Word2vec是2013年发布的用于自然语言处理(Natural Language Processing,NLP)的一项技术。Word2vec算法使用一个神经网络模型来从一个大的语料库中学习词的关系。
这篇文章主要内容是我对论文《word2vec Parameter Learning Explained》的学习和理解,通过学习,大致了解Word2vec是如何对单词进行机器学习的。
前置知识
数学知识
-
向量
两个向量之间的夹角越小,向量的相似度越高。
向量 a 和 b 的夹角使用如下公式计算:
cosθ=∣∣a∣∣ ∣∣b∣∣a⋅b
-
导数
导数是微积分学中的一个概念。函数在某一点的导数是指这个函数在这一点附近的变化率。导数的本质是通过极限的概念对函数进行局部的线性逼近。
-
内积
又称点积、标量积或数量积。
向量 a 和 b的点积定义为:
a⋅b=∑i=1naibi=a1b1+a2b2+...+anbn
-
外积
又称为 张量积。
给定m×1 列向量u 和 1×n 行向量v,它们的外积被定义为m×n 的矩阵A。
u⊗v=A=uv
⎣⎡b1b2b3b4⎦⎤⊗[a1a2a3]=⎣⎡a1b1a1b2a1b3a1b4a2b1a2b2a2b3a2b4a3b1a3b2a3b3a3b4⎦⎤
-
转置
在线性代数中,矩阵 A 的转置是另一个矩阵 AT 由下列等价动作建立:
- 把 A的行写为 AT的列
- 把 A的列写为 AT的行
例子:
⎣⎡135246⎦⎤T=[123456]
-
矩阵乘法

自然语言处理
-
独热向量
在一任意维度的向量中,仅有一个维度的值是1,其余为0。
在自然语言处理中,词汇表中的每个词用一个独热向量表示。
比如,"大人的世界真的没有想象中简单呢"
经过分词和排序之后得到了如下的词汇表:
['世界', '中', '呢', '大人', '想象', '没有', '的', '真的', '简单']
这个句子就能得到下面这个矩阵,为了看起来直观,矩阵旁边加上了对应的字符串和该字符串在句子中对应的索引:
⎣⎡ 012345678世界001000000中000000100呢000000001大人100000000想象000001000没有000010000的010000000真的000100000简单000000010⎦⎤
分词需要专门的分词器进行处理,上述的分词只是我随便分的,用于示意,使用中文分词工具(比如jieba)分出来不一定是那样的。
-
词向量
能够表示词的含义的一定维度的向量。
-
词嵌入
词嵌入是把一个维数为所有词的数量的高维空间嵌入到一个维数低得多的连续向量空见中,每个单词或词组被映射为实数域上的问题。
嵌入:数学上,嵌入是指一个数学结构经过映射包含到另一个结构中。某个物件 X 称为嵌入到另一个物件 Y 中,是指有一个保持结构的单射f:X→Y,这个映射 f 就给出了一个嵌入。
神经网络
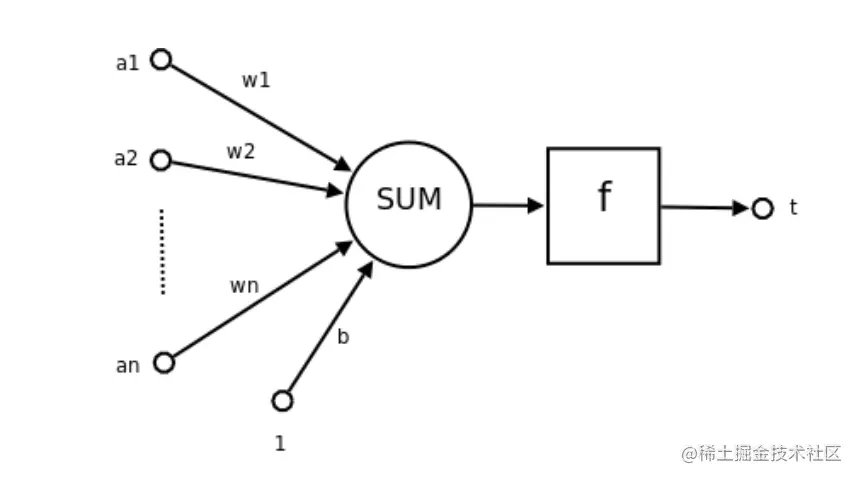
-
a1∼an为输入向量的各个分量。
-
w1∼wn为神经元各个突触的权重值。
-
b为偏置(在这篇文章中没有考虑偏置)。
-
f为传递函数(也称为激活函数),通常为非线性函数。
-
t为神经元输出。
t=f(WTA+b)
=f(a1×w1+a2×w2+...+an×wn+b)
-
神经网络
人工神经网络 (Artificial Neural Network,ANN) 由节点层组成,包含一个输入层、一个或多个隐藏层和一个输出层。 每个节点也称为一个人工神经元。
-
全连接网络
全连接网络,在全连接网络中,每个输入元素都与下一层的各个神经元相连,每个连接都有相应的权重。
-
softmax
softmax函数,或者称为 归一化指数函数。它能将一个含任意实数的K维向量 z "压缩"到另一个K 维实向量σ(z) 中,使得每一个元素的范围都在(0,1) 之间,并且所有元素的和为1。
σ(z)j=∑k=1Kezkezj for j=1,...,K
-
反向传播
反向传播(Backpropagation,缩写为BP),是"误差反向传播"的简称,是一种与最优化方法结合使用,用来训练人工神经网络的常见方法。该方法对网络中所有权重计算损失函数的梯度。这个梯度会回馈给最佳方法,用来更新权重值以最小化损失函数。
Word2Vec
训练Word2Vec嵌入有两种方法:
- 连续词袋(continuous bag-of-words,CBOW)方法,基于上下文邻近词(输入词)预测目标词(输出词)。
- skip-gram方法,基于目标词(输入词)预测上下文单词(输出词)。
CBOW模型
连续词袋(continuous bag-of-words,CBOW)方法,基于邻近词(输入词)预测目标词(输出词)。
一个上下文单词
假设每个上下文只考虑一个单词,也就是说我们给出一个上下文单词,预测一个目标词。
一、从输入层到输出层的计算过程
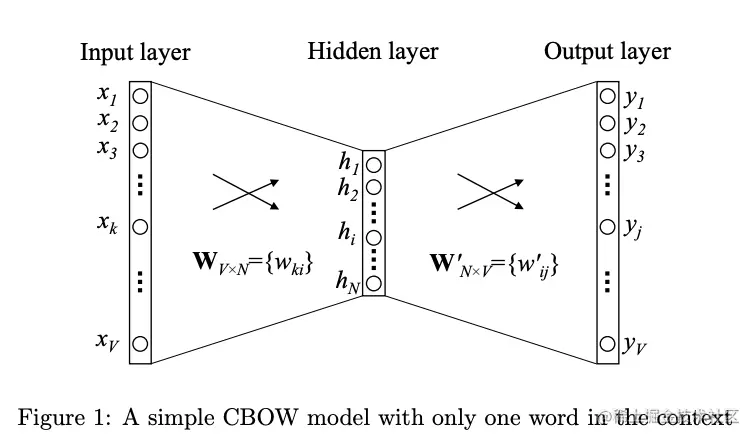
V是词的数量,N是隐藏层神经元的数量。
输入是一个独热向量 x={x1,x2,...,xV}。
输入层和隐藏层之间的权重是一个V×N 的矩阵W:
W=⎣⎡w11w21w31⋮wk1⋮wV1w12w22w32⋮wk2⋮wV2………⋱…⋱…w1Nw2Nw3N⋮wkN⋮wVN⎦⎤
N维向量vw 是表示输入单词的向量,称为"输入向量"。W的第 i 行是 vwT。
给出一个上下文单词,假设xk=1 并且对于k′=k,xk′=0。
h=WTx=W(k,⋅)T:=vwIT (1)
(WTx:=vwIT的意思是将 WTx 定义为 vwIT。)
相当于把W的第k行复制到了h中。vwI 是输入词 wI的向量表示。
隐藏层到输出层的权重是一个从 N×V 的矩阵W′={wij′}:
W′=⎣⎡w11w21w31⋮wi1⋮wN1w12w22w32⋮wi2⋮wN2………⋱…⋱…w1Vw2Vw3V⋮wiV⋮wNV⎦⎤
这里在单词上右上角加的一撇,只是为了表明是另一个矩阵,没有别的意思。
使用这个权重,我们可以为词汇表中的每个词计算一个得分:
uj=vwj′Th (2)
vwj′ 是矩阵 W′ 的第 j 列。
u={u1,u2,u3,...uj,...uv},u=W′Th。u 称为输出层神经元的净输入(net input)。
使用softmax将输入结果压缩为0到1之间的值。
p(wj∣wI)=yj=∑j′=1Veuj′euj (3)
yj是输出层的第j个单元。
将(1)、(2)代入(3)中,有:
p(wj∣wI)=yj=∑j′=1Vevwj′′Thevwj′Th (4)
vw 和 vw′ 是单词 w 的两种表示形式。vw来源于 W (输入 → 隐藏 权重矩阵)的所有行,称为单词 w 的"输入向量"; vw′ 来源于 W′(隐藏 → 输出 权重矩阵)的所有列,称为单词 w 的"输出向量"。
例子1
虽然称为例子1,其实本文的例子1、2、3都是同一个例子,只是拆成了不同部分来讲。
上述的理论知识可能稍微有一点点抽象,但是看一个具体的例子就能明白了:
V为词汇的数量,一般是一个很大的值,这里为了直观,假设V为5,N为3,权重值是随便写的一些值。
-
输入的独热向量为:x={0,1,0,0,0}。
-
输入层和隐藏层之间的权重矩阵为:
W=⎣⎡w11w21w31w41w51w12w22w32w42w52w13w23w33w43w53⎦⎤=⎣⎡0.030.160.120.320.610.230.020.560.190.320.210.580.660.990.35⎦⎤
-
通过公式 (1) 计算,得到三维结果词向量的表示。
h=WTx:=vwIT (1)
h=WTx=⎣⎡w11w12w13w21w22w23w31w32w33w41w42w43w51w52w53⎦⎤×⎣⎡01000⎦⎤
=⎣⎡0.030.230.210.160.020.580.120.560.660.320.190.990.610.320.35⎦⎤×⎣⎡01000⎦⎤
=⎣⎡0.160.020.58⎦⎤
-
隐藏层和输出层之间的权重为:
W′=⎣⎡w11′w21′w31′w12′w22′w32′w13′w23′w33′w14′w24′w34′w15′w25′w35′⎦⎤=⎣⎡0.110.350.600.770.130.290.160.050.260.500.360.920.250.370.89⎦⎤
可以用公式 (2) 为每一个单词计算一个得分:
uj=vwj′Th (2)
u=W′Th=⎣⎡w11′w12′w13′w14′w15′w21′w22′w23′w24′w25′w31′w32′w33′w34′w35′⎦⎤×⎣⎡0.160.020.58⎦⎤
=⎣⎡0.110.770.160.500.250.350.130.050.360.370.600.290.260.920.89⎦⎤×⎣⎡0.160.020.58⎦⎤
=⎣⎡0.37260.2940.17740.62080.5636⎦⎤
这里可以使用python的numpy包进行计算:
import numpy as np
w = np.array([
[0.11, 0.35, 0.60],
[0.77, 0.13, 0.29],
[0.16, 0.05, 0.26],
[0.50, 0.36, 0.92],
[0.25, 0.37, 0.89]
])
h = np.array([
[0.16],
[0.02],
[0.58]
])
print(np.dot(w, h))
[[0.3726]
[0.294 ]
[0.1774]
[0.6208]
[0.5636]]
-
使用softmax函数(用作神经元的激活函数)将输入结果压缩为0到1之间的值。
p(wj∣wI)=yj=∑j′=1Veuj′euj (3)
p(wj∣wI) 表示输入为wI的条件下,输出为wj的概率。
在第4步中,已经计算出了:
u=⎣⎡0.37260.2940.17740.62080.5636⎦⎤
通过归一化指数函数,计算出结果向量:
y=⎣⎡0.1910.1760.1570.2450.231⎦⎤
这个结果表示输出为 w0 的概率为0.191,输出为 w1 的概率是0.176。这些概率加起来的值约为1(约等于是因为保留了3位小数)。
可以通过numpy计算结果:
arr = np.array([0.3726, 0.294, 0.1774, 0.6208, 0.5636])
softmax_result = np.exp(arr) / sum(np.exp(arr))
print(softmax_result.round(3))
二、从隐藏层到输出层的权重更新方程
推导这个模型的权重更新方程。(现在这个推导理论上是可行的,但是由于现实生活中庞大的词汇量和训练语料库,在每次训练中对所有词进行计算是不现实的,需要使用分层的softmax来解决这个问题,还可以使用负采样,只处理一部分样本而不是全部样本)。
训练的目标是最大化(4):
p(wj∣wI)=yj=∑j′=1Vevwj′′Thevwj′Th (4)
也就是输入为 wI时,实际输出单词是wO(定义wO在输出层的索引是j∗)的概率。
max p(wO∣wI)=max yj∗ (5)
max log p(wO∣wI)=max log yj∗ 6
log yj∗=uj∗−log∑j′=1Veuj′:=−E (7)
将式子(3)两边同时取对数就能得到(7)。
p(wj∣wI)=yj=∑j′=1Veuj′euj (3)
E=−log p(wO∣wI)是损失函数,我们需要最小化这个值。
log没有标明底数时,底数值可能是2、10或者e。计算机相关的文档中底数一般为2,数学计算中底数10比较常见,而在这篇文章中,log的底数是e(自然底数)。
对输出层的第 j 个神经元的净输入uj求 E 的导数:
∂uj∂E=yj−tj:=ej (8)
这个导数就是输出层的预测误差,定义为 ej 。
tj=1(j=j∗),tj只有在实际输出单词是第 j 个神经元的时候为1,否则为0。
这里我理解为是因为巧妙地选择了E=−log p(wO∣wI) 作为损失函数,在满足E 越小,p(wO∣wI)越大的同时,E 对 uj 的导数刚好等于 yj−tj,是预测误差。便于后续的计算。
求导过程:
∂uj∂E=∂uj∂(log∑j′=1Veuj′−uj)
=∂uj∂E=∂uj∂(log∑j′=1Veuj′)−∂uj∂(uj)
=lne∑j′=1Veuj′euj−∂uj∂(uj)
=yj−1(j=j∗)
1是表示指示函数,当输入为True的时候,输出为1;当输入为False的时候,输出为0。
这里1其实是个空心的1,但是markdown不能直接支持这种显示。所以直接写成1了。
然后对 wij′ 求导数,得到隐藏层到输出层权重的斜率(变化率):
∂wij′∂E=∂uj∂E⋅∂wij′∂uj=ej⋅hi (9)
根据公式(2),对wij′求 uj 的导数,值为 hi 。hi 是隐藏层的第 i 个神经元的输出。
uj=vwj′Th (2)
因此,使用随机梯度下降,可以得到隐藏层到输出层的权重更新方程:
wij′(new)=wij′(old)−η⋅ej⋅hi (10)
或者:
vwj′(new)=vwj′(old)−η⋅ej⋅h for j=1,2,3,...,V (11)
η>0 是学习率,ej=yj−tj ,是预测误差,hi 是隐藏层的第 i 个神经元。vwj′是 wj 的输出向量。
学习率是一个超参数,是开始学习过程之前设置的参数,从公式 (11) 中就可以看出,学习率越大,每次调整时新向量和旧向量之间的距离就越大,选择一个合适的学习率至关重要,过大了会无法收敛到全局极小值,过小了会花费很多时间,因为每次的调整都比较小。
斜率ej⋅hi 为负的时候,表示曲线 E 是下降的,w 需要变大才能得到更小的E。
斜率ej⋅hi 为正的时候,表示曲线 E 是上升的,w 需要变小才能得到更小的E。
例子2
还是沿着例子1讲。在从输入层到输出层的计算的例子中,直接随便写了几个权重值进行计算示例,实际上这些权重是需要根据更新函数一遍遍调整,得到一个合适的值的:
vwj′(new)=vwj′(old)−η⋅ej⋅h for j=1,2,3,...,V (11)
-
一开始的时候,需要设置 W 和 W′ 中的权重为随机生成的值。如何初始化权重值很重要,是一个值得单独探讨的问题,这里就不深究了,我直接用例子1中随便写的值作为初始值。
-
假设通过训练语料库,已经得到了 上下文—目标 词对。这里是一个上下文单词对应一个目标词。假设目前词汇表中的独热向量有以下这些:
⎣⎡没有10000逻辑01000的00100单词00010库00001⎦⎤
这里选择其中的一个 上下文—目标 词对为:a={0,1,0,0,0} (上下文单词)和 b={0,0,0,1,0}(目标单词)。
-
学习率设置为 0.02,(这里也不深究学习率,只是随便设置的一个值)。
-
求∂wij′∂uj
对 wij′ 求导数,得到隐藏层到输出层权重的斜率(变化率):
∂wij′∂E=∂uj∂E⋅∂wij′∂uj=ej⋅hi (9)
先回顾下例子1中的内容:
在例子1中,用公式 (2) 为每一个单词计算一个得分:
uj=vwj′Th (2)
u=W′Th=⎣⎡w11′w12′w13′w14′w15′w21′w22′w23′w24′w25′w31′w32′w33′w34′w35′⎦⎤×⎣⎡h1h2h3⎦⎤
u=⎣⎡w11′×h1+w21′×h2+w31′×h3w12′×h1+w22′×h2+w32′×h3w13′×h1+w23′×h2+w33′×h3w14′×h1+w24′×h2+w34′×h3w15′×h1+w25′×h2+w35′×h3⎦⎤
能直观地得出:∂wij′∂uj=hi
-
根据例子1中得到的输出结果:
y=⎣⎡0.1910.1760.1570.2450.231⎦⎤
因为上下文目标词对是:a={0,1,0,0,0} (上下文单词)和 b={0,0,0,1,0}(目标单词),所以在j=1,的时候,yj=0.191,tj=0,ej=0.191。在j=4 的时候,yj=0.245,tj=1,所以ej=−0.755。这样就能得到每一个输出层神经元的预测误差。用e 表示输出层各个位置对应的误差,在这一次计算中,有:
e=⎣⎡e1e2e3e4e5⎦⎤=⎣⎡0.1910.1760.157−0.7550.231⎦⎤
对输出层的第 j 个神经元的净输入uj求 E 的导数:
∂uj∂E=yj−tj:=ej (8)
对 wij′ 求导数,得到隐藏层到输出层权重的斜率(变化率):
∂wij′∂E=∂uj∂E⋅∂wij′∂uj=ej⋅hi (9)
-
通过预测误差更新权重,隐藏层到输出层权重的更新方程为:
vwj′(new)=vwj′(old)−η⋅ej⋅h for j=1,2,3,...,V (11)
W′T=⎣⎡w11′w12′w13′w14′w15′w21′w22′w23′w24′w25′w31′w32′w33′w34′w35′⎦⎤=⎣⎡0.110.770.160.500.250.350.130.050.360.370.600.290.260.920.89⎦⎤
以j=1 为例:
vw1′(old)=⎣⎡0.110.350.60⎦⎤
vw1′(new)=vw1′(old)−η⋅(y1−t1)⋅h
根据例子1中的计算,已经得出y1=0.191,根据训练集的到的上下文-目标 词对,t1 为0。
所以:
vw1′(new)=vw1′(old)−η⋅(y1−t1)⋅h
vw1′(new)=⎣⎡0.110.350.60⎦⎤−0.02⋅0.191⋅⎣⎡0.160.020.28⎦⎤
=⎣⎡0.1090.350.598⎦⎤
可以使用numpy进行计算:
import numpy as np
h = np.array([
[0.16],
[0.02],
[0.58]
])
v_old = np.array([
[0.11],
[0.35],
[0.60]
])
v_new = v_old - 0.02 * 0.191 * h
print(v_new.round(3))
[[0.109]
[0.35 ]
[0.598]]
这就求出了vw1′(new),
-
按同样的方法求出 W′ 1 ~ 5 列的值,就得到了新的权重矩阵 W′(new):
W′(new)=⎣⎡0.1090.350.5980.7690.130.2880.1590.050.2580.5020.360.9290.2510.370.893⎦⎤
遍历词汇表中的所有单词,根据得到的输出结果和实际应该输出结果的误差,先把W′ 的值更新,然后根据更新后的W′ 的值,把W 更新,然后重新进行一遍从输入层到输出层的计算,根据得到的输出结果和实际应该输出结果的误差,重复这个过程,直到输出值 和 实际应该输出值的误差在一个较小的范围内。
三、从输入层到隐藏层的权重更新方程
对隐藏层的输出求 E 的导数。
∂hi∂E=∑j=1V∂uj∂E⋅∂hi∂uj=∑j=1Vej⋅wij′:=EHi (12)
hi 是隐藏层的第 i 个神经元的输出,uj 在公式 (2) 中定义,是输出层的第j 个神经元的净输入。
uj=vwj′Th (2)
ej=yj−tj 是输出层的第j 个词的预测错误。
根据 (1) 我们得到:
hi=∑k=1Vwki⋅xk (13)
h=WTx:=vwIT (1)
对 W 的每一个元素求E 的导数,得到:
∂wki∂E=∂hi∂E⋅∂wki∂hi=EHi⋅xk (14)
这等于x 和 EH 的张量积。
∂W∂E=x⊗EH=xEHT (15)
我们得到了一个V×N 的矩阵。因为x 只有一个元素是非0的,所以∂W∂E只有一行是非0的。所有W 的其他行在这次迭代之后并没有改变,因为它们的导数是0。我们得到W 的更新方程是:
vwI(new)=vwI(old)−ηEHT (16)
因为EH 是词汇表中的所有单词的输出向量和他们的预测错误ej=yj−tj的加权。我们可以理解(16)为:将词汇表中的每个输出向量的一部分添加到上下文单词的输入向量中。
如果yj>tj,上下文单词的输入向量wI 会移动到离输出向量wj 较远的地方;
如果yj<tj,上下文单词的输入向量wI 会移动到离输出向量wj更近的地方;
如果wj 已经被相当准确地预测了,它对输入向量wI的移动的影响就较小。
因为我们一遍遍地更新模型参数,通过遍历由训练语料库生成的上下文单词和目标单词对,对向量的影响会累积。在多次迭代之后,输入和输出单词之间的相对位置会最终平衡。
例子3
-
求∂hi∂uj,先回顾下例子1中的内容:
在例子1中,用公式 (2) 为每一个单词计算一个得分:
uj=vwj′Th (2)
u=W′Th=⎣⎡w11′w12′w13′w14′w15′w21′w22′w23′w24′w25′w31′w32′w33′w34′w35′⎦⎤×⎣⎡h1h2h3⎦⎤
u=⎣⎡w11′×h1+w21′×h2+w31′×h3w12′×h1+w22′×h2+w32′×h3w13′×h1+w23′×h2+w33′×h3w14′×h1+w24′×h2+w34′×h3w15′×h1+w25′×h2+w35′×h3⎦⎤
当i=1 时,∑j=1V∂uj∂E⋅∂hi∂uj=e1×w11′+e2×w12′+e3×w13′+e4×w14′+e5×w15′
EH1=0.021+0.135+0.025+−0.379+0.058=−0.14
注意,这里的wij′ 是通过隐藏层和输出层之间的更新方程,已经更新过的权重。
用同样的方法,可以计算i 为 1 ~ 3 时的∑j=1V∂uj∂E⋅∂hi∂uj。得到EH 为:
EH=[−0.14−0.055−0.288]
用e 表示输出层各个位置对应的误差,在这一次计算中,有:
e=⎣⎡e1e2e3e4e5⎦⎤=⎣⎡0.1910.1760.157−0.7550.231⎦⎤
根据隐藏层到输出层之间的更新方程,已经得到的新的权重矩阵 W′(new):
W′(new)=⎣⎡0.1090.350.5980.7690.130.2880.1590.050.2580.5020.360.9290.2510.370.893⎦⎤
对隐藏层的输出求 E 的导数:
∂hi∂E=∑j=1V∂uj∂E⋅∂hi∂uj=∑j=1Vej⋅wij′:=EHi (12)
-
使用更新方程得到新的权重
在例子1中,输入层输入的独热向量,在k=2 时为1,其余时候为0。
h=WTx=⎣⎡w11w12w13w21w22w23w31w32w33w41w42w43w51w52w53⎦⎤×⎣⎡x1x2x3x4x5⎦⎤
=⎣⎡w11×x1+w21×x2+w31×x3+w41×x4+w51×x5w12×x1+w22×x2+w32×x3+w42×x4+w52×x5w13×x1+w23×x2+w33×x3+w43×x4+w53×x5⎦⎤
在这个例子中,输入的独热向量在k=2 时为1,其余时候为0。
∂W∂E=x⊗EH=⎣⎡x1x2x3x4x5⎦⎤⊗[−0.14−0.055−0.288]
=⎣⎡−0.14×x1−0.14×x2−0.14×x3−0.14×x4−0.14×x5−0.055×x1−0.055×x2−0.055×x3−0.055×x4−0.055×x5−0.288×x1−0.288×x2−0.288×x3−0.288×x4−0.288×x5⎦⎤
=⎣⎡0−0.140000−0.0550000−0.288000⎦⎤
W(new)=⎣⎡0.030.160.120.320.610.230.020.560.190.320.210.580.660.990.35⎦⎤−0.02⋅⎣⎡0−0.140000−0.0550000−0.288000⎦⎤
=⎣⎡0.030.1620.120.320.610.230.0210.560.190.320.210.5860.660.990.35⎦⎤
这就是更新后的输入层到隐藏层的权重。
以上过程大致总结如下:
从这里到之后的内容,只是大致看了下,并没有进行实际的计算。先记录在这里,后续如果有时间可以再细看并补充一下这部分内容。
多个单词的上下文
有多个上下文单词的CBOW模型是这样的如下图所示:
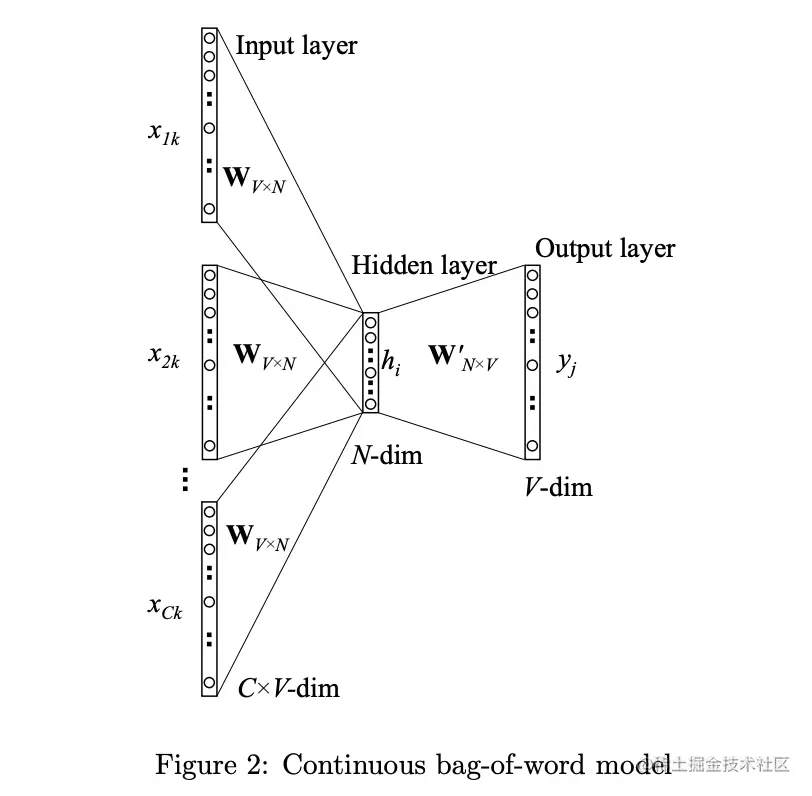 又多个上下文单词的CBOW模型取了输入上下文单词向量的平均值。
又多个上下文单词的CBOW模型取了输入上下文单词向量的平均值。
h=C1WT(x1+x2+...+xC) (17)
=C1(vw1+vw2+...+vwC)T (18)
C 是上下文中单词的数量,w1,...,wC 是上下文中的单词,vw 是一个单词w 的输入向量,损失方程是:
E=−log p(wO∣wI,1,...,wI,C) (19)
=−uj∗+log∑j′=1Veuj′ (20)
=−vwO′T⋅h+log∑j′=1Vevwj′T (21)
隐藏层到输出层的权重的更新方程和一个单词的上下文模型的方程(11)一样:
vwj′(new)=vwj′(old)−η⋅ej⋅h for j=1,2,3,...,V (22)
输入层和隐藏层权重的更新方程和(16)类似,除了我们现在需要为上下文中的每一个单词wI,C 应用这个单词:
vwI(new)=vwI(old)−ηEHT for c=1,2,3,...,C (23)
Skip-Gram模型
skip-gram模型和CBOW模型是相反的,目标词是输入层,上下文单词在输出层。
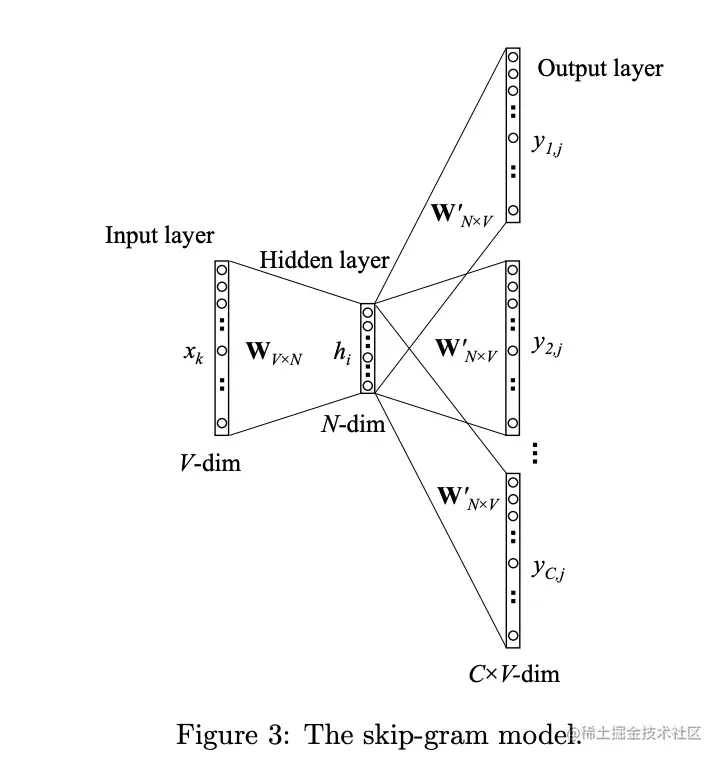
h=WTx=W(k,⋅)T:=vwIT (24)
p(wc,j=wO,c∣wI)=yc,j=∑j′=1Veuj′euc,j (25)
wc,j 是输出层第 c 个面板上的第 j 个单词;wO,c 是输出上下文单词中实际的第c 个单词。wI 是输入单词,yc,j 是输出层的第c 个面板的第j 个神经元的输出。uc,j 是输出层的第c 个面板的第j 个神经元的净输入。
uc,j=uj=vwj′T⋅h for c=1,2,3...,C (26)
损失函数是:
E=−log p(wO,1,wO,2,...,wO,C∣wI) (27)
=−log ∏c=1C∑j′=1Veuj′euc,jc∗ (28)
=−∑c=1Cujc∗+C⋅log∑j′=1Veuj′ (29)
jc∗ 是词汇表中的实际的第c 个输出上下文单词的索引。
∂uc,j∂E=yc,j−tc,j:=ec,j (30)
这是神经元的预测错误,和(8) 一样。为了简单声明,我们定义了一个V 维向量 EI={EI1,...,EIV}作为所有上下文单词的预测错误的和:
EIj=∑c=1Cec,j (31)
现在,对隐藏层到输出层的矩阵W′求E 的导数,得到:
∂wij′∂E=∑c=1C∂uc,j∂E⋅∂wij′∂uc,j=EIj⋅hi (32)
因此,我们得到隐藏层到输出层的矩阵W′的更新方程:
wwij′(new)=wwij′(old)−η⋅EIj⋅hi (33)
或者
vwj′(new)=vwj′(old)−η⋅EIj⋅h for j=1,2,3,...,V (34)
输入层到隐藏层之间的更新方程:
vwI(new)=vwI(old)−η⋅EHT (35)
EH 是一个N 维向量,每一个元素被定义为:
EHi=∑j=1VEIj⋅wij′ (36)
参考内容
- 论文:《word2vec Parameter Learning Explained》
- 书籍:《自然语言处理实战》
- 维基百科中对各个名词的解释。


