

探索性数据分析(EDA)是一种分析数据集以总结其主要特征的方法,通常使用统计图形和其他数据可视化方法。可以使用或不使用各种统计模型,但主要是EDA用于查看数据在正式建模或假设测试任务之外能告诉我们什么。
猜猜看...总是...

图片来自unsplash.com
为什么我首先要做任何EDA?
我相信一个更合适的问题会是。
在哪些情况下我不应该使用EDA?
EDA是数据科学的关键步骤之一,它允许我们对我们所处理的数据进行一定的洞察和统计测量。这对无数的用户来说是至关重要的,包括业务经理、利益相关者、数据科学家等。
对于数据科学家来说,EDA有助于定义和完善我们的重要特征变量选择,这将被用于尚未训练的机器学习模型。
在这个故事中,为了演示的目的,我们将使用一些FitBit数据。
健身追踪器数据是数据科学家、统计学家、医学专家、生理学家和心理学家的一个热门研究领域,这里仅举几个学术研究领域。检测复杂的时间序列数据中的关系,如FitBit健身追踪器数据,可以是建立日常生活模式的一种方式,也是检测这些模式的偏差的一种方式。
一个好的EDA可以帮助发现这些...
分析
对Fitbit数据进行了彻底的分析。关键的发现被强调和讨论。本文提供的分析是利用从33个不同用户那里收集的940个数据点进行的。
在阅读这个故事的时候,我希望能向你传递推动代码编写的推理以及逻辑。
首先,为了了解这些用户的生活方式,我们根据用户的活动水平绘制分钟和距离。
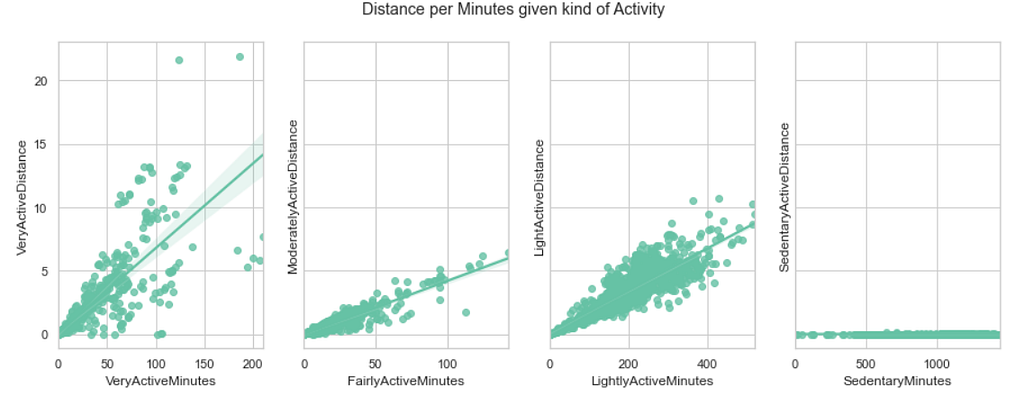
正如预期的那样,非常活跃_的人在较短的时间内走完了距离(也就是说,他们有较大的速度,由较陡的回归线表示)。一个有点出乎意料的结果是,"轻度活动分钟"比 "中度_活动分钟"的速度更大。如果知道这种分类是如何进行的,以便真正理解 "轻度 "活动和 "中度 "活动之间的区别,那就很有意思了。
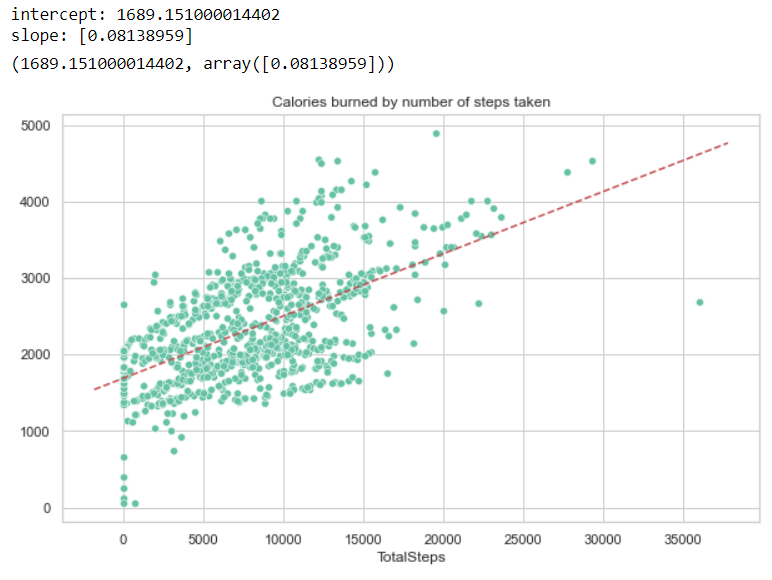
让我们对_总步数_ 与_卡路里_做一些简单的线性回归...
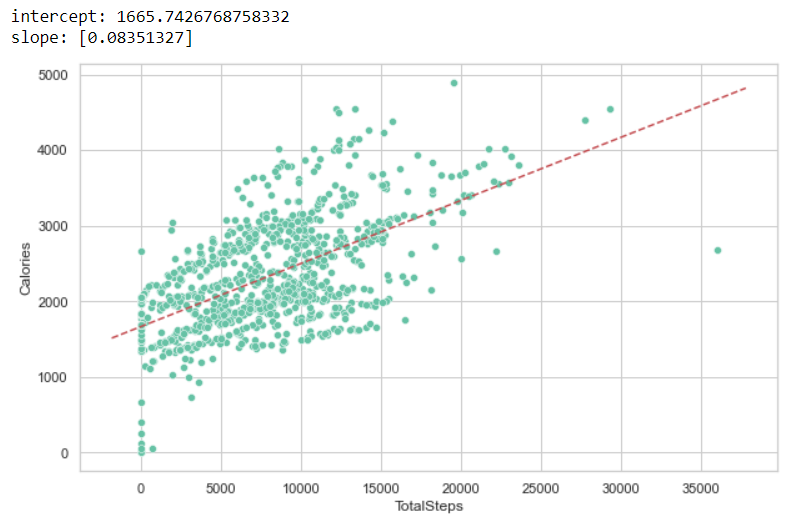
再一次,正如预期的那样,一天中燃烧的卡路里量随着用户走的步数增加而增加。一个有趣的事实是,回归线的截距代表了在没有走步的情况下一天所消耗的卡路里量。这是用户在非常久坐的情况下燃烧的卡路里量。根据Healthline网站,这个数字对应于基础代谢率。
如果我们知道用户的性别、体重、身高和年龄,这个数值就可以计算出来。例如,他们报告说,一个体重175磅、身高5英尺11英寸的35岁男子的基础代谢率为1,816卡路里,一个体重135磅、身高5英尺5英寸的35岁妇女的基础代谢率为1,383卡路里。为了将这些估计值与我们的数据进行比较,我们可以用线性回归法得到截距值。预测的BMR是~1665.74(介于35岁女性和男性的预测值之间)。
如果我们只过滤走了零步的数据点,并得到卡路里分布的统计数据,我们可以进一步得到用户的BMR信息。
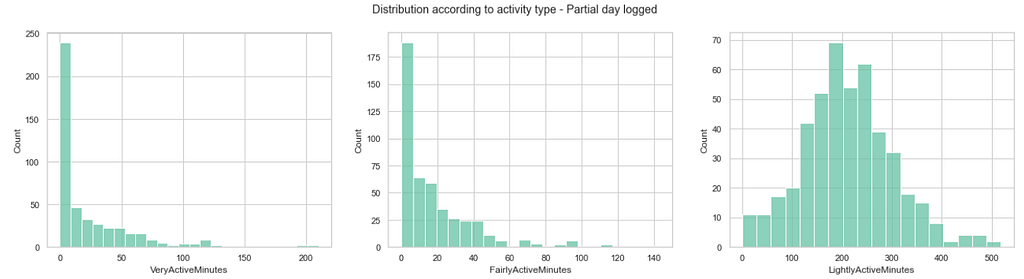
让我们看看_非常活跃的_分钟、_相当活跃的分钟_和_轻微活跃_的分钟的数据分布...
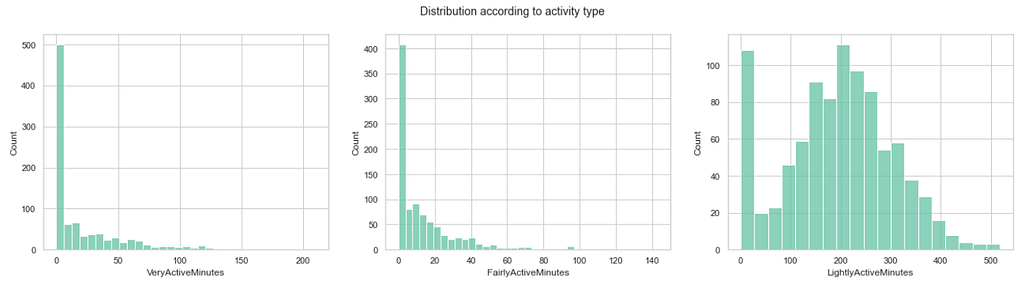
这里有一个问题:不清楚是否所有的用户都在分析期内的整个一天中使用了健身追踪器。如果一个用户记录了一整天,那么_VeryActiveMinutes_ +FairlyActiveMinutes +LightlyActiveMinutes +SedentaryMinutes 的总和应该等于1440分钟(一天的总分钟数)。
从上面的代码片段中,我们推导出
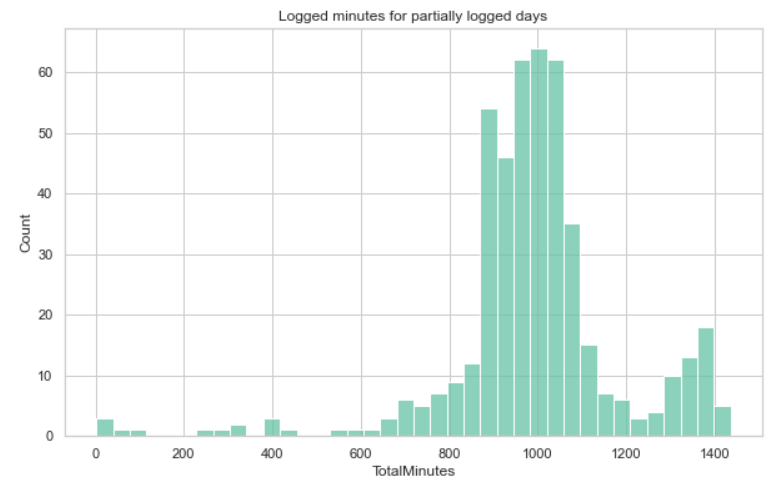
There are 474 (out of 936) rows where users logged the whole day.
There are 462 rows where users logged parts of the day.
轻度活动分钟_的分布是非常对称的,在极少的活动时间内没有峰值。整天记录的用户最终可能会注册大量的_轻度活动分钟,而那些只记录一天中部分时间的用户可能只注册需求较高的活动。
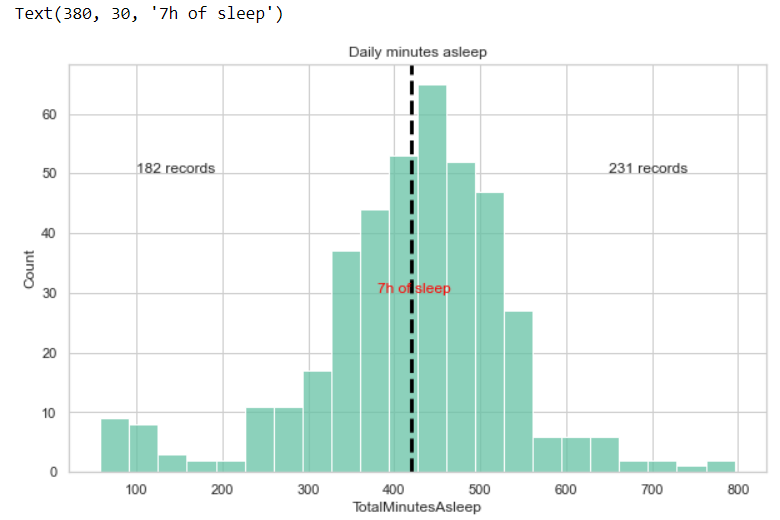
现在,让我们看一下睡眠习惯...
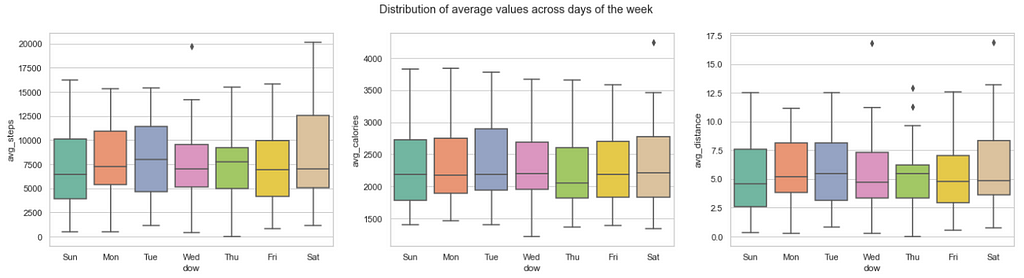
一周中的哪一天有什么不同吗?现在我们看了一下我们的数据和它的分布,一周中的哪一天对用户的行为有很大的不同吗?
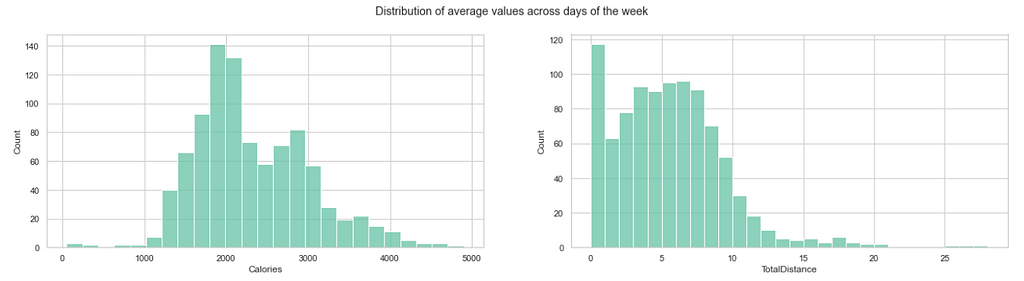
周末的久坐时间有什么变化?
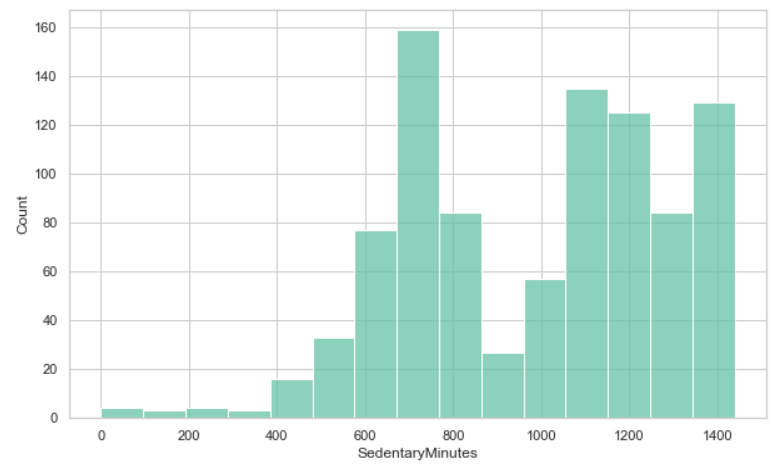
这种分布是如何取决于周末的?
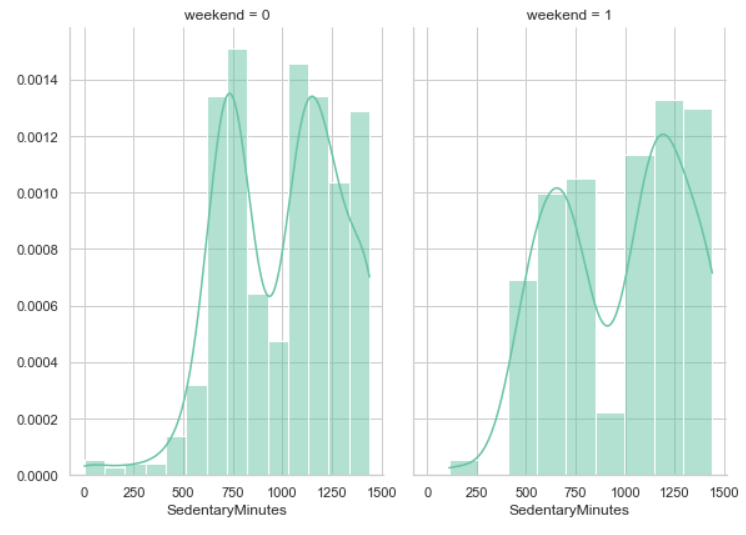
我们现在已经根据_久坐_时间的分布区分了两组用户
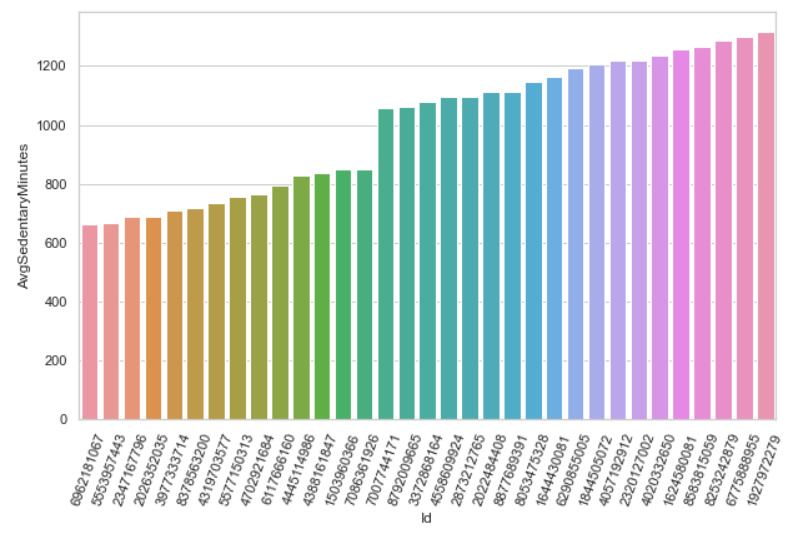
似乎我们在这里发现了一个趋势,有一个明显的偏移,似乎是在这两组人的边界线附近。让我们来验证一下...
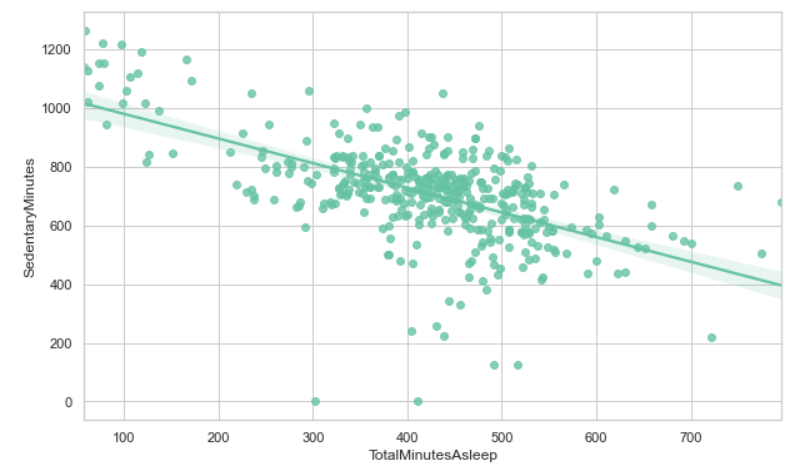
在这里,我们发现了一个明显的趋势,即睡眠时间多的用户倾向于少坐。这表明睡得最多的用户,往往在白天也更活跃。
数据洞察力
仅仅使用我们33个用户的日常活动,我们就得出了一些有趣的结论
在此,我包括从上述EDA中得出的一些高层次的见解。
- 用户在一周的不同日子里的活动没有明显的区别;每天的平均步数约为7670步。
- 根据CDC的一些研究。"......较高的每日步数与较低的各种原因的死亡风险有关"。疾 病预防控制中心还告知我们。"......与每天走4000步(一个被认为对成年人来说很低的数字)相比,每天走8000步与全因死亡(或因各种原因死亡)的风险降低51%有关。每天走12,000步与走4,000步相比,风险降低65%"。
如果目标是燃烧一些卡路里,发现所走的步数和燃烧的卡路里之间存在着线性关系。相应地,我们可以使用用户数据来拟合一个模型,预测用户应该走多少步才能达到一定的卡路里消耗量。
- 关于睡眠习惯,随着睡眠时间的增加,久坐的时间明显减少。
接下来怎么办?
EDA通常是为了获得数据洞察力而进行的,它可以帮助我们完成机器学习的任务。在下一个故事中,我们使用相同的数据集和衍生的洞察力来训练几个机器学习模型来解决回归问题。
如果你喜欢我的故事,并想跳转到带有代码和完整数据集的笔记本,我已经在我的个人git上的一个repo中发布了它。
给这个 repo 打个星吧 :)
如果你的数据科学和/或人工智能项目需要任何帮助,请不要犹豫,在Linkedin或midasanalytics.ai上联系我。
使用SQL和Seaborn(SNS)在Python中进行探索性数据分析(EDA)最初发表在Medium上的Towards Data Science,人们通过强调和回应这个故事来继续对话。
