

本文已参与「掘力星计划」,赢取创作大礼包,挑战创作激励金。
0x0、引言
金九银十眨眼就过,下周就十一月份了,十月一篇文章没写,羞愧难当,刚好有素材,赶紧水上一篇~
严正声明:
本文仅用于记录爬虫技术研究学习,不会提供爬取脚本,所爬数据已删且未传播,请勿用于非法用途,如有其它非法用途造成损失,于本文无关。
对爬虫学习感兴趣的朋友可移步至我之前写的:《Python爬虫从入门到入狱》学习札记
0x1、起因
下班路上,日常刷着某招聘APP,手滑点到课程Tab,哟哟,课程还挺多的啊,质量看着还好,真不错。
突然想起上一年转发了N个群推广,白嫖到的全年VIP,应该很多朋友跟我一样都薅了一波,且加入了收藏不看吃灰系列~
总有一天,会学习的,对吧,但是,这个VIP年卡TM的快过期了!!!
别慌,问题不大,过期就过期嘛,大不了续费,十几块的奶茶钱,咱还是出得起的~
瞥了一眼续费要多少钱:
卧槽,这价格...TM还好啊,嘴上 (硬气),手却 (不争气) 地开始长截图起来了...
因为贫穷,连知识都要离开我吗?不,你们不能走!!!
截了几张长图后,我开始觉得有点不对劲:
几分钟才截一张图,这么多课程和章节,我截到猴年马月呢?我电源键按烂了,可能都没截完吧?
而且一直拿着手机截图,其他事都不能干,手滑万一按错,把闪光灯给点亮了,在拥挤的地铁里,就尴尬了...
作为一个喜欢偷懒的开发仔,肯定是得想想办法解放双手,成就自己的梦想的,说干就干!
0x2、点点点好像不太行
把点点点的操作交给程序来完成,那得先捋下截图的流程:
循环往复途中三步,直到截玩所有课程,流程看着很简单,手机自动点点点方案四选一:
- 无障碍服务
- py脚本 + adb命令
- 自动化测试工具:Appium、airtest
- autojs
打开Android手机,开发者工具 → 显示布局和边界,能看到①②都是原生控件,很好定位到控件做模拟点击/获取文本。
点击流程、逻辑处理啥的还好,最大的难点是「长截图」,据我了解上面这些工具应该都是不支持长截图的,所以得自己去实现长截图,一般的方案是:
多次滑动截图 → 多张截图拼接生成长截图
这里的处理挺繁琐的,滑动距离计算、图片拼接后的准确率(内容重叠、缺失)等,又吃力又不讨好的事,咋不干,so,换个方案吧,抓包走一波~
0x3、抓包好像也不太行
先抓PC端,23333,请求头加密劝退~
再抓下Android端,23333,一样的请求头,再次劝退~
淦,血压飙升!那就解密一波?看了下是360加固,所以接下来是 脱壳逆向 环节?
23333,开个玩笑,标题都说简单了,肯定有更简单的方法,那就是:点点点 + 抓包
0x4、点点点+抓包就行了
从移动端的点点点,换到了PC端网页的点点点,常规技术方案:
Selenium和Pyppeteer,后者依赖Chromium内核,无需繁琐的环境配置,相比起前者效率也高一些。这里使用前者,无他,只是因为我比较熟而已。
玩法也很简单:
利用查找元素的API定位元素 → 模拟点击 → 模拟输入 → 获取特定标签中的文本 → 保存到本地文件
好像有点过分容易和无脑了?那加一点点技术含量:
配合抓包工具 → 拦截页面发起的请求 → 过滤筛选出所需数据 → 保存到本地文件
此处使用 browsermob-proxy 进行拦截,接下来开始说下爬取流程~
1、工具准备
Selenium→pip install selenium命令直接装,安装不了的自己百度;chromedriver.exe→ Chrome看下浏览器版本,官网对版本直接下:chromedriver,放工程目录中;browsermob-proxy-2.1.4→ Github仓库 直接下,同样解压放工程目录中;
其它用到的库pip直接装~
2、初始化代理服务器和浏览器
import os
from browsermobproxy import Server
from selenium import webdriver
import time
# 初始化代理
def init_proxy():
server = Server(os.path.join(os.getcwd(), r'browsermob-proxy-2.1.4\bin\browsermob-proxy'))
server.start()
return server.create_proxy()
# 初始化浏览器,传递代理对象
def init_browser(proxy):
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless') # 无头浏览器
chrome_options.add_argument('ignore-certificate-errors') # 无视证书验证
chrome_options.add_argument('--start-maximized') # 开始时直接最大屏幕
# 设置用户数据目录,避免每次都要重新登陆
chrome_options.add_argument(r'--user-data-dir=D:\ChromeUserData')
chrome_options.add_argument('--proxy-server={0}'.format(proxy.proxy)) # 设置请求的代理
return webdriver.Chrome(options=chrome_options)
if __name__ == '__main__':
server_proxy = init_proxy()
browser = init_browser(server_proxy)
server_proxy.new_har("test", options={
'captureContent': True,
'captureHeaders': True
})
browser.get("https://www.baidu.com")
time.sleep(2)
catch_result = server_proxy.har
for entry in catch_result['log']['entries']:
print(entry['response']['content'])
# 用完记得关
server_proxy.close()
browser.close()
接着运行稍等片刻后,可以看到控制台打印出爬取到的日志信息:
Tips:可以对catch_resul下断点调试,记住想要数据的key,就不用百度啦~
代理和浏览器支棱起来了,接着就要开始点点点了~
3、模拟登陆
浏览器打开首页,定位到登录标签:
查找有没有这个标签,有就说明未登录,执行登录逻辑,点一下这个按钮,出现下述弹窗:
切换到账户密码登录,定位到输入手机号码与密码的结点,输入手机密码,然后点击登录。
有时由于风控或者其他因素,会弹出验证码校验,如:
一个简单的处理方式:在点击登录后预留一定的时间,你自己手动去完成验证。
因为上面设置了 Chrome浏览器的用户数据目录,登录一次过后就处于登录态了,后续打开浏览器都不用登录了,当然顶号、Cookie过期时可能需要再手动调用下登录方法。
写个简单代码示例~
def login():
browser.get(base_url)
time.sleep(2)
not_login_element = browser.find_element_by_class_name("not-login-item")
if not_login_element is None:
print("处于登录状态,直接退出")
else:
# 点击登录
not_login_element.click()
time.sleep(1)
# 切换TAB到账号密码登录
browser.find_elements_by_class_name("account-text")[1].click()
# 输入账号密码
input_items = browser.find_elements_by_class_name("input-item")
input_items[2].find_element(By.TAG_NAME, 'input').send_keys("xxx")
input_items[3].find_element(By.TAG_NAME, 'input').send_keys("xxx")
# 点击登录
browser.find_element_by_class_name("login-btn").click()
# 有时可能会出现验证码弹窗,预留足够时间给你点
time.sleep(20)
# 用完就关
proxy.close()
browser.close()
4、获取所有课程ID
首页底部的专栏,找到所有的课程:
###
F12打开开发者工具,切换到Network选项卡,清空,然后刷新页面,随便找一个课程名,搜索下,很好定位:
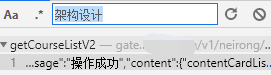

没有做分页,数据都在一条Json中返回了,所以只需抓一次,全选复制Json,保存到本地,做下解析,提取出所有课程id,简单代码示例如下:
# 课程列表与id
def load_all_course_list():
with open(lg_course_item_json, 'r+', encoding='utf-8') as f:
content_dict = json.load(f)
c_list = []
for course in content_dict['content']['contentCardList'][22]['courseList']:
c_list.append(str(course['id']))
cp_utils.write_list_data(c_list, course_id_list_file)
部分处理结果如下:
还好就101个课程,不算太多,接着到获取每个课程里的章节。
5、获取章节ID
随手打开一个章节,清空,刷新页面,随意搜一个标题,同样很好定位:
拿到课程id有什么用呢?遍历上面的课程id列表,一直替换url中的courseID,就是每个课程的url:
course_template_url = 'https://xxx/courseInfo.htm?courseId={}#/content'.format('课程id')
browser.get() 直接加载上述链接,这里直接保存返回的json,因为考虑到某些字段后续可能还有用,简单代码示例如下:
# 加载课程列表
def load_course_list():
course_id_list = cp_utils.load_list_from_file(course_id_list_file)
for course_id in course_id_list:
proxy.new_har("course_list", options={
'captureContent': True,
'captureHeaders': True
})
browser.get(course_template_url.format(course_id))
time.sleep(random.randint(3, 30))
result = proxy.har
for entry in result['log']['entries']:
if entry['request']['url'].find('getCourseLessons?courseId=') != -1:
content = entry['response']['content']
# 筛选正确的请求
if len(str(content)) > 200:
text = json.loads(content['text'])
course_name = text['content']['courseName']
json_save_path = os.path.join(course_json_save_dir, course_name + '.json')
with open(json_save_path, "w+", encoding='utf-8') as f:
f.write(json.dumps(text, ensure_ascii=False, indent=2))
print(json_save_path, " 文件写入完毕...")
proxy.close()
browser.close()
可以看到陆续保存的json文件~

6、获取文章内容
如法炮制,关键词搜索:

章节URL:
article_template_url = 'https://xxx/courseInfo.htm?courseId={}#/detail/pc?id={}'.format(course_id, theme_id))
同样循环遍历,解析返回数据中textContent字段内容,保存为html即可,比较简单,就不贴代码了。
数据量不大,半天基本可以爬完,打开保存后的HTML发现,都乱码了:
小问题,指定下编码方式即可,直接把网页内容塞到注释区域即可:
<html>
<meta http-equiv="Content-Type" content="text/html;charset=utf-8">
<head><title></title></head>
<body>
<!--复制到这里-->
</body>
</html>
好的,课程都爬下来了,你可能会说:就这?也太简单了,我也是这样觉得的,那再加亿点点细节吧!!!
0x5、加亿点点细节
1、HTML转Markdown
没有样式的HTML,打开后真的是丑得不行,而且不好转存,那我们把它转成Markdown吧~
人生苦短,我用Python,遇到需求不要慌,先找下有没有轮子,没有再自己造,这不,随手一搜就找到了:
pip命令行直接装,写段demo,试试看转换效果:
import cp_utils
import html2text as ht
if __name__ == '__main__':
text_marker = ht.HTML2Text()
content = cp_utils.read_content_from_file('test.html')
cp_utils.write_str_data(text_marker.handle(content), "after.md")
转换结果看着还好,目前是没问题的,接着就是遍历文件,批处理转换一波了~
import cp_utils
import os
import html2text as ht
lg_save_dir = os.path.join(os.getcwd(), "lg_save")
course_json_save_dir = os.path.join(lg_save_dir, "course_json")
article_save_dir = os.path.join(lg_save_dir, "article")
md_save_dir = os.path.join(lg_save_dir, "md")
if __name__ == '__main__':
text_marker = ht.HTML2Text()
cp_utils.is_dir_existed(lg_save_dir)
cp_utils.is_dir_existed(course_json_save_dir)
cp_utils.is_dir_existed(article_save_dir)
cp_utils.is_dir_existed(md_save_dir)
course_dir_list = cp_utils.fetch_all_file(article_save_dir)
for course_dir in course_dir_list:
course_name = course_dir.split("\\")[-1]
for article_path in cp_utils.fetch_all_file(course_dir):
article_name = article_path.split("\\")[-1]
for lesson_path in cp_utils.filter_file_type(article_path, ".html"):
lesson_name = lesson_path.split("\\")[-1].split(".")[0]
after_save_dir = os.path.join(md_save_dir,
course_name + os.path.sep + article_name + os.path.sep)
cp_utils.is_dir_existed(after_save_dir)
md_file_path = os.path.join(after_save_dir, lesson_name + '.md')
cp_utils.write_str_data(text_marker.handle(cp_utils.read_content_from_file(lesson_path)),
md_file_path)
静待片刻后,所有文件转换完成,配合一波我之前写的 hzwz-markdown-wx MD转公号HTML样式脚本:
排版一下子就高大上起来了,2333,当然,只是开开玩笑,并不会这样做大死,尊重作者劳动成果~
2、图片处理
md中的图片都是用的站点的图床,有些同学可能有下面的需求:
需求一:有离线看文档的需求
小case,解析md文件,下载图片到本地,替换原链接即可,顺带添加一波md标题(文件名)。
注意:Markdown中本地链接需使用 相对路径,而不能 绝对路径!
简单代码示例如下:
# 匹配图片URL的正则
pic_pattern = re.compile(r'!\[.*?\]\((.*?)\)', re.S)
def process_md(md_path):
content = cp_utils.read_content_from_file(md_path)
# 添加一级标题
title = md_path.split('.')[0]
new_content = "# {}\n{}".format(title, content)
# 查找所有图片链接
pic_result = pic_pattern.findall(new_content)
for pic in pic_result:
# 本地图片绝对路径
pic_file_path = os.path.join(pic_save_dir, pic.split('/')[-1])
# 图片相对路径
pic_relative_path = "..{}pic{}{}".format(os.path.sep, os.path.sep, pic.split('/')[-1])
# 下载图片
cp_utils.download_pic(pic_file_path, pic)
# 把MD文件中资源URL替换为本地相对路径
new_content = new_content.replace(pic, pic_relative_path)
# 保存md文件
cp_utils.write_str_data(new_content, os.path.join(md_new_save_dir, title + '.md'))
运行后,才下了一张图就报错了:
我去,为啥图片名会有回车???看下md文件报错处:
我服,html2text 转换的bug,回头给作者提下issues,当下得先想办法解决这个问题。
- 治标:下载不报错,图片下载时替换下url中的\n为空白,但是修改md文件时还是得处理;
- 治本:找出这种异常的图片链接的位置,去掉\n回车。
这里肯定是治本的,好了,那如何定位并替换掉多余的回车呢?请出字符串处理神器 → 正则表达式,解法有下述几种:
- ①
re.findAll() + str.replace()
# 匹配异常图片的正则,re.M 代表支持多行匹配
error_pic_pattern = re.compile(r'http.*?\n.*?\..*?\)', re.M)
# 获取匹配到的所有异常图片,用去掉\n后的字符串,来替换原本的字符串
error_pics = error_pic_pattern.findall(new_content)
for error_pic in error_pics:
new_content = new_content.replace(error_pic, error_pic.replace("\n", ""))
print(new_content)
- ②
re.sub() + 匹配后的数据替换
sub()函数支持修改的地方使用函数方法,所以可以把方法①简化成这样:
# 去掉回车的函数
def trim_enter(temp):
return temp.group().replace("\n", "")
new_content = error_pic_pattern.sub(trim_enter, new_content)
- ③
re.sub() + 反向引用
反向引用:指定替换结果的过程中,可引用原始字符串中匹配到的内容。
re.sub的匹配结果也有和re.match一样的分组,因此只需在替换表达式中引用分组结果即可,引用方式有下述两种:
- \number → 如\1,表示匹配结果中第一个分组
- \g<number> you → 作用同上,好处是可以避免歧义,入\10表示第一个分组后加0还是第是个分组;
所以可以用下述代码进行替换:
error_pic_pattern_n = re.compile(r'(http.*?)(\n)(.*?\.\w+\))', re.M)
# 就是划分成了三个分组,然后把1、3分组拼接结果作为替换结果
new_content = error_pic_pattern_n.sub(r"\g<1>\g<3>", new_content)
修改完后,本地打开md文件,验证下图片可以正常查看即可~
需求二:想放到一些XX笔记中,又怕以后有防盗链啥的
直接传第三方CDN,替换下本地图片URL就好,帮人帮到底,贴个七牛云上传图片的简单代码示例吧~
# 七牛CDN配置信息
qn_access_key = 'xxx'
qn_secret_key = 'xxx'
# 上传图片到七牛云
def upload_qn_cdn(file_path):
with open(file_path, 'rb') as f:
data = f.read()
# 构建鉴权对象
q = Auth(qn_access_key, qn_secret_key)
# 上传空间名称
bucket_name = '存储空间名称'
key = 'lg/' + str(int(round(time.time() * 1000))) + '_' + f.name
token = q.upload_token(bucket_name, key, 3600 * 24)
ret, info = put_data(token, key, data)
print(ret)
print(info)
if info.status_code == 200:
full_url = 'http://qiniupic.coderpig.cn/' + ret["key"]
return full_url
需求三:想弄成PDF,方便自己查看
越来越离谱...自己动手丰衣足食,搜下:Python Markdown转PDF 找个库就好~
0x6、小结
本节过了一下 某站点课程-文字部分 的爬取流程,还挺简单的,你可能会问,怎么没有音视频爬取?
抱歉,可能是我真的太菜了,搞了两个小时都没折腾出来,而且也没有太强的爬取欲望,就算了。
瞄了眼有个Java的库,感兴趣的可以自行研究下加密规则:lagou-course-downloader
另外说一点,别觉得Selenium模拟就很安全,这样启动的浏览器有几十个特征可以被网站通过JavaScript嗅探到。
好吧,就说这么多,感谢~
