

与其他编程练习相比,机器学习项目是代码和数据的融合。你需要两者来实现结果,做一些有用的事情。多年来,许多知名的数据集已经被创建,而且许多已经成为标准或基准。在本教程中,我们将看到如何轻松获得那些知名的公共数据集。我们还将学习,如果现有的数据集都不符合我们的需要,如何制作一个合成数据集。
完成本教程后,你将知道。
- 在哪里为机器学习项目寻找免费的数据集?
- 如何使用Python中的库下载数据集
- 如何使用scikit-learn生成合成数据集
让我们开始吧。

教程概述
本教程分为四个部分;它们是。
- 数据集存储库
- 在scikit-learn和Seaborn中检索数据集
- 在TensorFlow中检索数据集
- 在scikit-learn中生成数据集
数据集存储库
机器学习已经发展了几十年,因此有一些具有历史意义的数据集。这些数据集的最著名的资料库之一是UCI机器学习资料库。那里的大多数数据集都是小尺寸的,因为当时的技术还不够先进,无法处理较大尺寸的数据。位于这个资源库中的一些著名的数据集是虹膜花数据集(由罗纳德-费舍尔在1936年推出)和20个新闻组数据集(通常由信息检索文献提及的文本数据)。
较新的数据集通常规模较大。例如,ImageNet数据集就超过160GB。这些数据集在Kaggle中很常见,我们可以通过名字搜索它们。如果我们需要下载它们,建议在注册账户后使用Kaggle的命令行工具。
OpenML是一个较新的资源库,承载了大量的数据集。它很方便,因为你可以通过名字搜索数据集,但它也有一个标准化的网络API供用户检索数据。如果你想使用Weka,它会很有用,因为它提供ARFF格式的文件。
但是,仍然有很多数据集是公开的,但是由于各种原因没有在这些资源库中。你可能还想看看维基百科上的 "机器学习研究的数据集清单 "页面机器学习研究的数据集清单"。该页面包含了一长串归属于不同类别的数据集,并附有下载链接。
在scikit-learn和Seaborn中检索数据集
琐碎的是,你可以通过浏览器、通过命令行、使用wget 工具或使用网络库(如Python中的requests )从网上下载这些数据集来获得这些数据。由于其中一些数据集已经成为一种标准或基准,许多机器学习库已经创建了函数来帮助检索它们。由于实际的原因,数据集往往不是随库提供的,而是在你调用这些函数时实时下载的。因此,你需要有一个稳定的网络连接来使用它们。
Scikit-learn就是一个例子,你可以使用其API下载数据集。相关的函数被定义在sklearn.datasets,,你可以在下面看到函数的列表。
例如,你可以使用函数load_iris() 来获得鸢尾花数据集,如下所示。
import sklearn.datasets
data, target = sklearn.datasets.load_iris(return_X_y=True, as_frame=True)
data["target"] = target
print(data)
load_iris() 函数将返回numpy数组(即没有列头)而不是pandas DataFrame,除非指定参数as_frame=True 。同时,我们将return_X_y=True ,所以只返回机器学习特征和目标,而不是一些元数据,如数据集的描述。上述代码的打印结果如下。
sepal length (cm) sepal width (cm) petal length (cm) petal width (cm) target
0 5.1 3.5 1.4 0.2 0
1 4.9 3.0 1.4 0.2 0
2 4.7 3.2 1.3 0.2 0
3 4.6 3.1 1.5 0.2 0
4 5.0 3.6 1.4 0.2 0
.. ... ... ... ... ...
145 6.7 3.0 5.2 2.3 2
146 6.3 2.5 5.0 1.9 2
147 6.5 3.0 5.2 2.0 2
148 6.2 3.4 5.4 2.3 2
149 5.9 3.0 5.1 1.8 2
[150 rows x 5 columns]
分开特征和目标对于训练scikit-learn模型是很方便的,但是把它们结合起来对于可视化会有帮助。例如,我们可以像上面那样结合DataFrame,然后用Seaborn将相关图可视化。
import sklearn.datasets
import matplotlib.pyplot as plt
import seaborn as sns
data, target = sklearn.datasets.load_iris(return_X_y=True, as_frame=True)
data["target"] = target
sns.pairplot(data, kind="scatter", diag_kind="kde", hue="target",
palette="muted", plot_kws={'alpha':0.7})
plt.show()
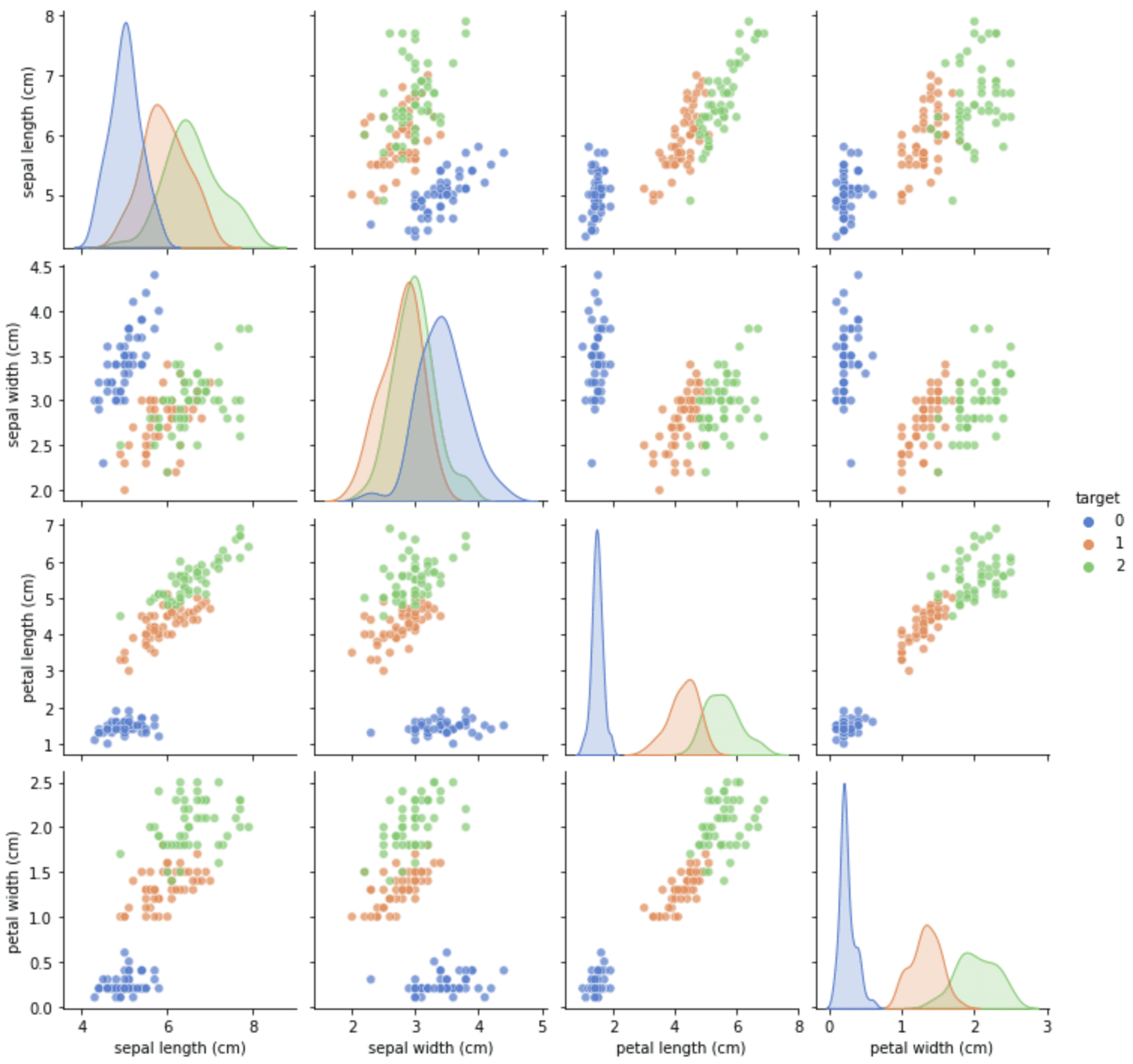
从相关图中,我们可以看到,目标0很容易区分,但目标1和2通常有一些重叠。因为这个数据集对演示绘图函数也很有用,我们可以从Seaborn中找到等效的数据加载函数。我们可以把上面的内容改写成以下内容。
import matplotlib.pyplot as plt
import seaborn as sns
data = sns.load_dataset("iris")
sns.pairplot(data, kind="scatter", diag_kind="kde", hue="species",
palette="muted", plot_kws={'alpha':0.7})
plt.show()
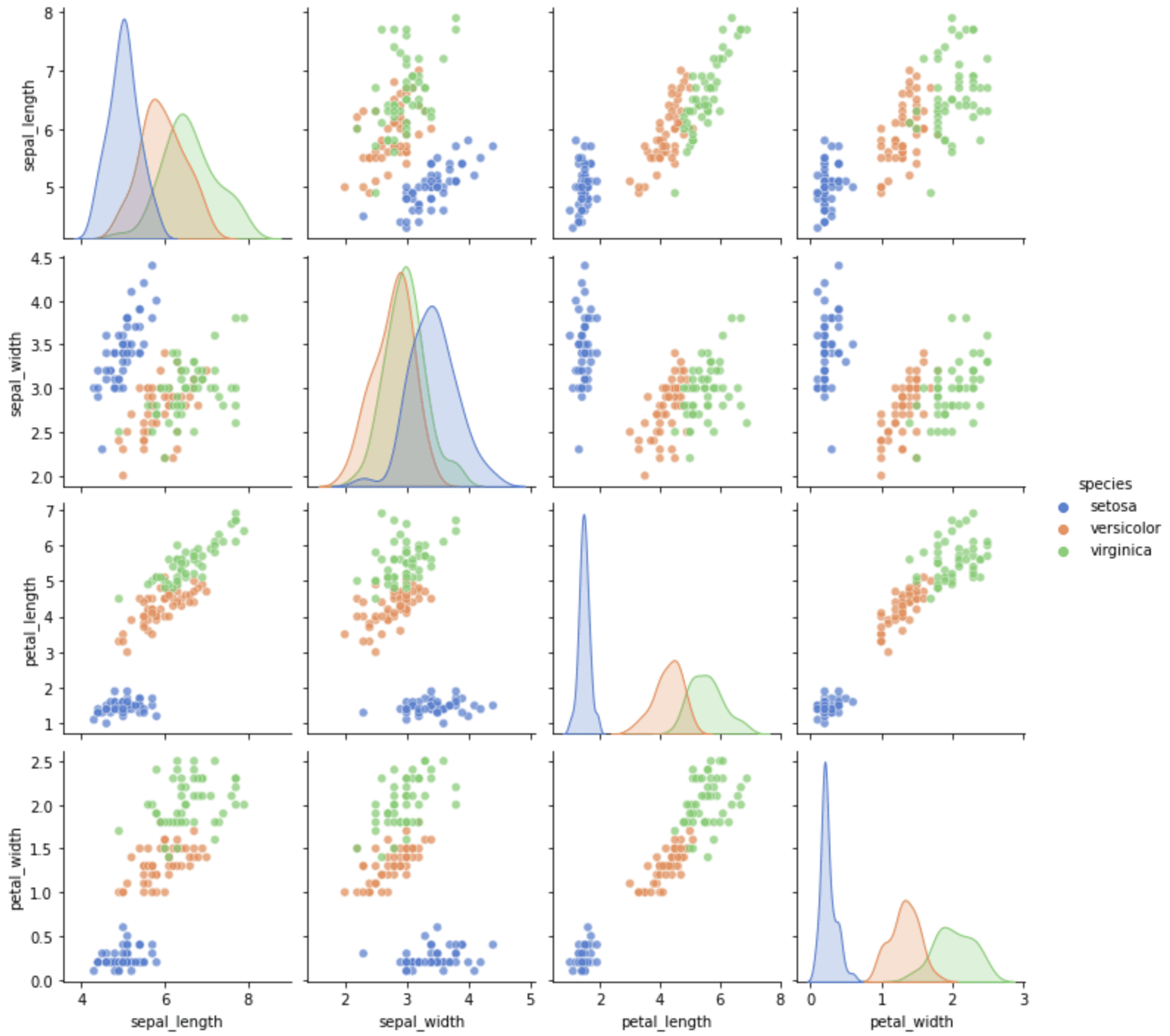
Seaborn支持的数据集是比较有限的。我们可以通过运行看到所有支持的数据集的名称。
import seaborn as sns
print(sns.get_dataset_names())
其中以下是Seaborn的所有数据集。
['anagrams', 'anscombe', 'attention', 'brain_networks', 'car_crashes','diamonds', 'dots', 'exercise', 'flights', 'fmri', 'gammas', 'geyser','iris', 'mpg', 'penguins', 'planets', 'taxis', 'tips', 'titanic']
有一些类似的函数可以从scikit-learn加载 "玩具数据集"。例如,我们有load_wine() 和load_diabetes() ,定义方式类似。
更大的数据集也是类似的。例如,我们有fetch_california_housing() ,它需要从互联网上下载数据集(因此函数名中有 "fetch")。Scikit-learn文档称这些为 "真实世界的数据集",但事实上,玩具数据集也同样是真实的。
import sklearn.datasets
data = sklearn.datasets.fetch_california_housing(return_X_y=False, as_frame=True)
data = data["frame"]
print(data)
MedInc HouseAge AveRooms AveBedrms Population AveOccup Latitude Longitude MedHouseVal
0 8.3252 41.0 6.984127 1.023810 322.0 2.555556 37.88 -122.23 4.526
1 8.3014 21.0 6.238137 0.971880 2401.0 2.109842 37.86 -122.22 3.585
2 7.2574 52.0 8.288136 1.073446 496.0 2.802260 37.85 -122.24 3.521
3 5.6431 52.0 5.817352 1.073059 558.0 2.547945 37.85 -122.25 3.413
4 3.8462 52.0 6.281853 1.081081 565.0 2.181467 37.85 -122.25 3.422
... ... ... ... ... ... ... ... ... ...
20635 1.5603 25.0 5.045455 1.133333 845.0 2.560606 39.48 -121.09 0.781
20636 2.5568 18.0 6.114035 1.315789 356.0 3.122807 39.49 -121.21 0.771
20637 1.7000 17.0 5.205543 1.120092 1007.0 2.325635 39.43 -121.22 0.923
20638 1.8672 18.0 5.329513 1.171920 741.0 2.123209 39.43 -121.32 0.847
20639 2.3886 16.0 5.254717 1.162264 1387.0 2.616981 39.37 -121.24 0.894
[20640 rows x 9 columns]
如果我们需要的不仅仅是这些,scikit-learn提供了一个方便的函数来从OpenML中读取任何数据集。比如说。
import sklearn.datasets
data = sklearn.datasets.fetch_openml("diabetes", version=1, as_frame=True, return_X_y=False)
data = data["frame"]
print(data)
preg plas pres skin insu mass pedi age class
0 6.0 148.0 72.0 35.0 0.0 33.6 0.627 50.0 tested_positive
1 1.0 85.0 66.0 29.0 0.0 26.6 0.351 31.0 tested_negative
2 8.0 183.0 64.0 0.0 0.0 23.3 0.672 32.0 tested_positive
3 1.0 89.0 66.0 23.0 94.0 28.1 0.167 21.0 tested_negative
4 0.0 137.0 40.0 35.0 168.0 43.1 2.288 33.0 tested_positive
.. ... ... ... ... ... ... ... ... ...
763 10.0 101.0 76.0 48.0 180.0 32.9 0.171 63.0 tested_negative
764 2.0 122.0 70.0 27.0 0.0 36.8 0.340 27.0 tested_negative
765 5.0 121.0 72.0 23.0 112.0 26.2 0.245 30.0 tested_negative
766 1.0 126.0 60.0 0.0 0.0 30.1 0.349 47.0 tested_positive
767 1.0 93.0 70.0 31.0 0.0 30.4 0.315 23.0 tested_negative
[768 rows x 9 columns]
有时候,我们不应该用名字来识别OpenML中的数据集,因为可能有多个同名的数据集。我们可以在OpenML上搜索数据ID,并在函数中使用它,如下所示。
import sklearn.datasets
data = sklearn.datasets.fetch_openml(data_id=42437, return_X_y=False, as_frame=True)
data = data["frame"]
print(data)
上面的代码中的数据ID指的是泰坦尼克号数据集。我们可以将代码扩展为以下内容,以显示我们如何获得titanic数据集,然后运行逻辑回归。
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import fetch_openml
X, y = fetch_openml(data_id=42437, return_X_y=True, as_frame=False)
clf = LogisticRegression(random_state=0).fit(X, y)
print(clf.score(X,y)) # accuracy
print(clf.coef_) # coefficient in logistic regression
0.8114478114478114
[[-0.7551392 2.24013347 -0.20761281 0.28073571 0.24416706 -0.36699113
0.4782924 ]]
在TensorFlow中检索数据集
除了scikit-learn,TensorFlow是另一个我们可以用于机器学习项目的工具。出于类似的原因,TensorFlow也有一个数据集API,它能以最适合TensorFlow的格式给你数据集。与scikit-learn不同,该API不是标准TensorFlow包的一部分。你需要用命令来安装它。
pip install tensorflow-datasets
所有数据集的列表可以在目录上找到。
所有的数据集都由一个名称来标识。这些名称可以在上面的目录中找到。你也可以用下面的方法得到一个名字的列表。
import tensorflow_datasets as tfds
print(tfds.list_builders())
它可以打印出1000多个名字。
作为一个例子,我们选取MNIST手写数字数据集作为一个例子。我们可以按以下方式下载数据。
import tensorflow_datasets as tfds
ds = tfds.load("mnist", split="train", shuffle_files=True)
print(ds)
这向我们表明,tfds.load() 给我们一个类型为tensorflow.data.OptionsDataset 的对象。
<_OptionsDataset shapes: {image: (28, 28, 1), label: ()}, types: {image: tf.uint8, label: tf.int64}>
特别是,这个数据集的数据实例(图像)是一个形状为(28,28,1)的numpy数组,而目标(标签)是标量。
在稍加润色后,该数据就可以在Keras的fit() 函数中使用了。一个例子如下。
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, Dense, AveragePooling2D, Dropout, Flatten
from tensorflow.keras.callbacks import EarlyStopping
# Read data with train-test split
ds_train, ds_test = tfds.load("mnist", split=['train', 'test'],
shuffle_files=True, as_supervised=True)
# Set up BatchDataset from the OptionsDataset object
ds_train = ds_train.batch(32)
ds_test = ds_test.batch(32)
# Build LeNet5 model and fit
model = Sequential([
Conv2D(6, (5,5), input_shape=(28,28,1), padding="same", activation="tanh"),
AveragePooling2D((2,2), strides=2),
Conv2D(16, (5,5), activation="tanh"),
AveragePooling2D((2,2), strides=2),
Conv2D(120, (5,5), activation="tanh"),
Flatten(),
Dense(84, activation="tanh"),
Dense(10, activation="softmax")
])
model.compile(loss="sparse_categorical_crossentropy", optimizer="adam", metrics=["sparse_categorical_accuracy"])
earlystopping = EarlyStopping(monitor="val_loss", patience=2, restore_best_weights=True)
model.fit(ds_train, validation_data=ds_test, epochs=100, callbacks=[earlystopping])
如果我们提供as_supervised=True ,数据集将是图元(特征、目标)的记录,而不是字典。这对Keras来说是必需的。此外,为了在fit() 函数中使用数据集,我们需要创建一个可迭代的批次。这是通过设置数据集的批次大小来完成的,以便将其从OptionsDataset 对象转换成BatchDataset 对象。
我们应用LeNet5模型进行图像分类。但由于数据集中的目标是一个数值(0到9),而不是一个布尔向量,我们要求Keras在计算准确率和损失之前,通过在sparse_categorical_accuracy 和sparse_categorical_crossentropy 函数中指定compile() ,将softmax输出向量转换为一个数字。
这里的关键是要理解每个数据集的形状是不同的。当你把它与你的TensorFlow模型一起使用时,你需要调整你的模型以适应数据集。
在scikit-learn中生成数据集
在scikit-learn中,有一组非常有用的函数来生成具有特定属性的数据集。因为我们可以控制合成数据集的属性,这对评估我们的模型在其他数据集不常见的特定情况下的性能很有帮助。
Scikit-learn文档将这些函数称为样本生成器。它很容易使用;例如。
from sklearn.datasets import make_circles
import matplotlib.pyplot as plt
data, target = make_circles(n_samples=500, shuffle=True, factor=0.7, noise=0.1)
plt.figure(figsize=(6,6))
plt.scatter(data[:,0], data[:,1], c=target, alpha=0.8, cmap="Set1")
plt.show()
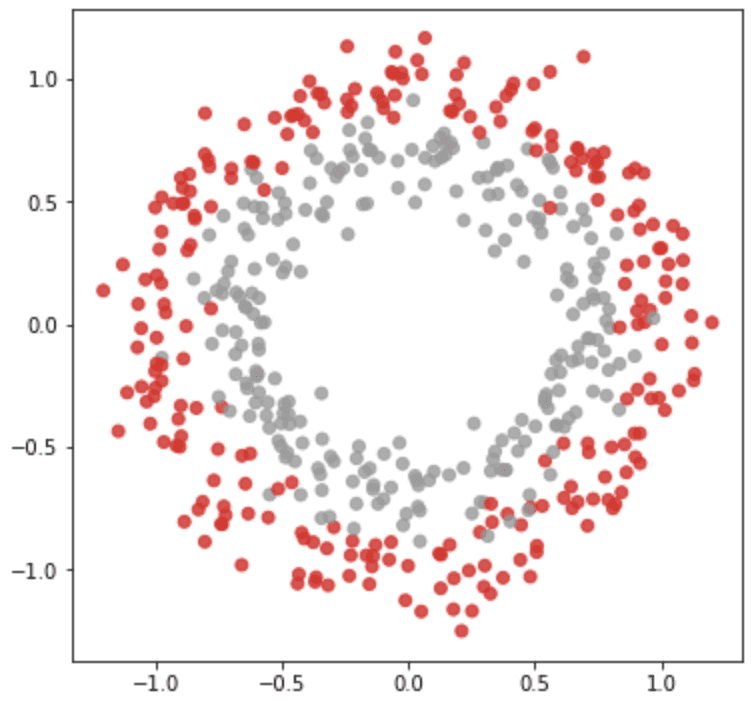
make_circles() 函数在一个二维平面上生成散点的坐标,这样就有两个类以同心圆的形式定位。我们可以通过参数factor 和noise 来控制圆的大小和重叠。这个合成数据集有助于评估分类模型,如支持向量机,因为没有线性分离器可用。
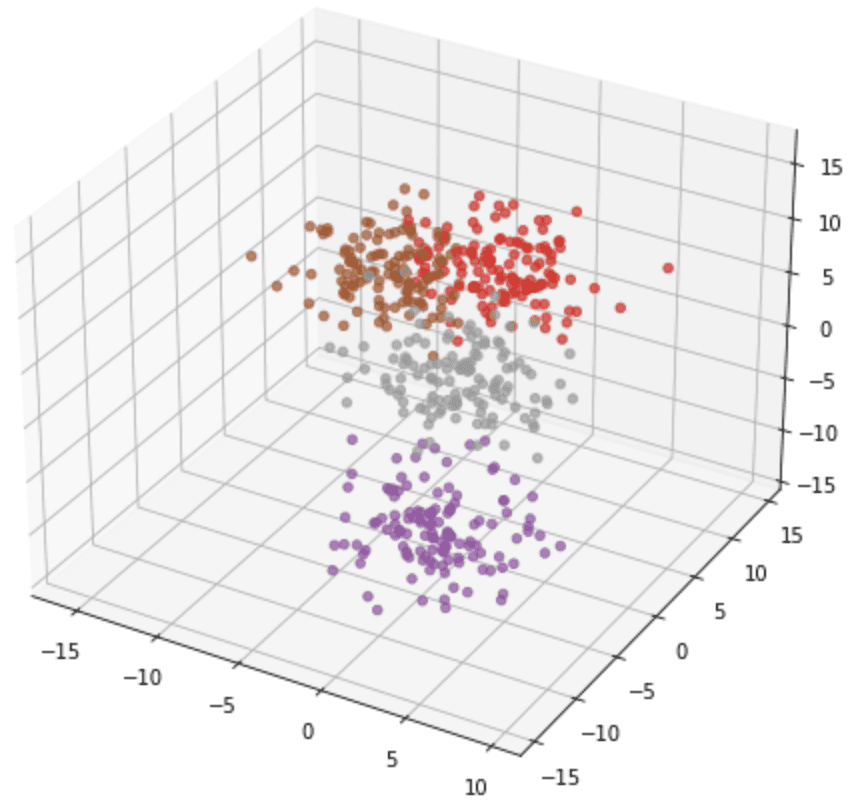
make_circles() 的输出总是两类,而且坐标总是二维的。但是其他一些函数可以生成更多类别或更高维度的点,如make_blob() 。在下面的例子中,我们生成了一个有4个类的三维数据集。
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
data, target = make_blobs(n_samples=500, n_features=3, centers=4,
shuffle=True, random_state=42, cluster_std=2.5)
fig = plt.figure(figsize=(8,8))
ax = fig.add_subplot(projection='3d')
ax.scatter(data[:,0], data[:,1], data[:,2], c=target, alpha=0.7, cmap="Set1")
plt.show()
还有一些函数用于生成回归问题的数据集。例如,make_s_curve() 和make_swiss_roll() 将在三维中生成以目标为连续值的坐标。
from sklearn.datasets import make_s_curve, make_swiss_roll
import matplotlib.pyplot as plt
data, target = make_s_curve(n_samples=5000, random_state=42)
fig = plt.figure(figsize=(15,8))
ax = fig.add_subplot(121, projection='3d')
ax.scatter(data[:,0], data[:,1], data[:,2], c=target, alpha=0.7, cmap="viridis")
data, target = make_swiss_roll(n_samples=5000, random_state=42)
ax = fig.add_subplot(122, projection='3d')
ax.scatter(data[:,0], data[:,1], data[:,2], c=target, alpha=0.7, cmap="viridis")
plt.show()
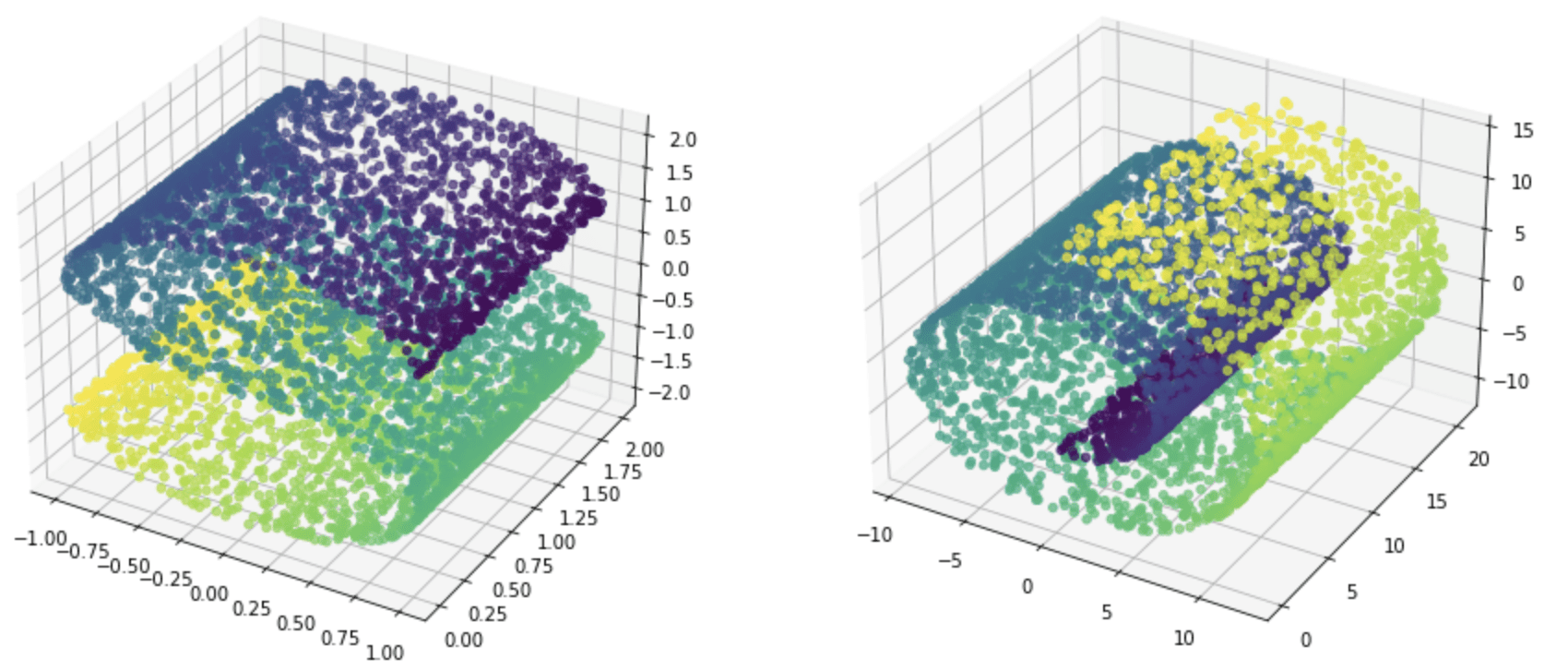
如果我们不喜欢从几何角度看数据,还有make_classification() 和make_regression() 。与其他函数相比,这两个函数为我们提供了对特征集的更多控制,比如引入一些多余的或不相关的特征。
下面是一个使用make_regression() 来生成数据集并使用它运行线性回归的例子。
from sklearn.datasets import make_regression
from sklearn.linear_model import LinearRegression
import numpy as np
# Generate 10-dimensional features and 1-dimensional targets
X, y = make_regression(n_samples=500, n_features=10, n_targets=1, n_informative=4,
noise=0.5, bias=-2.5, random_state=42)
# Run linear regression on the data
reg = LinearRegression()
reg.fit(X, y)
# Print the coefficient and intercept found
with np.printoptions(precision=5, linewidth=100, suppress=True):
print(np.array(reg.coef_))
print(reg.intercept_)
在上面的例子中,我们创建了10个维度的特征,但其中只有4个是有信息的。因此,从回归的结果来看,我们发现只有4个系数是显著不为零的。
[-0.00435 -0.02232 19.0113 0.04391 46.04906 -0.02882 -0.05692 28.61786 -0.01839 16.79397]
-2.5106367126731413
一个类似于使用make_classification() 的例子如下。在这种情况下,使用的是支持向量机分类器。
from sklearn.datasets import make_classification
from sklearn.svm import SVC
import numpy as np
# Generate 10-dimensional features and 3-class targets
X, y = make_classification(n_samples=1000, n_features=10, n_classes=3,
n_informative=4, n_redundant=2, n_repeated=1,
random_state=42)
# Run SVC on the data
clf = SVC(kernel="rbf")
clf.fit(X, y)
# Print the accuracy
print(clf.score(X, y))
摘要
在本教程中,你发现了在Python中加载一个普通数据集或生成一个数据集的各种选项。
具体来说,你学到了
- 如何使用scikit-learn、Seaborn和TensorFlow中的数据集API来加载常见的机器学习数据集
- 不同API返回的数据集格式的微小差异以及如何使用它们
- 如何使用scikit-learn生成数据集
