

性能分析一直是性能实施项目中的一个难点。对于只做性能测试不做性能分析的团队来说,总是不能把问题非常显性地展示出来,不能给其他团队非常明确的引导。对于这种类型的测试实施,只能把问题抛出来,让其他相关团队去查。沟通成本很高。
而一个成熟的性能团队应该是要把问题点分析出来,给其他团队或责任人非常明确的瓶颈点,以加快问题的处理进度。
从完整的分析思路上考虑。有两个要点:分段和分层。
 如上图所示,分段就是要把 1-6 以及在 server1/2、DB 上消耗的时间都统计出来。分层就是要把上图中各种不同颜色的层都分析到。
可以使用的方法在不同的项目中各不一样,取决于应用的架构。
性能分析的深度要到什么程度为宜呢?主要是看组织的结构和项目中涉及到的人的职责定义。要把握的深度就是让各团队没有技术上的 Gap。这一点非常重要。
从实际的操作层面来说,因为性能主要是在大压力下是否能保持住时间的可接受性。所以主要把握如下几点:
1.从响应时间到具体的代码;
2.从响应时间到具体的 SQL;
3.从响应时间到具体的配置
有了这几个层面的分析,基本上就可以确定一个问题的瓶颈点了。
在数据理解上,有两个阶段:
1.知道计数器的含义:
这个阶段看似简单,但能记得住那么多 performance counter 的人并不多,这个记不住倒是没有太大关系,遇到就查,多遇几次自然就记住了;
如上图所示,分段就是要把 1-6 以及在 server1/2、DB 上消耗的时间都统计出来。分层就是要把上图中各种不同颜色的层都分析到。
可以使用的方法在不同的项目中各不一样,取决于应用的架构。
性能分析的深度要到什么程度为宜呢?主要是看组织的结构和项目中涉及到的人的职责定义。要把握的深度就是让各团队没有技术上的 Gap。这一点非常重要。
从实际的操作层面来说,因为性能主要是在大压力下是否能保持住时间的可接受性。所以主要把握如下几点:
1.从响应时间到具体的代码;
2.从响应时间到具体的 SQL;
3.从响应时间到具体的配置
有了这几个层面的分析,基本上就可以确定一个问题的瓶颈点了。
在数据理解上,有两个阶段:
1.知道计数器的含义:
这个阶段看似简单,但能记得住那么多 performance counter 的人并不多,这个记不住倒是没有太大关系,遇到就查,多遇几次自然就记住了;
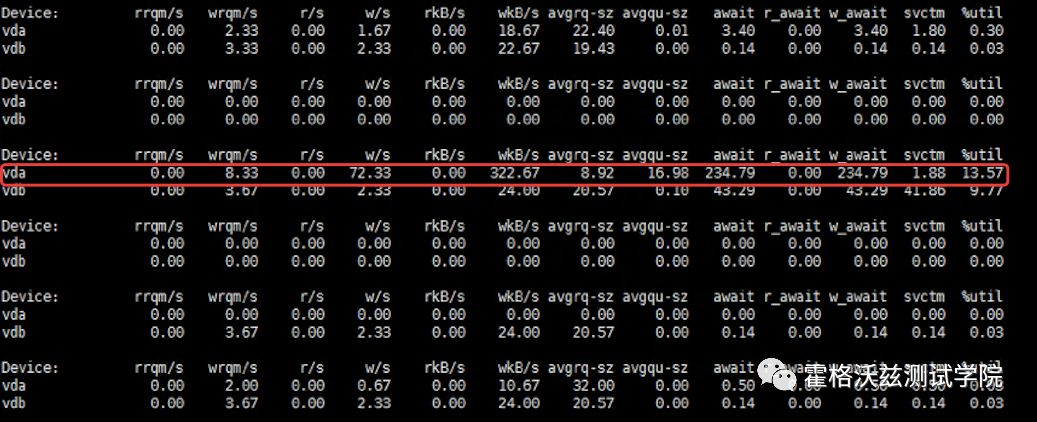 比如,对于上图来说,要理解的计数器就是 await 和 svctm,await 高是肯定存在问题。如果要判断问题是严重不严重还要看另一个计数器就是 avgqu-sz,它是队列长度。svctm 是平均每次 io 的时间(单位:ms)。
再来看看 CPU 的计数器。
比如,对于上图来说,要理解的计数器就是 await 和 svctm,await 高是肯定存在问题。如果要判断问题是严重不严重还要看另一个计数器就是 avgqu-sz,它是队列长度。svctm 是平均每次 io 的时间(单位:ms)。
再来看看 CPU 的计数器。
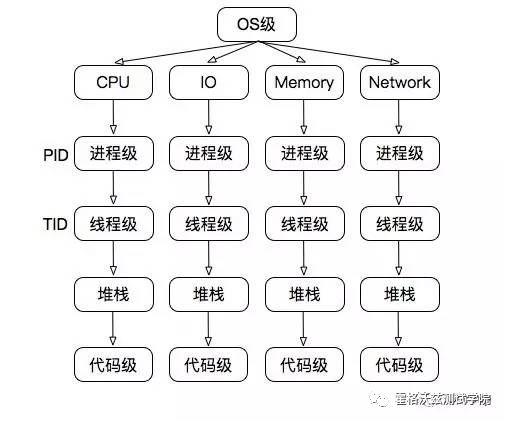
CPU 的计数器在 top 中有 8 个,在 mpstat 中多两个。在上面的计数器中,通常的说法是,us CPU 是用户态的,如果这部分高,通常是应用代码消耗的;sy CPU 是系统态的,如果这部分高,通常是 os 层的配置有问题。
这种说法在大部分情况下是合理的,但是不管是 us CPU 还是 sy CPU,高和低都只是问题的表现。分析到此并不是性能分析的结束,下面要找到的就是为什么这么高?这一步是非常关键的。一般情况下,分析路径是:
 所以下一步就很清晰了,就是找哪个进程、线程消耗的 CPU 高,进而查到代码。
2.知道计数器的值之间的关系:
这个阶段大部分人都需要好几年的时间才能完全掌握常规的计数值,之所以说只能掌握常规的计数值是因为有一些数值的联动关系不是那么容易碰得到。
比如说 CPU 模式对 TPS 和 RT 的影响,大部分人都是拿到硬件的时候都是 Full performance mode 了,并不关心还有没有其他的模式;比如说网络计数值导致的 TPS 有规律或无规律的抖动。
这些场景都要求做性能分析的在看到某个计数值的时候能有直接的反应,但是这一点非常难。因为数值的高低对大部分人来说就是一个谜,经常有人问这样的问题,这个值是高还是低,应该说只要不是一起工作的人都说不上来某个值是高还是低(当然对一些非常清晰的场景是比较容易判断的),合理还是不合理。
所以下一步就很清晰了,就是找哪个进程、线程消耗的 CPU 高,进而查到代码。
2.知道计数器的值之间的关系:
这个阶段大部分人都需要好几年的时间才能完全掌握常规的计数值,之所以说只能掌握常规的计数值是因为有一些数值的联动关系不是那么容易碰得到。
比如说 CPU 模式对 TPS 和 RT 的影响,大部分人都是拿到硬件的时候都是 Full performance mode 了,并不关心还有没有其他的模式;比如说网络计数值导致的 TPS 有规律或无规律的抖动。
这些场景都要求做性能分析的在看到某个计数值的时候能有直接的反应,但是这一点非常难。因为数值的高低对大部分人来说就是一个谜,经常有人问这样的问题,这个值是高还是低,应该说只要不是一起工作的人都说不上来某个值是高还是低(当然对一些非常清晰的场景是比较容易判断的),合理还是不合理。
 如上图所示:procs 的 b 列很高,这个值的含义是等 io 的进程数,它在上图中和 CPU wa 列是对应的。同时,也和 IO 的 bi、bo 列是对应的,从这几个值关联来看下步是要看哪个进程消耗的 IO 多了。
能经过数据理解的这一层次,才算是到了中级性能分析工程师的能力。
4.1 压力工具的曲线
做性能分析,看曲线是最直接了当的。压力工具可以给我们的明确的信息就是这个系统是不是有问题的,这也是压力工具自身曲线可以明确显示的唯一的信息。请看下面几张图:
TPS 图:
如上图所示:procs 的 b 列很高,这个值的含义是等 io 的进程数,它在上图中和 CPU wa 列是对应的。同时,也和 IO 的 bi、bo 列是对应的,从这几个值关联来看下步是要看哪个进程消耗的 IO 多了。
能经过数据理解的这一层次,才算是到了中级性能分析工程师的能力。
4.1 压力工具的曲线
做性能分析,看曲线是最直接了当的。压力工具可以给我们的明确的信息就是这个系统是不是有问题的,这也是压力工具自身曲线可以明确显示的唯一的信息。请看下面几张图:
TPS 图:
 响应时间图:
响应时间图:
 递增线程图:
递增线程图:
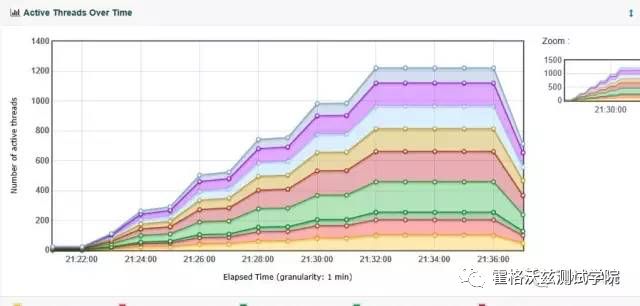 怎么理解这几张图呢?
先看张线程图。可以知道多个业务都有设置并发递增线程。这个图能给的信息就是这个且只有这个。
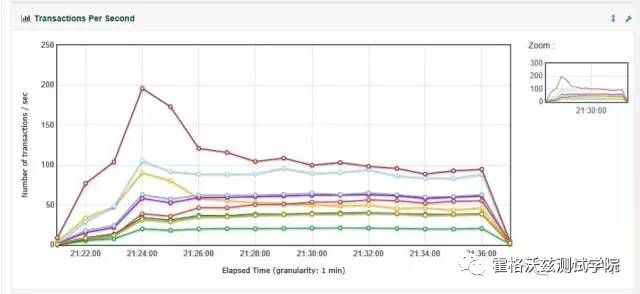
结合 TPS 图可以知道,在第三个梯度的时候,TPS 到了峰值。在第四个梯度的时候,TPS 已经开始下降了。
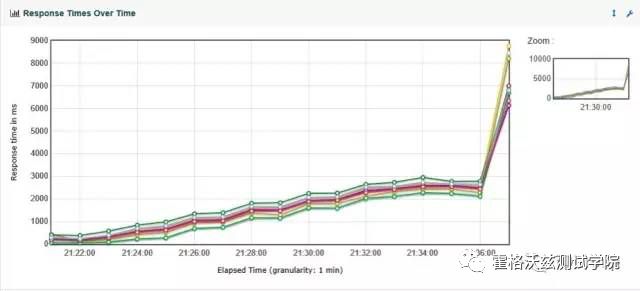
再结合响应时间图,在第三个梯度的时候,响应时间是明显地抬了头。后面响应时间在持续增加,每个梯度都有增加。
这时候有两件动作可做:
1.修改场景接着测试。
如何修改场景?把线程数降低。降到在梯度增加的过程中,响应时间没有明显增加的趋势之后再来看 TPS 是什么趋势。对于一个系统来说,响应时间有增加、TPS 没有增加(或有下降)、线程数有增加,这几个判断就明确说明了系统是有瓶颈的,并且也仅能说明这一点。
2.在当前场景下,分析瓶颈点,看时间消耗在哪个环节上。
这两个动作取决于目标,如果 TPS 在第三个梯度上已经达到了业务指标,那可以不做优化。所以第一个动作的前提是 TPS 目标已达到。
显然,第二个动作就是 TPS 目标还未达到。
当然有人提出 TPS 目标达到了,有瓶颈也是需要优化呀?在这一点上,就要看做决定的人怎么考虑了,因为优化是要付出成本的。接下来再说另一种曲线。
4.2 系统监控曲线。
由于操作系统级的监控有非常多的监控曲线,这里拿一个内存的来举例子。
内存曲线图:
怎么理解这几张图呢?
先看张线程图。可以知道多个业务都有设置并发递增线程。这个图能给的信息就是这个且只有这个。
结合 TPS 图可以知道,在第三个梯度的时候,TPS 到了峰值。在第四个梯度的时候,TPS 已经开始下降了。
再结合响应时间图,在第三个梯度的时候,响应时间是明显地抬了头。后面响应时间在持续增加,每个梯度都有增加。
这时候有两件动作可做:
1.修改场景接着测试。
如何修改场景?把线程数降低。降到在梯度增加的过程中,响应时间没有明显增加的趋势之后再来看 TPS 是什么趋势。对于一个系统来说,响应时间有增加、TPS 没有增加(或有下降)、线程数有增加,这几个判断就明确说明了系统是有瓶颈的,并且也仅能说明这一点。
2.在当前场景下,分析瓶颈点,看时间消耗在哪个环节上。
这两个动作取决于目标,如果 TPS 在第三个梯度上已经达到了业务指标,那可以不做优化。所以第一个动作的前提是 TPS 目标已达到。
显然,第二个动作就是 TPS 目标还未达到。
当然有人提出 TPS 目标达到了,有瓶颈也是需要优化呀?在这一点上,就要看做决定的人怎么考虑了,因为优化是要付出成本的。接下来再说另一种曲线。
4.2 系统监控曲线。
由于操作系统级的监控有非常多的监控曲线,这里拿一个内存的来举例子。
内存曲线图:
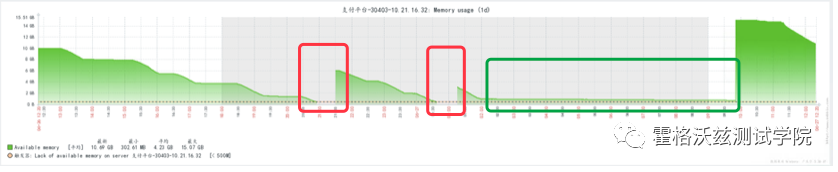 对 linux 操作系统来说,操作系统的内存会慢慢被分配掉,变成 caching memory。所以如果只看 available memory 的意义并不大,需要 -/+ buffer/cache 之后再看可用内存。这一点大家都清楚。
那么上面是不是说内存没有问题呢?当然不是。因为内存不仅被用光了,而且还断了一段,后面又有了数据,接着又用光,又断了一段时间。红色的框中,是有问题的,因为这一段连数据都没有抓到,抓数据的进程应该是没了。
所以 available memory 的下降并不是要关注的重点,-/+ buffer/cache 之后的 available memory 才是要关注的重点。另外从上图中看到的断掉的时间点也是要分析的重点。
另外,上图中,蓝框内内存一直在很低的状态,后面却突然升高了那么多。这里也是要分析的重点。
JVM 图
对 linux 操作系统来说,操作系统的内存会慢慢被分配掉,变成 caching memory。所以如果只看 available memory 的意义并不大,需要 -/+ buffer/cache 之后再看可用内存。这一点大家都清楚。
那么上面是不是说内存没有问题呢?当然不是。因为内存不仅被用光了,而且还断了一段,后面又有了数据,接着又用光,又断了一段时间。红色的框中,是有问题的,因为这一段连数据都没有抓到,抓数据的进程应该是没了。
所以 available memory 的下降并不是要关注的重点,-/+ buffer/cache 之后的 available memory 才是要关注的重点。另外从上图中看到的断掉的时间点也是要分析的重点。
另外,上图中,蓝框内内存一直在很低的状态,后面却突然升高了那么多。这里也是要分析的重点。
JVM 图
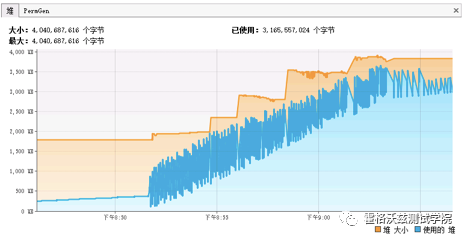 对 JVM 曲线来说,也是要看趋势的,基础知识是 jvm gc 的逻辑。YGC 一直在做,heap 一直在增加,这个过程是不是正常的呢?对于没有做过 Full GC 的 JVM 来说,heap 是有增加的趋势是可以理解的,但是这个 “理解” 需要一个前提,就是业务有没有增量。
如果是有业务的增量,上图就是正常的;如果没有业务增量,上图就是不正常的,那什么样的才是没有业务增量的正常呢?看下图:
对 JVM 曲线来说,也是要看趋势的,基础知识是 jvm gc 的逻辑。YGC 一直在做,heap 一直在增加,这个过程是不是正常的呢?对于没有做过 Full GC 的 JVM 来说,heap 是有增加的趋势是可以理解的,但是这个 “理解” 需要一个前提,就是业务有没有增量。
如果是有业务的增量,上图就是正常的;如果没有业务增量,上图就是不正常的,那什么样的才是没有业务增量的正常呢?看下图:
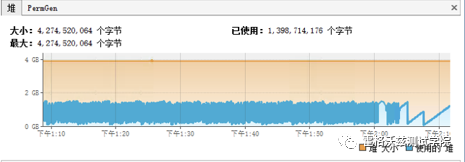 上图就明显是个非常正常的 JVM。
对于曲线的理解,首先要知道的是数据的来源和含义。在性能分析中,有很多曲线的趋势都不是可以直接指明问题的,只能通过收集全部的信息来做完整的分析才能判断问题存在点。
上面举了两个例子的角度分别是:压力工具生成的曲线和后端服务器相应的工具生成的曲线。就是为了说明一点:曲线分析是在关注所有的层面。
连续三天,晚上在执行一个业务场景持续几个小时之后,就开始连续报错。服务器连不上了。但在报错的一开始,并不是全部都报错,而是有部分是可以成功的,但是过一段时间之后,所有业务都报错了。次日来看,发现进程不见了。
本来以为是进程崩溃退出了,那日志中应该留下来些证据。但是打开了日志查看了一下,没有任何异常信息。连续三天都出现。就登录 zabbix 上去看了一下主机资源。
上图就明显是个非常正常的 JVM。
对于曲线的理解,首先要知道的是数据的来源和含义。在性能分析中,有很多曲线的趋势都不是可以直接指明问题的,只能通过收集全部的信息来做完整的分析才能判断问题存在点。
上面举了两个例子的角度分别是:压力工具生成的曲线和后端服务器相应的工具生成的曲线。就是为了说明一点:曲线分析是在关注所有的层面。
连续三天,晚上在执行一个业务场景持续几个小时之后,就开始连续报错。服务器连不上了。但在报错的一开始,并不是全部都报错,而是有部分是可以成功的,但是过一段时间之后,所有业务都报错了。次日来看,发现进程不见了。
本来以为是进程崩溃退出了,那日志中应该留下来些证据。但是打开了日志查看了一下,没有任何异常信息。连续三天都出现。就登录 zabbix 上去看了一下主机资源。
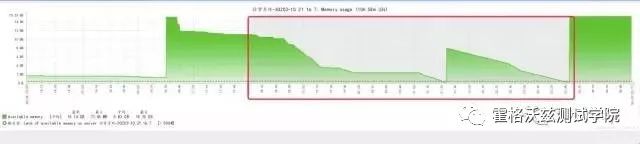 红框内的是出现问题的时间段。看到这里似乎明白了为什么并不是所有业务都失败。因为内存还有上升的这个阶段。但是为什么降到底之后又上去,再次降到底呢?先看一下拓扑图。
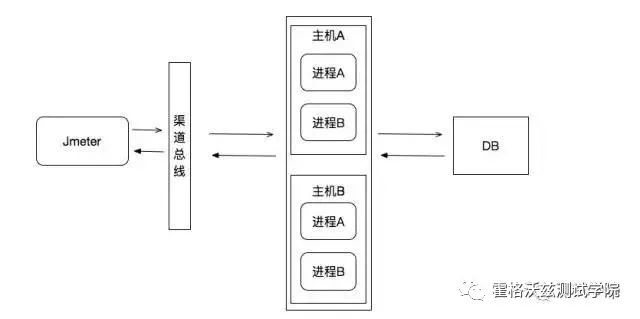
两个主机,四个进程,既然进程都没了,应该不是一块没的,要不然不会还有业务可以成功。
翻了一下应用日志,确实没有什么和进程消失相关的错误信息。
既然是进程没了,日志也没信息,那下一步是什么呢?就是看 dmesg 了。系统日志总有些信息吧。进程死了无非就那么几个地方能看到。
4.应用日志;
5.出 dump;
6.系统日志。
红框内的是出现问题的时间段。看到这里似乎明白了为什么并不是所有业务都失败。因为内存还有上升的这个阶段。但是为什么降到底之后又上去,再次降到底呢?先看一下拓扑图。
两个主机,四个进程,既然进程都没了,应该不是一块没的,要不然不会还有业务可以成功。
翻了一下应用日志,确实没有什么和进程消失相关的错误信息。
既然是进程没了,日志也没信息,那下一步是什么呢?就是看 dmesg 了。系统日志总有些信息吧。进程死了无非就那么几个地方能看到。
4.应用日志;
5.出 dump;
6.系统日志。
 在这里提醒一下,最好直接运行 dmesg 命令,而不是去看 /var/log/dmesg 文件。因为命令中会把其他 message 也放进去,会全一点。
查看了 dmesg 之后,发现如下信息:
在这里提醒一下,最好直接运行 dmesg 命令,而不是去看 /var/log/dmesg 文件。因为命令中会把其他 message 也放进去,会全一点。
查看了 dmesg 之后,发现如下信息:
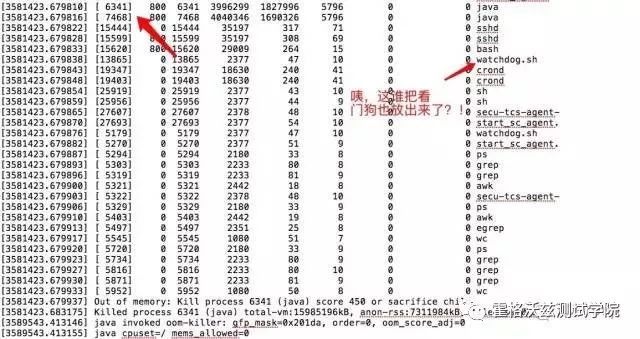 从时间上来算一下。系统运行时间 41.45 天,确实和第一个图上的 21:30 的时间对应得上。从这里来看是 6341 进程被杀了。
再看第二个图:
从时间上来算一下。系统运行时间 41.45 天,确实和第一个图上的 21:30 的时间对应得上。从这里来看是 6341 进程被杀了。
再看第二个图:
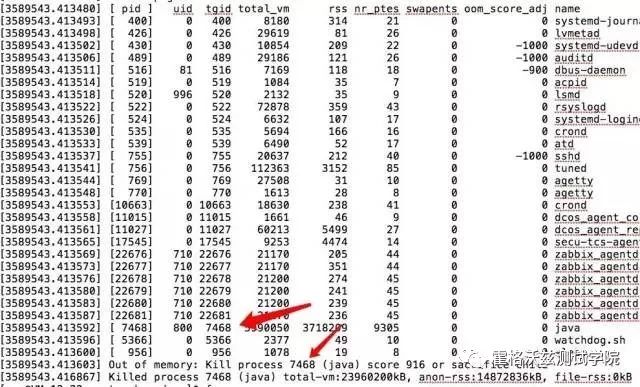 再来算一下时间。41.55 天,和第一个图上的 11:45 能对得上。
看来是 OOM Killer 主动把这两个进程给杀了。从下面的信息来看是这两个进程消耗 linux 主机的物理内存和虚拟内存太大,以致于把内存都给消耗光了,最后 OOM Killer 就站出来主持公道了:小子挺横呀,老子分给你了一亩三分地,不好好呆着,敢来抢地盘,干它!
于是就真的被 kill 了。
既然知道了内存消耗得多,那这个场景就好复现了。接着用原场景测试。看下 Java 进程的内存,Java 的内存分成堆内堆外。因为是操作系统的 OOM Killer 干掉的,所以基本上可以排除堆内的内存导致的。因为堆是有限制的嘛。
既然这样,那就是堆外。打个 threaddump 看看。
再来算一下时间。41.55 天,和第一个图上的 11:45 能对得上。
看来是 OOM Killer 主动把这两个进程给杀了。从下面的信息来看是这两个进程消耗 linux 主机的物理内存和虚拟内存太大,以致于把内存都给消耗光了,最后 OOM Killer 就站出来主持公道了:小子挺横呀,老子分给你了一亩三分地,不好好呆着,敢来抢地盘,干它!
于是就真的被 kill 了。
既然知道了内存消耗得多,那这个场景就好复现了。接着用原场景测试。看下 Java 进程的内存,Java 的内存分成堆内堆外。因为是操作系统的 OOM Killer 干掉的,所以基本上可以排除堆内的内存导致的。因为堆是有限制的嘛。
既然这样,那就是堆外。打个 threaddump 看看。
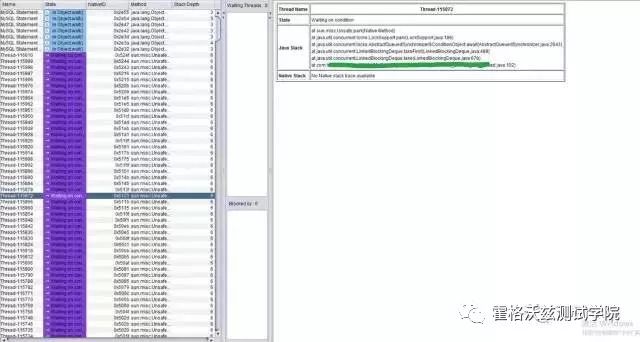 怎么这么多线程?并且也看到了开发的包名。
把这个路径给了开发之后,让他们翻翻这一段的源码,看到类似如下内容:Threadthread=newThread();(当然还有调用的代码,就不一一罗列了)开发这才知道是为啥有这么多新创建的线程。于是拿回去改去了。
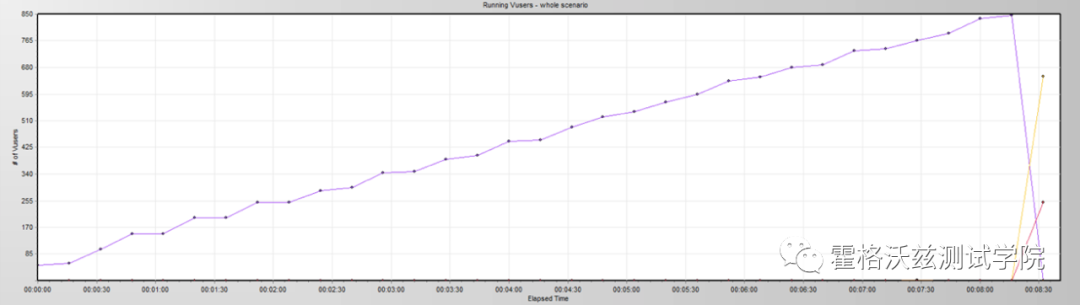
用户递增图:
怎么这么多线程?并且也看到了开发的包名。
把这个路径给了开发之后,让他们翻翻这一段的源码,看到类似如下内容:Threadthread=newThread();(当然还有调用的代码,就不一一罗列了)开发这才知道是为啥有这么多新创建的线程。于是拿回去改去了。
用户递增图:
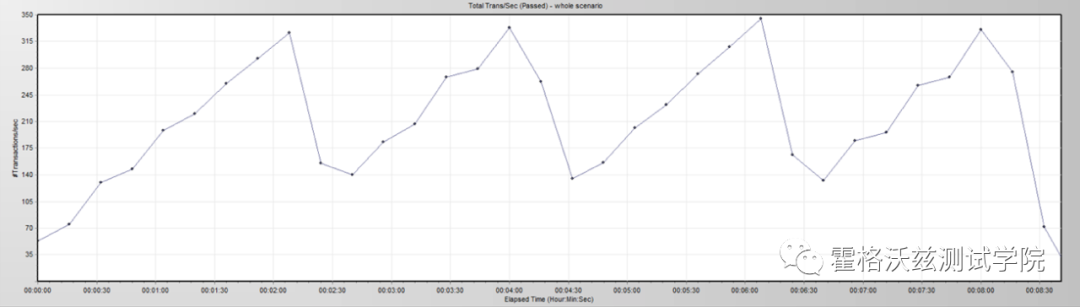
 TPS 图:
TPS 图:
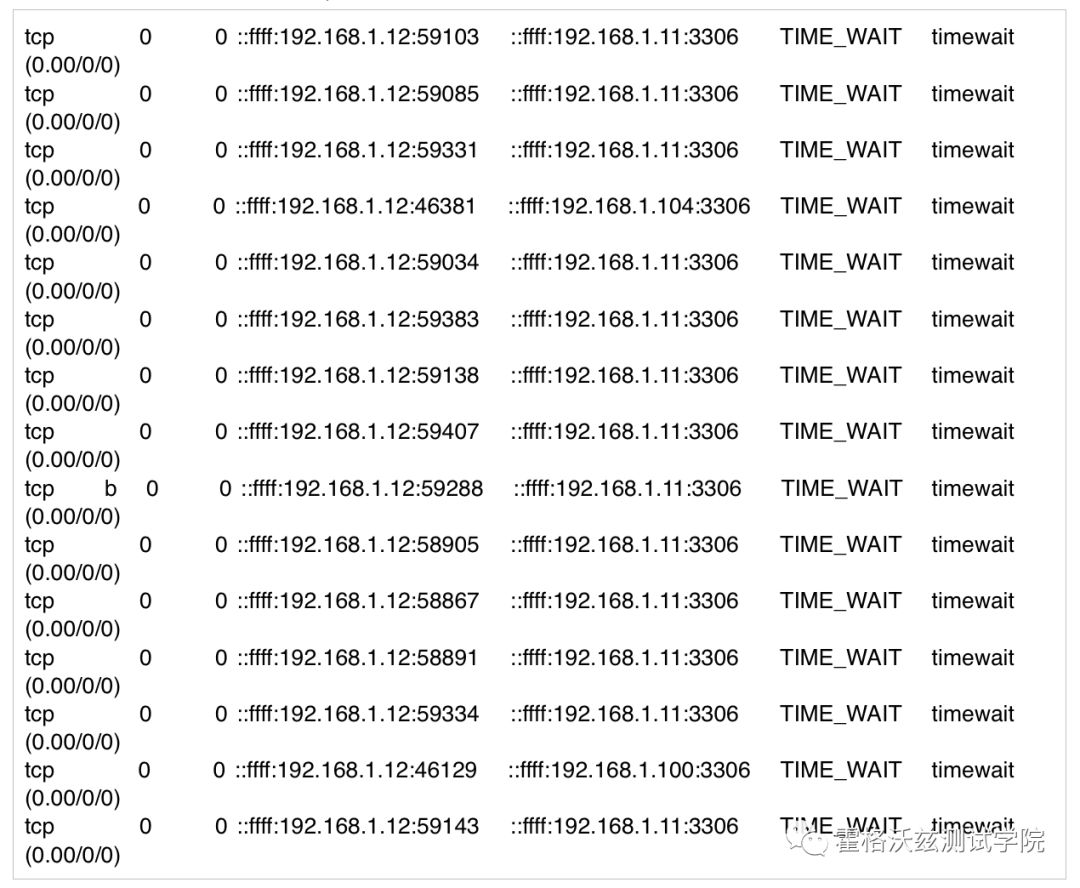
 通过查看网络连接状态,看到有大量的 TIME_WAIT 出现。
通过查看网络连接状态,看到有大量的 TIME_WAIT 出现。
 尝试分析过程如下:
1.为 TIME_WAIT 修改 TCP 参数
通过检查 sysctl.conf,看到所有的配置均为默认,于是尝试如下修改:
7. net.ipv4.tcp_tw_recycle = 1
8. net.ipv4.tcp_tw_reuse = 1
9. net.ipv4.tcp_fin_timeout = 3
10. net.ipv4.tcp_keepalive_time = 3
回归测试,问题依旧。
2.修改 Nginx 的 proxyignoreclient_abort
考虑到当客户端主动断开时,服务器上也会出现大量的 TIME_WAIT,所以打开 proxy_ignore_client_abort,让 Nginx 忽略客户端主动中断时出现的错误。proxy_ignore_client_abort on;修改后,重启 Nginx,问题依旧。
3.修改 tomcat 参数
查看 tomcat 的 server.xml 时,看到只设置了 maxthreads。考虑到线程的分配和释放也会消耗资源。所以在这里加入如下参数:maxKeepAliveRequests="256"minSpareThreads="100"maxSpareThreads="200"。
重启 tomcat,问题依旧。
4.换 Nginx 服务器
在分段测试的时候,看到通过 Nginx 就会出现 TPS 上到 300 就会下降的情况,所以考虑是 Nginx 机器的配置问题,于是换了在另一台机器上重新编译了 Nginx,所有的操作系统都是一样的配置。
通过新的 Nginx 做压力,问题依旧,所以可以判断这个问题是和操作系统的配置有关,和 Nginx 本身的配置无关。
5.停掉防火墙
和网络连接有关的内容,剩下的就只有防火墙了。于是执行了:Serviceiptables stop。在执行了之后,看到 TPS 立即就上去了。并且可以增加得非常高。从而定位,TPS 的下降和防火墙有关。
6.系统日志
进到 /var/log,查看 messages,看到大量的如下信息:
11.Nov 4 11:35:48 localhost kernel: __ratelimit: 108 callbacks suppressed
12.Nov 4 11:35:48 localhost kernel: nf_conntrack: table full, dropping packet.
13.Nov 4 11:35:48 localhost kernel: nf_conntrack: table full, dropping packet.
14.Nov 4 11:35:48 localhost kernel: nf_conntrack: table full, dropping packet.
15.Nov 4 11:35:48 localhost kernel: nf_conntrack: table full, dropping packet.
16.Nov 4 11:35:48 localhost kernel: nf_conntrack: table full, dropping packet.
17.Nov 4 11:35:48 localhost kernel: nf_conntrack: table full, dropping packet.
18.Nov 4 11:35:48 localhost kernel: nf_conntrack: table full, dropping packet.
19.Nov 4 11:35:48 localhost kernel: nf_conntrack: table full, dropping packet.
20.Nov 4 11:35:48 localhost kernel: nf_conntrack: table full, dropping packet.
21.Nov 4 11:35:48 localhost kernel: nf_conntrack: table full, dropping packet.
22.Nov 4 11:35:53 localhost kernel: __ratelimit: 592 callbacks suppressed
23.Nov 4 11:35:53 localhost kernel: nf_conntrack: table full, dropping packet.
24.Nov 4 11:35:53 localhost kernel: nf_conntrack: table full, dropping packet.
25.Nov 4 11:35:57 localhost kernel: nf_conntrack: table full, dropping packet.
26.Nov 4 11:35:57 localhost kernel: nf_conntrack: table full, dropping packet.
27.Nov 4 11:35:57 localhost kernel: nf_conntrack: table full, dropping packet.
28.Nov 4 11:35:57 localhost kernel: nf_conntrack: table full, dropping packet.
29.Nov 4 11:35:57 localhost kernel: nf_conntrack: table full, dropping packet.
30.Nov 4 11:35:57 localhost kernel: nf_conntrack: table full, dropping packet.
31.Nov 4 11:35:57 localhost kernel: nf_conntrack: table full, dropping packet.
32.Nov 4 11:35:57 localhost kernel: nf_conntrack: table full, dropping packet.
33.Nov 4 11:35:58 localhost kernel: __ratelimit: 281 callbacks suppressed
34.Nov 4 11:35:58 localhost kernel: nf_conntrack: table full, dropping packet.
35.Nov 4 11:35:58 localhost kernel: nf_conntrack: table full, dropping packet.
36.Nov 4 11:35:58 localhost kernel: nf_conntrack: table full, dropping packet.
37.Nov 4 11:35:58 localhost kernel: nf_conntrack: table full, dropping packet.
38.Nov 4 11:35:58 localhost kernel: nf_conntrack: table full, dropping packet.
39.Nov 4 11:35:58 localhost kernel: nf_conntrack: table full, dropping packet.
40.Nov 4 11:35:58 localhost kernel: nf_conntrack: table full, dropping packet.
41.Nov 4 11:35:58 localhost kernel: nf_conntrack: table full, dropping packet.
42.Nov 4 11:35:58 localhost kernel: nf_conntrack: table full, dropping packet.
43.Nov 4 11:35:58 localhost kernel: nf_conntrack: table full, dropping packet.
44.Nov 4 11:36:14 localhost kernel: __ratelimit: 7 callbacks suppressed
7.参数修改
因为出现大量的 nf_conntrack:table full,dropping packet。所以在 sysctl.conf 中加入了如下参数设置。
45.net.netfilter.nf_conntrack_max = 655350
46.net.netfilter.nf_conntrack_tcp_timeout_established = 1200
修改参数后,执行:Serviceiptables start.可以看到,TPS 仍然可以很高,从而解决问题。
解决问题后的 TPS 图:
尝试分析过程如下:
1.为 TIME_WAIT 修改 TCP 参数
通过检查 sysctl.conf,看到所有的配置均为默认,于是尝试如下修改:
7. net.ipv4.tcp_tw_recycle = 1
8. net.ipv4.tcp_tw_reuse = 1
9. net.ipv4.tcp_fin_timeout = 3
10. net.ipv4.tcp_keepalive_time = 3
回归测试,问题依旧。
2.修改 Nginx 的 proxyignoreclient_abort
考虑到当客户端主动断开时,服务器上也会出现大量的 TIME_WAIT,所以打开 proxy_ignore_client_abort,让 Nginx 忽略客户端主动中断时出现的错误。proxy_ignore_client_abort on;修改后,重启 Nginx,问题依旧。
3.修改 tomcat 参数
查看 tomcat 的 server.xml 时,看到只设置了 maxthreads。考虑到线程的分配和释放也会消耗资源。所以在这里加入如下参数:maxKeepAliveRequests="256"minSpareThreads="100"maxSpareThreads="200"。
重启 tomcat,问题依旧。
4.换 Nginx 服务器
在分段测试的时候,看到通过 Nginx 就会出现 TPS 上到 300 就会下降的情况,所以考虑是 Nginx 机器的配置问题,于是换了在另一台机器上重新编译了 Nginx,所有的操作系统都是一样的配置。
通过新的 Nginx 做压力,问题依旧,所以可以判断这个问题是和操作系统的配置有关,和 Nginx 本身的配置无关。
5.停掉防火墙
和网络连接有关的内容,剩下的就只有防火墙了。于是执行了:Serviceiptables stop。在执行了之后,看到 TPS 立即就上去了。并且可以增加得非常高。从而定位,TPS 的下降和防火墙有关。
6.系统日志
进到 /var/log,查看 messages,看到大量的如下信息:
11.Nov 4 11:35:48 localhost kernel: __ratelimit: 108 callbacks suppressed
12.Nov 4 11:35:48 localhost kernel: nf_conntrack: table full, dropping packet.
13.Nov 4 11:35:48 localhost kernel: nf_conntrack: table full, dropping packet.
14.Nov 4 11:35:48 localhost kernel: nf_conntrack: table full, dropping packet.
15.Nov 4 11:35:48 localhost kernel: nf_conntrack: table full, dropping packet.
16.Nov 4 11:35:48 localhost kernel: nf_conntrack: table full, dropping packet.
17.Nov 4 11:35:48 localhost kernel: nf_conntrack: table full, dropping packet.
18.Nov 4 11:35:48 localhost kernel: nf_conntrack: table full, dropping packet.
19.Nov 4 11:35:48 localhost kernel: nf_conntrack: table full, dropping packet.
20.Nov 4 11:35:48 localhost kernel: nf_conntrack: table full, dropping packet.
21.Nov 4 11:35:48 localhost kernel: nf_conntrack: table full, dropping packet.
22.Nov 4 11:35:53 localhost kernel: __ratelimit: 592 callbacks suppressed
23.Nov 4 11:35:53 localhost kernel: nf_conntrack: table full, dropping packet.
24.Nov 4 11:35:53 localhost kernel: nf_conntrack: table full, dropping packet.
25.Nov 4 11:35:57 localhost kernel: nf_conntrack: table full, dropping packet.
26.Nov 4 11:35:57 localhost kernel: nf_conntrack: table full, dropping packet.
27.Nov 4 11:35:57 localhost kernel: nf_conntrack: table full, dropping packet.
28.Nov 4 11:35:57 localhost kernel: nf_conntrack: table full, dropping packet.
29.Nov 4 11:35:57 localhost kernel: nf_conntrack: table full, dropping packet.
30.Nov 4 11:35:57 localhost kernel: nf_conntrack: table full, dropping packet.
31.Nov 4 11:35:57 localhost kernel: nf_conntrack: table full, dropping packet.
32.Nov 4 11:35:57 localhost kernel: nf_conntrack: table full, dropping packet.
33.Nov 4 11:35:58 localhost kernel: __ratelimit: 281 callbacks suppressed
34.Nov 4 11:35:58 localhost kernel: nf_conntrack: table full, dropping packet.
35.Nov 4 11:35:58 localhost kernel: nf_conntrack: table full, dropping packet.
36.Nov 4 11:35:58 localhost kernel: nf_conntrack: table full, dropping packet.
37.Nov 4 11:35:58 localhost kernel: nf_conntrack: table full, dropping packet.
38.Nov 4 11:35:58 localhost kernel: nf_conntrack: table full, dropping packet.
39.Nov 4 11:35:58 localhost kernel: nf_conntrack: table full, dropping packet.
40.Nov 4 11:35:58 localhost kernel: nf_conntrack: table full, dropping packet.
41.Nov 4 11:35:58 localhost kernel: nf_conntrack: table full, dropping packet.
42.Nov 4 11:35:58 localhost kernel: nf_conntrack: table full, dropping packet.
43.Nov 4 11:35:58 localhost kernel: nf_conntrack: table full, dropping packet.
44.Nov 4 11:36:14 localhost kernel: __ratelimit: 7 callbacks suppressed
7.参数修改
因为出现大量的 nf_conntrack:table full,dropping packet。所以在 sysctl.conf 中加入了如下参数设置。
45.net.netfilter.nf_conntrack_max = 655350
46.net.netfilter.nf_conntrack_tcp_timeout_established = 1200
修改参数后,执行:Serviceiptables start.可以看到,TPS 仍然可以很高,从而解决问题。
解决问题后的 TPS 图:
 上图中有两次 TPS 下降的过程是因为又尝试了修改防火墙的参数配置,重启了两次防火墙。
综上,对于性能分析来说,不仅是现象的解释,还有瓶颈的定位及问题的解决。这些工作所要求的基础知识较多,一个人力不能及的时候,就需要一个团队来做。关键是要把问题分析得清晰透彻。(end)
由霍格沃兹测试学院校长思寒老师、高楼老师以及来自腾讯、阿里巴巴的 BAT 多位资深性能测试技术专家联袂打造。3 个月大咖带你掌握性能测试实战三大核心技能:性能压测体系、性能监控体系、性能分析体系。一步步实战进阶,挑战性能之巅!
上图中有两次 TPS 下降的过程是因为又尝试了修改防火墙的参数配置,重启了两次防火墙。
综上,对于性能分析来说,不仅是现象的解释,还有瓶颈的定位及问题的解决。这些工作所要求的基础知识较多,一个人力不能及的时候,就需要一个团队来做。关键是要把问题分析得清晰透彻。(end)
由霍格沃兹测试学院校长思寒老师、高楼老师以及来自腾讯、阿里巴巴的 BAT 多位资深性能测试技术专家联袂打造。3 个月大咖带你掌握性能测试实战三大核心技能:性能压测体系、性能监控体系、性能分析体系。一步步实战进阶,挑战性能之巅!
获取更多技术文章分享和免费资料领取点击链接:`qrcode.testing-studio.com/f?from=juej… 获取更多技术文章分享和免费资料领取点击链接
