

这篇文章是收集我在工作中经常会用到的nginx相关知识点,本文并不是基础知识的讲解更多的是一些方案中的简单实现。
序言
Nginx 是开源、高性能、高可靠的 Web 和反向代理服务器,而且支持热部署,几乎可以做到 7 * 24 小时不间断运行,即使运行几个月也不需要重新启动,还能在不间断服务的情况下对软件版本进行热更新。性能是 Nginx 最重要的考量,其占用内存少、并发能力强、能支持高达 5w 个并发连接数,最重要的是,Nginx 是免费的并可以商业化,配置使用也比较简单。
本次分享不会过多的着墨于Nginx的api讲解以及干巴巴地概念,而是会从Nginx能够帮我们解决什么问题入手来向大家展示Nginx的几个重要使用场景;(偏向于前端场景)
Nginx 的最重要的几个使用场景:
- web相关-单页面history配置
- web相关-跨域问题解决(反向代理或者设置跨域头部)
- web相关-动静分离 + 缓存
- 负载均衡
- 简易的灰度部署
- 优雅降级-ssr方案的容灾处理
Location 路径匹配
在讲解具体应用场景之前,有必要先了解 nginx 中的 location指令;location 就是nginx中的路由——用于匹配 uri;
server {
# 匹配具体的路由地址
location / {
try_files $uri $uri/ /index.html;
}
}
上面是一个location匹配的例子,实际上,location匹配表达式还有多种,如果按照优先级划分的话会分成以下几种:
=表示精确匹配。只有请求的url路径与后面的字符串完全相等时,才会命中。 优先级最高^~表示前缀匹配,如果该符号后面的字符是最佳匹配,采用该规则,不再进行后续的查找。~表示该规则是使用正则定义的,区分大小写。~*表示该规则是使用正则定义的,不区分大小写。- '空格' 表示普通匹配。
一般前缀匹配
^~和 普通匹配空格统称为非正则匹配
换成符号的优先级就是:
[=] > [^~] > [~/~*] > [空格]
简而言之,匹配规则如下:
- 查找精确匹配
=, 满足的话直接退出 - (没有前缀匹配的话可以跳过第2步)查找非正则匹配(前缀匹配 和 普通匹配)的最长匹配结果, 如果结果是由前缀匹配
^~修饰的那么直接返回,不是的话先缓存结果 - 查找正则匹配,按从上到下的顺序进行匹配;只要从上到下正则满足一个就直接返回退出;
- 正则都没有匹配到的话,那么会返回第2步没有用前缀匹配
^~修饰修饰的结果;
# 表示全匹配 任何未匹配到的路由最终都会经过这里处理
location / {
try_files $uri $uri/ /index.html;
}
Location 例子
server {
server_name website.com;
location /document {
return 701;
}
location ~* ^/docume.*$ {
return 702;
}
location ~* ^/document$ {
return 703;
}
}
curl -I website.com/document
HTTP/1.1 702
# 匹配702 没有前缀匹配 正则的优先级更高,而且正则是一旦匹配到就直接退出 所以不会再匹配703
server {
server_name website.com;
location ~* ^/docume.*$ {
return 701;
}
location ^~ /doc {
return 702;
}
location ~* ^/document$ {
return 703;
}
}
curl http://website.com/document
HTTP/1.1 702
# 匹配702 因为 第2步中最长匹配是 前缀匹配^~ 所以直接返回 不再匹配正则字符串
server {
server_name website.com;
location /doc {
return 702;
}
location /docu {
return 701;
}
}
curl http://website.com/document
HTTP/1.1 701
# 701 普通匹配是按照最长匹配,跟顺序无关
server {
server_name website.com;
location ^~ /doc {
return 702;
}
location /docu {
return 701;
}
location ~* ^/ccc {
return 703;
}
}
curl http://website.com/document
HTTP/1.1 701
# 701 第2步匹配的最长字符串是 /docu 但不是前缀匹配 所以先放着
# 正则匹配不上 返回最长匹配结果 所以就是701
server {
server_name website.com;
location ^~ /doc {
return 702;
}
location /docu {
return 701;
}
location ~* ^/doc {
return 703;
}
}
curl http://website.com/document
HTTP/1.1 703
# 703 第2步匹配的最长字符串是 /docu 但不是前缀匹配 所以先放着
# 正则匹配上了 直接返回正则的 703
server {
server_name website.com;
location ^~ /docum {
return 702;
}
location /docu {
return 701;
}
location ~* ^/doc {
return 703;
}
}
curl http://website.com/document
HTTP/1.1 702
# 702 第2步匹配的最长字符串是 /docum 而且是前缀匹配 ^~ 直接返回 702
单页面history配置
以下内容少部分摘自vue-router官方文档
目前前端HTML5的单页面路由实现基于两种形式,各有优缺点:
Hash模式
使用 URL 的 hash 来模拟一个完整的 URL,于是当 URL 改变时,页面不会重新加载。
- 优点:兼容性好,不需要服务端或者网关额外配置
- 缺点:链接上带 # 号——丑,锚点功能无法使用
History模式
- 优点:解决了 hash 模式的所有缺点;
- 缺点:路由功能由前端实现,需要网关或者服务端配置支持;
本质上是因为路由功能由前端实现,服务器或者网管上本质上只有
index.html页面并没有路由链接的静态文件路由;
所以呢,要在服务端增加一个覆盖所有情况的候选资源:如果 URL 匹配不到任何静态资源,则应该返回同一个 index.html 页面,这个页面就是 app 依赖的页面。
使用Nginx来解决
try_files指令
语法:try_files file ... uri 或 try_files file ... = code
作用是按顺序检查文件是否存在,返回第一个找到的文件或文件夹(结尾加斜杠/的表示文件夹),若所有的文件或文件夹都找不到,会进行一个内部重定向到最后一个参数。
location / {
index index.html index.htm;
# 网站主页路径 一般设置放置index.html文件所在目录即可
root /var/www/html;
try_files $uri $uri/ /index.html;
}
以目录去区分多个history单文件
因为不可能每一个项目开启一个域名,仅仅指向通过增加路径来划分多个网站,比如:
www.taobao.com/tmall/login访问天猫的登录页面www.taobao.com/alipay/login访问支付宝的登录页面
server {
listen 80;
server_name taobao.com;
index index.html index.htm;
# 通过正则来匹配捕获 [tmall|alipay]中间的这个路径
location ~ ^/([^/]+)/(.*)$ {
try_files $uri $uri/ /$1/dist/index.html =404;
}
}
跨域问题解决
受限于浏览器的同源策略,跨域请求(域名、端口、协议)会被浏览器单方面的阻止,一般可以通过CORS配置或者反向代理来进行跨域限制的解除;
配置跨域头部(CORS)
跨源资源共享(CORS,或通俗地译为跨域资源共享)是一种基于 HTTP 头的机制,该机制通过允许服务器标示除了它自己以外的其他源(域、协议或端口),使得浏览器允许这些源访问加载自己的资源。
在 nginx 中我们通过add_header添加对应的跨域头部即可
location ^~ /api/ {
# 跨域处理 设置头部域名
add_header Access-Control-Allow-Origin *;
# 跨域处理 设置头部方法
add_header Access-Control-Allow-Methods 'GET,POST,DELETE,OPTIONS,HEAD';
}
反向代理
反向代理的流程是客户端向代理服务器发送请求,但不需要客户端指定目标服务器,代理服务器根据规则进行客户端的请求转发,获取内容并返回给客户端;反向代理隐藏了真实的服务器,为服务器收发请求,使真实的服务器对客户端不可见。一般在处理跨域请求的时候比较常用。
# 接口反向代理
location ^~ /api/ {
proxy_pass http://www.test-website.com/;
proxy_set_header Host $http_host;
}
# http://www.test.com/api/b.js => http://www.test-website.com/b.js
proxy_pass的坑
-
如果
proxy_pass只是设置域名的话,表示为相对路径。那么 location 匹配的路径就不会删除; -
如果
proxy_pass域名后面带上任意路径的话,那么表示为绝对路径; location上匹配的路径都会被删除; -
当
location使用正则时,proxy_pass只能与域名的形式结束;
proxy_pass为域名
proxy_pass只设置域名的话可以认为是指替换域名,任然保留路径
location ^~ /api/ {
proxy_pass http://www.test-website.com;
}
# http://www.test.com/api/b.js => http://www.test-website.com/api/b.js
location ^~ /api {
proxy_pass http://www.test-website.com;
}
# http://www.test.com/api/b.js => http://www.test-website.com/api/b.js
proxy_pass为路径
proxy_pass如果为路径的话那么就要十分注意了,以下是几个例子:
# --------- /api/ ----------------
location ^~ /api/ {
# 绝对路径 location匹配路径会被删除
proxy_pass http://www.test-website.com/test;
}
# http://www.test.com/api/b.js => http://www.test-website.com/testb.js
location ^~ /api/ {
# 跟上面的区别在这 多加了个斜杠
proxy_pass http://www.test-website.com/test/;
}
# http://www.test.com/api/b.js => http://www.test-website.com/test/b.js
# --------- /api ----------------
location ^~ /api {
proxy_pass http://www.test-website.com/test;
}
# http://www.test.com/api/b.js => http://www.test-website.com/test/b.js
# 跟上面的区别在于这里多加了个斜杠
location ^~ /api {
proxy_pass http://www.test-website.com/test/;
}
# http://www.test.com/api/b.js => http://www.test-website.com/test//b.js
如果proxy_pass作为路径来转发的话,那么要注意 proxy_pass 以及 location 要么统一加 / 要么统一不加
做转发的时候一般推荐
proxy_pass以及location都添加 / 来作为结尾
当 proxy_pass 遇到正则
当 location使用正则时,proxy_pass只能与域名的形式结束; 这时候项修改路径的话可以通过 rewrite来实现
# 接口反向代理
location ~* ^/api/ {
# 改写路径
rewrite ^/api/(.*)$ /$1 break;
# 反向代理
proxy_pass http://www.test-website.com;
}
# http://www.test.com/api/b.js => http://www.test-website.com/b.js
如果不希望使用 rewrite的话也可以换成这样子
动静分离 + 缓存
一般来说,大型应用都需要进行动静分离,由于Nginx的高并发及静态资源缓存等特性,经常将静态资源部署在Nginx上。如果请求的是静态资源,直接到静态资源目录获取资源,如果是动态资源请求,则利用反向代理,把请求转发给对应服务器进行处理,从而实现动静分离。
# html文件
location / {
index index.html index.htm;
proxy_set_header Host $host;
# 设置 history模式
try_files $uri $uri/ /index.html;
# index.html文件不可以设置强缓存 设置协商缓存即可
add_header Cache-Control 'no-cache, must-revalidate, proxy-revalidate, max-age=0';
}
# 接口反向代理到对应的服务端
location ^~ /api/ {
# 改写路径
rewrite ^/api/(.*)$ /$1 break;
# 反向代理
proxy_pass http://static_env;
proxy_set_header Host $http_host;
}
# 静态资源设置七天强缓存
location ~* .(?:css(.map)?|js(.map)?|gif|svg|jfif|ico|cur|heic|webp|tiff?|mp3|m4a|aac|ogg|midi?|wav|mp4|mov|webm|mpe?g|avi|ogv|flv|wmv)$ {
# expires 表示 设置7天强缓存
expires 7d;
access_log off;
}
负载均衡
负载均衡是高可用网络基础架构的关键组件,通常用于将工作负载分布到多个服务器来提高网站、应用、数据库或其他服务的性能和可靠性。
在Nginx中主要基于upstream做负载均衡,中间会涉及一些相关的策略比如ip_hash、weight
http {
upstream backserver{
# 哈希算法,自动定位到该服务器 保证唯一ip定位到同一部机器 用于解决session登录态的问题
ip_hash;
server 127.0.0.1:9090 down; (down 表示单前的server暂时不参与负载)
server 127.0.0.1:8080 weight=2; (weight 默认为1.weight越大,负载的权重就越大)
server 127.0.0.1:6060;
server 127.0.0.1:7070 backup; (其它所有的非backup机器down或者忙的时候,请求backup机器)
}
location ^~ /api/ {
rewrite ^/api/(.*)$ /$1 break;
proxy_pass http://backserver;
}
}
Nginx默认提供了三种负载分配方式,默认为轮询。常用有以下几种分配方式:
- 轮询(默认):每个请求按时间顺序逐一分配到不同的后端服务器;
- weight:指定轮询几率,weight和访问比率成正比,用于后端服务器性能不均的情况。
- ip_hash:每个请求按访问ip的hash结果分配,这样每个访客固定访问一个后端服务器,可以解决session的问题。
简易的灰度部署
灰度发布的核心其实就是通过对Nginx 文件的修改实现流量的定向分发,通过Nginx我们可以实现一个简单的灰度部署——通过头部 headers 中的 cookie 来进行环境区分;
nginx中可以通过
$http_xxx来获取headers头部的变量值
# 线上稳定环境
upstream stable {
server xxx max_fails=1 fail_timeout=60;
server xxx max_fails=1 fail_timeout=60;
}
# 灰度测试环境
upstream canary {
server xxx max_fails=1 fail_timeout=60;
}
server {
listen 80;
server_name xxx;
# 设置变量 默认为 默认环境
set $group "stable";
# 根据cookie头部设置接入的服务
if ($http_cookie ~* "tts_version_id=canary"){
set $group canary;
}
if ($http_cookie ~* "tts_version_id=stable"){
set $group stable;
}
location / {
index index.html index.htm;
}
# 根据不同的环境切分api流量入口
location ^~ /api/ {
rewrite ^/api/(.*)$ /$1 break;
proxy_pass http://$group;
}
}
优雅降级
SSR服务端渲染由于是依赖服务器资源,在流量过大的情况下,有可能会出现服务不可用的情况,返回特殊的错误码例如500等。这时候我们可以实现优雅降级,利用 nginx 做对应的流量分发,当SSR页面返回异常错误的时候,nginx会将流量导入到CSR页面当中。
优雅降级需要proxy_intercept_errors来开启自定义错误捕获功能,用error_page指令来手动进行降级指向备用地址。
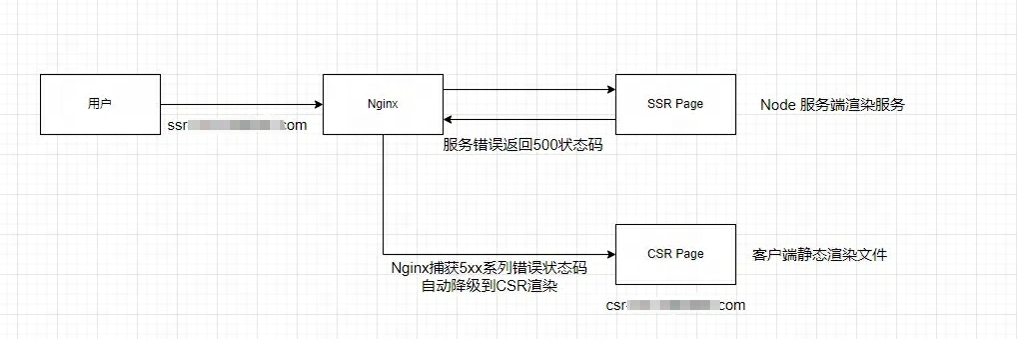
upstream ssrserver {
server xxx max_fails=1 fail_timeout=60;
server xxx max_fails=1 fail_timeout=60;
}
# 服务端渲染
server {
listen 80;
server_name ssr-website.com.com;
location / {
proxy_pass http://ssrserver;
# 开启自定义错误捕获 如果这里不设置为on的话 会走向nginx处理的默认错误页面
proxy_intercept_errors on;
# 捕获500系列错误 如果500错误的话降级为下面的csr渲染
error_page 500 501 502 503 504 = @csr_location
# error_page 500 501 502 503 504 = 200 @csr_location
# 注意这上面的区别 等号前面没有200 表示 最终返回的状态码已 @csr_location为准 加了200的话表示不管@csr_location返回啥都返回200状态码
}
location @csr_location {
proxy_pass http://csr-website.com.com;
rewrite_log on;
}
}
# 客户端渲染
server {
listen 80;
server_name csr-website.com.com;
location / {
index index.html index.htm;
}
}
webp根据浏览器自动降级为png
这套方案不像常见的由nginx把png转为webp的方案,而是先经由图床系统(node服务)上传两份图片:
- 一份是原图png
- 一份是png压缩为webp的图片(使用的是imagemin-webp)
然后通过nginx检测头部是否支持webp来返回webp图片,不支持的话就返回原图即可。这其中还做了错误拦截,如果cos桶丢失webp图片及时浏览器支持webp也要降级为png
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
# 设置日志格式
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"'
'"$proxy_host" "$upstream_addr"';
access_log /var/log/nginx/access.log main;
sendfile on;
keepalive_timeout 65;
# 开启gzip
gzip on;
gzip_vary on;
gzip_proxied any;
gzip_comp_level 6;
gzip_types text/plain text/css text/xml application/json application/javascript application/rss+xml application/atom+xml image/svg+xml;
# 负载均衡 这里可以是多个cos桶地址即可
upstream static_env {
server xxx;
server xxx;
}
# map 设置变量映射 第一个变量指的是要通过映射的key值 Accpet 第二个值的是变量别名
map $http_accept $webp_suffix {
# 默认为 空字符串
default "";
# 正则匹配如果Accep含有webp字段 设置为.webp值
"~*webp" ".webp";
}
server {
listen 8888;
absolute_redirect off; #取消绝对路径的重定向
#网站主页路径。此路径仅供参考,具体请您按照实际目录操作。
root /usr/share/nginx/html;
location / {
index index.html index.htm;
proxy_set_header Host $host;
try_files $uri $uri/ /index.html;
add_header Cache-Control 'no-cache, max-age=0';
}
# favicon.ico
location = /favicon.ico {
log_not_found off;
access_log off;
}
# robots.txt
location = /robots.txt {
log_not_found off;
access_log off;
}
#
location ~* .(png|jpe?g)$ {
# Pass WebP support header to backend
# 如果header头部中支持webp
if ($webp_suffix ~* webp) {
# 先尝试找是否有webp格式图片
rewrite ^/(.*).(png|jpe?g)$ /$1.webp break;
# 找不到的话 这里捕获404错误 返回原始错误 注意这里的=号 代表最终返回的是@static_img的状态吗
error_page 404 = @static_img;
}
proxy_intercept_errors on;
add_header Vary Accept;
proxy_pass http://static_env;
proxy_set_header Host $http_host;
expires 7d;
access_log off;
}
location @static_img {
#set $complete $schema $server_addr $request_uri;
rewrite ^/.+$ $request_uri break;
proxy_pass http://static_env;
proxy_set_header Host $http_host;
expires 7d;
}
# assets, media
location ~* .(?:css(.map)?|js(.map)?|gif|svg|jfif|ico|cur|heic|webp|tiff?|mp3|m4a|aac|ogg|midi?|wav|mp4|mov|webm|mpe?g|avi|ogv|flv|wmv)$ {
proxy_pass http://static_env;
proxy_set_header Host $http_host;
expires 7d;
access_log off;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root /usr/share/nginx/html;
}
}
}
一些额外的使用场景
请求过滤
# 非指定请求全返回 403
if ( $request_method !~ ^(GET|POST|HEAD)$ ) {
return 403;
}
location / {
# IP访问限制(只允许IP是 172.168.1.1 机器访问)
allow 172.168.1.1;
deny all;
root html;
index index.html index.htm;
}
图片防盗链
server {
listen 80;
server_name *.sherlocked93.club;
# 图片防盗链
location ~* .(gif|jpg|jpeg|png|bmp|swf)$ {
valid_referers none blocked 172.168.1.1; # 只允许本机 IP 外链引用
if ($invalid_referer){
return 403;
}
}
}
开启gzip压缩
gzip压缩是一种常用的网页压缩技术,传输的网页经过gzip压缩之后大小通常可以缩减到原来的一般甚至更小,更小的网页体积意味着带宽的节约与传输速度的提升,特别是对于访问量巨大的大型应用来说,每个静态资源体积的缩小,都会带来相当可观的流量与带宽节省
http {
# 开启gzip
gzip on;
# 增加响应头”Vary: Accept-Encoding” 用来给浏览器识别
gzip_vary on;
# Nginx做为反向代理的时候启用: any – 无条件压缩所有结果数据
gzip_proxied any;
# 压缩等级
gzip_comp_level 6;
# 需要压缩的资源
gzip_types text/plain text/css text/xml application/json application/javascript application/rss+xml application/atom+xml image/svg+xml;
}
总结
上面讲解了几种nginx常用于解决的场景问题,本次分享的内容更多的局限于单机情况下的 nginx 能够解决的问题场景;那么大家回想一下使用nginx进行负载均衡时,nginx机器挂掉了怎么办?
在一些大型项目中对于这种需要用到多节点高可用的情况更多的是通过 集群 的方式来解决高可用的问题,业内常用的就是我们常听到的 Kubernetes(k8s)。k8s中默认的网关层 ingress 就是使用 nginx 来搭建的。
当然k8s的搭建一般跟运维相关,所以不用过多的深入了解。
