

持续创作,加速成长!这是我参与「掘金日新计划 · 6 月更文挑战」的第6天,点击查看活动详情
一、【超简单之强化学习入门】基于Sarsa表格方法的出租车调度

滴滴滴,发车了,强化学习开始复习了。之前强化学习一直活在 GridWorld里面,那么,这次就来个漂亮的 Taxi 界面
- Agent 在 Environment 中执行一些操作(通常通过向环境传递一些控制输入,例如出租车移动方向、上下客),并观察环境状态的变化。一个这样的动作观察交换被称为timestep。
- RL的目标是以某种特定的方式操纵环境。例如,我们希望 agent 将 出租车开到上客点,并将乘客送达目的地。如果它成功地做到了这一点(或朝着这一目标取得了一些进展),它将得到一个积极的奖励,同时还将获得这一timestep的观察结果。如果代理尚未成功(或未取得任何进展),奖励也可能为负或0。然后,将对agent进行训练,使其在多个时间步中累积的回报最大化。
- 经过一段时间后,Environment 可能会进入停止状态。例如,客人已送达!在这种情况下,我们希望将环境重置为新的初始状态。如果代理进入这种终端状态,环境将向代理发出完成信号。
二、Gym 的Taxi环境介绍
1.Gym介绍
Gym是强化学习的标准API,也是各种参考环境的集合。它下面有如下各类库,是学习强化学习的入门库:
- Atari
- MuJoCo
- Toy Text
- Classic Control
- Box2D
- Thrid Party Environments
GYM文档:www.gymlibrary.ml/
2.Gym安装
安装命令很简单 pip install gym 即可。
注意:如win下调用不成功,需要安装 vs_buildtools,切记切记,该安装文件已上传根目录。
!pip install -U pip --user >log.log
!pip install gym >log.log
!pip list|grep gym
gym 0.12.1
3.Taxi环境介绍
此环境是玩具 Toy Text 环境的一部分。
3.1基本环境信息
Action Space |
Discrete(6) |
Observation Space |
Discrete(500) |
Import |
|
3.2 环境描述
网格世界中有四个指定位置,分别由R(ed)、G(reen)、Y(ellow)和B(lue)表示。当这一集开始时,出租车从一个随机的正方形开始,乘客在一个随机的位置。出租车开到乘客的位置,接上乘客,开到乘客的目的地(四个指定位置中的另一个),然后让乘客下车。乘客下车后,这一集就结束了。
+---------+
|R: | : :G|
| : | : : |
| : : : : |
| | : | : |
|Y| : |B: |
+---------+
3.3 动作Action
有6个离散的确定性动作:
- 0: move south
- 1: move north
- 2: move east
- 3: move west
- 4: pickup passenger
- 5: drop off passenger
3.4 观察者Observations
共有500个离散状态,因为共有25个滑行位置、5个可能的乘客位置(包括乘客在滑行中的情况)和4个目的地位置。
请注意,在一集中,实际上可以达到400个状态。失踪状态对应于乘客与其目的地在同一位置的情况,因为这通常标志着一集的结束。当乘客和出租车都在目的地时,在成功的事件发生后,可以观察到四种额外的状态。这给出了总共404个可到达的离散状态。
每个状态空间由元组表示:(taxi_row、taxi_col、passenger_location、destination)
观测值是对相应状态进行编码的整数。然后可以使用“decode”方法对状态元组进行解码。
乘员未知Passenger locations:
- 0: R(ed)
- 1: G(reen)
- 2: Y(ellow)
- 3: B(lue)
- 4: in taxi
目的地Destinations:
- 0: R(ed)
- 1: G(reen)
- 2: Y(ellow)
- 3: B(lue)
奖励 Rewards
-
- -1 除非触发其他奖励,否则每一步-1。
-
- +20运送乘客。
-
- -10 非法执行“接送”行为。
三、Sarsa表格方法简介
Sarsa全称是state-action-reward-state'-action',目的是学习特定的state下,特定action的价值Q,最终建立和优化一个Q表格,以state为行,action为列,根据与环境交互得到的reward来更新Q表格,更新公式为:
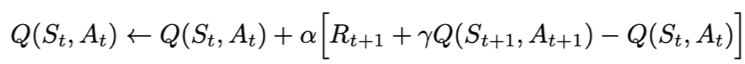
Sarsa在训练中为了更好的探索环境,采用ε-greedy方式来训练,有一定概率随机选择动作输出。
1.SarsaAgent定义
# -*- coding: utf-8 -*-
import numpy as np
class SarsaAgent(object):
def __init__(self,
obs_n,
act_n,
learning_rate=0.01,
gamma=0.9,
e_greed=0.1):
self.act_n = act_n # 动作维度,有几个动作可选
self.lr = learning_rate # 学习率
self.gamma = gamma # reward的衰减率
self.epsilon = e_greed # 按一定概率随机选动作
self.Q = np.zeros((obs_n, act_n))
# 根据输入观察值,采样输出的动作值,带探索
def sample(self, obs):
if np.random.uniform(0, 1) < (1.0 - self.epsilon): #根据table的Q值选动作
action = self.predict(obs)
else:
action = np.random.choice(self.act_n) #有一定概率随机探索选取一个动作
return action
# 根据输入观察值,预测输出的动作值
def predict(self, obs):
Q_list = self.Q[obs, :]
maxQ = np.max(Q_list)
action_list = np.where(Q_list == maxQ)[0] # maxQ可能对应多个action
action = np.random.choice(action_list)
return action
# 学习方法,也就是更新Q-table的方法
def learn(self, obs, action, reward, next_obs, next_action, done):
""" on-policy
obs: 交互前的obs, s_t
action: 本次交互选择的action, a_t
reward: 本次动作获得的奖励r
next_obs: 本次交互后的obs, s_t+1
next_action: 根据当前Q表格, 针对next_obs会选择的动作, a_t+1
done: episode是否结束
"""
predict_Q = self.Q[obs, action]
if done:
target_Q = reward # 没有下一个状态了
else:
target_Q = reward + self.gamma * self.Q[next_obs,
next_action] # Sarsa
self.Q[obs, action] += self.lr * (target_Q - predict_Q) # 修正q
def save(self):
npy_file = './q_table.npy'
np.save(npy_file, self.Q)
print(npy_file + ' saved.')
def restore(self, npy_file='./q_table.npy'):
self.Q = np.load(npy_file)
print(npy_file + ' loaded.')
2.模型训练
# -*- coding: utf-8 -*-
import gym
import numpy as np
np.random.seed(0)
import gym
from agent import SarsaAgent
import time
def run_episode(env, agent, is_render=False):
total_steps = 0 # 记录每个episode走了多少step
total_reward = 0
obs = env.reset() # 重置环境, 重新开一局(即开始新的一个episode)
action = agent.sample(obs) # 根据算法选择一个动作
while True:
next_obs, reward, done, _ = env.step(action) # 与环境进行一个交互
next_action = agent.sample(next_obs) # 根据算法选择一个动作
# 训练 Sarsa 算法
agent.learn(obs, action, reward, next_obs, next_action, done)
action = next_action
obs = next_obs # 存储上一个观察值
total_reward += reward
total_steps += 1 # 计算step数
if is_render:
env.render() # 渲染新的一帧图形
if done:
break
return total_reward, total_steps
def test_episode(env, agent):
total_reward = 0
obs = env.reset()
while True:
action = agent.predict(obs) # greedy
next_obs, reward, done, _ = env.step(action)
total_reward += reward
obs = next_obs
time.sleep(0.5)
env.render()
if done:
print('test reward = %.1f' % (total_reward))
break
def main():
# 环境使用
env = gym.make('Taxi-v3')
env.reset(seed=1024)
print('观察空间 = {}'.format(env.observation_space.n))
print('动作空间 = {}'.format(env.action_space.n))
print('状态数量 = {}'.format(env.observation_space.n))
print('动作数量 = {}'.format(env.action_space.n))
state = env.reset()
taxirow, taxicol, passloc, destidx = env.unwrapped.decode(state)
print(taxirow, taxicol, passloc, destidx)
print('的士位置 = {}'.format((taxirow, taxicol)))
print('乘客位置 = {}'.format(env.unwrapped.locs[passloc]))
print('目标位置 = {}'.format(env.unwrapped.locs[destidx]))
env.render()
env.step(0)
env.render()
# agent定义
agent = SarsaAgent(obs_n=env.observation_space.n, act_n=env.action_space.n)
# 训练
episodes = 3000
episode_rewards = []
is_render = False
# 开始训练
for episode in range(episodes):
ep_reward, ep_steps = run_episode(env, agent, is_render)
print('Episode %s: steps = %s , reward = %.1f' % (episode, ep_steps,
ep_reward))
# 每隔20个episode渲染一下看看效果
if episode % 20 == 0:
is_render = True
else:
is_render = False
# 训练结束,查看算法效果
test_episode(env, agent)
if __name__ == "__main__":
main()
训练日志
Episode 1493: steps = 200 , reward = -290.0
Episode 1494: steps = 200 , reward = -344.0
Episode 1495: steps = 113 , reward = -110.0
Episode 1496: steps = 19 , reward = 2.0
Episode 1497: steps = 10 , reward = 2.0
Episode 1498: steps = 118 , reward = -169.0
Episode 1499: steps = 108 , reward = -87.0
Episode 1500: steps = 200 , reward = -281.0
模型训练好了就可以开车了。
项目地址:aistudio.baidu.com/aistudio/pr…
参考:强化学习7日打卡营 aistudio.baidu.com/aistudio/ed…
