原文链接
简介
本文研究的是关于排名的学习,即构建一个模型或函数来排名对象,学习排名对于文档检索、协同过滤和许多其他应用程序都非常有用。
许多应用程序的中心问题是排名,包括文档检索、协同过滤、专家查找、反网络垃圾邮件、情感分析和产品评估等。由于其重要性,排名学习近年来在机器学习领域引起了广泛的关注。基于一种称为对感知的方法(pairwise approach) 已经开发了几种方法,并成功地应用于文档检索,该方法以文档对作为学习的实例,将学习问题形式化为分类问题,在学习过程中,它从排名列表中收集文档对,并为每个文档对分配一个标签,表示两个文档的相对相关性,然后用标记好的数据训练分类模型,并利用分类模型进行排序,分类模型可以使用SVM、Boosting和神经网络等。
排名学习
排名学习是机器学习中一个新的热门话题,其中一种主要的学习排名的方法称为成对方法(pairwise approach),在成对方法中,学习任务被形式化为:将对象对分为两类(正确排名和错误排名)。
Listwise 方法
本节以文献检索为例,对排名学习进行了概述。特别地,详细地描述了按列表排列(Listwise)方法。
在训练中,给定一组查询Q={q(1),...,q(m)},每个查询q(i)和一份文件清单d(i)={d1(i),...,dn(i)(i)}相关联,dj(i)表示第j个文件,n(i)表示文件清单的规模。进一步,每份文件清单d(i)又和一份评价清单(分数)y(i)={y1(i),...,yn(i)(i)}相关联。显然,yj(i)表示查询q(i)和文件dj(i)的关联程度,它可以是人类明确或含蓄给出的分数,例如:yj(i)可以是在搜索引擎中检索并返回q(i)时对dj(i)的点击次数,次数越高说明二者的关联程度越高。
对于每个查询-文件对(q(i),dj(i))创建一个特征向量xj(i)=Ψ(q(i),dj(i)),i=1,2,...,m;j=1,2,...,n(i)。每个特征列表x(i)=(x1(i),...,xn(i)(i))和分数列表y(i)=(y1(i),...,yn(i)(i))组合成一个实例(instance)。训练集的定义为T={(x(i),y(i))}i=1m。
创建一个排名函数f,对于每个特征向量xj(i)输出一个分数f(xj(i))。显然,对于一个特征向量列表x(i)可以得到一个分数列表z(i)=(f(x1(i)),...,f(xn(i)(i)))。学习的目标为最小化 Listwise 损失函数L:
Mini=1∑mL(y(i),z(i))(1)
通过学习得到的模型,在测试中给文件d(i′)打分,然后根据分数降序排名文件。
上面描述的学习问题被称为排名学习的列表方法(listwise approach to learn-
ing to rank)
Pairwise 方法
在Pairwise 方法中,从训练集T中创建新训练集T′,其中每个特征向量对xj(i),xk(i),j=k 组成一个新的实例,若yj(i)>yk(i)则给特征向量对赋值+1,否则赋值−1,这表明T′为一个二分类数据集,像SVM这类分类器可以很容易处理该问题。
概率模型
使用两种概率模型来计算公式(1)中的损失函数。
Permutation Probability 排列概率
假设现在有一组需要排名的对象由数字{1,2,...,n}定义,这些对象中的一个排名π被定义为从{1,2,...,n}到其自身双射,写作π=<π(1),...,π(n)>,π(j)定义为一个在排名中的位置j的对象。n个对象所有可能的排名集合定义为Ωn。
假设有一个排名函数,它为n个对象分配分数,分数集合的定义为s=(s1,...,sn),sj为第j个对象的分数。
假设使用排名函数对排名列表(permutation)进行预测时存在不确定性,换句话说,假设:任何排名都是可能的,排名函数对不同的排名可能计算出不同的似然值
定义1:假设π是n个对象的一个排名结果,ϕ()为一个严格递增的正函数。给定分数列表s,排名π的概率可以定义为:
Ps(π)=j=1∏n∑k=jnϕ(sπ(k))ϕ(sπ(j))
例子:对于对象{1,2,3}及其打分s=(s1,s2,s3),序列π=<1,2,3>,π′=<3,2,1>的概率为:
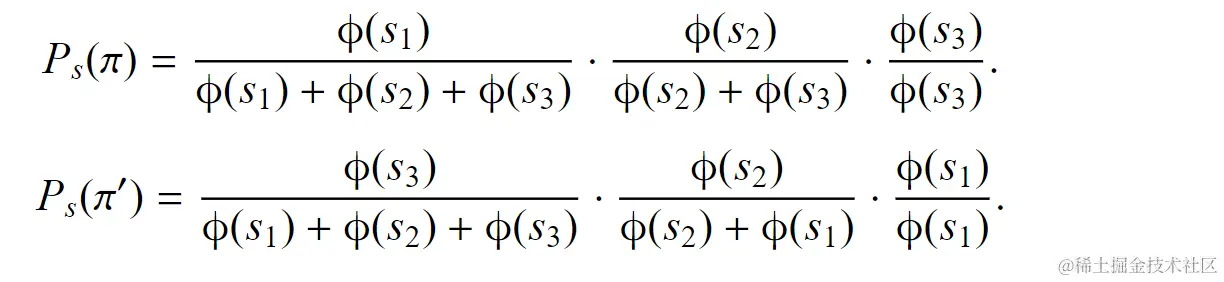
定理2: 排名概率Ps(π),π∈Ωn在排名集合上组成了一个概率分布。举例说明,对于每个π∈Ωn,都有Ps(π)>0 and ∑π∈ΩnPs(π)=1。
定理3:给定两个排名π,π′,若:
- π(p)=π′(q),π′(p)=π(q),p<q
- π(r)=π′(r),r=p,q
- sπ(p)>sπ(q)
则:Ps(π)>Ps(π′)。这个定理说明,对于一个排名,若得分较高的对象排在得分较低对象的前面,若交换两个对象的位置,得到的排名概率会低于原来的排名。
定理4:对于n个对象,若s1>s2>...>sn则Ps(<1,2,..,n>)为最高的排名概率,Ps(<n,n−1,...,1>)为最低的排名概率。(显然很容易证明)
定理5:
-
对于线性函数ϕ(x)=αx,α>0,其排名概率是尺度不变的,即:
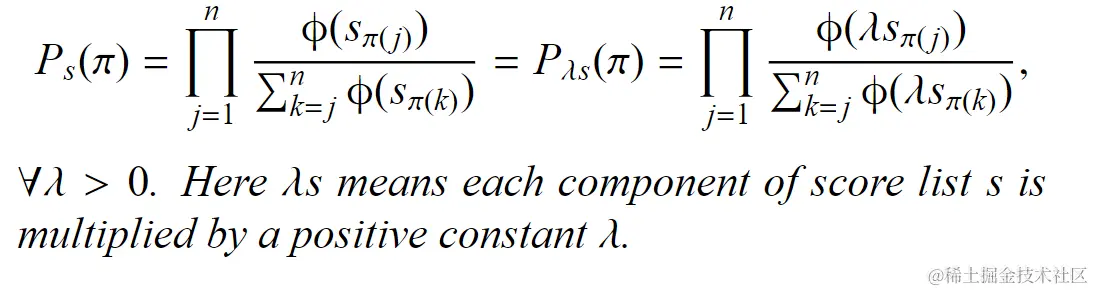
-
对于指数函数ϕ(x)=exp(x),其排名概率是平移不变的,即:
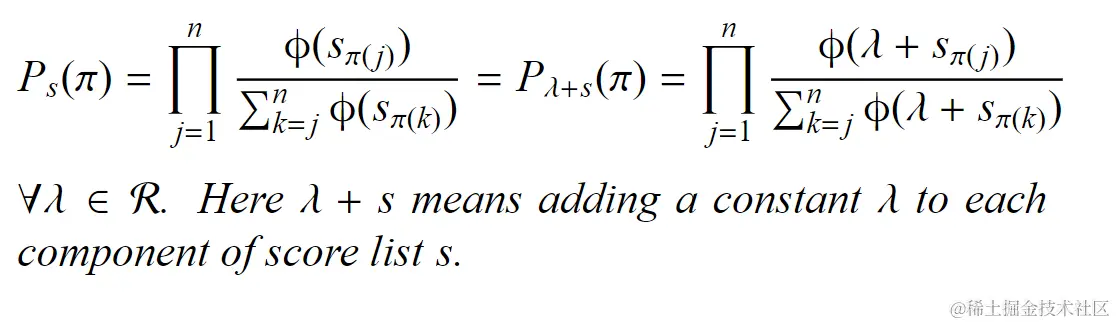
给定两个得分列表,我们可以先计算对应的两个排名概率分布,然后取这两个分布之间的度量作为 Listwise 损失函数,然而这种计算方法的时间复杂度为O(n!),不实用,因此提出了top-k概率。
top-k概率
top-k概率的计算非常简单易懂,取对象的前k个概率(j1,j2,...,jk)来表示它们被排名在前k位置的概率。
定义6:top-k子组合gk(j1,j2,...,jk)包含了前k个对象的所有可能排名:
gk(j1,j2,...,jk)={π∈Ωn∣π(t)=jt,∀t=1,2,...,k}
gk为所有top-k子组合的集合:
gk={gk(j1,j2,...,jk)∣jt=1,2,...,n,∀t=1,2,...,k,ju=jv,∀u=v}
显然,集合gk包含了(n−k)!n!个成员。
定义7:对象的top-k概率(j1,j2,...,jk)为子组合gk(j1,j2,...,jk)的概率,即:
Ps(gk(j1,j2,...,jk))=π∈gk(j1,j2,...,jk)∑Ps(π)
定义8:对于top-k概率Ps(gk(j1,j2,...,jk)),存在:
Ps(gk(j1,j2,...,jk))=t=1∏k∑l=tnϕ(sjt)ϕ(sjt)
推理9:top-k概率构成了集合gk的概率分布。
定理10:给定对象ju,jv,若sju>sjv,u=v,u,v=1,2,...,n,则:Ps(gk(j1,...,ju,...,jv,...,jk))>Ps(gk(j1,...,jv,...,ju,...,jk))。和上述一样,这个公式证明了top-k概率的平移不变性和尺度不变性。
给定两个得分列表,可以定义对应的top-k概率分布之间的度量作为 Listwise 损失函数。例如,使用交叉熵为度量,公式(1)中的损失函数可以定义为:
L(y(i),z(i))=−∀g∈gk∑Py(i)(g)log(Pz(i)(g)) 

