

[
](alan-jones.medium.com/?source=pos…)
6月14日
-
6分钟阅读
[
拯救
如何用Python和Pandas刮取和清理维基百科的表格
维基百科的表格是给人看的,不是用来用电脑处理的,但在Python和Pandas的帮助下,我们可以把它们整理出来。我们以2021年F1赛季的结果为例。
2016年摩纳哥大奖赛中的奔驰F1车队。图片由 安德鲁-沃克, CC-BY-2.0.
维基百科是一个很好的资源,但并不特别适合数据分析员使用。文章中的数据是为了让人看的,而不是由计算机处理的,所以它不一定能提供一个立即可用的资源。但是Python和Pandas为我们提供了刮取和清理维基百科数据的工具。
在维基百科的表格中,一列中往往有不止一个数据。例如,在我们要看的一级方程式赛车数据中,有一列包含了车手完成比赛的位置。这很好。
问题是,这些数据被附加了一些代码,表明车手是否在杆位上发车,是否驾驶了最快的一圈,是否退赛,以及其他可能的结果。这是不可以直接使用的。
但是Pandas的出现,首先让我们能够从维基百科的表格中抓取数据,其次,对这些数据进行清理,以便我们能够有效地处理它们。
作为一个例子,我们将看看2021年F1赛季的结果,看看如何从维基百科页面中提取数据,然后对其进行处理,使其能够被很好地可视化。
我在Jupyter笔记本中写了这段代码,所以如果你想跟随,只需将下面的每个代码块粘贴到一个新的笔记本单元中并运行它。
下面是表格的样子。
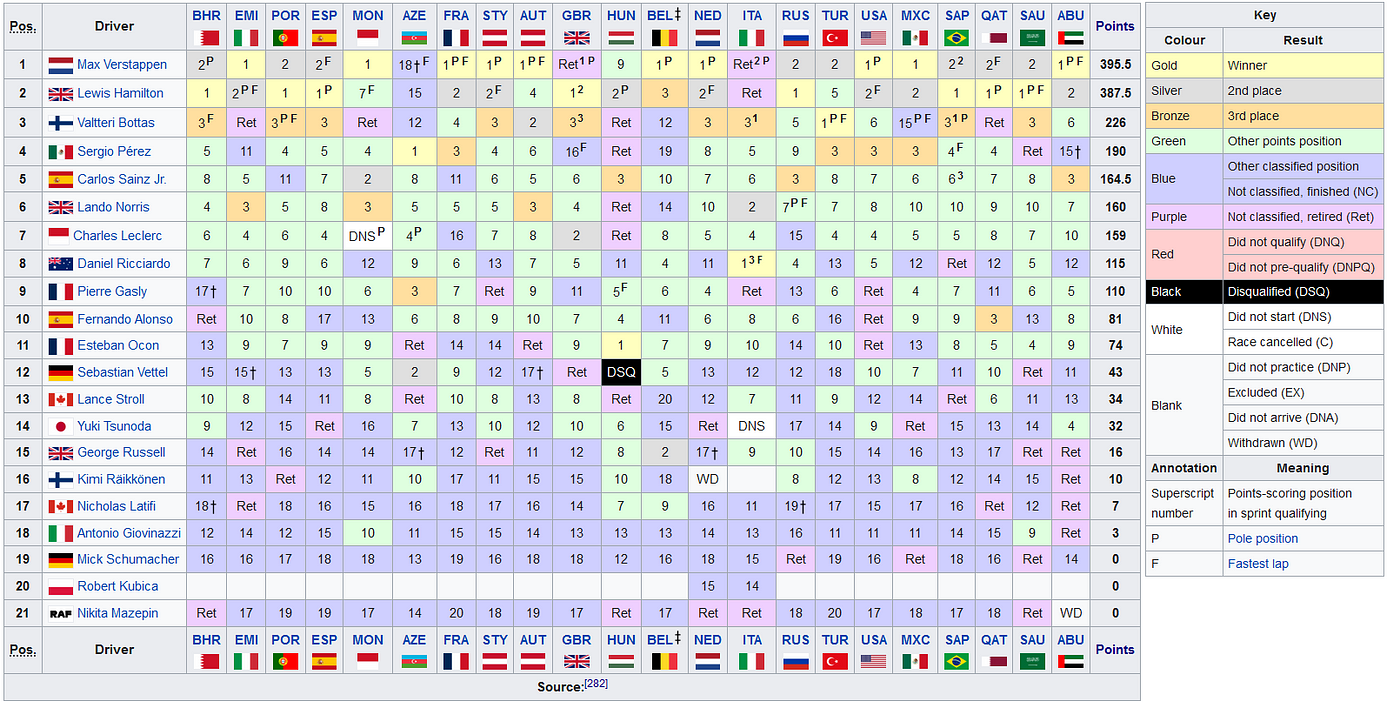
2021年F1赛季的结果,来源维基百科,CC-BY-SA 3.0
这是相当清楚的,比赛旁边有漂亮的小旗子,所以我们可以看到他们的位置,车手也有他们的国籍。
每场比赛中每个车手的最终位置都被标示出来,每个单元格都有颜色编码,这取决于该车手的特定结果,同时颜色编码还可能在最终位置上添加一个符号。因此,例如,在意大利大奖赛中,刘易斯-汉密尔顿获得第二名(用银色和单元格中的数字2表示),但该单元格还包含一个 "P "和一个 "F",以表示他以杆位起步,并且还驾驶了最快的单圈。
这对读者来说都是有意义的,但在用程序分析时就会感到困惑。
为了下载表格,我们使用Pandas的read_html 函数。我在之前的文章《如何使用维基百科作为数据源》中已经介绍过了,所以这里就不多说了。
我只想说,这个函数会返回一个网页中所有表格的列表。由于任何给定的网页上可能有很多表,我们可以添加一个参数来过滤返回的内容。因此,下面的代码返回网页中所有的表,url, ,这些表的列名之一是字符串"Driver" 。
url="https://en.wikipedia.org /wiki/2021_Formula_One_World_Championship"df = pd.read_html(url,match="Driver")
然后由我们在返回的列表中找到我们需要的表。
在这个特定的维基百科网页上只有几个表,而我要找的这个表在返回的列表中是最后一个,即df[2] 。
作者的屏幕截图
现在我们有了可以在Pandas中处理的东西,但它首先需要进行一些处理。
首先要注意的是,最后两行是多余的,但这很容易排序。
df2 = df[2][:-2]
这段代码从下载的数据框中创建了一个新的数据框df2 ,但错过了最后两行。
我们的下一个任务是将Points 列改为数字(由于倒数第二行的列名,它被视为字符串)。
df2.Points = pd.to_numeric(df2.Points)
现在我们可以对这些数据做一些处理了。下面这行代码画出了每个司机获得的分数的条形图。
df2.plot.bar(x='Driver', y='Points')
图片由作者提供
但这只是一个列的排序。比赛结果仍然是一团糟,所以让我们试着解决这个问题。
正如我之前所说,比赛结果单元格包含不止一个数据--车手位置和其他各种信息。
我们可以直接过滤掉多余的字符,让车手位置成为单元格中唯一的数据。但我不喜欢丢失数据,所以让我们看看如何保留每场比赛中谁在杆位和谁开出最快圈速的信息。你可以对其他数据做同样的处理(例如,Ret 意味着退赛),但如果我们这样做,我们就有可能变得乏味,所以我们将忽略其他数据。
所以我将创建另一个数据框架,在其中增加两列,一列记录杆位,另一列记录最快圈速。我们只是删除其他的东西。
首先,我们得到一个比赛的列表--这些是除了前两个和最后一个之外的所有列名。
races = df2.columns[2:-1]
然后,我们为每一个比赛名称创建新的变更列。
df3 = pd.DataFrame()df3['Driver'] = df2['Driver']for r in races: # copy race columns but remove the P for pole df3[r] = df2[r].replace('P','', regex=True) # record pole in a new column df3[f'Pole-{r}'] = df2[r].str.contains('P')
下面是结果。
图片由作者提供
表中的所有数据现在都是有效的,可以被正确处理。(我们在罗伯特-库比卡方面确实有点问题。他是一名后备车手,只参加了两场GP,但就Pandas而言,NaN ,结果完全没有问题,所以不需要再做任何事情)。
因此,让我们证明我们可以用这些数据做一些有用的事情,并制定一个新的表格,列出每个车手取得的杆数和最快圈数。
首先,我们需要一个车手列表--这很容易,它在列Drivers 。接下来,我们将遍历该列表,计算杆数和最快圈数,并创建与车手相匹配的列表。最后,我们从这些列表中创建一个新的数据框架。
我相信有人会告诉我,有更多的Pythonic方法可以做到这一点,但这很简单,现在就可以了。
drivers = df3['Driver']poles = []fast = []
我们的新数据框架看起来像这样。
图片由作者提供
我们可以用它来画一个简单的柱状图,像这样。
dp.plot.bar(x='Drivers',y=['Poles','Fastest'])
按作者分类的图片
所以,我们有了它。维基百科是一个很好的数据源,只要花点功夫,我们就可以把它转换成适合用Python和Pandas进行分析的东西。
谢谢你的阅读,我希望你觉得这很有用。这篇文章没有repo--代码都在文章中--但是你可以从我的Github网页上看到我的其他文章和访问这些代码。你可能还有兴趣订阅我的不定期通讯Technofile。
