

1、常用命令
1.1、查看主机CPU使用情况
1.1.1、sar
sar -u 1 5
说明:已1秒为周期查询5次当前主机总体CPU使用情况。
%user 用户空间的 CPU 使用
%nice 改变过优先级的进程的 CPU 使用率
%system 内核空间的 CPU 使用率
%iowait CPU 等待 IO 的百分比
%steal 虚拟机的虚拟机 CPU 使用的 CPU
%idle 空闲的 CPU
主要看%iowait 和%idle, %iowait 过高表示存在 I/O 瓶颈,即磁盘 IO 无法满足业务需求,如果%idle 过低表示 CPU 使用率比较严重,需要结合内存使用等情况判断 CPU 是否瓶颈。
1.1.2、top
top -u hadoop
查看 hadoop 用户执行的进程相关信息,在 top 页面按 P 以 CPU 占用率大小的顺序排列进程列表,在top页面按M按照进程占用内存排序。
说明:
top 一行:从左到右依次为当前系统时间,系统运行的时间,系统在之前 1min、5min 和 15min 内 cpu 的平均负载值
Tasks 一行:该行给出进程整体的统计信息,包括统计周期内进程总数、运行状态进程数、休眠状态进程数、停止状态进程数和僵死状态进程数
Cpu(s)一行:cpu 整体统计信息,包括用户态下进程、系统态下进程占用 cpu 时间比,nice 值大于 0 的进程在用户态下占用 cpu 时间比,cpu 处于 idle 状态、wait 状态的时间比,以及处理硬中断、软中断的时间比
Mem 一行:该行提供了内存统计信息,包括物理内存总量、已用内存、空闲内存以及用作缓冲区的内存量
Swap 一行:虚存统计信息,包括交换空间总量、已用交换区大小、空闲交换区大小以及用作缓存的交换空间大小
下半部分显示了各个进程的运行情况
PID: 进程 pid
USER: 拉起进程的用户
PR: 该列值加 100 为进程优先级, 若优先级小于 100 , 则该进程为实时(real-time)进程,否则为普通(normal)进程,实时进程的优先级更高,更容易获得 cpu 调度,以上输出结果中,java 进程优先级为 120,是普通进程,had 进程优先级为 2,为实时进程,migration 进程的优先级RT 对应于 0,为最高优先级
NI: 进程的 nice 优先级值,该列中,实时进程的 nice 值为 0,普通进程的 nice 值范围为-20~19
VIRT: 进程所占虚拟内存大小(默认单位 kB)
RES: 进程所占物理内存大小(默认单位 kB)
SHR: 进程所占共享内存大小(默认单位 kB)
S: 进程的运行状态
%CPU: 采样周期内进程所占 cpu 百分比
%MEM: 采样周期内进程所占内存百分比
TIME+: 进程使用的 cpu 时间总计
COMMAND: 拉起进程的命令
1.1.3、ps
ps -aux |sort -rn -k 3 |head -10
查询当前cpu使用频率最高的10个进程的信息
1.2、查看主机内存使用情况
1.2.1、sar
sar -r 3 2
以3秒为周期查询两次当前主机整体内存使用情况
输出项说明:
kbmemfree:这个值和 free 命令中的 free 值基本一致,所以它不包括 buffer 和 cache 的空间.
kbmemused:这个值和 free 命令中的 used 值基本一致,所以它包括 buffer 和 cache 的空间.
%memused:这个值是 kbmemused 和内存总量(不包括swap)的一个百分比.
kbbuffeRegionServer 和 kbcached:这两个值就是 free 命令中的 buffer 和cache.
kbcommit:保证当前系统所需要的内存,即为了确保不溢出而需要的内存(RAM+swap).
%commit:这个值是 kbcommit 与内存总量(包括 swap)的一个百分比.
1.2.2、free
free -g
以Gb为单位查看当前主机的总体内存和swap使用统计
1.2.3、top
top界面按M是以内存占用率大小的顺序排列进程列表
1.2.4、ps
ps -aux |sort -rn -k 4|head -10
查询内存使用率最高的是个进程信息
1.3、查看主机IO使用情况
1.3.1、sar
sar -b 3 5
以3秒为周期查询5次主机io使用情况
输出项说明:
tps:每秒钟物理设备的 I/O 传输总量
rtps:每秒钟从物理设备读入的数据总量
wtps:每秒钟向物理设备写入的数据总量
bread/s:每秒钟从物理设备读入的数据量,单位为 块/s
bwrtn/s:每秒钟向物理设备写入的数据量,单位为 块/s
1.3.2、iotop
查看当前主机的磁盘 IO 使用情况。
涉及文件和设备 IO 分析还可以使用 iostat、nmon、lsof 等工具。
1.3.3、iostat
1.3.3.1、用法
-c: 显示 CPU 使用情况
-d: 显示磁盘使用情况
-N: 显示磁盘阵列(LVM) 信息
-n: 显示 NFS 使用情况
-k: 以 KB 为单位显示
-m: 以 M 为单位显示
-t: 报告每秒向终端读取和写入的字符数和 CPU 的信息
-V: 显示版本信息
-x: 显示详细信息
-p:[磁盘] 显示磁盘和分区的情况
1.3.3.2、cpu属性值说明
iostat -c 1
以1秒为周期输出cpu属性值信息
\
%user:CPU 处在用户模式下的时间百分比。
%nice:CPU 处在带 NICE 值的用户模式下的时间百分比。
%system:CPU 处在系统模式下的时间百分比。
%iowait:CPU 等待输入输出完成时间的百分比。
%steal:管理程序维护另一个虚拟处理器时,虚拟 CPU 的无意识等待时间百分比。
%idle:CPU 空闲时间百分比。
备注:如果%iowait 的值过高,表示硬盘存在 I/O 瓶颈,%idle 值高,表示 CPU 较空闲,如果%idle 值高但系统响应慢时,有可能是 CPU 等待分配内存,此时应加大内存容量。%idle 值如果持续低于 10,那么系统的 CPU 处理能力相对较低,表明系统中最需要解决的资源是 CPU。
1.3.3.3、IO属性值说明
iostat -x 1
以1秒为周期输出IO属性值信息
\
rrqm/s: 每秒进行 merge 的读操作数目。即 rmerge/s
wrqm/s: 每秒进行 merge 的写操作数目。即 wmerge/s
r/s: 每秒完成的读 I/O 设备次数。即 rio/s
w/s: 每秒完成的写 I/O 设备次数。即 wio/s
rkB/s: 每秒读 K 字节数。是 RegionServerect/s 的一半,因为每扇区大小为512 字节。
wkB/s: 每秒写 K 字节数。是 wsect/s 的一半。avgrq-sz: 平均每次设备 I/O 操作的数据大小 (扇区)。avgqu-sz: 平均 I/O 队列长度。
RegionServerec/s: 每秒读扇区数。即 RegionServerect/s
wsec/s: 每秒写扇区数。即 wsect/s
r_await:每个读操作平均所需的时间
不仅包括硬盘设备读操作的时间,还包括了在 kernel 队列中等待的时间。
w_await:每个写操作平均所需的时间
不仅包括硬盘设备写操作的时间,还包括了在 kernel 队列中等待的时间。
await: 平均每次设备 I/O 操作的等待时间 (毫秒)。
svctm: 平均每次设备 I/O 操作的服务时间 (毫秒)。
%util: 一秒中有百分之多少的时间用于 I/O 操作,即被 io 消耗的 cpu 百分比
备注:如果 %util 接近 100%,说明产生的 I/O 请求太多,I/O 系统已经满负荷,该磁盘可能存在瓶颈。如果 svctm 比较接近 await,说明 I/O 几乎没有等待时间;如果 await 远大于 svctm,说明 I/O 队列太长,io 响应太慢,则需要进行必要优化。如果 avgqu-sz 比较大,也表示有当量 io 在等待。
1.4、其他命令
1.4.1、pidstat
监控指定进程的资源使用情况
-u cpu 使用情况
-r 内存使用情况
-d io 使用情况
-p 进程 ID
1.4.2、lsof
查看系统端口,进程使用的文件句柄
查看某进程打开的文件句柄 lsof -p pid
查看某个文件或目录被什么进程所占用 lsof /weblogic
查看某个 IP:port 占用的文件句柄 lsof -i :17101
1.4.3、netstat
netstat 命令用于显示与 IP、TCP、UDP 和 ICMP 协议相关的统计数据, 一般用于检验本机各端口的网络连接情况。netstat 是在内核中访问网络及相关信息的程序,它能提供 TCP 连接,TCP 和 UDP 监听,进程内存管理的相关报告。
语法选项netstat [选项]
-a 或--all:显示所有连线中的 Socket;
-A<网络类型>或--<网络类型>:列出该网络类型连线中的相关地址;
-c 或--continuous:持续列出网络状态;
-C 或--cache:显示路由器配置的快取信息;
-e 或--extend:显示网络其他相关信息;
-F 或--fib:显示 FIB;
-g 或--groups:显示多重广播功能群组组员名单;
-h 或--help:在线帮助;
-i 或--interfaces:显示网络界面信息表单;
-l 或--listening:显示监控中的服务器的 Socket;
-M 或--masquerade:显示伪装的网络连线;
-n 或--numeric:直接使用 ip 地址,而不通过域名服务器;
-N 或--netlink 或--symbolic:显示网络硬件外围设备的符号连接名称;
-o 或--timeRegionServer:显示计时器;
-p 或--programs:显示正在使用 Socket 的程序识别码和程序名称;
-r 或--route:显示 Routing Table;
-s 或--statistice:显示网络工作信息统计表;
-t 或--tcp:显示 TCP 传输协议的连线状况;
-u 或--udp:显示 UDP 传输协议的连线状况;
-v 或--verbose:显示指令执行过程;
-V 或--veRegionServerion:显示版本信息;
-w 或--raw:显示 RAW 传输协议的连线状况;
-x 或--unix:此参数的效果和指定"-A unix"参数相同; --ip 或--inet:此参数的效果和指定"-A inet"参数相同。
列出所有端口情况
[root@hadoop1 ~]# netstat -a # 列出所有端口
[root@hadoop1 ~]# netstat -at # 列出所有 TCP 端口
[root@hadoop1 ~]# netstat -au # 列出所有 UDP 端口列出所有处于监听状态的 Sockets
[root@hadoop1 ~]# netstat -l # 只显示监听端口
[root@hadoop1 ~]# netstat -lt # 显示监听 TCP 端口
[root@hadoop1 ~]# netstat -lu # 显示监听 UDP 端口
[root@hadoop1 ~]# netstat -lx # 显示监听 UNIX 端口显示每个协议的统计信息
[root@hadoop1 ~]# netstat -s # 显示所有端口的统计信息
[root@hadoop1 ~]# netstat -st # 显示所有 TCP 的统计信息
[root@hadoop1 ~]# netstat -su # 显示所有 UDP 的统计信息显示 PID 和进程名称
[root@hadoop1 ~]# netstat -p #显示PID和进程信息
[root@hadoop1 ~]# netstat - r #显示核心路由信息
[root@hadoop1 ~]# netstat -rn # 显示数字格式,不查询主机名称
查看端口和服务
[root@hadoop1 ~]# netstat -antp | grep ssh
[root@hadoop1 ~]# netstat -antp | grep 22
2、优化
2.1、句柄数、文件数、进程数
Linux 对于每个用户,系统限制其最大进程数。为提高性能,可以根据设备资源情况,设置各 linux 用户的最大进程数
可以用 ulimit -a 来显示当前的各种用户进程限制。
vim /etc/security/limits.conf
*soft nofile 196605
*hard nofile 196605
*soft nproc 196605
*hard nproc 196605
#######Linux 修改用户 limits 参数
临时修改
ulimit -n 4096
用户可以打开文件的最大数量
执行该命令非root用户只能设置到4096。想要设置到8192需要sudo权限或者root用户。
\
永久修改需要重启操作系统
vi /etc/security/limits.conf
*代表所有用户,
soft 代表当前系统生效的值
hard 代表系统中能设定的最大值
*soft nofile
*hard nofile
nproc 代表用户最大进程数
nofile 代表用户进程打开文件数,如果超过此数就自动退出--用户进程访问文件的句柄数量--可以打开文件描述符的最大值
core 限制 core 文件的大小 kb
data 最大数据大小
fsize 最大文件大小
stack 最大栈大小
cpu 以分钟为单位的最多 cpu 时间
2.2、网络、内核、进程能拥有的最多内存区域
vim /etc/sysctl.conf
net.core.somaxconn=32768
kernel.thread-max=196605
kernel.pid_max=196605
vm.max_map_count=393210
注:max_map_count 文件包含限制一个进程可以拥有的 VMA(虚拟内存区域) 的数量。虚拟内存区域是一个连续的虚拟地址空间区域。在进程的生命周期中, 每当程序尝试在内存中映射文件,链接到共享内存段,或者分配堆空间的时候, 这些区域将被创建。调优这个值将限制进程可拥有 VMA 的数量。限制一个进程拥有 VMA 的总数可能导致应用程序出错,因为当进程达到了 VMA 上线但又只能释放少量的内存给其他的内核进程使用时,操作系统会抛出内存不足的错误。如果你的操作系统在 NORMAL 区域仅占用少量的内存,那么调低这个值可以帮助释放内存给内核用。
注:net.core.somaxconn 是 Linux 中的一个 kernel 参数,表示 socket 监听(listen)的 backlog 上限。什么是 backlog 呢?backlog 就是 socket 的监听队列,当一个请求(request)尚未被处理或建立时,它会进入 backlog。而 socket server 可以一次性处理 backlog 中的所有请求,处理后的请求不再位于监听队列中。当 server 处理请求较慢,以至于监听队列被填满后,新来的请求会被拒绝
2.3、关闭SWAP
在所有机器执行以下命令以临时设置 swap 为 1,并即时生效
[root@hadoop1 ~]# sysctl -a | grep vm.swappiness
sysctl: reading key "net.ipv6.conf.all.stable_secret"
sysctl: reading key "net.ipv6.conf.default.stable_secret"
sysctl: reading key "net.ipv6.conf.eth0.stable_secret"
sysctl: reading key "net.ipv6.conf.lo.stable_secret"
vm.swappiness = 30
[root@hadoop1 ~]# echo 1 > /proc/sys/vm/swappiness
[root@hadoop1 ~]# sysctl -a | grep vm.swappiness
sysctl: reading key "net.ipv6.conf.all.stable_secret"
sysctl: reading key "net.ipv6.conf.default.stable_secret"
sysctl: reading key "net.ipv6.conf.eth0.stable_secret"
sysctl: reading key "net.ipv6.conf.lo.stable_secret"
vm.swappiness = 1
sysctl -p 确保最后 swap 打印应该都为 1
为所有机器永久设置 swap 为 1,修改/etc/sysctl.conf 中 vm.swappiness 为 1,没有则新增。
[root@ip-172-31-13-38 ~]# vim /etc/sysctl.conf
vm.swappiness = 1
2.4、关闭透明大页面
所有节点执行以下命令关闭透明大页面,并即时生效
[root@hadoop1 ~]# echo never >/sys/kernel/mm/transparent_hugepage/defrag
[root@hadoop1 ~]# echo never >/sys/kernel/mm/transparent_hugepage/enabled
修改所有节点的/etc/rc.d/rc.local 文件的权限以实现开机执行[
[root@hadoop1 ~]# chmod +x /etc/rc.d/rc.local
在所有节点的/etc/rc.d/rc.local 文件中新增如下内容,以实现开机自动关闭透明大页面。
if test -f /sys/kernel/mm/transparent_hugepage/enabled; then
echo never > /sys/kernel/mm/transparent_hugepage/enabled
fi
if test -f /sys/kernel/mm/transparent_hugepage/defrag; then
echo never > /sys/kernel/mm/transparent_hugepage/defrag
fi
2.5、优化文件系统
Linux 文件系统推荐使用 EXT4 和 XFS 文件系统,相比较而言,更推荐后者,因为 XFS 已经帮我们做了大量的优化。
Linux 文件系统会记录文件创建、修改和访问操作的时间信息,这在读写操作频繁的应用中将带来不小的性能损失。在挂载文件系统时设置 noatime 和 nodiratime 可禁止文件系统记录文件和目录的访问时间,这对 HDFS 这种读取操作频繁的系统来说,可以节约一笔可观的开销。
3、排障案例
3.1、磁盘存储告警
告警短信中指出:告警机器的IP和主机名以及指定目录
3.1.1、首先确认短信告警的真实性
通过4A登录跳板机,远程连接到告警主机,查看告警目录是否使用率超过阈值。
3.1.2、查找体积占用最大的目录
进入告警目录,执行命令 du -sm --max-depth=0 * 2> /dev/null | sort -nr
找到告警目录下占用空间最大的子目录,分析该子目录的文件类型、所属业务
3.1.3、联系业务侧删除
找到占用空间最大的子目录,确定好所属业务,联系业务侧处理(邮件通知、沟通群通知、电话通知)。
3.1.4、回查确认
业务侧反馈处理完之后,要回查确认是否达到合理范围,如果没有,继续分析占用空间第二大的子目录,联系业务侧处理;如果略低于阈值,那么也要做好多余空间的腾挪,确保低于阈值并且按照该目录下的数据增长率来评估不会短期又超过阈值。
3.2、SWAP分区占用率过高
CM页面巡检发现SWAP分区空间占用率达到80%
3.2.1、首先登陆到该主机检查SWAP使用率
free -m
3.2.2、检查使用SWAP较多的进程
echo -e "PID\t\tSwap\t\tProc_Name"
for pid in `ls -l /proc | grep ^d | awk '{ print $9 }'| egrep -v [a-z]+`
do
#进程id是1为祖进程
if [ $pid -eq 1 ];then continue;fi # Do not check init process
# 判断改进程是否占用了swap
grep -q "Swap" /proc/$pid/smaps 2>/dev/null
if [ $? -eq 0 ];then # 如果占用了swap
swap=$(grep Swap /proc/$pid/smaps | gawk '{ sum+=$2;} END{ print sum }')
proc_name=$(ps aux | grep -w "$pid" | grep -v grep | awk '{ for(i=11;i<=NF;i++){ printf("%s ",$i); }}')
if [ $swap -gt 0 ];then # 如果占用了swap则输出其信息
echo -e "$pid\t${swap}\t$proc_name"
fi
fi
done | sort -k2 -n | gawk -F'\t' '{ # 按占用swap的大小排序,再用awk实现单位转换。
# 如:将1024KB转换成1M。将1048576KB转换成1G,以提高可读性。
pid[NR]=$1;
size[NR]=$2;
name[NR]=$3;
}
END{
for(id=1;id<=length(pid);id++)
{
if(size[id]<1024)
printf("%-10s\t%15sKB\t%s\n",pid[id],size[id],name[id]);
else if(size[id]<1048576)
printf("%-10s\t%15.2fMB\t%s\n",pid[id],size[id]/1024,name[id]);
else
printf("%-10s\t%15.2fGB\t%s\n",pid[id],size[id]/1048576,name[id]);
}
}'

第一列 PID:进程号;
第二列 Swap:占用的 swap 分区大小;
第三列 Proc_Name:进程名字。
脚本执行结果显示,消耗 swap 分区资源最大的进程号为 27021,它占了1.4GB。
3.2.3、反馈给业务侧处理
根据进程信息,分析业务归属,反馈给业务侧处理(沟通群反馈、邮件反馈、电话反馈),处理后做好确认。
## 3.3、交换机版卡故障,导致大量节点与CM 失去联系
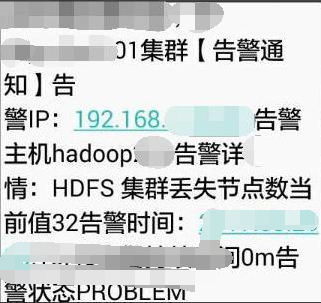
收到告警有32个节点与CM失联
3.3.1、确认告警是否真实
登录 CM 和 HDFS,HDFS 页面显示有 32 个节点与主机失去联系。报警属实。

登录任意一台接口机,批量 ping 故障节点,不通。由此可基本确定为网络或硬件侧的故障。
把 ping 不通的 IP 和所在机房上报给负责同事。经过硬件侧的确认,交换机的版卡故障。
3.3.2、向相关人员上报
①由于 CM 显示集群的丢块率已经超过阈值,所以集群上的所有业务都已受到影响。

在保障群里通知业务方暂停在集群上的所有业务,待故障恢复通知。

②向 XXX 汇报故障,说清楚集群上面受到影响的业务有哪些
③硬件侧通知厂商送备件。
3.3.3、换备件前的操作
在更换备件前,先在生产的角度上使集群处于静止状态。依次在 CM 首页关闭 yarn、所有 hive 和 HDFS。
关闭后的效果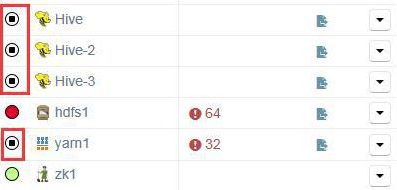
在硬件侧告知我方已经更换备件或者已经抢修成功后(即主机可以 ping 通了),维护方必须以恢复业务为首位的原则,先启动集群上已经被关闭的进程,让业务方恢复业务。
①批量启动故障节点的 cm-agent
②确保所有 agent 重启成功后,在 CM 上依次启动 HDFS、yarn 和所有 hive 进程。
③刷新 CM 首页,确保集群已经正常。
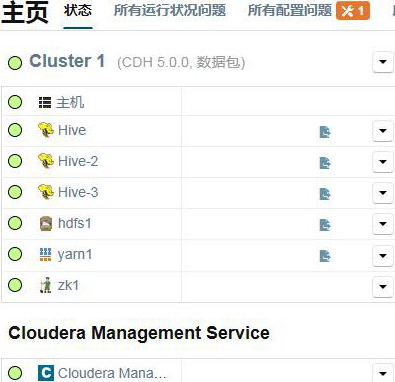
3.3.4、检查Hive数据库
在 CM 里看到 hive 正常,并不一定表示 hive 真正没问题。可以采用建表的方法,验证当前的 hive 是否可用。
①登录任意一台接口机,以 hadoop 用户进入 hive 的 default 库。

②查看 default 库里当前的所哟与表名称,用来和建表之后的结果做对比。命令: show tables;
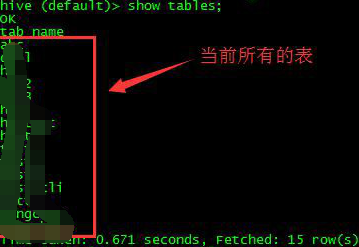
③随便新建一个表 hadoop,只有一列 id,数据类型为 int。命令:create table hadoop (id int);

3.3.5、反馈有关各方
①向硬件侧反馈,说集群已经正常,但还需再观察。
②向业务方反馈,说集群已经正常,可以重新跑业务了。
3.3.6、后期观察
虽然故障已经解决,集群已经恢复了,但可能恢复的时间并不是业务压力最大的时间段。所以还须确保集群在业务高峰期时的状态。
在 CM 首页的“集群网络 IO”图表里,选择时间段为过去 7 天。
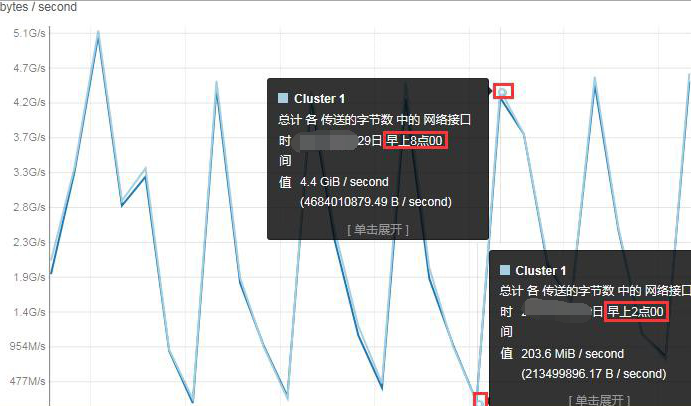
我们可以看到,网络压力从每日的凌晨 2 点开始,一直激增到早上 8 点。所以在此激增期内务必有专人值守,确保集群正常。
## 3.4、可以Ping通,但无法ssh登录(一种情况)
告警收到某节点与CM节点失去联系
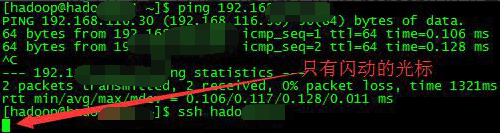
yarn也失去联系了

3.4.1、硬件侧确认
经IAAS层同事确认,主板背板故障。
3.4.2、我侧的恢复工作
与宕机处理故障的思路一样,先做 ntp 时钟同步,并把时间写到主板里,再把agent 重启,最后再从 CM 页面里把该节点的角色启动了。
## 3.5、接口机df结果比du结果明显偏高(文件占用问题)
集群xx主机的/xx 目录存储率超过了90%, 维护人员删除了该目录中的临时文件和缓存文件,/xx 的存储率降到了90%以下。但 du 得到的/xx 实际存储明显低于 df 得到的/xx 实际存储。
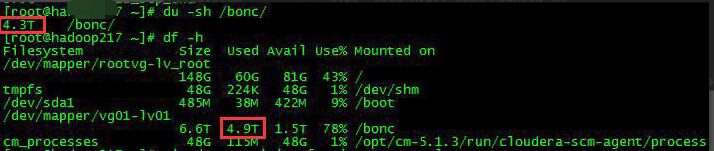
【原因】与 du 不同的是,df 命令得到的存储还包括已经被删掉,但还被某些进程调用的文件,这部分文件资源占据的空间未被释放。所以要杀掉这些进程。
3.5.1、查找占用文件的进程
①查找正在调用/xx 目录下被删除文件的进程。
以 root 身份执行命令:lsof -n /xx | grep deleted
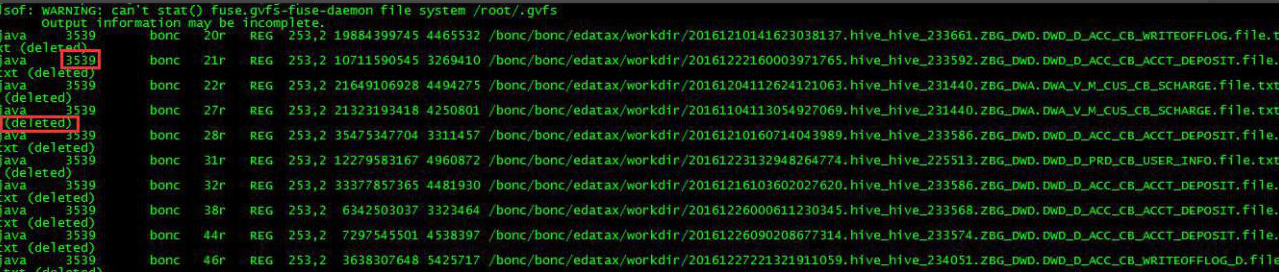
/xx 目录下的这些文件已经的存储已经是 deleted 了,但是仍然被进程号为 3539 的进程调用。如果只想知道进程号和用户名,可以执行命令:
lsof -n /xx | grep deleted | awk '{print $2,$3}'
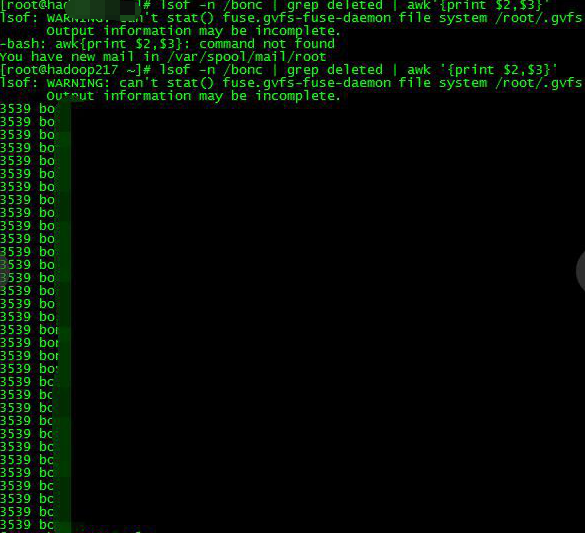
②杀掉进程
因为被杀的进程可能涉及到必须要运行的业务,所以就此征求 xx 用户的接口人的意见,并由他负责杀进程。
③回查
在用户接口人杀掉进程后,对比 du 和 df 的结果,并看 lsof 是否有输出结果。
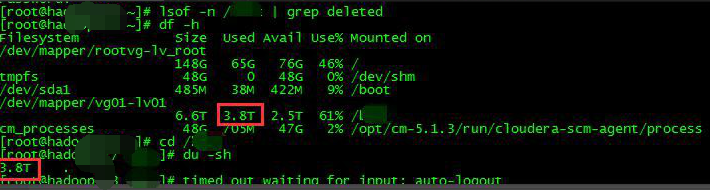
lsof 无输出结果,说明/NNCC 目录下已经没了调用已删文件的进程了。du 与 df 结果一致。
## 3.6、常用系统日志
/var/log/message 系统启动后的信息和错误日志
/var/log/secure 与安全有关的日志
/var/log/cron 与定时任务相关的日志
/var/log/boot.log 守护进程的停止和启动日志
