1. 隐马尔可夫模型定义
隐马尔可夫模型,根据字面意思。首先它一定存在马尔可夫链,即服从马尔可夫性质:无记忆性。也就是说,某一时刻的状态只受前一时刻影响,而与更早的状态无关。其次,“隐”的意义是,对某一问题,存在一个隐藏的状态序列来指导现实,但是无法形象化显示,故被称为隐状态。
下面介绍给出HMM的基本要素:状态集,观测集,隐状态序列,观测集序列,初始概率分布,状态转移概率,发射概率。
状态集Q和观测集V
所有可能的隐藏状态集Q,所有可能的观察值集V,其中n是可能的状态数,m是可能的观察数:
Q=q1,q2,,,qn,V=v1,v2,,,vm
隐状态序列I和观测集序列O
假设I是长度为T的隐状态序列,O是其对应的观测值序列:
I={i1,i2,,,iT},O={o1,o2,,,oT}
初始概率分布π
π=(πi)
其中表示在t时刻,πi=p(i1=qi),表示在t=1时刻隐状态为qi的概率。)$
隐状态转移概率A
A=[aij]n∗m
其中,aij=p(it=qj∣it−1=qi)表示t-1时刻的状态qi转移到t时刻状态qj的概率。
发射概率B
发射概率表示由隐状态得到观测状态的概率,
B=[bj(k)]n∗mbj(k)=p(ot=vk∣it=qj)
其中,bj(k)表示在状态qj发射得到vk的概率。
2. HMM可以解决的三个问题
- 概率计算,给定一个确定的HMM模型(即参数λ={A,B,π}确定)和观测序列O,求在该模型参数下观测序列的输出概率。
- 学习问题,已知观测序列O,估计模型参数λ={A,B,π},使得在该模型下观测序列的概率最大。
- 预测问题,已知模型的参数λ={A,B,π}和观测序列O,求解一组使得观测序列概率最大的隐状态序列。对应NLP中的任务有:分词,词性标注,
3. HMM解决三个问题的具体算法
对应上面的三个问题,分别有经典的算法:
1.概率计算(观察序列的概率)
(1) 暴力算法
直接的算法就是计算所有可能的概率,即:
P(O∣λ)=p(O,I∣λ)=p(O∣I,λ)p(I∣λ)
其中I=i1,i2,,,iT是隐序列,每个时刻都有N种状态,由于隐状态与观测序列无关,所以其概率为:
p(I∣λ)=πi1ai1i2ai2i3...aiT−1iT,i=1,2,3,....T
在参数和隐状态都确定的情况下,产生观测序列O的概率就是发射概率的乘积,即:
p(O∣I,λ)=bi1(o1)bi2(o2)...biT(oT)
最终的结果就是上面两者的乘积:
P(O∣λ)=πi1bi1(o1)ai1i2bi2(o2)...aiT−1iTbiT(oT),i=1,2,3,....T
算法的复杂度是TNT。
(2) 前向算法
在给定模型参数和观测序列O={o1,o2,..oT}的下,at(i)表示t时刻at=i的前向概率:
at(i)=p(o1,o2,...ot,it=qi∣λ)
由前向递推关系,at(i)等于t-1时刻所有可能的状态转移到当前状态ot的概率之和:
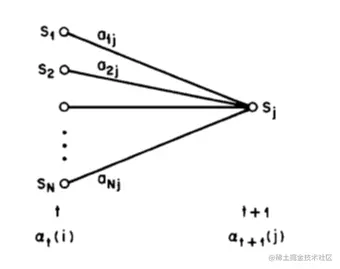 详细来说,在计算t+1时刻概率时,前向算法如下:
详细来说,在计算t+1时刻概率时,前向算法如下:
- 初始值定义:
a1(i)=πi1bi(o1),i=1,..n
- 递推公示(上图中i,j与公式中不对应):
at+1(i)=[∑j=1nat(j)aji]bji
- 在T时刻求和
P(O∣λ)=∑i=1naT(i)
(3) 后向算法
与前向算法相似,在给定观测序列O={o1,o2,..oT}下,βt(i)表示t时刻at=i的后向概率:
βt(i)=p(ot+1,ot+2,...oT,it=qi∣λ)
根据后向递推关系,βt(i)等于所有可能的t+1时刻状态转移到当前状态(同时t+1时刻发射出观测值ot+1)的概率之和。因此,后向算法计算如下:
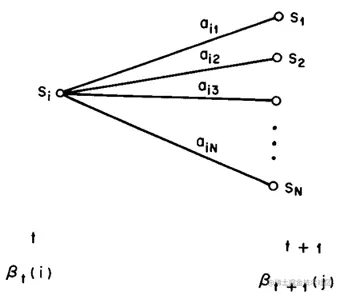
- 赋初值
βT(i)=1,i=1,2..n
- 反向递推公式:
βt(i)=∑j=1naijbj(ot+1)βt+1(j)
- 在0时刻求和
p(O∣λ)=∑i=1nπi1bj(o1)β1(i)
前向和后向算法,都是利用序列之间的递推关系,以及动态规划的算法实现。
【参考】
1. 前向算法和后向算法代码实现
2.参数估计
一般来说,隐马尔可夫的参数估计问题有两种:有监督和无监督。有监督意味着,在训练过程中,已知观测序列和隐序列,这种参数估计可以直接使用最大似然估计。无监督意味着,训练集只给了观测序列,这种情况需要使用EM算法,先假设参数,通过期望最大化来获得隐状态序列,根据隐状态序列来更新参数,不断迭直至收敛。
- 有监督(最大似然估计)
- 无监督(Baum-Welch)
3.状态预测
隐状态的转移其实是一个有向无环图,而状态预测问题就是在这个有向无环图中寻找最短路径,维特比算法就是一种利用动态规划算法在这种篱笆网络中寻找最短路径的算法。
首先引入σt(i)的概念,它表示从t=1时刻到t时刻观测状态为i的最优路径的概率值。则:
σt(i)=maxi1,i2..it−1(it=i,it−1..i1,ot..o1∣λ),i=1,2...n
递推得到t+1时刻(t+1时刻的观测值为ot+1)公式为:
σt+1(i)=maxj∈1..nσt(j)ajibi(ot+1)
为了记住上一节点状态,定义θt(i):
θt(i)=argmaxj∈1..nσt−1(j)aji,i=1,2..n
根据上面的定义,计算最优路径的算法为:
(1)初始化,
σ1(i)=πi1bi(o1),i=1,2..nθ1(i)=0
(2)根据上面公式,递推,对于=2,3,..T,
(3)终止,
P∗=maxi∈1,2..nσT(i)iT∗=argmaxi∈1,2..nθT(i)
(4)最优路径回溯,从T-1到1,
it∗=θt+1(it∗)
得到最优路径I=i1∗,i2∗,..iT∗。回溯的过程只需要从T−1开始,不需要任何计算,因为θ中保存了到达当前最优路径状态的上一状态。
【参考】
1. HMM中Viterbi算法实现例子
2. 隐马尔可夫模型


