

祝愿所有码农都能在2022心想事成.
由于synchronized的重量级锁, 需要在用户态和内核态之间切换, 性能非常低下, 而轻量级锁的自旋操作, 是基于cpu指令级的cas操作是在用户态操作, 所以非常高效, jdk中有很多基于cas实现的juc原子类. 对这些原子类的操作都不需要笨重的加锁操作从而非常高效.
什么是CAS
jdk中对操作系统底层的CAS原子操作进行了封装, 为上层java程序提供了CAS操作的API.
在jdk的sun.misc.Unsafe类中提供了一些用于执行低级别, 不安全的底层操作, 例如直接访问内存资源, 自主管理内存, 大量的方法都是native的, 基于C++实现. 不建议在应用中直接使用.
在应用中使用cas操作主要涉及Unsafe方法的调用. 具体:
- 获取unsafe实例.
- 调用unsafe实例的cas方法.
- 调用unsafe实例的字段偏移量方法, 用于获取对象中的字段偏移量, 从而作为参数传递给cas方法.
Unsafe实例获取
Unsafe unsafe = Unsafe.getUnsafe();
三个cas方法
unsafe.compareAndSwapInt();
unsafe.compareAndSwapLong();
unsafe.compareAndSwapObject()
cas方法的四个参数:
- Object o : 字段所属的对象.
- long offset : cas操作的属性的偏移量
- Object excepted : 期望的属性旧值
- Object update : 新的要设置的值.
操作过程就是先比较旧值是否相等, 如果相等就设置新值, 如果不等就不执行操作, 直接返回false.
第一个和第二参数组合起来可以找到最终需要操作的内存地址, 然后直接基于内存地址进行操作.
Unsafe提供的偏移量相关
unsafe.staticFieldOffset();// 静态字段使用
unsafe.objectFieldOffset();// 非静态字段使用
使用CAS进行无锁编程
CAS是一种无锁算法, 该算法关键依赖两个值: 期望值, 新值, 原理就是事实的值和期望值相等, 就设置新值, 否则返回false;
大致实现步骤:
- 获取字段的期望值
- 计算出新值
- 使用cas设置新值, 如果失败重新计算期望值和新值, 一直循环直到成功.
do{
getOldValue();
caculatorNewValue();
} while(!cas(targetObject, long field, oldValue, newValue)
使用无锁编程实现轻量级安全自增
public class CasSafeIncrement {
static class test{
static Unsafe unsafe ;
static long offset=0;
private volatile int sum=0;
static {
try {
Class klass = Unsafe.class;
Field field = klass.getDeclaredField("theUnsafe");
field.setAccessible(true);
unsafe = (Unsafe) field.get(null);
offset = unsafe.objectFieldOffset(test.class.getDeclaredField("sum"));
System.out.println("sum偏移量: " + offset);
} catch (NoSuchFieldException | IllegalAccessException e) {
e.printStackTrace();
}
}
public void multiThreadStart() throws InterruptedException {
ExecutorService executorService = Executors.newFixedThreadPool(10);
CountDownLatch countDownLatch = new CountDownLatch(10);
for (int i = 1; i <= 10; i++) {
executorService.submit(() -> {
cyclePlus();
});
countDownLatch.countDown();
}
countDownLatch.await();
executorService.shutdown();
int i = 0;
while (!executorService.isTerminated()) {
i++;
System.out.println("第: "+i+"次检查线程池是否关闭");
}
System.out.println(sum);
}
public void cyclePlus() {
System.out.println(Thread.currentThread().getName());
for (int i = 1; i <= 10000; i++) {
int oldValue = sum;
int atmp = 0;
do {
oldValue = sum;
if (atmp > 1) {
System.out.println("第: "+(atmp-1)+"重试次数");
}
atmp++;
} while (!unsafeCAS(oldValue, oldValue + 1));
}
}
public boolean unsafeCAS(int oldValue, int newValue) {
return unsafe.compareAndSwapInt(this, offset, oldValue, newValue);
}
public static void main(String[] args) throws InterruptedException {
test test = new test();
test.multiThreadStart();
}
}
}
其中可以看到sum的偏移量是12, 这个12是怎么来的?
因为在test类中, 前面两个静态字段属于Class类, 所以不占位置, 而对象头占用字节数为: markword 64位, classpointer: 32(指针压缩后的结果), 也就是96位, arrayLength占用0字节.
所以sum在test类中的相对偏移量是: 96/8=12.
JUC原子类
原子操作, 意味着一个线程对这种类型的对象操作时, 是无法被其他线程中断的, 即整个操作是原子性的, 没有线程安全性问题.
Atomic原子操作包
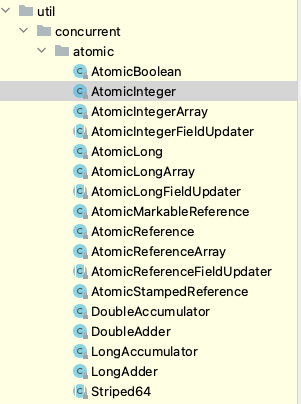
原子类包下的类型可以分为4类: 基础原子类, 数组原子类, 原子引用类, 字段更新原子类.
基本原子类
通过原子的方式更新Java基础类型变量的值, 三个: Integer, Long , Boolean.
数组原子类
通过原子操作更新Java数组中某个元素的值, 三个: IntegerArray, LongArray, ReferenceArray.
引用原子类
原子更新引用类型的变量:
AtomicReference: 原子引用类型
AtomicMarkableReference: 带有更新标记位的原子引用类型, 与boolean标记和引用关联可以解决AtomicBoolean的ABA问题.
AtomicStampedReference: 带有更新版本号的原子引用类型. 解决AtomicInteger的ABA问题.
字段更新原子类
AtomicIntegerFieldUpdater: 原子更新整型字段的更新器.
AtomicLongFieldUpdater: 原子更新长整型字段的更新器
AtomicReferenceFieldUpdater: 原子更新引用类型中的字段.
基础原子类AtomicInteger
常用方法api
get()//获取当前值
getAndSet(int newValue)// 获取当前值然后设置新值.
getAndincrement()//获取当前值, 然后自增
getAndDecrement()//获取当前值, 然后自减
getAndAdd(int delta)//获取当前值, 然后加上预期值.
boolean compareAndSet(int except, int update)// 通过cas设置新值.
多线程累加示例:
public class AtomicIntegerTest {
static AtomicInteger atomicCount = new AtomicInteger(0);
public static void main(String[] args) {
ExecutorService executorService = Executors.newFixedThreadPool(10);
IntStream.rangeClosed(1, 10).forEach(i->executorService.submit(()->{
selfPlus();
}));
executorService.shutdown();
while (!executorService.isTerminated()) {
}
System.out.println(atomicCount.get());
}
public static void selfPlus() {
IntStream.rangeClosed(1, 10000).forEach(i->{
atomicCount.getAndIncrement();
});
}
}
## 稳定输出
100000
非常安全高效
💡 long 和boolean基本类似数组原子类AtomicIntegerArray
以原子的方式更新数组中的某个元素.
常用api
get(int i)
addAndGet(int i, int delta) //获取下标对应值, 并赋值新值.
getAndIncrement(int i)//获取对应下标值并自增.
getAndDecrement(int i)//同上.
getAndAdd(int i, int delta) // 获取值并加上预期值.
compareAndSet(int i, int expectedValue, int newValue)//cas设置新值.
AtomicInteger线程安全原理
所有方法都类似, 以getAndIncrement为例
public final int getAndIncrement() {
return U.getAndAddInt(this, VALUE, 1);// U是unsafe类, this, 当前对象, Value: Atomic原子类包装属性的偏移量, 1: 变化量
}
@HotSpotIntrinsicCandidate
public final int getAndAddInt(Object o, long offset, int delta) {
int v;
do {
v = getIntVolatile(o, offset);// 获取指定偏移量位置的旧值,
} while (!weakCompareAndSetInt(o, offset, v, v + delta));/ v, 即期望旧值.
return v;
}
@HotSpotIntrinsicCandidate
public final boolean weakCompareAndSetInt(Object o, long offset,
int expected,
int x) {
return compareAndSetInt(o, offset, expected, x);//cas方法
}
@HotSpotIntrinsicCandidate
public final native boolean compareAndSetInt(Object o, long offset,
int expected,
int x);//native方法, c++直接基于内存操作的变量值, 操作系统级原子cas操作封装实现.
对象操作的原子性
道理同基本类型, 区别在与操作对象, 对象可以包括多个属性, 这点是基本类型无法做到的. 相当于原子性的一次操作多个基本类型字段.
public static void main(String[] args) {
AtomicReference<User> userAtomicReference = new AtomicReference<>();
}
原子更新对象字段属性, integer
public static void main(String[] args) {
AtomicIntegerFieldUpdater<User> age = AtomicIntegerFieldUpdater.newUpdater(User.class, "age");
User user = new User();
user.setAge(1);
age.getAndIncrement(user);
int i = age.get(user);
}
ABA问题
有一个变量a=1, 两个线程t1, t2来执行操作, t1读到a=1, 然后t2也读到a=2, t1通过cas设置a=2, 又通过cas把值设置为1, 然后t2使用cas设置值为3, 实际的操作过程为: 1→2→1→3, 而t2执行的操作是依据第一个1→3. 这样过程就是错误的了.虽然结果是正确的, 但是有些业务场景可能会关心业务发生的过程的.
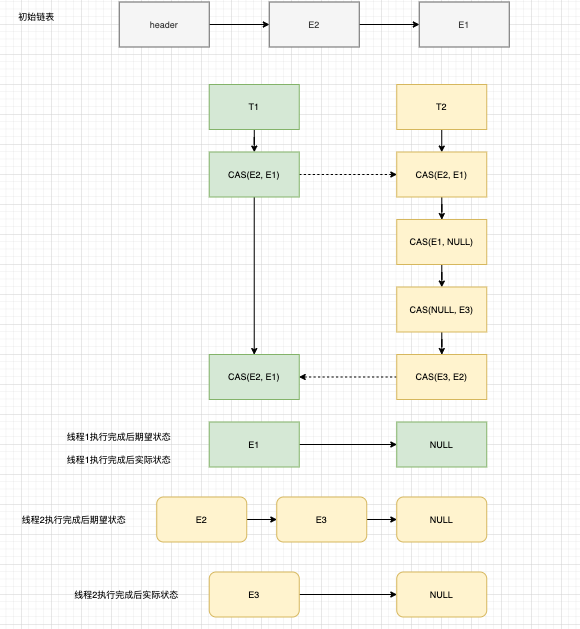
在线程1开始执行cas操作时, cpu资源让出, 然后线程2执行了一堆操作, 但是最终header还是e2, 所以线程1cas还是成功执行了, 引发的后果就是元素3成了游离态的元素.
解决方案
通用解决方案, 版本号, 每次执行完一次操作,对数据的版本号+1, 所以上面如果有版本号, 一开始拿到的e2版本是1, 最后执行cas时, 版本号会变成: 4, 从版本号可以发现这时的e2 不是一开始读取的e2.
使用AtomicStampedReference解决ABA问题
在cas的基础上, 增加了stamp标记, 可以用来查看数据是否发生变化. 工作原理就是先判断实际值和逾期值是否相等, 如果相等再判断stamp标记是否相等, 只有全部相等才能把新值和新stamp更新.
AtomicStampedReference(V initialRef, int initialStamp); initlaRef: 要引用的原始数据, initialStamp: 初始版本号.
常用api:
getRerference();
getStamp();
compareAndSet(exceptedReference, newReference, exceptedStamp, newStamp);
示例:
public class AtomicStampedReferenceTest {
public static void main(String[] args) throws InterruptedException {
Integer i = 1;
AtomicStampedReference<Integer> reference = new AtomicStampedReference<>(i, 0);
Thread t1 = new Thread(()->{
int stamp = reference.getStamp();
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
boolean compareAndSet = reference.compareAndSet(i, 2, stamp, stamp + 1);
if (!compareAndSet) {
System.out.println("t1失败");
}
});
Thread t2 = new Thread(()->{
int stamp = reference.getStamp();
int b=3;
boolean compareAndSet1 = reference.compareAndSet(i, b, stamp, stamp + 1);
boolean compareAndSet2 = reference.compareAndSet(b, i, stamp+1, stamp + 2);
System.out.println("t2执行结束后的i值: "+i);
if (!compareAndSet1 || !compareAndSet2) {
System.out.println("t2失败");
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(i);
}
}
## 输出
t2执行结束后的i值: 1
t1失败
1
可见t1 由于时间搓对比false, 得知这里的1和期望值1, 不是同一个版本的1, 即数据发生过变化.
使用AtomicMarkableReference解决ABA问题
同上, 只是版本号修改为了布尔值, 能够检测到数据发生了变化, 但不知道变化了几次.
提升高并发场景下CAS操作性能
在竞争激烈的场景下, cas会导致大量的空自旋, 从而浪费大量的CPU资源, 大大的降低了程序的性能, 可以使用LongAdder代替AtomicInteger.
💡 除了存在cas空自旋带来的问题, 在smp架构的cpu平台上, 大量的cas操作可能会导致”总线风暴”.LongAdder
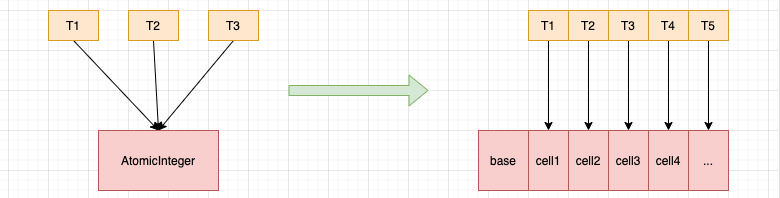
以空间换时间策略. 1.8版本jdk提供, 用于提高并发场景下的cas性能问题.
LongAdder的思想是把一个整数拆分为n个整数组成的数组, 然后线程在数组不同的位置上执行操作, 获取最终结果时, 对数组中的所有元素求和即可.
public class LongAdderTest {
static LongAdder adder = new LongAdder();
public static void main(String[] args) {
long start = System.currentTimeMillis();
ExecutorService exe = Executors.newFixedThreadPool(10);
IntStream.rangeClosed(1, 10).forEach(i->{
exe.submit(LongAdderTest::selfPlus);
});
exe.shutdown();
while (!exe.isTerminated()) {
System.out.println("轮询关闭");
}
System.out.println(adder.intValue());
long end = System.currentTimeMillis() - start;
System.out.println(end);
}
private static void selfPlus() {
IntStream.rangeClosed(1, 10000000).forEach(i->{
adder.add(1);
});
}
}
输出结果:
100000000
197
如果把LongAdder换成AtomicInteger, 测试结果:
100000000
1954
可以看出效率相差将近10倍.
LongAdder这种思想还是牛逼的.
LongAdder原理
原理就是将线程竞争的热点分散到数组中的不同位置, 减少cas的无效竞争, 空轮询次数从而提高效率. 解决思路非常像ConcurrentHashMap. 分段锁的思想.
CAS在JDK中的广泛应用
总结:
- 避免ABA, 通过AtomicStampedReference类和AtomicMarkableReference类来避免aba问题.
- 只能保证一个变量的操作是原子性的, 当包含多个属性操作时, 可以通过对象包含多个属性来实现.
- cas的空自旋带来的损耗, 通过longAdder分散热点, 使用队列削峰.
在jdk中的应用:
Atomic包, AQS以及显示锁, ConcurrentHashMap.
