简介
多模态学习的目标是处理和联系不同模态(如图像,文本和音频等)间的数据,本文主要针对双模态数据,特别是图像和文本间的跨模态检索研究,跨模态学习的一个关键挑战是模态的异质性ーー缺乏来自不同模态数据间的直接比较。为解决这个问题,一个经典的方案是在一个联合潜在子空间中表示不同模态的数据,从而捕获跨模态数据间的联系。
最具代表性的跨模态子空间学习方法之一是 canonical correlation analysis(CCA),通过最大化两个模态间投影特征间的相关性来学习其公共子空间,然而CCA只考虑数据模态间的直接联系,而忽视了一些高层语义信息例如数据标签等。
虽然标签语义在学习多模态数据表示时可能有所帮助,但在跨模态学习中仍需谨慎使用标签语义,因为用户提供的标签注释在现实场景中常常是模糊的和不准确的,这些标签很可能对跨模态学习模型的性能产生不利影响。
如图1所示的例子中,根据标签两张图片可能都被标记为“person”的类别中,被认为语义相似的概率很高,可是它们的内容差别很大。因此,有必要对语义依赖的某些方面加以区分,使其有更明确的区分。

为这就这个问题,文章提出了 Feature Learning and Partial Correlation Learning (FLPCL)。具体的说,特征学习(Feature Learning)是用于学习每个模态中语义一致和不一致的特征表示,而局部相关性学习(Partial Correlation Learning)基于标签语义最大化不同模态间的学习特征表示相关性。通过充分利用上述特点,FLPCL可以明确地保留模态间和模态内的关系,从而有效地完成跨模态检索任务。
相关工作
CCA算法
CCA是一个非常受欢迎的统计学习方法,通过学习线性投影来最大化不同模态间的相关性。相关改进工作还有generalized multiview analysis (GMA)、A three-view for-
mulation of CCA (3V-CCA) 、Multi-label
CCA (ml-CCA)等等,但这些方法都没有考虑到用户标签的噪声问题。
跨模态数据检索 Cross-Modal Retrieval
跨模态数据检索的目标在于从一个模态中检索语义相关的数据实例,以响应另一个模态的查询。例如,给定一个图像查询,用户可以从数据库中检索相关的文本描述或者给定一个文本查询可以返回相关内容的图像。
跨模态检索的一个基本挑战是如何学习到一种有意义的方式来表示和关联数据。
局部CCA
首先回顾局部CCA的概念,它在剔除第三个变量的线性影响后,找出两个变量之间的相关性。
给定图像和文本两个模态的样本对数据集D={(y1u,y1t),...,(yNv,yNt)},其中N为样本规模,i=1,...,N,yiu∈Rdv,yit∈Rdt为第i个样本的原始图像和文本特征。每个图像-文本对(yiu,yit)都被分配了一个语义标签向量xi。定义图像模态的数据矩阵为Yu=[y1u,...,yNu],同理得到文本模态的数据矩阵Yt=[y1t,...,yNt],和标签模态X=[x1,...,xN]∈Rdx×N。标签模态X被用作第三语义模态,它可以被解释,为图像模态和文本模态间观测到的关系。综上,局部CCA可以被形式化为下面的多元线性多重回归模型:
Yv=AXv+ev∣X Yv=AXt+et∣X
其中Av∈Rdv×dx,At∈Rdt×dx为常数系数矩阵。正态随机误差矩阵ev∣X∈Rdv×N,et∣X∈Rdt×N称为残差(residuals),为Yv,Yt间的度量。选取矩阵Av,At使均方误差的期望值最小,获得下面的矩阵(^)表示估计值:
A^v=ΣvXΣXX−1,A^t=ΣtXΣXX−1
Σ表示协方差矩阵,ΣvX=YvXT,ΣXX=XXT,ΣtX=YtXT。
综上可知,ev∣X=Yv−Y^v=Yv−A^vX,et∣X=Yt−Y^t=Yt−A^tX,则残差矩阵间的典型相关性Yv−Y^v,Yt−Y^t被称为局部典型相关性(partial canonical correlation)。
本文方法
对于给定图像和文本模态,FLPCL的任务是学习一个共同潜在空间来捕获两个模态间的共享相关性信息,然后使用这些信息来学习跨模态信息检索的潜在表示方法。为了生成高度语义相关的多模态嵌入,将附加的语义标签看作第三模态并被两种模态共享,图2展示了FLPCL的总体框架,由两个部分构成:特征学习和局部相关性学习。
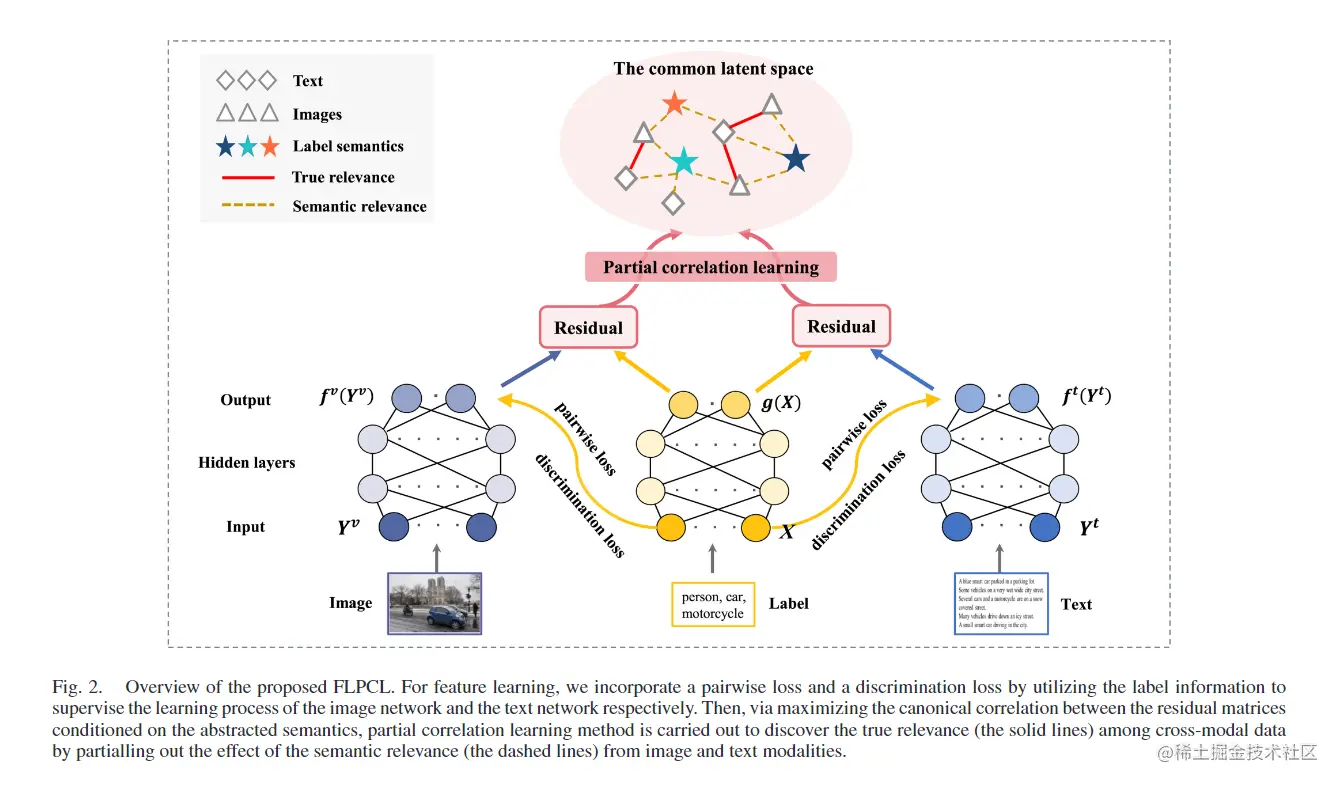
特征学习
给定三个模态(图像、文本和标签),首先使用全连接深度神经网络(DNN)模型来学习它们各自的低维表示。对于图像模态,首先将每个图像表示为一个向量yiv,然后将特征向量的集合Yv作为DNN的输入,Yv的第一次输出为h1v=s(H1vYv+Θ1v),s(⋅)为一个非线性激活函数,H1v为一个权重矩阵,Θ1v为一个偏置矩阵。Yv再作为下一层的输入,反复重复这个步骤直到得到最终DNN的输出为fv=fv(Yv)=[f1v,...,fNv]∈Rdv′×N,同理可得文本模态的最终输出ft。
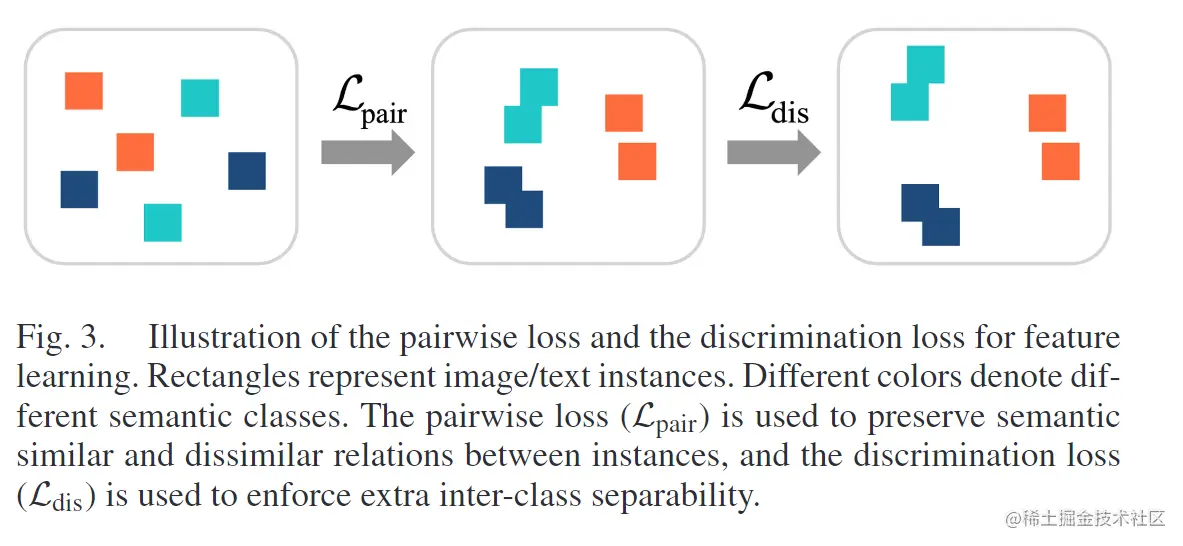
为学习图像/文本网络的相关和不相关特征,向嵌入空间中引入两个辅助损失约束,即成对损失和鉴别损失,如图3所示,图中矩形表示图像/文本实例,不同的颜色表示不同的语义类别。成对损失Lpair用于表示实例间语义相同和不同的关系,鉴别损失Ldis用来加强类之间的可分离性。
成对损失:带有相同标签信息的相同模态实例在嵌入空间中会拥有相似的输出表示,为获得图像和文本模态的语义连续嵌入空间,多标签注释信息被用作监督来指导每个模态的特征学习。将两个实例之间的语义相似度定义为相应标签特征之间的成对相似度,即Sij=xiTxj。在给定图像特征表示时,语义相似度的特性被假设为一个概率分布函数:
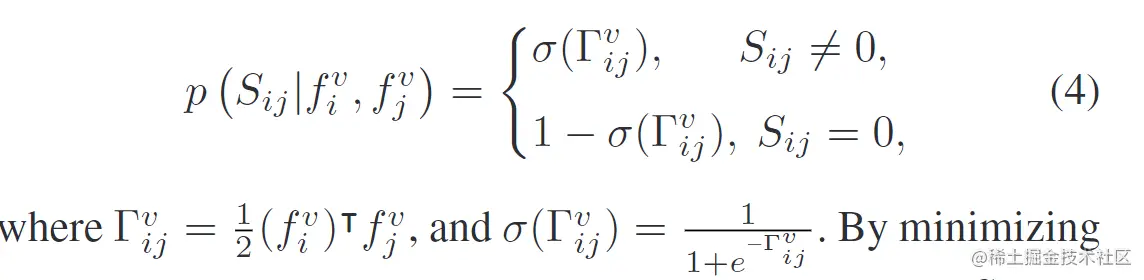
通过最小化Sij的负对数似然值,可以得到下面的损失:
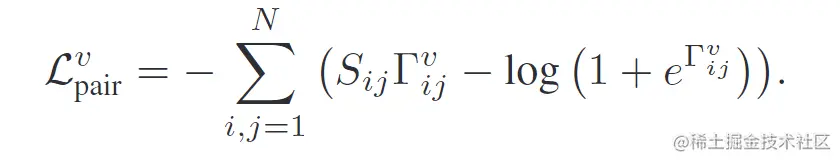
对于文本模态也是类似的方法得到Lpairt。
鉴别损失:将鉴别损失定义为一个全连接层、一个softmax 函数和一个交叉熵损失的组合。全连接层就像一个线性分类器,softmax交叉熵损失被用来促进特征表示的可分离性。
首先将从图像网络中提取到的图像表示fv输入到softmax分类器中来预测一个语义类别的概率分布p^v,对于第i个图像特性的预测概率p^iv可以定义为:
p^iv=∑j=1dxexp((ξjv)Tfiv)exp((ξxiv)Tfiv)
其中fiv为DNN表示的第i张图像,xi为其对应的标签,ξjv表示全连接网络权重矩阵ξv的第j行。标签维度dx表示语义类别的数量。利用交叉熵损失分别计算图像和文本模态的判别损失,分别表示为:
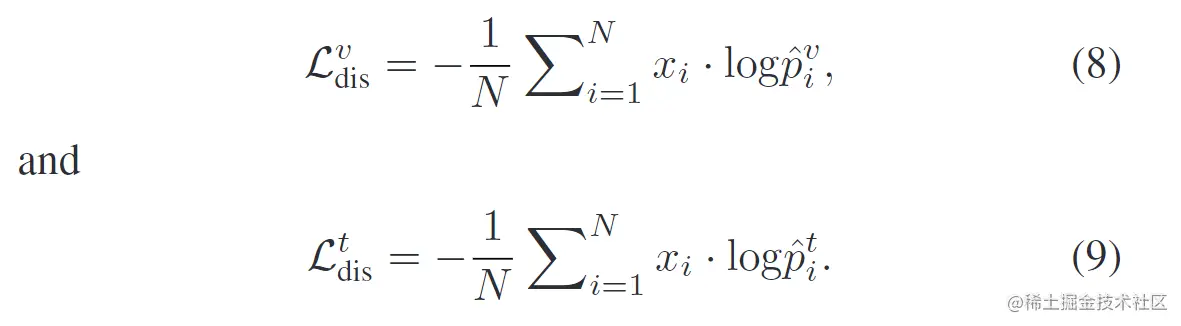
最小化两个损失可以提升嵌入空间中模态表示的鉴别能力。
第j对图像-文本对的标签注释定义为xj,若第j个数据对属于i类别,则xij=1,否则为0。标签矩阵定义为X,使用DNN来获得最终标签特征g=g(X)∈Rdx′×N。
语义局部相关性学习
为学习不同模态之间的语义局部相关性,需要最大化fv,ft间的典型相关
性。首先根据线描的局部CCA公式计算回归模型:
fv(Yv)=BvG(X)+efv∣G,ft(Yt)=BtG(X)+eft∣G
其中G=G(X)=WTg(X),efv∣G,eft∣G为新的残差矩阵,B^v=ΣfvGΣGG−1,B^t=ΣftGΣGG−1,且ΣfvG=cov(fv,G),ΣftG=cov(ft,G)。通过最大化基于标签语义的新残差矩阵之间的典型相关,可以获得跨模态部分相关性学习的目标:
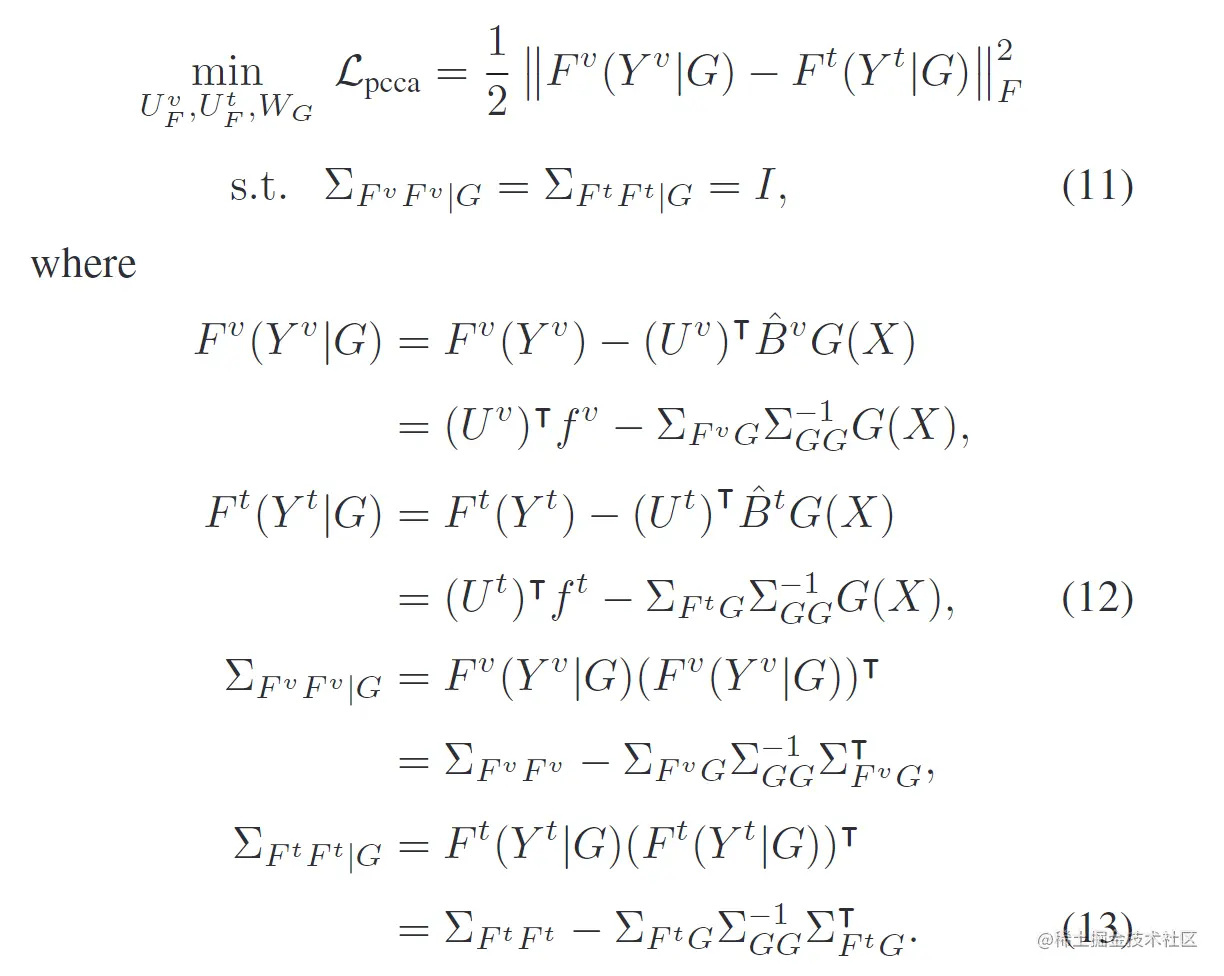
优化
FLPCL的总体目标如下:
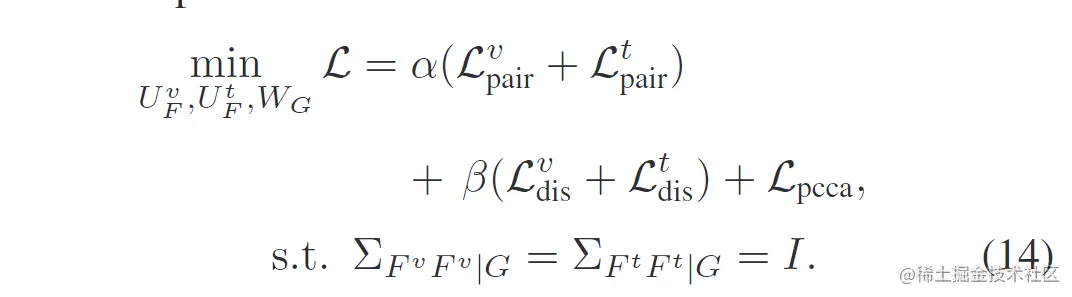
其中Lpairv,Lpairt用于表示模态内的语义一致性,交叉熵函数Ldisv,Ldist用于提升模态内特征鉴别性,Lpcca用于最大化模态间局部典型相关性,其余为参数。


