向这里的 buffer 文件夹。
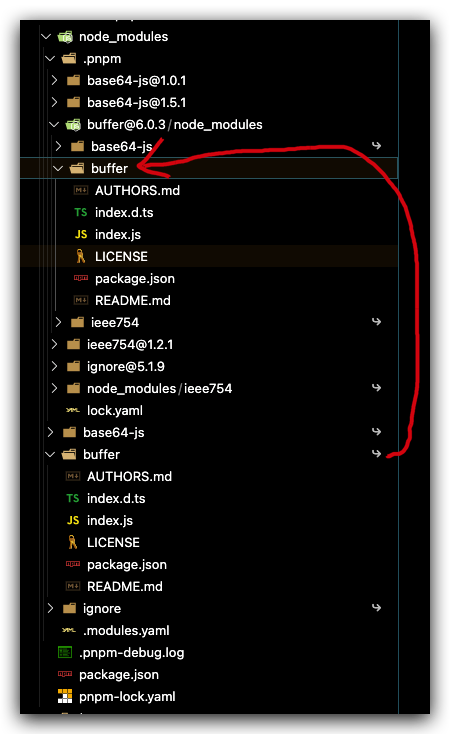
将包本身和依赖放在同一个node_module下面,与原生 Node 完全兼容,又能将 package 与相关的依赖很好地组织到一起,设计十分精妙。通过软链实现的嵌套模式,将之前最大的问题——模块安装冗余问题得到解决。
并且 pnpm 这种依赖管理的方式也很巧妙地规避了在 npm/yarn 中暂未得到解决的非法访问依赖的问题,也就是只要一个包未在 package.json 中声明依赖,那么在项目中是无法访问的。
支持 monorepo
monorepo 的宗旨就是用一个 git 仓库来管理多个子项目,所有的子项目都存放在根目录的packages目录下,那么一个子项目就代表一个package。并通过 lerna 来进行管理。这里包括 elementUI-plus 以及我们的业务也都用到了这项技术概念。
我们在实际开发中可能都会遇到如果想要给所有 package 添加一个包,需要在项目根目录下执行 npm i 后还要执行一遍 lerna 的命令。而 pnpm 与 npm/yarn 另外一个很大的不同就是支持了 monorepo,体现在各个子命令的功能上,比如在根目录下 pnpm add A -r, 那么所有的 package 中都会被添加 A 这个依赖,当然也支持 --filter字段来对 package 进行过滤。
总结
目前来看 npm 在实际开发中还是有一定的缺陷,但是不得不承认它是成熟和稳定的一项包管理工具。并且它随 node 一起提供,目前能以足够好的方式处理包管理。作为开发者,我更希望 npm 能够受到社区这些有意思的包管理工具中受到启发(就像 yarn 一样),提供更好用的 npm。
