

在Node中,应用需要处理网络协议、操作数据库、处理图片、接收上传文件等, 在网络流和文件操作中, 还要处理大量二进制数据, JavaScript自带的字符串远远不能满足这些需求, 于是Buffer对象应运而生。
Buffer结构
Buffer是一个像Array的对象,主要用于操作字节。 它将性能相关部分用C++实现, 将非性能相关的部分用JavaScript实现。由于Buffer太过常见, Node在进程启动时就已经加载了它, 并将其放在全局对象上。 所以在使用Buffer时, 无需通过require() 即可直接使用。
Buffer对象
Buffer 类是 JavaScript Uint8Array 类的子类。 它的元素为16进制的两位数, 注意 Buffer() 已经弃用了, 新版本用Buffer.from(str, unitCode) 替代
其中unitCode 支持: ASCII UTF-8 Base64 Binary USC-2 Hex, 不写就默认UTF-8
我们也可以通过 Buffer.isEncoding() 判断是否支持编码类型。
与Array一样, Buffer也可以访问length属性得到长度, 也可以通过下标访问元素,代码如下:
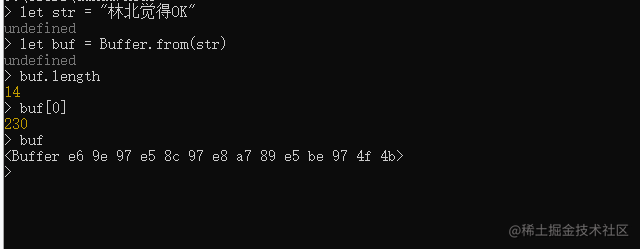
length计算方法: 中文占3个长度, 字母和半角标点符号占1个长度。
另外 buf[0] = e6 = 14 * 16 + 6 = 230
同样也可以手动赋值给buf, 如
```js
buf[2] = 166 //0~255之间的随机值
//如果给的值小于0, 就自动将该值逐次加256, 直到它的值在0~255之间。
//如果赋值大于255, 就逐次减256
//如果是小数, 只保留整数部分,舍弃小数部分
Buffer转字符串
直接使用 toString() 即可
iconv & iconv-lite
对于Buffer.from 不支持的类型,可以借助Node生态圈中得模块实现, 如: iconv 和 iconv-lite。
iconv 通过C++实现, iconv-lite 采用纯JavaScript 实现, 下面以iconv-lite为例写个demo:
let iconv = require('iconv-lite')
//Buffer转字符串
let str = iconv.decode(buf, 'GBK')
//字符串转Buffer
let buf = iconv.encode(str, 'GBK')
Buffer 拼接
Buffer在实际使用场景中, 通常是以一段一段的方式传输, 这里要牵扯到文件流来举例了。
const fs = require('fs')
let fileStream= fs.createReadStream('xx.text')
//如果读取的是图片, 可以根据需要设置
fileStream.setEncoding('base64')
let buf = ''
//监听data事件, data事件是Node提供的(自带的)
fileStream.on('data', function(chunk) { //chunk 是Buffer对象
buf += chunk
})
fileStream.on('end', () => {
console.log(buf)
})
highWaterMark
let opts = {
flags: 对文件进行何种操作,默认为'r',读文件
encoding:指定编码,默认为null,如果不设置具体的编码格式,读出的数据就是Buffer类型;
//start:从start开始读取文件
//end:读取文件到end为止(包括end)
highWaterMark: 最高水位线,内部缓冲区最多能容纳的字节数,如果超过这个大小,
就停止读取资源文件,我搜索得到的 默认值是64KB, 写文件默认是16KB, 所以读写速度是有差异的
}
fs.createReadStream(filePath , opts)
在文件读取时, highWaterMark 设置对性能的影响至关重要, 下面是我不加highWaterMark时的测试, 读取时间花了 10 秒
const fs = require('fs')
let fileStream = fs.createReadStream('./goland.exe') //大概 370M
let res = ''
let startTime = null
fileStream.on('data', chunk => {
startTime = startTime || new Date().getSeconds();
console.log(startTime)
res += chunk
})
fileStream.on('end', () => {
let endTime = new Date().getSeconds();
console.log(endTime)
})
接下来我们设置下highWaterMark缓冲区大小
变成了8秒, 书上说该值越大, 读取速度越快, 但是我测了好像到了一定程度就快不了了, 再大也没用!!!
alloc(size, fill, encoding)
const buf = Buffer.alloc(5); //默认fill = 0, encoding = 'utf-8'
console.log(buf);
// 打印: <Buffer 00 00 00 00 00>
const buf = Buffer.alloc(5, 'a');
console.log(buf);
// 打印: <Buffer 61 61 61 61 61> //16进制61, 对应ASCII码97 (一起念: 阿思gi)
copy
let A = Buffer.from('abcdefg')
let B = Buffer.from('hijklmn')
// 将 `A` 字节的[1, 3) 复制到 `B` 中,从 `B` 第 0 位 开始。
A.copy(B, 0, 1, 3) //后面两位前开后闭
console.log(1, A);
console.log(2, B);
最后的轻语
一个人的成功, 只有15%归结于他的专业知识, 另外的85%要归结于他的表达思想、 领导他人及唤起他人热情的能力。 --------
西方的一位智者, 戴尔*卡耐基
