

背景1
文件上传是个非常普遍的场景,特别是在一些资源管理相关的业务中。
文件上传的3种实现方式
- 经典的form和input上传
这种方式基本没有什么人用了
- 使用formData上传
就是用js去构建form表单的数据,简单高效
- 使用fileReader读取文件数据进行上传
这里呢,我简单写了个Demo,使用的是通过js去构建formDate这种方式,同时设置他请求头里面的Content-Type为multipart/form-data格式
<template>
<div>
<input
type="file"
@change="uploadFile"
>
</div>
</template>
<script>
import Http from '@/api/http.js'
export default {
methods: {
async uploadFile(e) {
const file = e.target.files[0]
this.sendFile(file)
},
// 文件上传方法
sendFile(file) {
let formdata = new FormData()
formdata.append('file', file)
Http.post('/upload/file', formdata, {'Content-Type': 'multipart/form-data'})
},
}
}
</script>
然后后端这里是用node写的,文件上传的位置是public下面的upload文件夹下,现在是空的,这里简单写了个读取的方法,很简单
async file() {
const {ctx} = this;
const file = ctx.request.files[0];// file包含了文件名,文件类型,大小,路径等信息
const fileName = ctx.request.files[0].filename;// file包含了文件名,文件类型,大小,路径等信息
const fileObj = fs.readFileSync(file.filepath);
// 将文件存到指定位置
fs.writeFileSync(path.join(uploadPath, fileName), fileObj);
this.success({}, '文件上传成功');
}
背景2
任何问题,量级比较小的情况下,都比较简单,比如说你做增删改查没问题,但是比方说你想做高并发、高流量、分布式就会比较难
文件上传其实很简答,但是比方说我们要上传1个G的文件或者2个G的文件件,你该怎么做?在文件比较大的时候,普通的上传方式可能会遇到以下。
-
上传耗时久。非常容易卡顿
-
由于各种网络原因上传失败,且失败之后需要从头开始。比方说我上传1个G的文件,刷新页面,或者说网路报错,可能之前已经上传的200m的内容呢,就白费了
思路
解决方案呢,就是切片+秒传
那么我把这个文件呢,切成1m甚至100k,依次上传,就算中间有中断,但是之前已经上传的区块呢,后端是可以存起来的,下一次我只需要接着上一次的进度上传就可以了。二一个就是浏览器发送请求是可以并发的,多个请求同时发送,提高了传输速度的上限。
秒传指的是文件在传输之前计算其内容的散列值,也就是 Hash 值,将该值传到后台,如果后台存在 Hash 值一致的文件,认为该文件上传完成。
该方案很巧妙的解决了上述提出的一系列问题,也是目前资源管理类系统的通用解决方案。
1. 切片上传
文件切片和核心是使用 Blob 对象的 slice 方法
首先我先定义单个切片的大小,对之前的逻辑稍作改造,如果文件大小小于一个切片就直接上传,如果大于一个切片,那么就走切片上传的逻辑
逻辑呢,大体是这样的,拿到文件之后呢,我们先在这里计算一下这个文件的hash值,然后再执行cutBlob切片这个方法,这个cutBlob无非就是创建了一个数组,然后通过file.slice把文件切成一个个的切片,最终切成多少块是和你的size是相关的。我在这里定义了一个切片的大小,2m,最终呢,放进chunk这个数组当中,切片完成之后呢,再把这些切片依次上传到后端,那么后端呢收到请求以后,首先先创建一个以这个文件hash命名的文件夹,在文件夹下依次生成对应的切片
//前端
<script>
import Http from '@/api/http.js'
import SparkMD5 from 'spark-md5'
export default {
data() {
return {
remainChunks: [], // 剩余切片
chunkSize: 5 * 1024 * 1024 // 切片大小
}
},
methods: {
async uploadFile(e) {
const file = e.target.files[0]
if (file.size < this.chunkSize) {
//简单上传
this.sendFile(file)
} else {
//切片上传
this.createFileMd5(file).then(async hash => {
const chunkInfo = await this.cutBlob(file, hash)
this.remainChunks = chunkInfo.chunkArr
for (let i = 0; i < this.remainChunks.length; i++) {
this.sendChunk(this.remainChunks[i])
}
})
}
},
// 单个文件上传方法
sendFile(file) {
let formdata = new FormData()
formdata.append('file', file)
Http.post('/upload/file', formdata, {'Content-Type': 'multipart/form-data'})
},
// 切片上传计算文件的hash值
createFileMd5(file) {
const spark = new SparkMD5.ArrayBuffer() // 文件hash处理
return new Promise((resolve) => {
const reader = new FileReader()
reader.readAsArrayBuffer(file)
reader.addEventListener('loadend', () => {
const content = reader.result
// 生成文件hash
spark.append(content)
const hash = spark.end()
resolve(hash)
})
})
},
// 对文件进行切片
cutBlob(file, hash) {
const chunkArr = [] // 所有切片缓存数组
const chunkNums = Math.ceil(file.size / this.chunkSize) // 切片总数
return new Promise((resolve) => {
let cur = 0
for (let i = 0; i < chunkNums; i++) {
// 如果已上传则跳过
let contentItem = file.slice(cur, cur + this.chunkSize)
chunkArr.push({
index: i,
hash,
total: chunkNums,
name: file.name,
size: file.size,
chunk: contentItem
})
cur += this.chunkSize
}
resolve({
chunkArr
})
})
},
// 切片上传
async sendChunk(item) {
let formdata = new FormData()
formdata.append('file', new File([item.chunk], item.name))
formdata.append('hash', item.hash)
formdata.append('index', item.index)
formdata.append('total', item.total)
formdata.append('name', item.name)
// eslint-disable-next-line max-len
await Http.post('/upload/fileChunk', formdata, {'Content-Type': 'multipart/form-data'})
},
}
}
</script>
//后端
async fileChunk() {
const {ctx} = this;
const {index, hash, total} = ctx.request.body;
const file = ctx.request.files[0];// file包含了文件名,文件类型,大小,路径
等信息
const fileName = hash + '-' + index;// file包含了文件名,文件类型,大小,路径等信息
const fileObj = fs.readFileSync(file.filepath);
// 将文件存到指定位置
if (!fs.existsSync(path.join(uploadPath, hash))) {
fs.mkdirSync(path.join(uploadPath, hash));
}
fs.writeFileSync(path.join(uploadPath, hash, fileName), fileObj);
const files = fs.readdirSync(path.join(uploadPath, hash, '/'));
if (files.length != total || !files.length) {
this.success({}, '切片上传成功');
return;
}
}
此时,被切片的文件已经成功的上传到了后端的指定位置。并生成了以文件的hash值为命名的文件夹,文件夹下包含上传的文件切片。
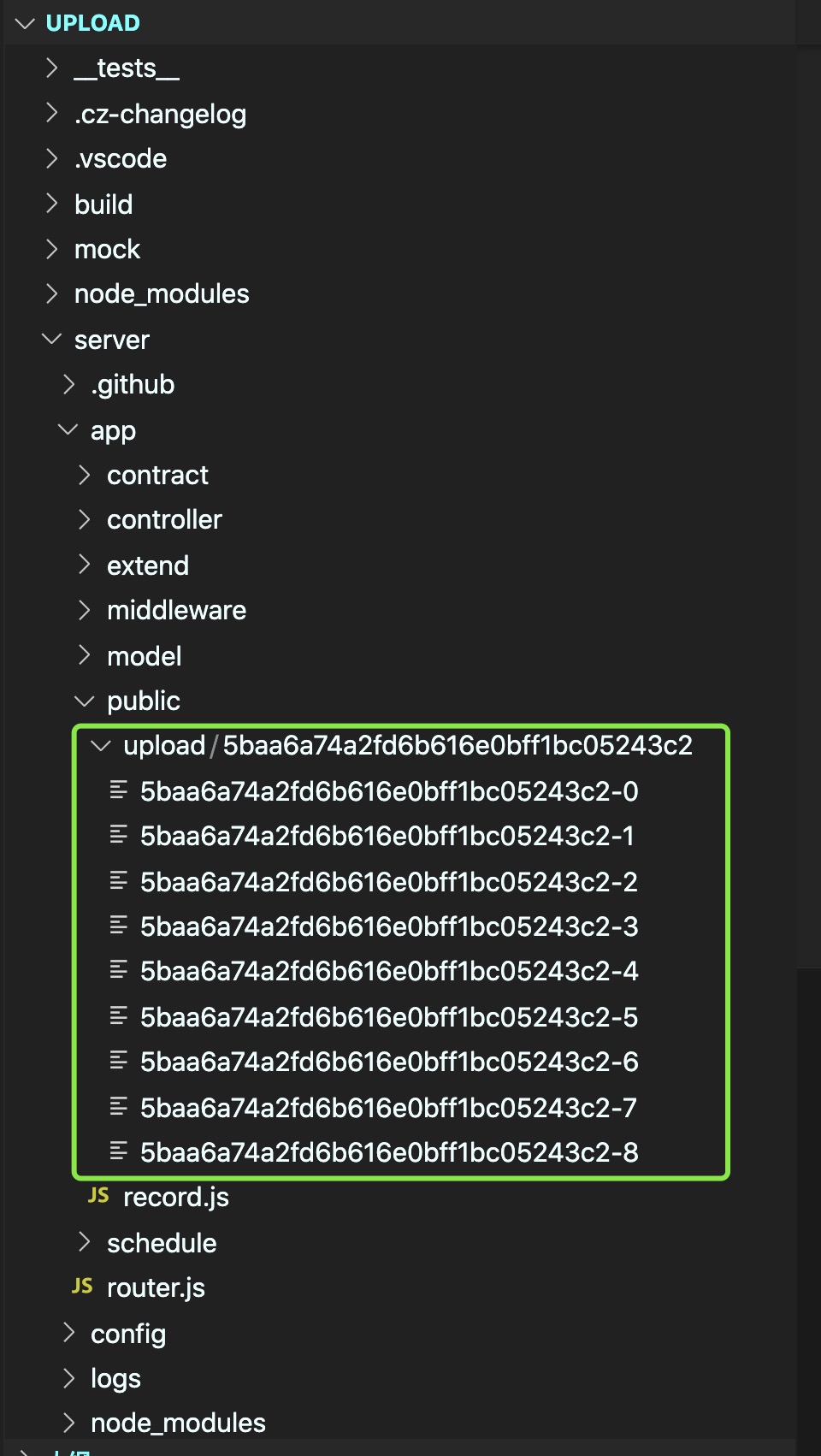
紧接着我们需要对文件进行合并
2. 文件合并
-
前端发送切片完成后,发送一个合并请求,后端收到请求后,将之前上传的切片文件合并。
-
后台记录切片文件上传数据,当后台检测到切片上传完成后,自动完成合并。
-
创建一个和源文件大小相同的文件,根据切片文件的起止位置直接将切片写入对应位置。
这三种方案中,前两种都是比较通用的方案,且都是可行的,方案一的好处就是流程比较清晰,代价在于多发了一次请求,就是你需要去多写一个回调函数。方案二比方案一少了一次请求,而且呢,逻辑也都挪到了后端去做,是一种比较好的方式。
方案三比较好的,相当于直接省略了文件合并的步骤,速度比较快。但是不用语言的实现难度不同。如果没有合适的 API 的话,自己实现的难度很大。
那么这里呢,我们改造下他的后端,在切片上传的方法中,增加一个判断,首先读取对应hash值文件夹下面的文件,如果个数与切片个数不符,就正常返回,如果文件个数等于切片个数,就执行merge的方法
async fileChunk() {
const {ctx} = this;
const {index, hash, total} = ctx.request.body;
const file = ctx.request.files[0];// file包含了文件名,文件类型,大小,路径等信息
const fileName = hash + '-' + index;// file包含了文件名,文件类型,大小,路径等信息
const fileObj = fs.readFileSync(file.filepath);
// 将文件存到指定位置
if (!fs.existsSync(path.join(uploadPath, hash))) {
fs.mkdirSync(path.join(uploadPath, hash));
}
fs.writeFileSync(path.join(uploadPath, hash, fileName), fileObj);
const files = fs.readdirSync(path.join(uploadPath, hash, '/'));
if (files.length != total || !files.length) {
this.success({}, '切片上传成功');
return;
}
this.fileMerge()
}
async fileMerge() {
const {ctx} = this;
const {total, hash, name} = ctx.request.body;
const dirPath = path.join(uploadPath, hash, '/');
const filePath = path.join(uploadPath, name); // 合并文件
// 已存在文件,则表示已上传成功
if (fs.existsSync(filePath)) {
this.success({}, '文件已存在');
return;
// 如果没有切片hash文件夹则表明上传失败
} else if (!fs.existsSync(dirPath)) {
this.error(-1, '文件上传失败');
return;
} else {
// 创建文件写入流
const fileWriteStream = fs.createWriteStream(filePath);
for (let i = 0; i < total; i++) {
const chunkpath = dirPath + hash + '-' + i;
const tempFile = fs.readFileSync(chunkpath);
fs.appendFileSync(filePath, tempFile);
fs.unlinkSync(chunkpath);
}
fs.rmdirSync(path.join(uploadPath, hash));
fileWriteStream.close();
}
}
3. 限制请求个数
在尝试将一个 5G 大小的文件上传的时候,发现前端浏览器出现卡死现象,原因是切片文件过多,浏览器一次性创建了太多了 xhr 请求。这是没有必要的,拿 chrome 浏览器来说,默认的并发数量只有 6,过多的请求并不会提升上传速度,反而是给浏览器带来了巨大的负担。因此,我们有必要限制前端请求个数。
这里呢,我们加一个js 异步并发控制,这个异步并发控制的逻辑是:运用 Promise 功能,定义一个数组 fetchArr,每执行一个异步处理往 fetchArr 添加一个异步任务,当异步操作完成之后,则将当前异步任务从 fetchArr 删除,则当异步 fetchArr 数量没有达到最大数的时候,就一直往 fetchArr 添加,如果达到最大数量的时候,运用 Promise.race Api,每完成一个异步任务就再添加一个,最后执行。
上面这逻辑刚好适合大文件分片上传场景,将所有分片上传完成之后,执行回调请求后端合并分片。
// 请求并发处理
sendRequest(arr, max = 6) {
let fetchArr = []
let toFetch = () => {
if (!arr.length) {
return Promise.resolve()
}
const chunkItem = arr.shift()
const it = this.sendChunk(chunkItem)
it.then(() => {
// 成功从任务队列中移除
fetchArr.splice(fetchArr.indexOf(it), 1)
}, err => {
// 如果失败则重新放入总队列中
arr.unshift(chunkItem)
console.log(err)
})
fetchArr.push(it)
let p = Promise.resolve()
if (fetchArr.length >= max) {
p = Promise.race(fetchArr)
}
return p.then(() => toFetch())
}
toFetch()
},
4. 断点续传
切片上传有一个很好的特性就是上传过程可以中断,不论是人为的暂停还是由于网络环境导致的链接的中断,都只会影响到当前的切片,而不会导致整体文件的失败,下次开始上传的时候可以从失败的切片继续上传。
这里需要我们在每次开始上传前,去询问一遍后端以及上传的切片数。并且返回已经上传成功的切片次序的数组,那么后续再次切片的时候呢,就跳过这些已经上传完成的切片。后端呢,也新增一个查询切片文件是否已上传的方法,去读取对应hash值文件夹下已上传的文件的后缀,并返回给前端。
//前端改造,新增询问下载进度的接口
sendBlob() {
this.createFileMd5(this.file).then(async hash => {
let {data} = await this.getUploadedChunks(hash)
let uploaded = data.data.chunks
this.uploadedChunkSize = uploaded.length
const chunkInfo = await this.cutBlob(this.file, hash, uploaded)
this.remainChunks = chunkInfo.chunkArr
this.sendRequest(this.remainChunks, 6)
})
}
//后端改造,新增询问下载进度的接口
checkSnippet() {
const {ctx} = this;
const {hash} = ctx.request.body
// 切片上传目录
const chunksPath = path.join(uploadPath, hash, '/')
let chunksFiles = []
if (fs.existsSync(chunksPath)) {
// 切片文件
chunksFiles = fs.readdirSync(chunksPath)
}
let chunks = chunksFiles.length ? chunksFiles.map(v => v.split('-')[1] - 0) : []
this.success({chunks}, '查询成功')
}
5. 秒传
秒传指的是文件如果在后台已经存了一份,就没必要再次上传了,直接返回上传成功。在体量比较大的应用场景下,秒传是个必要的功能,既能提高用户上传体验,又能节约自己的硬盘资源。
秒传的关键在于计算文件的唯一性标识。
文件的不同不是命名的差异,而是内容的差异,所以我们将整个文件的二进制码作为入参,计算 Hash 值,将其作为文件的唯一性标识。
这个具体实现呢,和之前的断点续传也很类似,就是在每次开始上传前,去询问一遍后端,当前文件是否已经上传过。所以说这里呢,我们对前后端这里稍作改造,把这个逻辑合并到之前断点续传的方法当中,首先需要我么在文件合并成功的方法当中呢,记录下已经上传成功的文件的hash值,我是记录在public文件夹下面的record.js这个文件当中的,你也可以记录到数据库当中,我这里就简单实现一下。同时改造下查询分片是否上传成功的方法,先查询下当前文件对应的hash值是否存在,如果存在,则直接返回符合秒传的条件,前端则根据条件,跳出后续上传的逻辑,并更新进度。
//后端改造,新增询问下载进度的接口
checkSnippet() {
const {ctx} = this;
const {hash} = ctx.request.body
let content = fs.readFileSync(path.join('app/public/record.js'), 'utf-8').split('\n');
if (content.includes(hash)) {
this.success({hasUpload: true, chunks: []}, '已上传')
return
}
// 切片上传目录
const chunksPath = path.join(uploadPath, hash, '/')
let chunksFiles = []
if (fs.existsSync(chunksPath)) {
// 切片文件
chunksFiles = fs.readdirSync(chunksPath)
}
let chunks = chunksFiles.length ? chunksFiles.map(v => v.split('-')[1] - 0) : []
this.success({chunks, hasUpload: false}, '查询成功')
}
6. 整体流程
最后再梳理一遍整体的流程
-
获得文件后,使用 Blob 对象的 slice 方法对其进行切割,并封装一些上传需要的数据,文件切割的速度很快,不影响主线程渲染。
-
计算整个文件的 MD5 值。
-
获得文件的 MD5 值之后,我们将 MD5 值以及文件大小发送到后端,后端查询是否存在该文件,如果不存在的话,查询是否存在该文件的切片文件,如果存在,返回切片文件的详细信息。
-
根据后端返回结果,依次判断是否满足“秒传” 或是 “断点续传” 的条件。如果满足,更新文件切片的状态与文件进度。
-
根据文件切片的状态,发送上传请求,由于存在并发限制,我们限制 request 创建个数,避免页面卡死。
-
后端收到文件后,首先保存文件,保存成功后记录切片信息,判断当前切片是否是最后一个切片,如果是最后一个切片,记录文件信息,认为文件上传成功,清空切片记录。
7. 扩展
其实除了上述流程以外,还有很多值得改进的地方,比如:
-
文件 Hash 值的计算是 CPU 密集型任务,线程在计算 Hash 值的过程中,页面处于假死状态。所以,该任务一定不能在当前线程进行,我们使用 Web Worker 执行计算任务
-
根据当前的网络情况动态的调整切片的大小,类似于 TCP 的拥塞控制
-
并发重试,切片上传的过程中,我们有可能因为各种原因导致某个切片上传失败,比如网络抖动、后端文件进程占用等等。对于这种情况,最好的方案就是为切片上传增加一个失败重试机制。由于切片不大,重试的代价很小,我们设定一个最大重试次数,如果在次数内依然没有上传成功,认为上传失败。
-
多人上传同一个文件,只要其中一人上传成功即可认为其他人上传成功
