更多精彩文章,欢迎关注作者微信公众号:码工笔记
为了高效地判别一个对象是否在一个集合中,最常用的应该是Hash。传统的Hash方法能够保证给出的结果一定是正确的,即没有误判;但在允许一定错误率的场景下,传统Hash占用的空间以及查找所用的时间并不是最优的。
文章[1]介绍了三种Hash方法并进行了理论分析:
- 方法一:传统的Hash方法,槽位数等于key位数,无误判
- 方法二:传统Hash方法,槽位数小于key位数,可能误判
- 方法三:布隆过滤器,不分槽,每个key经哈希得到多个不同的bit地址并为其置1,可能误判
方法一:传统Hash方法,槽位数等于key位数
假设哈希表有如下配置参数:
- N:占用总空间大小,N个bit
- h:槽数,N bit 被分为 h 个槽
- b+1:槽大小,每个槽占用b+1位(有1个bit标识槽是否为空)
- n:hash表中所存key的个数,也即被占用的槽数
- ϕ:空槽占总槽数的比例,有:
ϕ=hh−n=NN−n⋅(b+1)
转换后可得:
N=1−ϕn⋅(b+1)
另定义以下变量:
- T:拒绝流程中需要比对的比特数的期望值,也即hash计算出的槽中存放的并非目标值时,后续还需要比对的bit数
- E:hash计算出的槽非空时,平均(期望值)需要比较E个bit才能确定槽中值的确不等于目标值
则有:
T=(1−ϕ)(E+T)+ϕ
拒绝流程是一个递归过程,如果发现槽中值并非目标值,则需要重新开始整个hash流程:
- 槽非空情况下(概率为1−ϕ),平均需要比较E个bit才能识别出来槽中数据与目标识不同,然后按T的定义还需要再比较T个bit。
- 槽空的情况下(概率为ϕ),只需要比较一个bit即可。
下面考虑如何来估算 E,假设比较槽内值与目标值之间的差异时,不失一般性,假设其前x个bit相等,第x+1个bit不同,则有:
E≈x=1∑∞(x+1)⋅(21)x=3
注:非空槽中值的标识位为定值,所以上式中是(21)x而不是(21)x+1
结合之前的公式则有:
T=(ϕ3)−2
从而得到传统Hash方式的时间-空间关系式:
N=n⋅(b+1)⋅T−1T+2
方法二:传统Hash方法,槽位数小于key位数
假设其参数配置如下:
- c:槽大小,每个槽占用c个bit
- ϕ′:空槽占总槽数的比例
则参考方法一的推导同理可得:
ϕ′=N′N′−n⋅c
T′=(ϕ′3)−2
N′=n⋅c⋅T′−1T′+2
在这种hash方法下,其错误率P′可使用下式计算:
P′=ϕ′(21)c−1
则有:
c=−log2P′+1+log23T′+2
N′=n⋅(−log2P′+1+log23T′+2)⋅T′−1T′+2
方法三:布隆过滤器,不分槽
- N′′:占用的总空间bit数
- ϕ′′:空槽率
- d:每个key经hash后占用的bit数
则有:
ϕ′′=(1−N′′d)n(16)
如果一个key实际未存储在布隆过滤器中,但由此key计算出的d个位置都是1,这时即发生了错判,错判概率为:
P′′=(1−ϕ′′)d
假设d≪N′′,对(16)式两边取以2为底的对数,则有:
log2ϕ′′=loge(1−N′′d)n∗log2e=−n⋅(N′′d)⋅log2e
则有:
N′′=n⋅(−log2P′′)⋅log2ϕ′′⋅log2(1−ϕ′′)log2e
下面我们计算一下T'':
如果在一次失败的查询中比较了x位,则前x−1位都是1,而第x位为0,这种情况出现的概率为ϕ′′⋅(1−ϕ′′)x−1。
假设:P′′≪1 且 d≫1,有:
T′′=x=1∑∞x⋅ϕ′′⋅(1−ϕ′′)x−1=ϕ′′1
则有:
N′′=n⋅(−log2P′′)⋅log2(T′′1)⋅log2(1−T′′1)log2e
方法二 VS. 方法三
为去掉上述公式中 n 和 P 的影响,引入空间归一化度量值 S:
S=(−n⋅log2P)N
则有:
S′=T′−1T′+2⋅(1+−log2P′1+log23T′+2)
S′′=log2T′′1⋅log2(1−T′′1)log2e
可以看出 S′>T′−1T′+2,并且有:
P′→0limS′=T′−1T′+2
两种方法时间-空间关系比较如下图示:
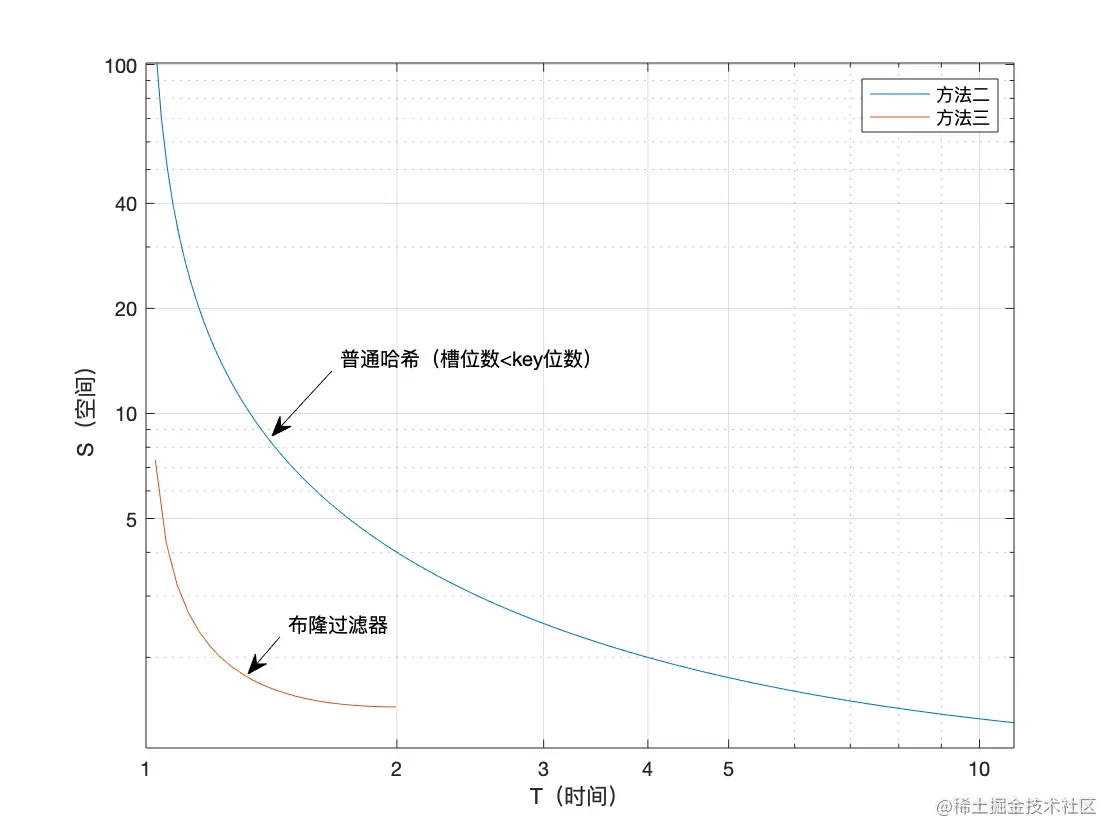
可见,布隆过滤器总体性能和空间更优。
参考资料
【1】Space/Time Trade-offs in Hash Coding wiht Allowable Errors


