0.论文信息

图例1.可以看出在Stable Learning模型相较于传统模型学习的优势
1.文章提出的背景
-
传统深度学习模型在源域与目标域不同时(即Out-Of-Distribution问题)学习效率不太行,是因为在分布中具有虚假的相关性,比如上图中的狗和水,其实判定狗并不需要水,但是因为源域数据的分布,模型会反映出这个虚假的相关性。
-
现有的Domain Generalization解决问题的核心是将类别划分为多个分布域,使得真正相关的特征在不同域中都有共性体现,而虚假的相关特征在不同域中千差万别。但是这种方法的弊端也显而易见,很多方法仍然建立在隐含地假设潜在域是平衡的这一基础之上。
-
假定训练数据的分布是未知的并且不隐含假设潜在域是平衡的,想要很好地解决这一问题时,存在两点挑战 :
- 特征之间的复杂的非线性依赖性比线性难以测量和消除
- 我们在全局样本加权策略中需要在深层模型中储存和计算,这将需要大量的成本并不容易实现
-
随后,给出了对应的解决思路:
- 针对第一个问题,提出了一种基于随机傅里叶特征的新型非线性特征去相关方法,具有线性计算复杂性。
- 针对第二个问题,提出了一个通过迭代节省和重新加载模型的特征和权重来感知和清除全局相关性的方法。
2.相关工作
Domain Generalization域泛化Feature Decorrelation去相关性
3.分布泛化的样本加权
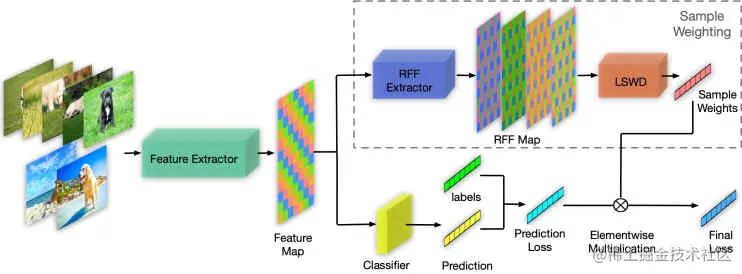
图例2.Stable Learning的整体网络结构
3.1 使用RFF的样本加权
传统的希尔伯特-施密特独立标准(HSIC)需要进行矩阵的平方运算,但是随着batch size的增大开销将大幅上涨,所以在大型数据训练的模型中不可实用。
实际上,Frobenius范数对应于欧几里德空间的HSIC范数,因此独立的测试统计可以基于Frobenius范数。
所以局部协方差可以采用以下的表达形式
Σ^AB=n−11i=1∑n[(u(Ai)−n1j=1∑nu(Aj))T⋅(v(Bi)−n1j=1∑nv(Bj))]u(A)=(u1(A),u2(A),...,unA(A)), uj(A)∈HRFFv(B)=(v1(B),v2(B),...,vnB(B)), vj(B)∈HRFFHRFF={h:x→2cosωx+ϕ ∣ ω∼N(0,1),ϕ∼Uniform(0,2π)}IAB=∥Σ^AB∥F2
更进一步地,可以使用可学习的权重来更好地去除相关性,引入权重w
Σ^AB;w=n−11i=1∑n[(wiu(Ai)−n1j=1∑nwju(Aj))T⋅(wiv(Bi)−n1j=1∑nwjv(Bj))]
对于两个不同的特征Z:,i与Z:,j,w对应优化即为
w∗=w∈Δnargmin1≤i<j≤mZ∑∥Σ^Z:,iZ:,j;w∥F2Δn={w∈R+n ∣ i=1∑nωi=n}
对应的表示函数f、预测函数g有如下关系式
w(0)=(1,1,...,1)TZ(t+1)=f(t+1)(X)f(t+1),g(t+1)=f,gargmini=1∑nwi(t)L(g(f(Xi)),yi)w(t+1)=w∈Δnargmin1≤i<j≤mZ∑∥Σ^Z:,i(t+1)Z:,j(t+1);w∥F2
3.2 全局学习样本权重
对于每个batch,规定ZO与wO如下,其中ZGi,wGi表示在每批次训练后更新的全局变量,而ZL与wL则代表本地存储的全局变量。
ZO=Concat(ZG1,ZG2,...,ZGk,ZL)wO=Concat(wG1,wG2,...,wGk,wL)
并使用如下的更新规则
ZGi′=αiZGi+(1−αi)ZLwGi′=αiwGi+(1−αi)wL
4.实验
- 4.1 实验参数设置与数据集
- 4.2 非平衡环境
- 4.3 灵活的非平衡环境
- 4.4 灵活的非平衡对抗环境
- 4.5 经典环境
- 4.6 消融研究
- 4.7 显著图谱

图例3.使用StableNet训练的更多场景及其对比效果
5.总结
为了解决问题提出StableNet......较好地解决了问题
6.个人感想
在这篇文章中,通过使用改进的Frobenius范数来衡量相关性并尽量去除掉虚假的相关性。感觉在相关性背后的深层逻辑其实还是因果性,但是使用相关性的处理要比因果性方便很多且行之有效,所以使用相关对于因果进行简化也不失为一种好的思路。


