Fine-Grained Text to Image Generation with Attentional Generative Adversarial Networks
源码链接
简介
根据自然语言描述自动生成图像是艺术生成和计算机辅助设计等许多应用中的一个基本问题。基于生成对抗网络( Generative Adversarial Networks , GANs)的文本-图像合成方法(text-to-image synthesis methods) 是最进流行的策略。
基于GANs的方法中,一种常用的策略是将整个文本描述编码成一个全局的句子向量,作为基于网络的图像生成的条件,然而这种策略仅仅局限于全局句子向量,缺乏单词层面的重要细粒度信息,从而阻碍了高质量图像的产生。为克服这个问题,文中提出了一种注意力驱动的、多阶段的细粒度文本-图像的注意力生成对抗网络(Attentional Generative Adversarial Network, AttnGAN) 模型,模型由两个新组件构成:
- 第一个组件为一个注意力生成网络,其中对生成器(generator)使用了一个注意力机制,通过聚焦与被绘制的子区域(sub-regions)最相关的单词来绘制图像的不同子区域。(如图1所示)
- 另一个组件为深度注意多模态相似度模型(a Deep Attentional Multimodal Similarity Model , DAMSM),DAMSM能够利用全局句子级别信息和细粒度词级别信息计算生成的图像与句子的相似度,因此DAMSM为训练生成器提供了额外的细粒度图像-文本匹配损失。

注意力生成对抗网络 AttnGAN
AttnGAN的架构如图2所示,包含两个组件:1、注意力生成网络;2、深度注意力多模态相似度模型。
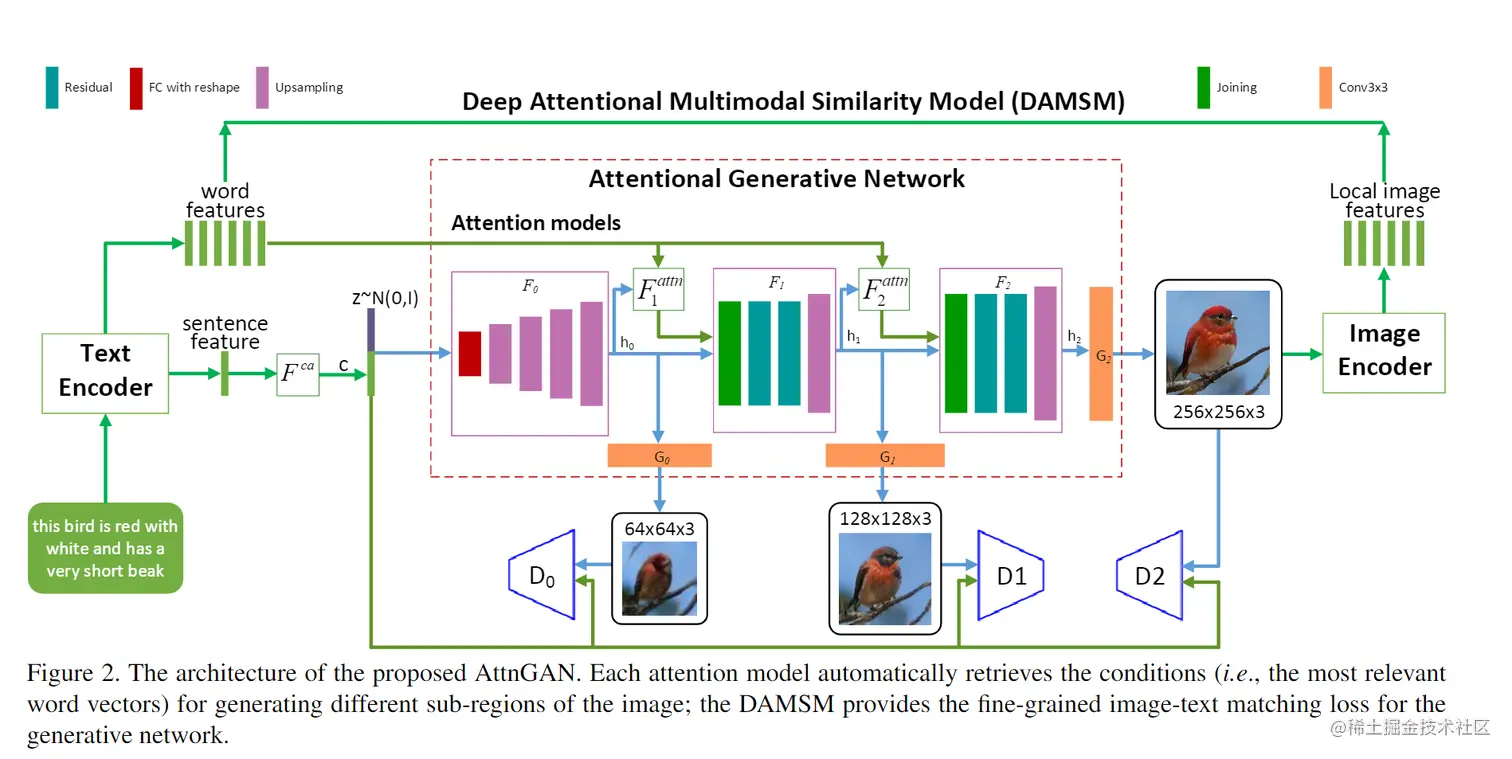
注意力生成网络
在本节中提出了一种新的注意力模型,其生成网络能够根据与子区域最相关的词来绘制图像的不同子区域。
如图2所示,注意力生产网络拥有m个生成器(G0,G1,...,Gm−1),其使用隐含状态h0,h1,..,hm−1作为输入,生产从小-大规模的图像(x^0,x^1,...,x^m−1)。具体如下:
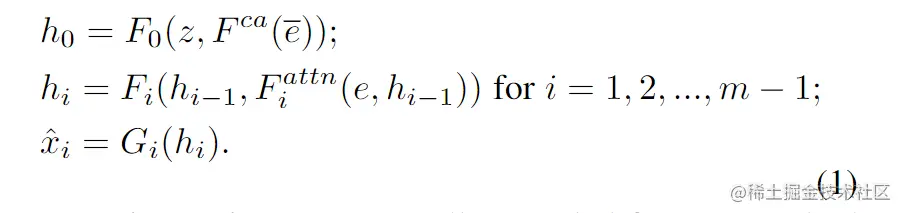
z为一个噪声向量,通常从一个正态分布中取样。eˉ为一个全局句子向量,e为词向量矩阵。Fca表示 Conditioning Augmentation,作用是将eˉ转换为条件向量(conditioning vector)。Fiattn表示在AttnGAN中第i阶段的注意力模型,Fca,Fiattn,Fi,Gi均被建模为神经网络。
Fattn(e,h)有两个输入,词向量 e∈RD×T和来自前一个隐含层的图像特征 h∈RD^×N。首先,通过增加一个新的感知器层( perceptron layer),将词特征转化为图像特征的公共语义空间,即:e′=Ue,U∈RD^×D。然后,根据图像的隐含特征h (query),对图像的每个子区域计算词上下文向量(word-context vector),即h中的每一列为图像一个子区域的特征向量。对于第j个子区域,其词上下文向量为词向量关于hj的一个动态表示,其计算方法为:
cj=i=0∑T−1βj,iei′,wherewhere βj,i=∑k=0T−1exp(sj,k′)exp(sj,i′)
其中,sj,i′=hjTei′,且βj,i表示模型在生成第j个子区域时对第i个单词的权重。然后,为图像特征集h定义词上下文矩阵通过:Fattn(e,h)=(c0,c1,....,cN−1)∈RD^×N。最后,将图像特征与相应的词上下文特征相结合,生成下一阶段的图像。
为了生成具有多级(句子级和词级)条件的真实图像,将注意力生成网络的最终目标函数定义为:
L=LG+λLDAMSM,wherewhere LG=i=0∑m−1LGi
λ为式中两项(即L)的平衡参数。
第一项为GAN损失,它集合了联合近似条件分布和无条件分布。在AttnGAN的第i阶段,生成器Gi有一个对应的鉴别器Di,则Gi的对抗损失定义为:
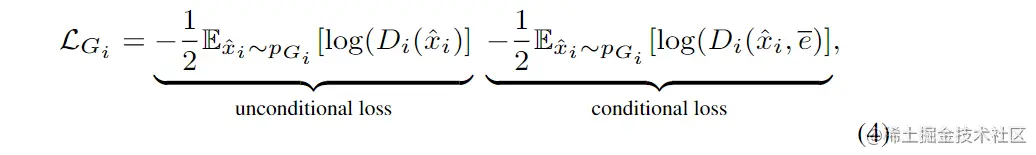
其中无条件损失决定图像的真伪,而条件损失决定图像与句子是否匹配。
对于Gi的训练,每个鉴别器Di通过最小化交叉熵损失被训练用于将输入分类为真假两类,则该损失定义为:

xi来自图像在第i个规模时的真实分布Pdatai,x^i来自相同规模下的模型分布PGi,AttnGAN的鉴别器在结构上是不相交的,因此它们可以并行训练,并且每个鉴别器都聚焦在单个图像尺度上。
第二项LDAMSM为一个词级别的细粒度图像-文本匹配损失,由DAMSM计算得到,将在下一节中详细说明。
深度注意多模态相似模型 DAMSM
DAMSM学习两个神经网络,将图像的子区域及句子的单词映射到一个共同的语义空间,从而在单词水平上度量图像-文本的相似度,计算出用于生成图像的细粒度损失。
文本编码器(The text encoder):为一个双向长短时记忆网络(LSTM),用于从文本描述中提取语义向量(semantic vectors)。在双向LSTM中,每个单词对应两个隐藏状态,每个方向对应一个隐藏状态,因此,连接它的两个隐藏状态来表示一个词的语义意义。所有词的特征矩阵表示为e∈Rd×T,ei的第i列为第i个词的特征向量。D为词向量的维度,T为词的数量。同时,双向LSTM的最后一个隐藏状态会被拼接为全局句子向量,用eˉ∈RD表示。
图像编码器(The image encoder) :为一个卷积神经网络(CNN),用于将图像映射为语义向量,CNN的中间层学习图像中不同子区域的局部特征,后一层学习图像的全局特征,具体的说,图像编码器是建立在通过ImageNet预训练的Inception-v3模型上的。首先,将输入图像缩放为299 × 299像素,然后从Inception-v3中的 mixed_6e 层提取局部特征矩阵f∈R768×289(从768×17×17缩放),f的每一列是图像中一个子区域的特征向量,768为局部特征向量的维数,289为图像中的子区域数。同时,从Inception-v3的最后平台池化层中提取全局特征向量fˉ∈R2048。最后,通过添加一个感知器层,将图像特征转换为文本特征的公共语义空间:
v=Wf,vˉ=Wˉfˉ
其中:v∈RD×289,它的第i列vi表示图像第i个子区域的世界特征向量。vˉ∈RD为整张图像的全局向量,D表示多模态(文本和图像模态)特征空间的维度。
注意驱动图像-文本匹配得分(The attention-driven image-text matching score):该评分被设计用于度量图像-句子对的匹配程度,基于一个介于图像和文本间的注意模型。首先计算句子中所有可能的单词组合和图像中子区域的相似度矩阵:
s∈RT×289,si,j为句子中第i个词和图像中第j个子区域间的点积相似度(dot-product similarity)。文章作者发现,将相似矩阵归一化效果更好:
sˉi,j=∑k=0T−1exp(sk,j)exp(si,j)
然后,建立一个注意力模型来计算每个单词(查询)的区域上下文向量,区域上下文向量(region-context vector)ci为一个图像子区域与句子中第i个单词关联的动态表示,为所有区域视觉向量的加权和:
ci=j=0∑288αivi,α=∑k=0288exp(γ1sˉi,k)exp(γ1sˉi,j)
γ1为在计算一个单词的区域上下文向量时,决定对其相关子区域的特征给予多少关注的一个因子。
最后,用ci,ei间的余弦距离定义第i个从和图像间的关联性,即:R(c1,ei)=(ciTei)/(∣∣ci∣∣ ∣∣ei∣∣)。受语音识别中最小分类误差公式的启发,整张图像(用Q表示)和整个文本描述(用D表示)间的注意驱动图像-文本匹配得分定义为:
R(Q,D)=log(i=1∑T−1exp(γ2R(ci,ei)))1/γ2
其中,γ2为一个决定如何放大最相关的词-区域-上下文对的重要性的因素。当γ2→∞时,R(Q,D)约等于maxi=1T−1 R(c1,ei)。
DAMSM损失:该损失被设计用于学习在半监督方式下的注意力模型,其中唯一的监督是整个图像和整个句子(一个词序列)间的匹配。对于一组(batch)图像-句子对{(Qi,Di)}i=1M,和句子Di及其匹配图像Qi的后验概率计算为:
P(Di∣Qi)=∑j=1M exp(γ3 R(Qi,Dj))exp(γ3 R(Qi,Di))
此处的γ3是通过实验确定的平滑因子。对于这组句子,只有Di与图像Qi匹配,将其余M−1个句子视为不匹配的描述。定义损失函数为图像与其对应文字描述(ground truth)匹配的负对数后验概率(negative log posterior probability)(w表示word):
L1w=−i=1∑MlogP(Di∣Qi)
对称的,最小化:
L2w=−i=1∑MlogP(Qi∣Di)
其中:
P(Qi∣Di)=∑j=1M exp(γ3 R(Qj,Di))exp(γ3 R(Qi,Di))
为句子Di与图像Qi匹配的后验概率。类似的方式可以得到L1s,L2s(此处的s为sentence)。
最终 DAMSM损失定义为:
LDAMSM=L1w+L2w+L1s+L2s 

