

五大数据结构
- Strings
- Hashes
- Lists
- Sets
- Sorted set
Strings
- 字符串
- 数值
Redis中的字符串叫做SDS(Simple Dynamic String)简单动态字符换,底层结构是一个带长度信息的字节数组byte
在Redis中,字符串有两种存储方式,在长度特别短的时候,用embstr,当长度超过44字节就会用raw形式存储
Redis的对象都会有一个对象头,结构如下
struct RedisObject {
int4 type ; //4bits
int4 encoding ; //4bits
int24 lru ; //24bits lru信息
int32 refcount ;//4bytes 引用计数
void *ptr; //8bytes,64-bit system
} robj ;
当SDS结构体太小的时候,头就会显得特别大
原子计数器 incr
抢购、秒杀、详情页
并发下,规避在数据库的操作
分布式主键自增
- incrby 一次性拿多点
- incr 累加
通过incrby一次性拿多一点 然后对他进行自增
Hashes
与Java的HashMap结构相似
底层实现:ziplist、hashtable
当满足以下两个条件,则使用ziplist进行存储
- 哈希对象保存的所有键值对的键和值的字符长度都小于64字节
- 哈希对象保存的键值对数量小于512个
电商购物车
Lists
- Stack 栈:LPUSH + LPOP
- Queue 队列:LPUSH + RPOP
- Blocking MQ 阻塞队列 :LPUSH + BRPOP
具有顺序特点的应用场景
BRPOP:阻塞弹出,如果没有元素 则会阻塞,等有元素之后再弹出
压缩列表(zipList)
redis中的list内部其实是一个叫做quicklist的数据结构。
首先在list元素比较少的时候,是ziplist,他是用一块连续的内存存储。
当数据量比较多的时候,才会转变成quicklist
快速列表(quickList)
元素特别多的时候,Redis会把用quickList,把一个个zipList给串起来
quickList他有自己的quickList node ,qucikList node下面连接的就是一个个的zipList
应用场景:
消息流
Sets
无顺序,更为复杂关系型特点,重复性,随机性,交集并集差集
底层结构:inset、dict
当元素较少时,使用inset进行存储;元素较多时使用字典dcit来存储
应用场景:
抽奖
朋友圈
关注模型
ZSets
有序集合
存进去的时候可以带一个分值(可以放时间戳,这样就保证了时间顺序)
底层结构:ZSets底层是一个复合结构,是由一个hash和SkipList组合的
跳表(skipList)
struct zslnode {
string value;
double score;
zslnode*[] forwards; //多层连接指针
zslnode* backward; //回溯指针
}
struct zsl {
zslnode* header; //跳跃列表头指针
int maxLevel; //跳跃列表当前的最高层
map<string, zslnode ht; //hash 结构的所有键值对
}
skipList是zset底层的实现方式。在Redis中,skipList具有高度的概念,高度越高,元素就越小,区分度就越大。这样可以减少很多不必要的遍历
使得链表拥有二分查找的能力
跳表:将有序链表改造为支持折半查找算法,可以进行快速的插入、删除、查找操作
时间复杂度O(logN)
排行榜
布隆过滤器
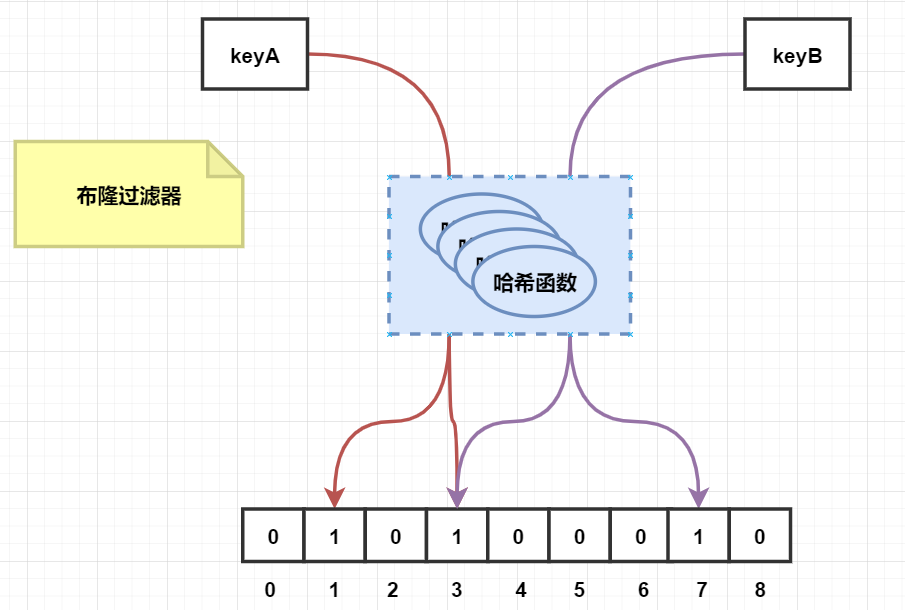
应用场景:
- 原本有10亿个号码,现在又来了10万个号码,要快速准确判断这10万个号码是否在10亿个号码库中
- 垃圾邮箱的过滤
特点:类似这种大数据量集合,快速准确的判断某个数据是否在集合中,并且不占内存,这就是布隆过滤器的应用场景
底层实现是bitmap
向布隆过滤器插入数据的时候,是通过多个hash函数计算出他的hashcode。一般都是通过一个hash函数。
因为使用的是hash,所以布隆过滤器无法解决hash的通病,也就是哈希碰撞。
所以布隆过滤器是可以判断某个数据一定不存在,但是不能证明某个元素一定存在
👍 优点:
能够在大数据集合中,快速定位某元素是否存在
👎 缺点:
随着数据的增加,误判率会增加,并且无法删除数据
bitmap
经典应用场景:统计千万级别用户签到活跃,可以通过bitmap实现
业务场景的特点:
具有连续的关系,不然内存开销会特别大
通过bitmap来存储,用户id 相当于 key,是否上线设为 value
bitcount:用来查找多少个1
bitpos[start,end]:用来查找第一个1或者0,表示用户从哪一天签到到哪一天
补充一点:
[start,end]参数是字节索引,因此是8的倍数,所以在具体的业务场景,很多时候我们都是将大于等于我们需要求的数的8的整数倍全部求出来,然后再通过我们的代码逻辑去求出符合业务场景。
有点像那个算法 汉明距离(求二进制1的数目)
求连续登录:
可以对全部时间表,进行一个&运算,然后再通过bitCount获取1的值,就是全部登录时间
GeoHash
一般做法
如果让你实现一个“附近的人”,你该如何设计?
一般计算两点之间距离,通过勾股定理足矣。如果再精确一点,可以加按一定的系数加权求和。因为我们的地球是椭圆的,经纬度坐标的密度不一样。
如果在此基础上,对附近的人进行排序,该如何设计?
如果数据以(id,经度,维度)的方式存储在数据库中,要进行排序的话,势必会将所有元素遍历,再计算每一个元素到目标点的举例,再排序
这个计算量是非常大的
一般我们可以采取一个矩形的区域来限定元素的数量,然后进行全量举例计算再排序,如果不满意,则可以扩大矩形的大小
GeoHash算法
GeoHash是业界通用对的地理位置距离排序算法。
核心是通过将二维的经纬度数据映射到一维上,这样所有元素的关系都可以通过一条直线上,相邻元素的距离来确认。
存储坐标,借助Zsets 实现,通过zset的score进行排序,就可以得到坐标附近的元素,通过将score还原成坐标值就可以得到元素的原始坐标
单例部署
Geo的数据是非常大的,在集群环境中,集合可能从一个节点迁移到另一个节点,如果单个key数据过大,就会影响迁移工作。
所以Geo的数据建议是使用单独Redis实例部署,不适合集群环境。
HyperLogLog
统计不重复的数据,用于大数据基数统计
比如统计一个网站的UV数据
PV数据
PV(page view)页面浏览量,就是页面的点击量,用户可以重复访问
UV数据
UV(unique visitor)页面不同IP地址的人数,简单来说就是PV去重,用户重复访问也是只有1条数据
只要理解了UV和PV的区别,也就知道,当我们要求UV的时候,只需要对PV做一个去重的操作即可。
借助Redis的set来做。用户每来访问一次,就加入到set里面。这也是办法。但是如果用户的访问了是千万级别,那么这个set可能就不行了。
HyperLogLog就是用来解决这种大数据的统计,但是他也有他的缺点,就是他并不是精确的,他的标准误差是0.81%
用法其实跟set一样,来一个数据,就直接pfadd,就可以。
通过pfcount来获取统计数值,他也通过pfmerge,将两个HyperLogLog合并在一起
Streams
内存版的kafka,消息的订阅发布,是一个消息链表
消息是持久化的
每个消息都有自己的唯一表示 Stream Id,Stream解决了之前Redis通过list实现简单的消息队列中,只允许单组的问题,Stream支持多组消费
Redis大海捞针Scan
面试:如果让你从1亿个Key找,找出固定前缀的10w个key,你会怎么找?
如果我们按普通的找法,用keys指令,势必会导致业务阻塞
Redis提供了一个Scan指令,它可以无阻塞地提取出key列表,但是具有一定地重复概率,但是花费的时间会比keys指令要长,但是它不阻塞是非常可以的
Redis渐进式rehash
Java的HashMap,在需要扩容的时候,会一次性将所有元素迁移到新的容器中。
在Redis中,有时会出现很大的Key或者数量很多,那么这些Key在迁移的时候会导致线程卡顿。因此Redis在扩容的时候,采用的是渐进式rehash
扩容的时候,保留新旧的hash结构,然后在后续的定时任务和hash操作指令中,循序渐进地将旧的数据,迁移到新的hash
当最后一个元素也迁移完,就把旧的结构删除
Redis单线程为什么快
redis的网络事件处理器是基于Reactor模式,又叫做文件事件处理器。
文件事件处理器是单线程,所以才叫单线程 文件事件分派器dispath
线程切换
cpu 频繁地线程切换上下文会消耗时间
IO多路复用
文件描述符(file descriptor):简称fd
select机制
select机制可以同时监控多个fd的读写情况,调用该方法可以返回哪些fd是可读或者可写的
他是底层实现是通过一个bitmap来实现(bitmap的应用场景)
局限性:
-
bitmap的大小有限制,通常为
1024 -
我们需要扫描三个bitmap才能知道我们所知道的所感兴趣的事件,一般情况下全量集合比较大而实际发生读写事件比较少,效率比较低
因此引入了poll
poll
poll本质上和select没有区别,也是将用户传入的数组拷贝到内核空间,然后去获取感兴趣的部分
但是他没有最大连接数的限制,原因是它是基于链表来存储的
并且他把我们感兴趣的事件(event)和实际发生(revents)的事件是做了区分,分别维护起来,因此可以解决刚刚遇到的问题
select/poll地几大缺点:
- 每次调用,都需要把fd集合从内存态拷贝到内核态,当我们fd的集合比较大的时候,这个开销也会变得很大
- select支持的文件描述符数量太小了,默认是1024(bitmap的大小限制问题)
- poll虽然是用链表维护感兴趣的事件,但是依然无法解决性能的问题
epoll
全称 eventPoll,poll和slect都是通过遍历的方式操作,epoll是通过回调
底层实现:
当调用epoll_create的时候,Linux内核会创建一个eventpoll结构体,里面维护了1个红黑树和一个链表
当调用epoll_ctl的时候,就会往eventpoll里面添加事件,这样重复添加的事件就可以通过红黑树而高效地识别出出来(红黑树是O(logN))
struct eventpoll{
....
/*红黑树的根节点,这棵树中存储着所有添加到epoll中的需要监控的事件*/
struct rb_root rbr;
/*双链表中存放着将要通过epoll_wait返回给用户的满足条件的事件*/
struct list_head rdlist;
....
}
在epoll中,对于每一个事件,都会建立一个epitem结构体
struct epitem{
struct rb_node rbn;//红黑树节点
struct list_head rdllink;//双向链表节点
struct epoll_filefd ffd;//事件句柄信息
struct eventpoll *ep;//指向其所属的eventpoll对象
struct epoll_event event;//期待发生事件的类型
}
当调用epoll_wait检查是否有事件发生时,只需要检查eventpoll对象中的链表结构是否有epitem元素即可;如果链表不为空,则把发生的事件复制到用户态,同时把事件数量返回给用户
epoll的优点:
- 不用重复传递。select/poll模式下,调用的时候会传递socket句柄给内核。现在我们可以省去这一步骤,因为我们把他们的句柄存在了epitem中,内核通过调用
epoll_ctl就可以获取到句柄的列表
重写序列化协议RESP
Redis的作者认为数据库系统的瓶颈,一般不在于网络流量,而在数据库的自身内部处理逻辑上
他觉得别人的不行,所以他自己写了个通信协议RESP
RESP是Redis的序列化协议,是一种直观的文本协议,优势在于实现过程非常简单,解析性能非常好
具体的规则:
单元结束时,同一加上回车和换行符\r\n。
| 数据类型 | 开头符号 |
|---|---|
| 单行字符串 | + |
| 多行字符串 | $ |
| 整数 | : |
| 错误信息 | - |
| 数组 | * |
例如:
//单行字符串
+hello world\r\n
//整数1024
:1024\r\n
RESP之所以能做得这么简单,其实是由于现在的网络建设,硬件配置跟上来了,所以放弃了很多检验和扩展的功能
redis只需要专注于数据的高性能解析速度,所以越简单,性能会越高
Redis的持久化机制
RDB
RDB基于快照(snapshot)的方式,保存一份dump文件,进行持久化数据,是一次全量备份。
新的dump文件会把旧的dump文件替换掉,因此他的内存占用是比较小的。
触发方式:
- save:
阻塞当前redis服务器,生成快照,执行命令期间,redis不能进行读写操作
- bgsave:
fork一个子线程进行快照的生成,只有在fork的开始会短暂阻塞redis服务器,在快照生成期间不会阻塞redis服务器
👍: RBD方式持久化的优点:
-
只有一个dump文件,方便维护,轻量
-
方便备份,容灾性好
-
性能最大化,采用fork的方法可以不影响redis服务
-
面对数据集大的时候,比AOF的启动效率高
👎 RBD方式持久化的缺点:
- 安全性比AOF低,因为他是间隔触发的,因此不适合对数据要求特别严苛的场景,比如金融之类的
- fork出的子线程在生成dump的时候也会影响cpu的效率
问题概述:
- RDB过程中,是否会停止对外提供服务?
- RDB的过程数据被归改了,备份的是旧的还是新的?
- RDB是不是把内容中的所有KV复制一份,保证数据不会被修改?
Fork进程
Redis用bgsave指令Fork出一个子线程进行数据备份,不会阻塞当前业务
Cow机制
COW(Copy On Write)
redis执行bgsave的时候,本质上就是调用Linux中的fork命令,fork中实现了cow写时复制
fork一个子进程,只有在父进程发生写操作修改内存数据时,才会真正去分配内存空间,并复制内存数据,而且也只是复制被修改的内存页中的数据,并不是全部内存数据;
精确到某一时刻的数据,所以如果在备份的时候,数据被修改了,那么还是那一时刻的数据。
AOF
AOF基于日志的形式进行持久化数据,有点像mysql的binlog。不过binlog存放的是二进制数据,而AOF的日志存放的是一行一行的命令,是连续的增量备份。
流程:
- 所有的写命令都会追加到AOF缓冲中
- AOP缓冲区根据对应的策略向硬盘进行同步操作
- 随着AOF文件越来越大,需要定期对AOF文件进行重写
- 当Redis重启时,可以加载AOF文件进行数据回复
fsync
如果一个指令还未及时写入日志中,redis旧宕机,那么就意味着这个指令将永远丢失了。
Linux提供了fsync函数,可以将指定文件的内容强制从内核缓存刷到磁盘。
只要Redis进程实时调用fsync函数,就可以保证日志不丢失。
但是fsync是一个磁盘IO操作,这对于追求高性能的Redis来说并不优雅。
所以Redis提出了几种同步策略。一般是用每隔1s左右调用一次fsync
同步策略:
- 每秒同步:异步完成,效率非常高
- 每修改同步:同步完成,每发生一次数据变化都会被立即记录到磁盘中
- 不同步:交给操作系统控制
👍:AOF方式持久化的优点:
- 数据安全
- 通过append模式写文件,即使中途宕机也不会破坏已经存在的内容
👎:AOF方式持久化的缺点:
-
AOF文件比RDB文件大,且回复速度慢
-
数据集大的时候,比RDB启动效率慢
-
运行效率也没有比RDB高
重写机制
随着指令的增加,AOF文件大小也会越来越大。为了压缩文件大小,redis提供了一个文件重写的机制
写后日志
以往的数据库,都是WAL(write ahead log)写前日志。
在实际修改数据的时候,先把修改的数据写到日志,以便于故障恢复。
AOF却正好相反,他是写后日志,先执行指令,再写入日志
Redis将命令写入AOF日志时,会进行语法检查,参数校验等,如果先执行了校验这一步,那么就会影响了业务,这与Redis高性能并不符合
混合模式
redis4.x开始支持混合模式,开启方式: aof-use-rdb-preamble true
redis在重启时会采用AOF模式,因为RDB数据并不完整;在触发重写机制的时候,会把内存中的数据以RDB的方式写入AOF中,再把AOF缓冲区的数据以AOF写入到文件
Redis高可用方案
主从复制
优点:
- 提高吞吐量
- 读写分离
- 负载均衡
- 高可用
runId
用来标识redis节点。每个redis节点启动都会生成唯一的uuid,每次redis重启后,runId都会发生变化
offset
复制偏移量。当主节点有写入命令时,offset = offset + 命令的字节长度
从节点在接收到主节点发送的命令后,也会增加自己的offset,并且把自己的offset发送给主节点;主节点既保存自己的offset ,也会保存从节点的offset,通过对比offset来判断主从节点数据是否一致
repl_backlog_size
写命令缓冲区。保存在主节点上的一个固定长度的先进先出队列,默认大小时1MB
增量同步
主节点将写命令,记录到本地的内存写入缓冲区(buffer)当中,然后异步地将buffer中的指令同步到从节点
从节点一边执行同步的指令流,一边给主节点反馈自己偏移量(offset),代表自己已经同步到哪里了
全量同步/快照同步
全量同步比增量同步消耗的资源更大,首先它要在主节点进行一次bgsave,生成一个rdb文件
然后将快照文件传给需要全量同步的从节点
从节点接收到了快照文件,会立即把自己的数据清空,然后进行加载快照文件
一般新的节点刚进入到集群的时候,需要进行全量同步,或者是offset出现异常,乱序,或者是长度不够大。
之后就可以走增量同步
无盘复制
在进行全量同步的时候,这是一个磁盘IO的操作,非常耗时
如果此时系统正在进行AOF的fsync操作,然后发生快照同步,那么fsync将会被推迟执行
严重影响主节点的效率
无盘复制是让主节点直接通过Sokcet将快照内容发送到从节点,生成快照是一个遍历的过程。
主节点会一边遍历内存,一边将序列化后的内容发送到从节点
哨兵模式
在主从复制下,虽然提高Redis的读写性能,但是同样面临着故障的风险
当主节点或者从节点宕机之后,需要及时的进行故障转移。而Sentinel哨兵集群就是负责这部分工作
哨兵集群是单独部署额外为Redis集群服务的,相当于一个巡逻保安队
主观下线
是基于sentinel实例对于redis服务器做出的判断,即单个sentinel认为某个服务下线
造成下线的原因可能是网络原因、接收不到订阅
当某个sentinel认为某个服务主观下线了之后,会去通过命令和其他sentinel交流来判断这个服务器是不是真的主观下线,如果接到足够数量(可以设定)的认同意见,那么这个服务就会被判断为客观下线
客观下线
指多个sentinel实例认为同一个服务器下线了,并且通过命令互相交流之后,得出了服务器下线判断,才会认为是客观下线
只有发生客观下线时,才会发生故障迁移
Codis
国人开发的Redis高可用集群方案,是由前豌豆荚中间件开发团队开发的,他们的项目负责人刘奇在后面开发出非常厉害的分布式数据库TiDB
Codis相当于一个Redis的代理服务器,也可以做成集群的样子,提高QPS
Codis分片原理
Codis将特定的Key转发到特定的Redis实例中,默认是1024个槽位(slot),有点像Cluster
当客户端传过来key之后,会进行一次crc32运算计算hash值,然后在进行1024取模运算,分发到对应的slot中
Codis的数据同步
这里指的同步是指在Coids集群下的同步,如果只是单例Codis就不需要同步,同步的数据是指不同Codis下的slot槽位关系
一开始Codis是把这些slot槽位关系存在zookeeper上,后面也支持了etcd。
在后来Cluster集群是各自节点保存全局的槽位信息
Codis缺点
- 引入了新的中间件,带来新的技术成本
- 加入了一个代理的操作,会带来额外的网络开销
Redis Cluster
采用sharding(分片)技术,Redis Cluster是去中心化的分布式实现方案,客户端可以和集群中的任一节点连接
通过哈希的方式,将数据分片,每一个节点均分布存储一定哈希槽(哈希值)区间的数据,默认分配了0-16383的槽位 2^14次方
每一个redis节点存储的是部分数据,并不是全部数据
槽位信息存储在每个节点当中,不用像Codis用第三方来存储
👍: 优点:
- 无中心架构,支持动态扩容,对业务透明
- 具备Sentinel的监控和自动Failover(故障转移)
- 客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可
- 高性能,客户端直连redis服务,免去了proxy代理的损耗
👎:缺点:
-
运维复杂
-
只能使用0号数据库
-
不支持批量操作(pipeline管道)
-
不利于集群扩展,新增结点的时候,会从其他节点中迁移数据,因此会产生大规模的网络IO;删除节点的时候,也会发生大规模的网络IO
节点通信Gossip
在Cluster集群中,各个节点之间的通信采用的是Gossip协议
每个节点通过集群总线(cluster bus)与其他节点进行通信。
槽位定位算法
Cluster对来客户端传来的key先进行crc16算法进行hash,然后再与16384进行取模运算,得到具体的槽位
当然Cluster也支持用户强制把某个Key挂在指定的槽位上,需要通过key字符串里面的tag标志来操作
一般我们对于比较大的key可以进行分段锁的思想进行拆分,比如微博中一个大V粉丝就有几千万甚至上亿,我们可以将其拆分成key1,key2,key3这样若干个小key。然后通过强制挂在在每一个Cluster节点上面。这样就可以避免之后 Moved跳转需要迁移耗费时间。
Movced跳转
当客户端端往Cluster集群中的某个Redis节点发出查询或者修改Key的指令时
恰好这个Key不在这个Redis节点,Redis节点就会向客户端发送一个Moved跳转指令并且携带好正确redis的地址,让客户端去目标Redis获取数据
因为每一个Redis节点都由一份槽位信息,所以节点们之间知道key在谁那里
迁移
Cluster的迁移单位是槽,Redis发生迁移时,槽里面的数据将会循序渐进地从源节点转移到目标节点的地方
Redis-trib工具会首先将源节点的状态会变成migrating,目标节点是importing,代表数据流动的方向
- 从源节点获取一份全部Key的数据,通过keysinslow指令
- 源节点挨个挨个进行key进行迁移,源节点对当前地key执行dump指令,得到序列化内容
- 再通过客户端向目标节点发送restore指令携带序列化后的内容,最后删除源节点中key的数据即可
大致流程:从源节点dump获取内容--->restore到目标节点--->删除原字节内容
可能下线(PFailover)与确定下线(Failover)
Cluster是去中心化的,一个节点认为某个节点故障,并不代表所有节点都认为他故障,还得需要一次讨论的过程
Cluster采用Gossip协议来广播自己的状态以及对整个集群的认知
当一个节点发现某个节点故障的时候,广播时就会携带这条失联信息,其他节点也能收到此信息,如果大多数节点都认为确实故障了,那么那个节点才会被认为是真的故障了
Redis事务
- MULTI : 开启事务,redis会将后续的命令逐个放入队列中,然后使用EXEC命令来原子化执行这个命令系列。
- EXEC: 执行事务中的所有操作命令。
- DISCARD: 取消事务,放弃执行事务块中的所有命令。
- WATCH: 监视一个或多个key,如果事务在执行前,这个key(或多个key)被其他命令修改,则事务被中断,不会执行事务中的任何命令。
- UNWATCH: 取消WATCH对所有key的监视。
执行流程:
- 开始事务
- 指令入队
- 执行事务
事务失败
redis没有回滚机制,但是有语法检查机制
如果是语法发生失败了,则事务中的全部命令都不会生效
如果是非语法发生失败,则对应的命令不生效,其他命令会生效
原子性
原子性是指事务,要么全部成功,要么全部失败。
在redis中,语法错误的指令并不会影响其他指令的执行
因此Redis不能保障事务的原子性,只能保证事务隔离性当中的串行化,因为他们都在同一个指令队列里面执行
事务ACID,Redis能保证那几个特性
| 能否保证 | 依据 | |
|---|---|---|
| A:原子性 | 不能 | Redis不具备回滚机制 |
| C:一致性 | 不能 | 无法保证原子性,从而无法保证事务一致性 |
| I:隔离性 | 能 | Redis是将执行命令存入队列中进行执行,相当于实现了串行化隔离 |
| D:持久性 | 能 | Redis具有RDB、AOF持久化机制 |
Reids事务中Watch机制
WATCH: 监视一个或多个key,如果事务在执行前,这个key(或多个key)被其他命令修改,则事务被中断,不会执行事务中的任何命令。
翻译成人话:你在开启事务的时候对某个值进行Watch(监听),如果在执行过程中,这个指发生了变化,那么事务就会强制性地中断
Watch机制其实是提供了乐观锁的一个实现
例如:
需要对用户A的账户进行存款,在并发的情况下,要么尝试悲观锁,直接加分布式锁,但是效率会比较低
我们可以通过Watch实现乐观锁的效果,具体的意思就是,我们把业务逻辑的指令都放入事务指令队列当中,并且Watch监听这个用户的存款是否被修改过
如果被修改过了,意味着有别的线程,已经抢先修改了该用户,那么本次事务将会失败。
Redis分布式锁
setnx:
指定的key不存在时,为该key设定值
setex:
给指定key设置超时时间
会遇到的问题:
- 任务超时,锁自动释放,导致并发问题(redsson看门狗监听)
- 加锁和释放锁不是同一个线程的问题(存入uuid,线程唯一标识)
- 不可重入,使用redisson解决(实现机制类似
AQS,计数) - 异步复制可能造成锁的丢失(redisson redLock),主节点的锁同步到从节点的时候,宕机,导致锁丢失
RedLock
red lock:(类似zk)
- 顺序向节点请求枷锁
- 根据一定的超时时间来判断是不是跳过该节点
- 超过
半数节点枷锁成功并且花费时间小于锁的有效期 - 认为该锁加锁成功
分段锁
1000个A商品可以分为 20个50的key
因此我们从只能锁1个A商品,变成了可以锁20个A商品,提高了性能
将锁的粒度减小
锁冲突处理
当已经出现了线程拿到了锁,其他的线程无法加锁成功,此时有3种策略来处理枷锁失败
- 抛异常,告诉用户稍后再试
- 设置sleep,稍后再试
- 将请求转移到延时队列,稍后再试
抛异常
通过捕获异常,然后告诉给用户稍后再试
人为sleep
人为sleep其实并不好,因为sleep的期间,这个线程的其他业务逻辑都将挂起,如果后续一直拿不到锁,那么就会产生永久性地堵死。
延时队列
用zset的value来存储这些线程ID,然后score装的是过期时间。
然后通过多线程轮询的方式获取到期的任务进行处理
多线程主要的是保障单一线程过了之后,其他线程可以继续处理。
Redis的过期键的删除策略
其实问的就是,缓存过期了,如何处理
Redis采用的是 惰性过期和定期过期
惰性过期
只有当访问一个key时,才回去判断该key是否已经过期,过期则清除。
最大化的节省CPU资源,但是对内存不友好,有可能残留僵尸key
定期过期
每隔一段时间,会扫描一定数量的数据库的expires字典中一定数量的key,并清除其中已经过期的key
因为时轮询的方式,所以会比惰性过期的性能差,但是可以及时清除无用的key,有利于内存
定时过期
在设置key的过期事件的同时,为该key创建一个个定时器,让定时器在key的过期时间来临的时候,对key进行删除
这种就更为苛刻,确保每个key都能被删除,但是消耗的资源,也是三者之中最高的
Redis的缓存淘汰机制
redis在缓存的内存不足的时候,会触发缓存淘汰机制
Redis提供了6套缓存淘汰策略
noeviction:默认的淘汰机制,不会继续服务写请求除了del请求,读请求可以进行。会影响一定线上业务volatile-lru:在已经到达过期时间的key集合里面,去找最少使用的key优先被淘汰volatile-random:在已经到达过期时间的key集合里面,随机找key淘汰volatile-ttl:在已经到达过期时间的key集合里面,去找key剩余寿命ttl,ttl越小越优先被淘汰allkeys-lru:在所有key的集合里面,去找最少使用的key优先被淘汰allkeys-random:在所有key的集合里面,随机找key淘汰
allkeys-xxx 和 volatile-xxx的区别就是,前者是去所有key中找key淘汰,意味着,如果该key未到过期时间,也有机会被淘汰。
如果Redis在业务当中有一些key是永不过期,用作持久化存储的,那就用volatile-xxx,避免被淘汰掉
Redis中实现多种队列
消息队列
通过Redis中List数据结构即可实现
具体是通过lpush + rpop,或者是rpush + lpop
阻塞队列
阻塞队列,相比于消息队列,当队列里面没有数据的时候,它会阻塞等数据来,并不会返回一个异常信息
在消息队列的基础上,把rpop或者lpop改为brpop或者blpop,b = blocking
延时队列
通过Zset数据结构实现,可以用value来存储任务的名字,然后score来代表他的过期时间
当过期时间到达之后,就执行这个任务
为了避免同一个任务被多个进程消费,可以使用zrangebyscore和zrem使用lua脚本进行原子化操作。
高并发超卖问题
java的synchronize锁只能锁当前的微服务,不能锁其他分布式服务
因此即使加了synchronize之后,还是会出现超卖问题
解决办法
分布式锁
redis中 使用 setnx
简单的分布式锁
//上锁 并且设置超时时间
Boolean result = stringRedisTemplate.opsForValue().setIfAbsent("lockKey", "zhuge", 10, TimeUnit.SECONDS);
if (!result) {
return "error_code";
}
try {
//业务代码
} catch (Exception e) {
e.printStackTrace();
} finally {
//释放锁
stringRedisTemplate.delete("lockKey");
}
面对高并发的情况还是会存在超卖问题:
我设置的超时时间是10,当我的业务逻辑执行时间是15的时候;
当我执行到的第10秒的时候,这把锁已经被释放了,允许被第二个线程获取;
当我第一个线程执行完15秒的时候同时也会把这把锁给delete掉,导致第二个线程的锁被释放了,这时候第三个线程趁虚而入
这个就是由于业务执行时间 > 超时时间,而导致自己上的锁,被别人提前释放了锁而引发的问题
进一步优化:加一个客户端标识 判断是不是自己上的锁
//标识当前客户端上的锁
String clienId = UUID.randomUUID().toString();
String lockKey = "lockKey";
//上锁 并设置标识 并且设置超时时间
Boolean result = stringRedisTemplate.opsForValue().setIfAbsent(lockKey, clienId, 10, TimeUnit.SECONDS);
if (!result) {
return "error_code";
}
try {
//业务代码
} catch (Exception e) {
e.printStackTrace();
} finally {
//判断是不是当前客户端上的锁 是否存在
if (clienId.equals(StringRedisTemplate.opsForValue().get(lockKey))) {
//存在 则释放锁
stringRedisTemplate.delete("lockKey");
}
}
Redisson
protected void scheduleExpirationRenewal(long threadId) {
ExpirationEntry entry = new ExpirationEntry();
ExpirationEntry oldEntry = EXPIRATION_RENEWAL_MAP.putIfAbsent(getEntryName(), entry);
if (oldEntry != null) {
oldEntry.addThreadId(threadId);
} else {
entry.addThreadId(threadId);
try {
renewExpiration();
} finally {
if (Thread.currentThread().isInterrupted()) {
cancelExpirationRenewal(threadId);
}
}
}
}
锁续命
开启一个子线程去判断,是否持有锁,如果有则加时
scheduleExpirationRenewal 方法的嵌套调用 ,延时 1/3的时间然后调用本身,实现一个定时器的效果
protected RFuture<Boolean> renewExpirationAsync(long threadId) {
return evalWriteAsync(getRawName(), LongCodec.INSTANCE, RedisCommands.EVAL_BOOLEAN,
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return 1; " +
"end; " +
"return 0;",
Collections.singletonList(getRawName()),
internalLockLeaseTime, getLockName(threadId));
}
看门狗
默认是30秒 internalLockLeeaseTime
他不是用clientId,而是用一个ThreadId来标识
缓存数据库双写不一致
延迟双删
这个方案其实还算是在我们能接受的范围里面,即便是会一个休眠时间,一般业务也会接受。
如果我们再严苛一点,放大错误。**第二次删除缓存也失败了呢?**那其实还是会出现数据不一致的问题。
延迟双删再优化
先删缓存,再更新数据库的错误根本原因在于,删除缓存失败
因此我们可以在这个点上面进行优化,比如可以做一个重试删除机制,如果没删成功,那就重试,重试到一定次数就放弃。是不是比原先的会好一点
Canal 和 Binlog
基于数据库增量日志解析,提供增量数据订阅&消费
原理:
把自己Canal server伪装成一个mysql slave,向mysql master发送dump协议,让master也给自己进行主从复制
master接受到了dump请求之后,开始推送binlog 给Canal server
Canal 自己解析binlog 但是不进行持久化,而是保存到内存中
缓存穿透
出现场景:
大量请求redis中不存在的数据,导致请求打到db上,db崩溃
解决方案:
- 接口层增加校验,如用户鉴权校验(参数校验)
- 从缓存区不到的数据,数据库也取不到的数据可以设置为null
- 布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不会存在的数据会被这个bitmap拦截掉,从而避免了对底层存储系统的查询压力
布隆过滤器中存在的数据,可能真实也不会存在
但是布隆过滤器中不存的数据,就一定不存在
缓存击穿
出现场景:
热点key 过期(或没有被缓存的),大量的请求打到DB中
解决方案:
- 设置热点数据永远不过期
- 互斥锁(缓存雪崩),只让1个线程取查数据库,其他线程在这里进行
cas自旋
缓存雪崩
出现场景:
- 同一时间点,大量的key过期失效
- 缓存重启
解决方案:
- 缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生
- 缓存预热
- 互斥锁
缓存预热
提前把热数据塞入redis
因为我们不知道,所以我们要采用 雪崩的那一套保护方案
开发逻辑上也要规避差集,会造成击穿,穿透,雪崩
我之前被一个字节面试官提问:“如果让你设计一套线上数据预热方案,你会怎么设计?”
具体操作:
- 部分加载。将所有的数据都扔到Redis,肯定是不切实际的。但是我们可以把部分高概率的热点数据放进去,比如排行榜,首页上面的一些数据
- 在proxy层统计。nginx+lua来统计请求到kafka中,统计出热点数据
- 数据保留队列。通过storm和kafka构建数据保留队列,storm去kafka中消费数据,实施统计出每个商品的访问次数
- LRUMap二级缓存。内部维护一个LRUMap,这里就不要用Redis的那个了,又要考虑数据的一致性,直接用本地内存。因为由LRU机制,所以存在于Map里面的数据就是热数据。
感谢
老钱,钱文品老师的《Redis 深度历险:核心原理与应用实践》
图片部分来源图灵学院的公开课截图
