

java函数式编程
函数式编程的核心是:==在思考问题时,使用不可变值和函数,函数对一个值进行处理,映射成另一个值==。
lambda表达式
Java8 的最大变化是引入了 Lambda 表达式——一种紧凑的、传递行为的方式。
第一个例子:线程
public class LambdaTest {
public static void main(String[] args) {
// Java7写法
new Thread(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName());
}
}).start();
// Java8Lambda表达式写法
new Thread(() -> {
System.out.println(Thread.currentThread().getName());
}).start();
}
}
不同于java7匿名内部类的代码,Lambda的代码中核心的代码只有以下:
() -> {
System.out.println(Thread.currentThread().getName());
}
甚至连方法名和类名都隐去了,只留下了最为重要的代码:运行逻辑代码的主体
()很显然是要放置的是参数,很显然run方法没有参数,因此其中是空的。
如果对应的函数型接口的方法有参,那么()中必然要有参数。
另外一个例子:Swing的button
//java7写法
button.addActionListener(new ActionListener() {
public void actionPerformed(ActionEvent event) {
System.out.println("button clicked");
}
});
//java8写法
button.addActionListener(event -> System.out.println("button clicked"));
可以明显的看出:
和使用匿名内部类的另一处不同在于声明 event 参数的方式。使用匿名内部类时需要显式 地声明参数类型 ActionEvent event,而在 Lambda 表达式中无需指定类型,程序依然可以 编译。这是因为 javac 根据程序的上下文(addActionListener 方法的签名)在后台推断出 了参数 event 的类型。这意味着如果参数类型不言而明,则无需显式指定。
注意的是:
==Java 8 仍然是一种静态类型语言。为了增加可读性并迁就我们的习惯,声明参数时 也可以包括类型信息,而且有时编译器不一定能根据上下文推断出参数的 类型!==
Lambda的变体
Lambda 表达式除了基本的形式之外,还有几种变体:
-
Runnable noArguments = () -> System.out.println("Hello World");该
Lambda表达式不包含参数,使用空括号 () 表示没有参数。该 Lambda 表达式 实现了 Runnable 接口,该接口也只有一个 run 方法,没有参数,且返回类型为 void。 -
Runnable multiStatement = () -> { System.out.print("Hello"); System.out.println(" World"); };该
Lamdba表达式中则是正常的方法代码块:{}号包裹方法体。因此这个方法中有2行代码,上例中的没有用{}包裹是因为方法逻辑只有1行代码,因此简写。当然,只有1行的方法代码也可以用{}包裹。 -
ActionListener oneArgument = event -> System.out.println("button clicked");该
Lambda表达式包含且只包含一个参数,可省略参数的括号 -
BinaryOperator addExplicit = (Long x, Long y) -> x + y;某些时候,最好也可以显式声明参数类型,此时就需要使用小括号将参数括起来,多个参数的情况也是如此。
Lambda这种自动推断类型的方式其实在java中早有体现:
final String[] array = { "hello", "world" }
等号右边的代码并没有声明类型,系统根据上下文推断出类型信息。
引用值而不是变量
Java8Lambda表达式可以引用非 final 变量,但是该变量在既成事实上必须是 final。虽然无需将变量声明为 final,但在 Lambda 表达式中,也无法用作非终态变量。如果坚持用作非终态变量,编译器就会报错。
如下例:Lambda 表达式中引用既成事实上的 final 变量(即name)
String name = getUserName();
button.addActionListener(event -> System.out.println("hi " + name));
如果你试图给该变量多次赋值,然后在 Lambda 表达式中引用它,编译器就会报错。比如下例 无法通过编译,并显示出错信息:
local variables referenced from a Lambda expression must be final or effectively final
String name = getUserName();
name = formatUserName(name);
button.addActionListener(event -> System.out.println("hi " + name));
函数性接口
==函数接口是只有一个抽象方法的接口,用作 Lambda 表达式的类型==
例如:前面所用的ActionListener接口
public interface ActionListener extends EventListener {
public void actionPerformed(ActionEvent event);
}
}
ActionListener 只有一个抽象方法:actionPerformed,被用来表示行为:接受一个参数,
返回空。记住,由于 actionPerformed 定义在一个接口里,因此 abstract 关键字不是必需
的。该接口也继承自一个不具有任何方法的父接口:EventListener
使用图形来表示不同类型的函数接口。指向函数接口的箭头表示参数,如果箭头 从函数接口射出,则表示方法的返回类型。ActionListener 的函数接口如图 2-1 所示。
ActionListener 接口,接受一个 ActionEvent 对象,返回空
使用 Java 编程,总会遇到很多函数接口,但 Java 开发工具包(JDK8)新提供的一组核心函数接口会频繁出现。
如下:
而JDK8之前已有的函数式接口如下:
java.lang.Runnablejava.util.concurrent.Callablejava.security.PrivilegedActionjava.util.Comparatorjava.io.FileFilterjava.nio.file.PathMatcherjava.lang.reflect.InvocationHandlerjava.beans.PropertyChangeListenerjava.awt.event.ActionListenerjavax.swing.event.ChangeListener
类型推断
某些情况下,用户需要手动指明类型,建议大家根据自己或项目组的习惯,采用让代码最 便于阅读的方法。有时省略类型信息可以减少干扰,更易弄清状况;而有时却需要类型信 息帮助理解代码。经验证发现,一开始类型信息是有用的,但随后可以只在真正需要时才 加上类型信息。
使用菱形操作符,根据方法签名做推断
useHashmap(new HashMap<>()); 根据方法签名已经可以推断出泛型的类型
Predicate<Integer> atLeast5 = x -> x > 5; 根据接口多态的泛型已经推断出x的类型
Predicate 也是一个 Lambda 表达式,和前文中 ActionListener 不同的是,它还返回一个 值。表达式 x > 5 是 Lambda 表达式的主体。这样的情况下,返回值就是 Lambda 表达式主体的值。
Predicate 接口的源码,接受一个对象,返回一个布尔值
public interface Predicate {
boolean test(T t);
}
BinaryOperator
该接口接受两个参数,返回一个值,参数和值的类型均相同。
BinaryOperator<Long> addLongs = (x, y) -> x + y; 也是通过接口多态的泛型去推断x、y类型
但若信息不够,类型推断系统也无能为力。类型系统不会漫无边 际地瞎猜,而会中止操作并报告编译错误,寻求帮助。
比如以下代码:
BinaryOperator add = (x, y) -> x + y;
编译器给出的报错信息如下:
Operator '& #x002B;' cannot be applied to java.lang.Object, java.lang.Object.
BinaryOperator的源码中的抽象方法如下:
R apply(T t, U u);
方法引用
方法引用可以将一个方法封装成一个变量。就是一个Function对象。
Lambda 表达式有一个常见的用法:Lambda表达式经常调用参数。比如想得到艺术家对象的姓名,Lambda 的表达式如下
artist -> artist.getName();
这种写法太普遍,因此java8有一个简写方式叫方法引用,它会这样处理上面的写法:
Artist::getName
这种语法归纳到方法中了,只是它不需要在后面加括号,因为这里并不调用该方法。我们只是提供了和 Lambda 表达式等价的一种结构
构造函数也有同样的缩写形式
如果你想使用 Lambda 表达式创建一个 Artist 对象,可能 会写出如下代码:
(name, nationality) -> new Artist(name, nationality)
方法引用可以这样简写:
Artist::new
例子:
Consumer c = (e)->System.out.println(e);
简写为:
Consumer c=System.out::println();
Employee emp = new Employee("阿杰" , 21,3000);
Function<Employee, String> ft = (e)->e.getName();
简写为:
Function<Employee, String> ft2 = Employee::getName;
静态方法的方法引用
例如:
Integer类的parseInt方法,可以这样表示
Function<String, Integer> function = Integer::parseInt;
System.out.println(function.apply("12312"));
//12312
在stream中是这样应用的:
List<String> strings = Arrays.asList("124512", "759247");
List<Integer> collect = strings.stream().map(Integer::parseInt).collect(Collectors.toList());
collect.forEach(System.out::println);
如上例中 Integer::parseInt 表示默认就以strings中的每一个字符串对象为参数而执行Integer.parseInt 这个静态方法。
Stream
Stream 是用函数式编程方式在集合类上进行复杂操作的工具。
Stream将要处理的元素集合看作一种流,在流的过程中,借助Stream API对流中的元素进行操作,比如:筛选、排序、聚合等。
简而言之,Stream API 提供了一种高效且易于使用的处理数据的方式。
特性
stream不会改变数据源,通常情况下会产生一个新的集合或一个值。- 不是数据结构,不会保存数据。
- 惰性求值,流在中间处理过程中,只是对操作进行了记录,并不会立即执行,需要等到执行终止操作的时候才会进行实际的计算。
Stream的创建
stream()和 parallelStream()
List<String> list = new ArrayList<>();
//创建一个顺序流
Stream<String> stream = list.stream();
//创建一个并行流
Stream<String> parallelStream = list.parallelStream();
数组转成流
Integer[] nums = new Integer[10];
Stream<Integer> stream = Arrays.stream(nums);
使用Stream中的静态方法:of()、iterate()、generate()
//of方法
Stream<Integer> stream = Stream.of(1,2,3,4,5,6);
//iterate()
Stream<Integer> stream2 = Stream.iterate(0, (x) -> x + 2).limit(6);
stream2.forEach(System.out::println); // 0 2 4 6 8 10
//generate
Stream<Double> stream3 = Stream.generate(Math::random).limit(2);
stream3.forEach(System.out::println);
Pattern.splitAsStream() 方法,将字符串分隔成流
Pattern pattern = Pattern.compile(",");
Stream<String> stringStream = pattern.splitAsStream("a,b,c,d");
stringStream.forEach(System.out::println);
使用 BufferedReader.lines() 方法,将每行内容转成流
BufferedReader reader = new BufferedReader(new FileReader("F:\\test_stream.txt"));
Stream<String> lineStream = reader.lines();
lineStream.forEach(System.out::println);
stream和parallelStream的简单区分
stream是顺序流,由主线程按顺序对流执行操作,而parallelStream是并行流,内部以多线程并行执行的方式对流进行操作,但前提是流中的数据处理没有顺序要求。例如筛选集合中的奇数。
除了直接创建并行流,还可以通过parallel()把顺序流转换成并行流:
Optional<Integer> findFirst = list.stream().parallel().filter(x->x>6).findFirst();
流的使用
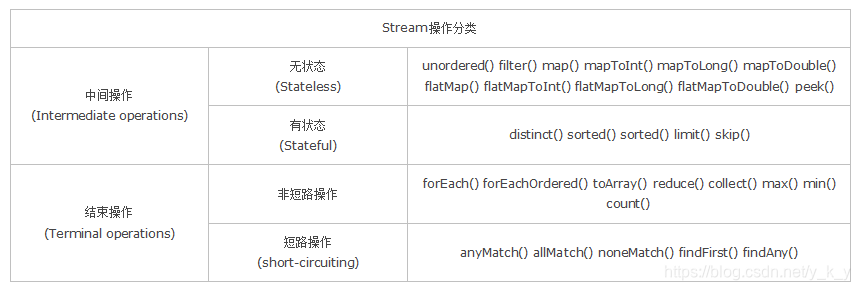
- 无状态:指元素的处理不受之前元素的影响;
- 有状态:指该操作只有拿到所有元素之后才能继续下去。
- 非短路操作:指必须处理所有元素才能得到最终结果。
- 短路操作:指遇到某些符合条件的元素就可以得到最终结果,如 A || B,只要A为true,则无需判断B的结果。
中间操作
只描述 Stream,最终不产生新集合(通常只生成stream)的方法叫作惰性求值方法;
这类方法称为中间操作。
筛选与切片
filter:过滤流中的某些元素 筛选出符合条件的数据 该操作是无状态的 接受的参数是Predicate对象
//筛选出大于33的数字
List<Integer> integers = Arrays.asList(5, 11, 33, 6, 89, 346, 12, 4, 1, 2, 67);
List<Integer> collect = integers.stream().filter(x -> x > 33).collect(Collectors.toList());
collect.forEach(System.out::println);
/*
89
346
67
*/
这里运用了collect结束操作它接受一个Collectors参数去将过滤后的流转成了一个List
-
limit(long a)获取前a个值 该操作是有状态的 参数是一个long类型的数据。List<Integer> integers = Arrays.asList(5, 11, 33, 6, 89, 346, 12, 4, 1, 2, 67); List<Integer> collect = integers.stream().filter(x -> x > 33).limit(2).collect(Collectors.toList()); collect.forEach(System.out::println); /* 89 346 */我们值是给上例的代码只是多加了一个对流的处理即
limt(2),则出现的只是前2个数据 -
distinct()通过流中元素的hashCode()和equals()去除重复元素 该方法没有参数 是有状态的List<Integer> integers = Arrays.asList(5, 11, 5, 8, 9, 5, 8, 11, 56, 34, 7, 9, 8, 5); List<Integer> collect = integers.stream().distinct().collect(Collectors.toList()); collect.forEach(i-> System.out.print(i+" ")); //5 11 8 9 56 34 7
映射
-
map()接收一个函数作为参数,该函数会被应用到每个元素上(即函数有返回值),**并将其映射成一个新的元素(映射成每个元素函数处理后的返回值)。**就是对流中的每一个元素进行处理后得到的元素去替换原来的元素。List<String> list = Arrays.asList("a,b,c", "1,2,3"); //将每个元素转成一个新的且不带逗号的元素 Stream<String> s1 = list.stream().map(s -> s.replaceAll(",", "")); s1.forEach(System.out::println); // abc 123 -
flatMap()接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个流。List<String> list = Arrays.asList("a,b,c", "1,2,3"); Stream<String> s3 = list.stream().flatMap(s -> { //此时的s代表每一个值即("a,b,c" 或 "1,2,3") //将每个元素转换成一个stream String[] split = s.split(","); Stream<String> s2 = Arrays.stream(split); return s2; }); s3.forEach(System.out::println); // a b c 1 2
排序
sorted()空参的此方法是自然排序,流中的元素需要实现Comparable接口sorted(Comparator com)定制排序,自定义Comparator排序器
消费
peek()如同于map,能得到流中的每一个元素。但map接收的是一个Function表达式,有返回值;而peek接收的是Consumer表达式,没有返回值。即对每一个元素执行了一个void修饰的方法(即无返回值)
Student s1 = new Student("aa", 10);
Student s2 = new Student("bb", 20);
List<Student> studentList = Arrays.asList(s1, s2);
studentList.stream()
.peek(o -> o.setAge(100))
.forEach(System.out::println);
//结果:
Student{name='aa', age=100}
Student{name='bb', age=100}
终止操作
最终会从 Stream 产生值或集合对象或对象的方法叫作及早求值方法。
这类方法称为终止操作。
匹配和聚合
allMatch:接收一个 Predicate 函数,当流中每个元素都符合该断言时才返回true,否则返回falsenoneMatch:接收一个 Predicate 函数,当流中每个元素都不符合该断言时才返回true,否则返回falseanyMatch:接收一个 Predicate 函数,只要流中有一个元素满足该断言则返回true,否则返回falsefindFirst:返回流中第一个元素 返回值是一个Optional容器(对象)。findAny:返回流中的任意元素 返回值是一个Optional容器(对象)。count:返回流中元素的总个数 返回值是long类型max:返回流中元素最大值 返回值是一个Optional容器(对象)。min:返回流中元素最小值 返回值是一个Optional容器(对象)。
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
boolean allMatch = list.stream().allMatch(e -> e > 10); //false
boolean noneMatch = list.stream().noneMatch(e -> e > 10); //true
boolean anyMatch = list.stream().anyMatch(e -> e > 4); //true
Integer findFirst = list.stream().findFirst().get(); //1
Integer findAny = list.stream().findAny().get(); //1
long count = list.stream().count(); //5
Integer max = list.stream().max(Integer::compareTo).get(); //5
Integer min = list.stream().min(Integer::compareTo).get(); //1
规约操作
Optional<T> reduce(BinaryOperator<T> accumulator)第一次执行时,accumulator函数的第一个参数为流中的第一个元素,第二个参数为流中元素的第二个元素;第二次执行时,第一个参数为第一次函数执行的结果,第二个参数为流中的第三个元素;依次类推。T reduce(T identity, BinaryOperator<T> accumulator):流程跟上面一样,只是第一次执行时,accumulator函数的第一个参数为identity,而第二个参数为流中的第一个元素。<U> U reduce(U identity,BiFunction<U, ? super T, U> accumulator,BinaryOperator<U> combiner): 在串行流(stream)中,该方法跟第二个方法一样,即第三个参数combiner不会起作用。在并行流(parallelStream)中,我们知道流被fork join出多个线程进行执行,此时每个线程的执行流程就跟第二个方法reduce(identity,accumulator)一样,而第三个参数combiner函数,则是将每个线程的执行结果当成一个新的流,然后使用第一个方法reduce(accumulator)流程进行规约。
//经过测试,当元素个数小于24时,并行时线程数等于元素个数,当大于等于24时,并行时线程数为16
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24);
Integer v = list.stream().reduce((x1, x2) -> x1 + x2).get();
System.out.println(v); // 300
Integer v1 = list.stream().reduce(10, (x1, x2) -> x1 + x2);
System.out.println(v1); //310
Integer v2 = list.stream().reduce(0,
(x1, x2) -> {
System.out.println("stream accumulator: x1:" + x1 + " x2:" + x2);
return x1 - x2;
},
(x1, x2) -> {
System.out.println("stream combiner: x1:" + x1 + " x2:" + x2);
return x1 * x2;
});
System.out.println(v2); // -300
Integer v3 = list.parallelStream().reduce(0,
(x1, x2) -> {
System.out.println("parallelStream accumulator: x1:" + x1 + " x2:" + x2);
return x1 - x2;
},
(x1, x2) -> {
System.out.println("parallelStream combiner: x1:" + x1 + " x2:" + x2);
return x1 * x2;
});
System.out.println(v3); //197474048
收集操作
-
collect接收一个Collector实例,将流中元素收集成另外一个数据结构。 -
Collector<T, A, R>是一个接口,有以下5个抽象方法:Supplier<A> supplier():BiConsumer<A, T> accumulator()BinaryOperator<A> combiner()Function<A, R> finisher()函数式接口,参数为:容器A,返回类型为:collect方法最终想要的结果R。Set<Characteristics> characteristics()返回一个不可变的Set集合,用来表明该Collector的特征。有以下三个特征:- CONCURRENT:表示此收集器支持并发。
- UNORDERED:表示该收集操作不会保留流中元素原有的顺序。
- IDENTITY_FINISH:表示finisher参数只是标识而已,可忽略。
元素顺序
在一个有序集合中创建一个流时,流中的元素就按出现顺序排列
则如下的代码,总是可以通过的。
List<Integer>numbers=asList(1,2,3,4);
List<Integer>sameOrder=numbers.stream().collect(toList());
assertEquals(numbers,sameOrder);
集合本身就是无序的,由此生成的流也是无序的。
比如说,HashSet就是一种无序的集合。以下代码,不能保证每次都能运行成功
Set<Integer> numbers = new HashSet<>(asList(4,3,2,1));
List<Integer> sameOrder = numbers.stream().collect(toList());
//该断言有时会失败
assertEquals(asList(4,3,2,1),sameOrder);
Collectors工具类
整个Collectors工具类就是在为Collector服务,用于创建各种不同的Collector。部分功能与Stream中的方法重合了,为了简化代码,完全不必采用Collectors实现,优先Stream方法。
List<Student> students = Arrays.asList(new Student("Tom", 8900, 23, "male", "New York"),
new Student("Jack", 7000, 25, "male", "Washington"),
new Student("Lily", 7800, 21, "female", "Washington"));
//转List
List<Integer> ageList = list.stream().map(Student::getAge).collect(Collectors.toList());
ageList.forEach(System.out::println);
//转成set
Set<Integer> ageSet = list.stream().map(Student::getAge).collect(Collectors.toSet());
//转成map,注:key不能相同,否则报错
Map<String, Integer> studentMap = list.stream().collect(Collectors.toMap(Student::getName, Student::getAge));
//字符串分隔符连接
String joinName = list.stream().map(Student::getName).collect(Collectors.joining(",", "(", ")"));
//聚合操作
//1.学生总数
Long count = list.stream().collect(Collectors.counting()); // 3
//2.最大年龄 (最小的minBy同理)
Integer maxAge = list.stream().map(Student::getAge).collect(Collectors.maxBy(Integer::compare)).get(); // 20
//3.所有人的年龄
Integer sumAge = list.stream().collect(Collectors.summingInt(Student::getAge)); // 40
//4.平均年龄
Double averageAge = list.stream().collect(Collectors.averagingDouble(Student::getAge)); // 13.333333333333334
//分组
Map<Integer, List<Student>> ageMap = list.stream().collect(Collectors.groupingBy(Student::getAge));
//多重分组,先根据类型分再根据年龄分
Map<Integer, Map<Integer, List<Student>>> typeAgeMap = list.stream().collect(Collectors.groupingBy(Student::getAge, Collectors.groupingBy(Student::getAge)));
//分区
//分成两部分,一部分大于10岁,一部分小于等于10岁
Map<Boolean, List<Student>> partMap = list.stream().collect(Collectors.partitioningBy(v -> v.getAge() > 10));
//规约
Integer allAge = list.stream().map(Student::getAge).collect(Collectors.reducing(Integer::sum)).get(); //40
-
Collectors.toList()用于转化成List集合的Collector对象,默认为ArrayList。 -
Collectors.toList()用于转化成Set集合的Collector对象,默认为HashSet。 -
mapping(Function<? super T, ? extends U> mapper, Collector<? super U, A, R> downstream)对流中的每个元素以Function参数进行处理,即类型转换,然后再将新元素以给定的Collector进行归纳。 类似于stream流中的map中间操作。 仍旧还是Collector对象 -
collectingAndThen(Collector<T,A,R> downstream,Function<R,RR> finisher)该方法是在归纳动作结束之后,对归纳的结果进行再处理。
-
counting()用于计数 -
minBy/maxBy其参数是一个是一个Comparator实例 -
summingInt/summingLong/summingDouble用于求和 参数是一个Function实例 -
averagingInt/averagingLong/averagingDouble用于求平均值 参数是一个Function实例 -
reduce与stream中规约类似 -
groupingBy用于分组 参数是一个Function实例 用于规定以何种方式分组 -
partitioningBy(Predicate<? super T> predicate)用于分区 该方法共有2个重载partitioningBy(Predicate<? super T> predicate,Collector<? super T, A, D> downstream)可以进行多重分组 -
toMap(Function<? super T, ? extends K> keyMapper, Function<? super T, ? extends U> valueMapper)根据给定的键生成器和值生成器生成的键和值保存到一个map中返回 该方法共有3个重载toMap(Function<? super T, ? extends K> keyMapper,Function<? super T, ? extends U> valueMapper,BinaryOperator<U> mergeFunction)在上面方法的基础上增加了对键发生重复时处理方式的mergeFunction,比如上面的默认的处理方法就是抛出异常toMap(Function<? super T, ? extends K> keyMapper,Function<? super T, ? extends U> valueMapper,BinaryOperator<U> mergeFunction,Supplier<M> mapSupplier)在第二个方法的基础上再添加了结果Map的生成方法。
public class CollectorsTest { public static void toMapTest(List<String> list){ Map<String,String> map = list.stream().limit(3).collect(Collectors.toMap(e -> e.substring(0,1),e -> e)); Map<String,String> map1 = list.stream().collect(Collectors.toMap(e -> e.substring(0,1),e->e,(a,b)-> b)); Map<String,String> map2 = list.stream().collect(Collectors.toMap(e -> e.substring(0,1),e->e,(a,b)-> b,HashMap::new)); System.out.println(map.toString() + "\n" + map1.toString() + "\n" + map2.toString()); } public static void main(String[] args) { List<String> list = Arrays.asList("123","456","789","1101","212121121","asdaa","3e3e3e","2321eew"); toMapTest(list); } } /* {1=123, 4=456, 7=789} {a=asdaa, 1=1101, 2=2321eew, 3=3e3e3e, 4=456, 7=789} {a=asdaa, 1=1101, 2=2321eew, 3=3e3e3e, 4=456, 7=789} */
Optional
Optional 是为核心类库新设计的一个数据类型(容器),用来替换 null 值。
人们对原有的 null 值 有很多抱怨,甚至连发明这一概念的 Tony Hoare 也是如此,他曾说这是自己的一个“价值 连城的错误”。作为一名有影响力的计算机科学家就是这样:虽然连一毛钱也见不到,却也可以犯一个“价值连城的错误”。
人们常常使用 null 值表示值不存在,Optional 对象能更好地表达这个概念。
使用 Optional 对象有两个目的:
- 首先,Optional 对象鼓励程序员适时检查 变量是否为空,以避免代码缺陷;
- 其次,它将一个类的 API 中可能为空的值文档化,这比 阅读实现代码要简单很多。
使用
使用工厂方法 of,可以从某个值创建出一个 Optional 对象。
Optional 对象相当于值的容器,而该值可以 通过 get 方法提取。
//成立Optional对象
Optional<String> a = Optional.of("a");
assertEquals("a", a.get());
Optional 对象也可能为空,因此还有一个对应的工厂方法 empty,另外一个工厂方法 ofNullable 则可将一个空值转换成 Optional 对象。
isPresent 方法检测容器中是否有值。
Optional emptyOptional = Optional.empty();
//将ofNullable转为optional对象
Optional alsoEmpty = Optional.ofNullable(null);
assertFalse(emptyOptional.isPresent());
使用 Optional 对象的方式之一是在调用 get() 方法前,先使用 isPresent 检查 Optional 对象是否有值。使用 orElse 方法则更简洁,当 Optional 对象为空时,该方法提供了一个 备选值。如果计算备选值在计算上太过繁琐,即可使用 orElseGet 方法。该方法接受一个 Supplier 对象,只有在 Optional 对象真正为空时才会调用。
Optional 对象不仅可以用于新的 Java 8 API,也可用于具体领域类中,和普通的类别无二 致。当试图避免空值相关的缺陷,如未捕获的异常时,可以考虑一下是否可使用 Optional 对象
