Representation Learning for Predicting Customer Orders
简介
预测未来客户订单对零售商做出许多关键的运营决策具有重要参考价值,这篇论文的目标在于预测未来订单的分布信息,即商品的可能子集及其频率(概率),这是前端仓库的分类选择和交付中心的能力评估等决策所需要的重要数据。
订单分布信息的学习与下一篮子预测(next-basket prediction)、时间集预测(temporal set prediction)和频繁集挖掘(frequent set mining)有很大的不同,其目标是描述一个特定时期内市场聚合行为的全貌,而下一篮子预测和时间集预测关注的是特定客户下一次购物的行为,而不考虑购买的时间,此外频繁集挖掘只给出高频集合,而不提供挖掘集合的确切概率信息,不能满足业务应用的需要。
由于可能的订单类型的组合爆炸式增长,从数据中学习订单分布面临着许多重大挑战,包括:
- 用于学习分布的订单数据通常是稀疏的,其中观察到的订单数量远远小于可能的订单类型的数量,许多可能的顺序类型不会出现在数据集中,或者只出现一次。
- 学习的订单分布应该捕捉到商品类目之间的相关性,因为一个订单所属的商品类目往往不是独立的。
- 为了在前面提到的下游应用程序中使用订单分布,通常需要生成许多随机订单。因此,还需要设计出有效的方法来根据学习到的订单分布抽样随机订单。
未来订单预测
在介绍预测模型之前,首先探讨在已知数据集订单分布p的前提下如何预测未来订单。
符号
用V={1,2,..,n}表示商品品类集合,S表示订单类型,为V的一个子集,所有可能的订单类型数量为N=2n。
假设订单分布在一定时间内是不变的(这是能够用历史订单预测未来订单的前提),假设p={p1,...,pN}为从历史数据中学习得到的订单分布,pi表示随机订单属于第i个订单类型中的概率,用pg={p1g,...,pNg}表示近期订单的 ground truth 分布。
用K表示未来一段时间内订单的数量,假设K是给定的(因为预测K比预测特定订单要容易得多)。使用一个N-维整数向量Cg=(c1g,...,cNg)来表示 ground truth 未来订单,c1g表示第i类订单的ground truth 订单数量。Cp=(c1p,...,cNp),表示学习得到的订单,显然∣∣Cp∣∣1=K,Cp的构造通常是基于学到的订单分布p。
评估度量
目标是让预测Cp尽可能接近Cg,因此需要度量二者的差异,二者间 overlap(可以理解为相似度)可以计算为:
Overlap(Cp,Cg)=i=1∑NKmin(cip,cig)
由于∣∣Cp∣∣1=∣∣Cg∣∣1=K,上式可以简化为:
Overlap(Cp,Cg)=1−2K∣∣Cp−Cg∣∣1
可见最小化∣∣Cp−Cg∣∣1等同于最大化Overlap(Cp,Cg)。
Overlap 最大化算法
定义概率Pr(Cg=C1;K,pg),其中Cg=C1=(c11,...,cN1),∣∣C1∣∣=K,它根据ground truth 订单分布pg 随机生成订单,因此得到:
Pr(Cg=C1;K,pg)=c11!,...,cN1!K!i=1∏N(pig)ci1
第i个订单类型中ground truth订单数量的边际概率为:
Pr(cig=Cci1;K,pg)=Kci1(pig)ci1(1−pig)K−ci1
可知,cig重复二项式分布B(K,pig)。对于一个确定的订单预测Cp,有:
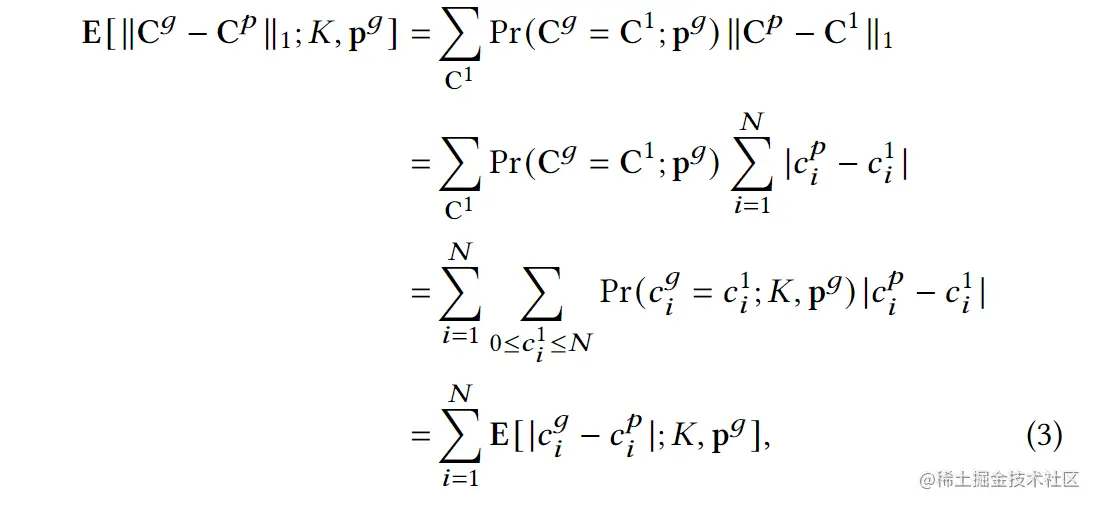
此处的E[∣cig−cip∣;K,pg]定义为根据pg生成cig时∣cig−cip∣的期望值。当cip为cig的几何平均数时(即Kpig取整),E[∣cig−cip∣;K,pg]达到其最小值。
Observation 1:当设置Cp≈Kpg时,cip的值为Kpig取整且∣∣Cp∣∣1=K,E[∣cig−cip∣;K,pg]接近于其最小值,其几何意义为Cg和Cp间的l1-距离期望值。
通过Observation 1可以很容易发现之前提到的最大化Overlap(Cp,Cg)实际上就是要设置Cp≈Kpg。然而实践中,并不能知道ground truth订单分布pg,只能通过近期历史数据中学习一个订单分布p,然后使用p来构造Cp,并希望p和pg尽可能接近,p也称之为一个代理订单分布(proxy order distribution)。
算法1中展示了使用代理订单分布p来构造Cp的过程。

生成性选择模型
本节提出了一个生成选择模型,可以有效地生成随机订单,该模型将商品类别嵌入到一个欧几里得空间并基于嵌入构建了一个商品类别图,在商品类别图上运行随机漫步来生成随机订单。
商品类别嵌入和商品类别图
给定商品品类集合V={1,2,...,n}和多个历史订单集合S={S1,S2,...,Sr},Si为V的一个子集。品类i表示为一个d-维向量xi∈Rd,称为品类嵌入(item embedding)。
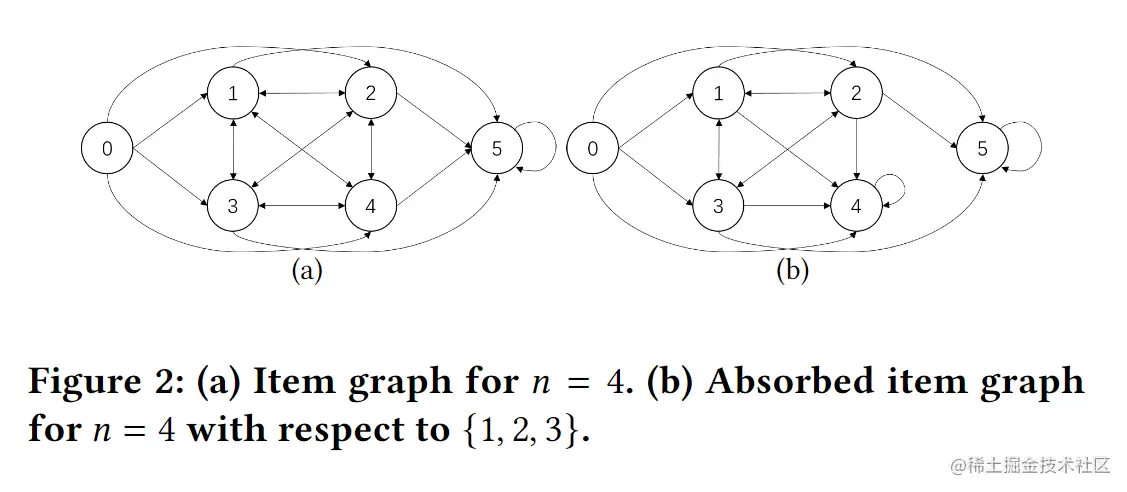
为构建品类图,引入了两个虚顶点(imaginary vertices),源节点0和汇聚节点n+1,以及嵌入x0的顶点0。品类图为一个有向图G=<V∪{0,n+1},E>,E中包含了从0到V、从V到V(除了循环),从V到n+1的所有边,和一个n+1上的循环,一个n=4的品类图如图2(a)所示:
随机漫步生成随机订单
将顾客选择的生成过程建模为基于品类图的随机漫步过程:从源节点0开始,客户只能沿着当前顶点外的边移动,最终将被困在汇聚节点n+1中(可见图2中最后的自循环),通过这种方式得到该客户的订单就是其所访问商品的集合。
形式化后,随机漫步可以被看过一个马尔科夫过程(Markov process){Xi,i=0,1,..∣X0=0},访问过的品类集合为S={Xi∣i=0,1,...}−{0,n+1}。此外还需要一个转移概率矩阵P,矩阵中Pij表示从i转移到j的概率,文中Pij的设置方式如下所示:
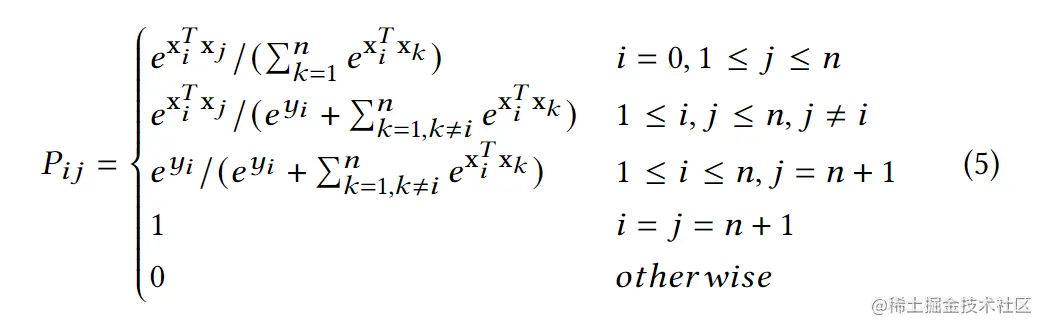
yi表示客户在购买品类i后是否会停止购买,定义一个参数集合X={x0,...,xn,y1,...,yn}。使用xiTxj来度量品类i,j间的相关性,使用softmax函数来标准化品类图中品类i和其他节点间的相关性。通过该模型随机生成的订单定义为S,使用Pr{S=s∣X}来表示某个订单类别s⊆V中一个随机订单S的概率。
训练过程
在本节中,为了学习顶点表示,我们首先将训练过程制定为一个最大似然估计任务。随机梯度的精确计算如算法2所示:

数据集和源码
数据集链接
源码链接


