

深入理解进程(一) 数据结构篇
进程,这个词大家应该耳熟能详了,那进程是什么呢?我们说程序一般是外存上的一个可执行文件,而进程就是这个可执行文件在内存中的一个执行实例。概念始终只会是一个抽象的概念,进程系列文章通过 的实例来将进程这个概念具象化。本篇主要介绍进程涉及到的一些数据结构,废话不多说,直接来看
进程控制块
可执行文件有着自己的格式,有相应的数据结构(比如 头)记录管理着文件的信息,当可执行文件被加载到内存当作进程执行后,也有类似的数据结构来记录管理进程的执行情况,这个数据结构就是 ,进程控制块, 里就是 结构体。
中记录了进程运行需要的一切环境和信息, 中的 定义如下:
struct proc {
uint sz; // Size of process memory (bytes)进程大小
pde_t* pgdir; // Page table 页表
char *kstack; // Bottom of kernel stack for this process 内核栈位置
enum procstate state; // Process state 程序状态
int pid; // Process ID 进程ID
struct proc *parent; // Parent process 父进程指针
struct trapframe *tf; // Trap frame for current syscall 中断栈帧指针
struct context *context; // swtch() here to run process 上下文指针
void *chan; // If non-zero, sleeping on chan 用来睡眠
int killed; // If non-zero, have been killed 是否被killed
struct file *ofile[NOFILE]; // Open files 打开文件描述符表
struct inode *cwd; // Current directory 当前工作路径
char name[16]; // Process name (debugging) 进程名字
};
看着记录的信息挺多的,但是相比于其他操作系统,这些信息算是很少的了,却也包括了各个方面的内容,所以我选择将进程放在最后一个大的板块来讲。本文讲述进程数据结构,就是来解释 中这些属性字段什么意思,有什么用处。
struct {
struct spinlock lock;
struct proc proc[NPROC];
} ptable;
#define NPROC 64 // maximum number of processes
每个进程都有这么一个进程控制块/结构体, 最多支持 个进程,这 个进程结构体集合在一起形成了进程结构体表 ,创建进程的时候寻找空闲的结构体分配出去,进程退出时再回收。这种形式来分配资源到现在应该也很熟悉了,像文件系统部分的 ,缓存块都是这样分配与回收的。
进程结构体表是一个全局的数据,配了一把锁给它,这把锁主要用来保护进程的状态和上下文。锁的问题是进程里面最难的部分之一,甚至我觉得没有之一,后篇再来详述。
进程运行状态
定义了 6 种运行状态:
enum procstate { UNUSED, EMBRYO, SLEEPING, RUNNABLE, RUNNING, ZOMBIE };
各个状态转化图如下所示:
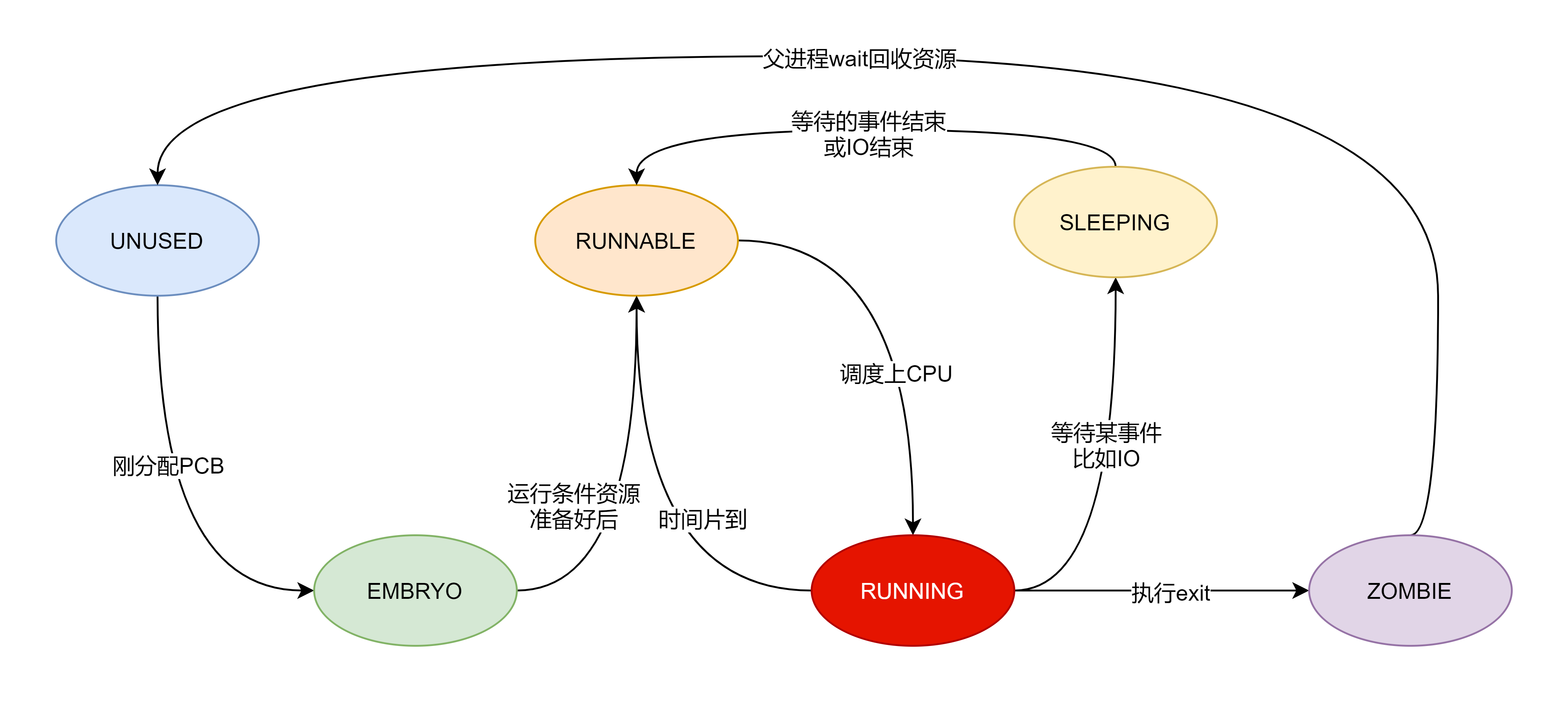
UNUSED:表示该任务结构体未使用处于空闲状态,当要创建进程的时候就可以将这个结构体分配出去
EMBRYO:该任务结构体刚分配出去,几乎什么资源都还没分配给该进程,所以处于 EMBRYO 萌芽状态
RUNNABLE:当进程需要的一切准备齐全之后就可以上 执行了,此时为 RUNNABLE 状态,表示就绪能够上 执行。
RUNNING:表示该进程正在 上执行,如果该时间片到了,则退下 变为 RUNNABLE 状态,如果运行过程中因为某些事件阻塞比如 也退下 变为 SLEEPING 状态。
SLEEPING:通常因为进程执行的过程中遇到某些事件阻塞通常就是 操作,这时候调用 休眠使得进程处于 SLEEPING 状态。当事件结束比如 结束之后就恢复到 RUNNABLE 状态,表明又可以上 执行了
ZOMBIE:进程该干的活儿干完之后就会执行 函数,期间状态变为 ZOMBIE,这个状态一直持续到父进程调用 来回收子进程资源。
如果子进程执行 退出之后,父进程一直没有调用 来回收子进程,那么这个子进程就一直处于僵尸状态,也就是通常所说的僵尸进程。
如果一个父进程退出,而它的一个或多个子进程还在运行,那么那些子进程将成为孤儿进程。孤儿进程将最后会被 进程(第一个进程)所收养,并由 进程对它们完成资源释放的回收工作。
结构体
进程运行在 上, 虽然小,但也是个支持多处理器的操作系统, 为每个 维护了一个数据结构记录当前 的信息:
/******proc.h*******/
struct cpu {
uchar apicid; // LAPIC ID
struct context *scheduler; // 调度器的上下文
struct taskstate ts; // 任务状态段
struct segdesc $GDT$[NSEGS]; // $GDT$
volatile uint started; // $CPU$是否已经启动
int ncli; // 关中断深度
int intena; // 该$CPU$是否允许中断
struct proc *proc; // 运行在该$CPU$上的进程指针
};
/******mp.c*******/
struct cpu cpus[NCPU];
/******param.h*******/
#define NCPU 8 // 支持的最大$CPU$数
与 一一对应, 就可以当作是 $$CPU,可以使用 函数获取当前 ,有关内容见多处理器下的中断机制
表示该 是否已经启动, 全局描述符表在计算机启动的时候创建,这两项详见多处理器下的计算机启动
表示关中断的深度, 表示当前 是否允许中断,这部分详见 LOCK 一文
每个处理器有着自己的调度器 ,调度器就是一段内核代码,当需要调度的时候,它来决定当前 执行哪一个状态为 RUNNABLE 的进程,或者说为状态是 RUNNABLE 的进程分配 ,怎样理解都没问题逻辑上都对。这里 结构体中记录的是 的上下文指针,后面我们会知道调度过程是 ,一次进程的切换过程涉及到两次进程与 的切换,进程与调度程序的上下文都需要正确的保存与恢复才能正常的执行。
关于调度的详细过程我们后面还会详述,这里主要是过一遍各类数据结构以及其包括的信息。关于 结构体还有个任务状态段
任务状态段
任务状态段 ,它是内存中的一段数据,听名字就知道这是用来记录任务状态的,任务状态是什么?主要就是各类寄存器的值,所以定义如下:
struct taskstate {
uint link; // 上一个任务的TR选择子
uint esp0; // 0特权级栈指针
ushort ss0; // 0特权级栈段选择子
ushort padding1;
uint *esp1; ushort ss1; ushort padding2;
uint *esp2; ushort ss2; ushort padding3;
void *cr3; // 页目录地址
uint *eip; // 切换任务时的eip
uint eflags;
uint eax; uint ecx; uint edx; uint ebx;
uint *esp; uint *ebp; uint esi; uint edi;
ushort es; ushort padding4; ushort cs; ushort padding5;
ushort ss; ushort padding6; ushort ds; ushort padding7;
ushort fs; ushort padding8; ushort gs; ushort padding9;
ushort ldt; ushort padding10;
ushort t; // Trap on task switch
ushort iomb; // I/O map base address
};
结构图如下所示:
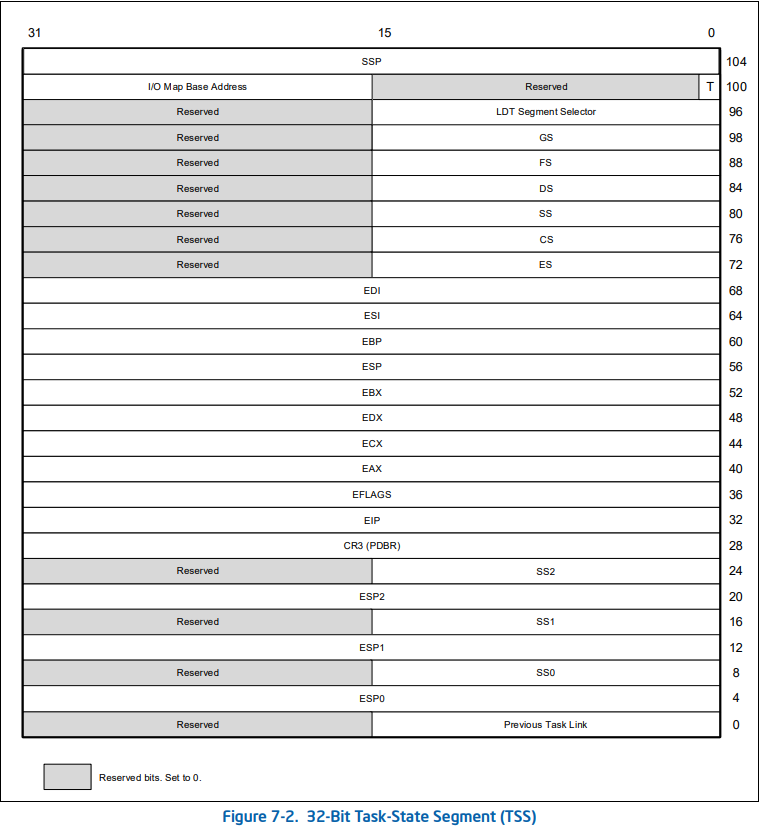
能够看出 里的内容就代表了一个任务的状态和结构:
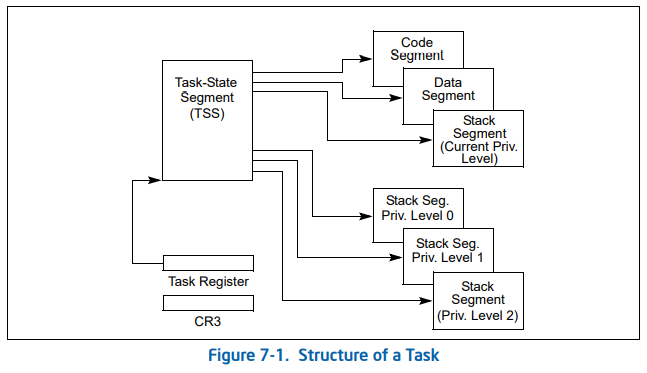
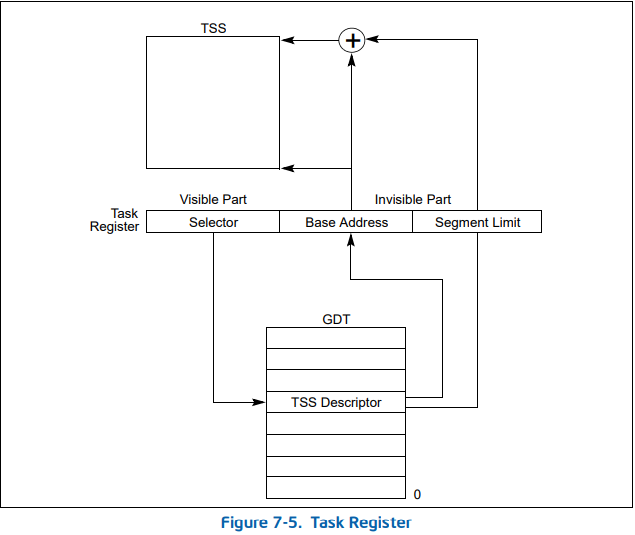
是内存中的一段数据,需要在 中注册专门的 描述符,还有个 寄存器,可见部分的选择子便指向 描述符。所以 是如何定位的? 中的选择子指向 描述符,通过 描述符中的基址界限就能够确定 的位置和大小。
按照最初设计 的想法,每个任务有着自己的 , 描述符,任务切换就是使 寄存器指向不同的 描述符。但奈何这种切换方式效率实在太低,几乎所有基于 的操作系统都没有采用原生的切换方式,而是自个儿建了一个类似结构——中断栈帧来辅助任务切换。所以想想在多处理器下的中断机制中那个很重要的数据结构中断栈帧,里面的内容是不是与 很相像,来源就在这儿。但这也不是说 就没用了,什么用处后面再慢慢到来。
的中断栈帧中保存了各段寄存器和通用寄存器,上面的 将这所有的段寄存器和通用寄存器也全囊括进去了,但还有些特殊的东西:
四种特权级栈
3 类栈段选择子 和栈顶指针 ,诸位应该都知道,硬件实际提供了 4 种特权级 的,只是咱们常用的也就 0 和 3,也就是通常所说的用户态和内核态。 中记录的栈信息有什么用处?跨越特权级的时候需要知道目标特权级栈的位置,去哪儿找?就去 中找。
比如前面我们讲中断的时候说过,用户态跨向内核态的时候, 首先就会将旧栈(低特权级栈/用户栈) 以及 等压入新栈(高特权级栈/内核栈),这个内核栈就是从 中的 和 获取的。
栈对于程序的重要性不言而喻,不同特权级下有不同的栈,所以 4 种特权级按理说应该有 4 种特权级栈(虽然只是用 0 和 3),但为什么 中只记录了 3 种特权级栈(0,1,2)呢?
这里我们需要知道,跨越特权级的时候,除了“返回”,都是从低特权级跨向高特权级。想想中断(用户态下发生中断),系统调用,会发现的确是这样,都是从低特权级跨向高特权级,最后返回的时候才是从高特权级转向低特权级。至于为什么高特权级不会主动跨向低特权级可以这样理解,高特权级的能力肯定要比低特权级大些,它不需要低特权级的帮助。
而低特权级跨向高特权级的时候 会自动地将低特权级的 和 压入高特权级栈,所以低特权级栈信息会放在高特权级栈中,不需要在 中记录, 中记录这个高特权级栈的 和 即可。因为不会存在高特权级主动向 0 特权级转移的情况,所以 也就不用记录 0 特权级栈的信息。
如此,关于跨越特权级寻找栈的脉络应该明了了,当低特权级向高特权级转移的时候从 中获取栈的位置,从高特权级返回到低特权级时从高特权级栈里面获取低特权级栈的位置。
IO位图
聊 位图之前,还是得先说说 的访问,前面的一些文章也提到过,访问 就是访问外设的一些端口,而这里所说的端口就是外设的一些寄存器,而外设的寄存器并不一定是端口。端口数量支持有限,比如 只支持 个 位端口,形成独立于内存的 KB IO 地址空间。但外设的寄存器可是有很多的, 个端口, 空间看着挺大,实际不够用,所以有了 的方式来访问外设所有允许访问的寄存器。外设提供两个端口 ,用 index 端口指定其他的寄存器,从 data 端口读写这个寄存器,data 端口就像是所有寄存器的窗口。
上述所说的访问 的方式叫做 端口映射,这种映射方式是将外设的 端口 看成一个独立的地址空间,访问这片空间不能用访问内存的指令,而需要专门的 in/out 指令来访问。还有一种访问 的方式叫做 内存映射,所谓内存映射,就是把这些寄存器看作内存的一部分,读写内存,就是读写外设的寄存器,可以用访问内存的指令比如 mov 来访问寄存器,比如说 的一些寄存器就是内存映射的。
这就是访问 的两种方式,但 是能随意访问的吗?当然不是, 的访问也是有特权级检查的,就算是内存映射直接读写内存的形式访问 ,听着感觉很随意,但是这部分内存都是映射到虚拟地址的高地址处,也就是内核部分,只有内核(0 特权级)才有权操作。
而 端口映射,使用 in/out 指令访问外设端口的方式也有特权级检查,这是由 EFLAGS 的 IOPL 位和 的 位图共同决定
EFLAGS的IOPL位共 ,四种组合分别对应 四种特权级,IOPL是一个总开关,“只有”当前特权级大于IOPL才允许使用 指令,也就是说数值上 时才能使用 指令。- 如果说
IOPL是个总开关,那么 中的 位图就是个局部开关,就算IOPL不让使用 指令,但是可以在 位图中将相应端口打开,此时同样可以对该端口进行读写操作。
因此综上所述,对于 位图有个大致的认识了,位图这种结构一般是用 来表示一个对象,比如前面文章聊过的数据块位图,一个 用来表示一个数据块,而这里的 位图道理同样如此,只不过这里 用来表示一个 位的 端口。
所以 位图总共 ,如果 位图存在的话一般位于 的顶部,具体位置由 中的 字段指出,这个字段记录的是 位图在 中的偏移量。 位图是 的一部分,那它的地址就必须在 的范围内, 不包含 位图总共 字节,所以 应该在 之间, 为 大小减 1,由 描述符中的 字段指出。
IO 位图这个局部开关要在 的时候才有效, 的时候本身就允许使用 指令对所有端口访问, 位图是不起作用的。另外如果没有 位图,便默认为禁止访问所有端口,只有 IOPL 这个总开关能够决定当前特权级是否能够访问端口。
如何知道 位图存在与否呢?如果 字段值大于 就说明 位图不存在,此时只有 IOPL 能决定当前特权级下能否访问端口。 就是如此,不使用 位图,IOPL 设置为 0,这样就只有内核才能使用 指令访问外设端口。
上一个任务的指针
这个属性字段与任务嵌套有关,任务嵌套就是指当前任务是被前一个任务调用才执行的,也就是当前任务嵌套于前一个任务当中,执行完之后还要回到前一个任务,有点类似与函数调用的意味,函数调用留下了返回地址,任务调用就留下了 指针。 中有个属性位 ,为 1 就表示当前任务是被另一个任务调用的。这也是 原生支持的一种任务切换方式,虽然只简单的提一提,但应该能够感觉到,这种方式很不灵活,更不用说其中的一些细节,是非常繁复的,效率低下,所以一般现代的操作系统不适用原生支持的任务切换方式。
在 中还包括了一个 选择子,接着来看看 是什么
本身支持两种数据结构来帮助任务切换,一种就是 ,上述已经见过它是什么样子了,还有一个是 , 的属性字段中就包括 ,诸位可能对 (全局描述符表) 比较熟悉,这在前文也提到过很多次,那 是什么呢?
(Local Descriptor Table) 局部描述符表,顾名思义,它还是一个存放段描述符的表,只不过变成“局部”的了,而局部的意思是每个进程都有一份自个儿的 ,不像 是所有进程共享的。最初 厂商建议(因为他们这么设计的嘛)各个进程的私有的内存段描述符(比如代码段数据段)应当存放在自己的段描述符表,也就是 里面。
每个 都需要在 中注册,也就是说对于每个 , 中都要有相应的 描述符,这也证明了 才是老大哥。那如何寻找 呢,我们知道 中存放的有 的地址和界限, 就知道 从哪儿开始到哪结束。那 是否有类似的寄存器 ?有倒是有,但 里面存放的并不是像 那样的基址和界限,因为 在 中有注册,靠 来寻址,所以 里面存放 的选择子就行了,这与前面的 是一样的。
给定一个选择子,怎么知道是去 中索引还是 中索引呢?还记得选择子的结构吗?
这张图就很清楚地表示了,如果选择子的第 2 位是 0 的话就表示去 中索引描述符,如果是 1 的话就去 中索引描述符。
有了上述的了解之后,关于内存段的寻址如下图所示:
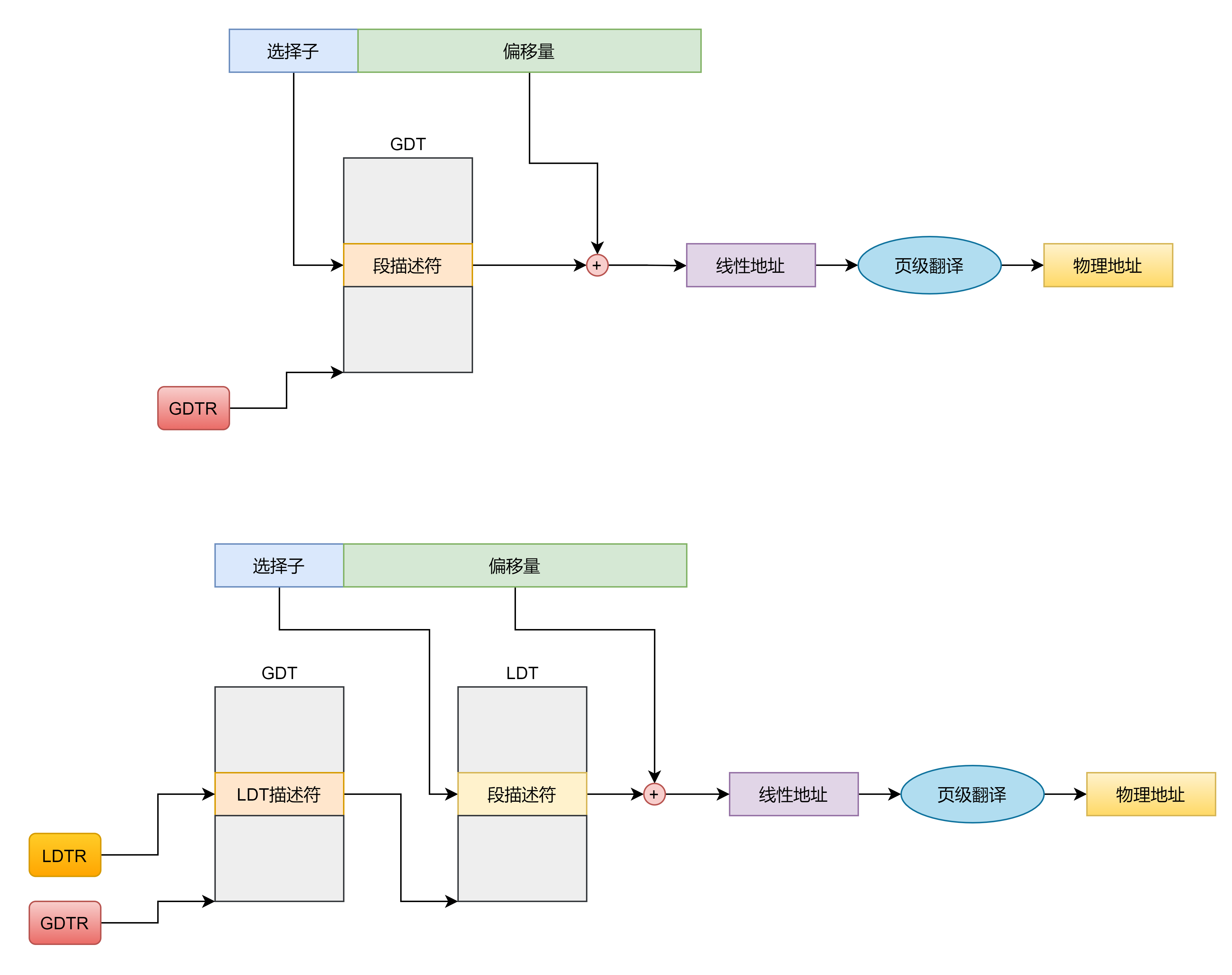
上面为只使用 的情况,下面为使用 的情况,这里注意 描述符里面存放的是 位的线性地址,还应作页级的转换才是物理地址,但是这里我就没画出来了。另外段寄存器的不可见部分缓存着描述符的基址界限等信息,不一定每次都会去访存获取信息。
上述关于 说了那么多,但实际情况中根本用不上 ,想想段描述符具体有什么用处?一个 8 字节的段描述符无非就记录了两种信息:位置和属性,所以段描述符就是用来描述一个段在哪有什么属性。
但现今操作系统基本上都使用平坦模式,段基址都设为 0,所以段描述符用来描述一个段在哪这个作用几乎就没了,所有的段都是从地址 0 开始。而属性这一块儿,每个进程的代码段(数据段)的属性其实都是一样的,所以代码段选择子和代码段描述符(数据段选择子和数据段描述符)完全可以共用。
因此每个进程的段描述符完全可以放在 里面,而不必放在私有的 里面,反正都共用了,直接放在 里面肯定更省事。再者如果使用 ,每新增一个任务,都要在 中添加新的 描述符,重新加载 ,任务结束后还要删掉,实在麻烦,所以现在的操作系统基本不使用, 中也没使用。
上述就是 和 这两种数据结构的介绍,它两是在硬件上支持的两种数据结构,最初设想使用这两种结构来进行任务切换,但奈何效率实在太低,所以这两种数据结构基本上没用。 前面说了根本用不上,但是 还是有用处的,每次低特权级跨向高特权级时需要从 中获取高特权级栈的位置。
而基本上 也就这一个作用了,拿来存放高特权级的 和 ,因为一般就使用用户态和内核态两种特权级,所以完全可以简单地认为: 就是拿来存放内核栈地址的。
切换进程时 不会自动地将新任务的内核栈地址写到 中,需要操作系统自己来做这件事情,这样新任务需要从用户态进入内核他的时候就从 中获取内核栈地址,这在进程第二篇文章里面会具体展开。
其实前面关于 讲述了那么多,其实都不重要,唯一较重要的就是 中存放内核栈地址,主要又想说个有头有尾,所以废话了点。
进程的页表、地址空间
我们都知道每个进程都有自己的虚拟地址空间,究其原因,每个进程都有自己单独的页表,一般来说现在都是用多级页表,所以准确地说每个进程都有单独的页目录。关于页表前文 的内存管理讲述了内核部分,这里补齐用户部分。
简要回顾 的内存管理方式,计算机启动初始化的时候, 将所有的空闲内存分成一页一页的大小然后使用链表头插法的方式将它们给串起来。所以 的空闲物理内存就可以看作是一个大链表。
char* $kalloc$(void);
void kfree(char *v);
函数分配一页的内存,实际上就是返回链头元素, 回收一页内存,实际上就是将这页内存的数据清除之后链接到链表头部去。
static int mappages(pde_t *pgdir, void *va, uint size, uint pa, int perm)
用来建立虚拟地址空间和物理地址空间的映射关系,它将物理地址空间 映射到 虚拟地址空间 ,从实现上来说就是在页目录 指定的页表中添加页表项,页表项的属性为 。
pde_t* setupkvm(void);
用来建立页表的内核部分,每个进程页表的内核部分都是一样的,建立进程页表时都会调用这个函数来建立内核部分。主要就是调用 建立物理地址空间和虚拟地址空间的映射关系。内核部分的映射关系如下所示:
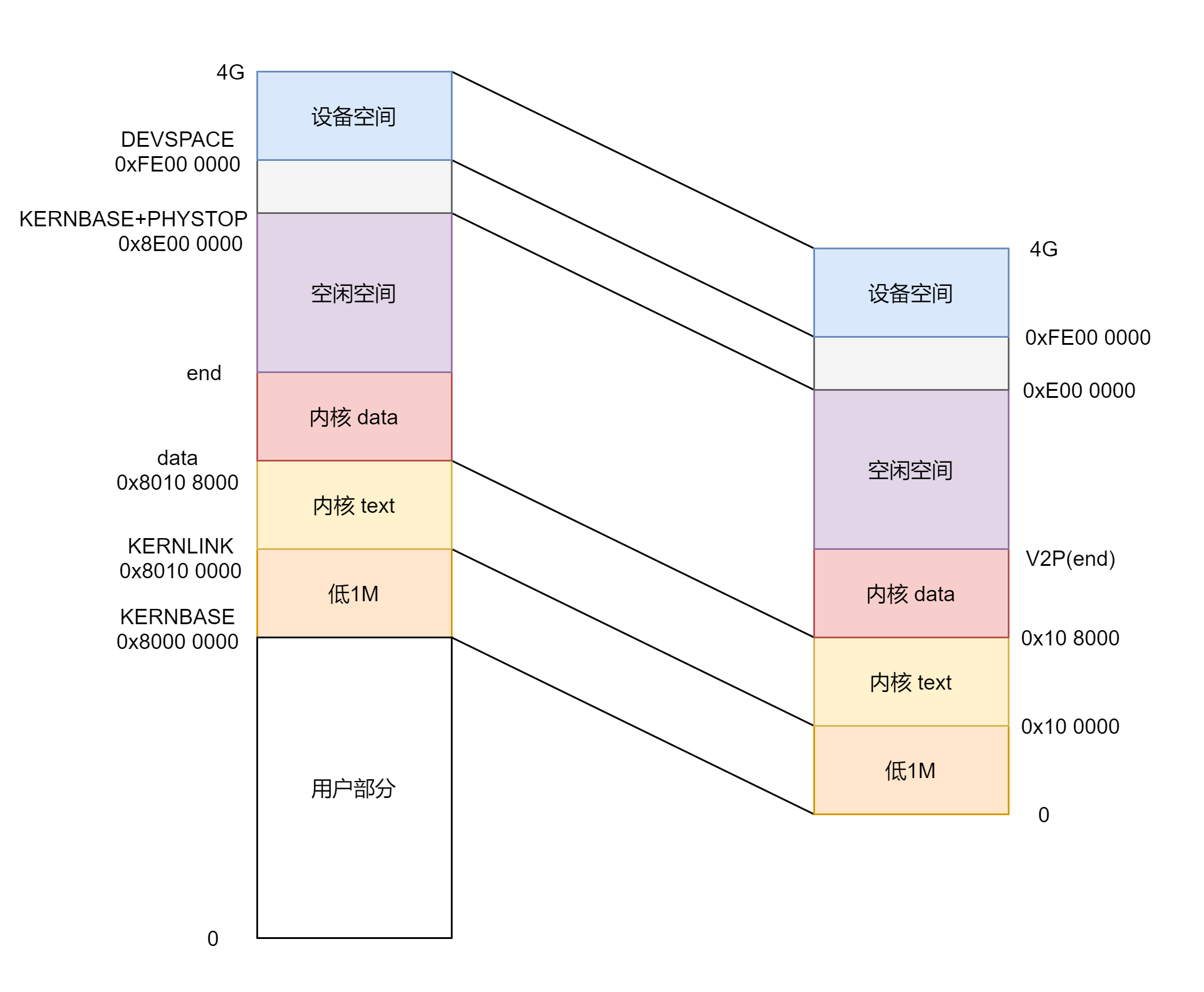
总共映射了五部分区域(有鲜明的颜色标记的区域),灰色区域是没有使用的。虚拟地址空间的低 为用户空间,用户空间映射到物理内存的空闲部分。 用户空间的布局如下:
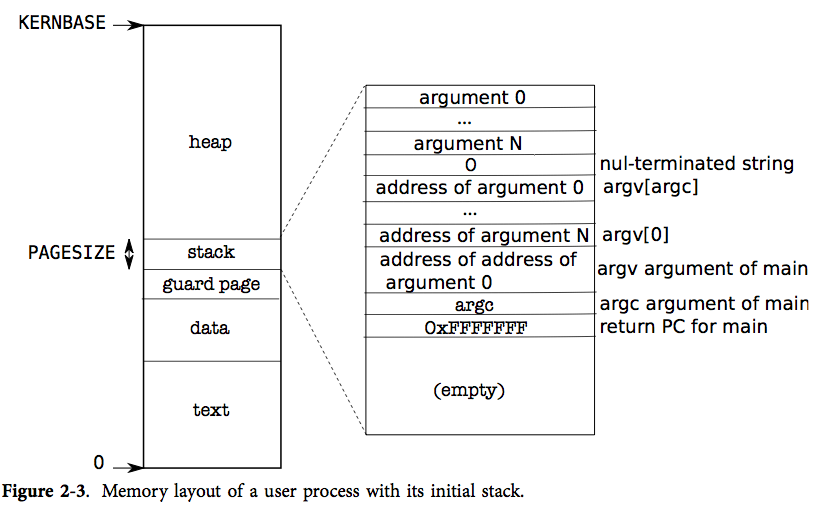
可以看出用户空间主要分为三个部分,堆、栈、代码和数据,由下至上分别来看
代码数据
最开始看 关于用户空间布局图的时候,一度以为画错了, 位下可执行文件的加载地址不是默认 吗?怎么变成 0 了,后面使用了 命令查看了一下一些用户程序(可执行文件)的加载地址,发现的确是从 0 开始的。链接时能够改变程序加载时的虚拟地址,这里应是将其改变为 0 了。
将代码数据段加载到虚拟地址 0 处也没什么问题,设置好页表建立好与物理地址空间的映射关系即可,灵活处理不用那么死板
这里注意注意注意,分配了物理内存且将其映射到虚拟地址 0 处,意味着什么?说明我们能够访问 0 地址, 指针可以使用,本质上来说之所以 不能使用,那是因为通常程序加载到 ,0 地址处没有映射,所以不能使用。而这里建立了映射那 0 地址是能使用的,但这不会出错吗?不会,因为还有一层编译保护,在 文件中开启了 优化,如果引用了 0 地址,会生成 指令, 当执行到这条指令的时候就会出错。但如果关闭 优化,已经过测试是能够引用 0 地址的。
栈
因为只使用用户态,内核态两种特权级,所以一个程序有两个栈,一个用户栈,一个内核栈。
用户栈位于代码数据段的上方,两者之间加了一个保护页,避免栈溢出。所谓保护页就是将这个页的页表项的 位置 0,表示用户态下不允许访问这个页。用户栈时装载程序也就是执行 函数时分配的,最后由父进程调用 回收
内核栈没有固定的位置,一般是 时调用 分配一页用作内核栈,同样的由父进程调用 回收资源
至于栈的作用就不用说了吧,诸位应该很熟悉很熟悉了,重点来看看堆
堆
栈上的数据在函数返回的时候就会释放,有时我们会想让一个函数里面生成的变量产生的数据存活时间久一点,而不是函数一返回就没了,这个时候就需要用到堆。
堆是一片动态分配的内存区域,在 里如上图所示位于栈的上方,内核下方。在这片区域分配的空间,函数返回后不会释放掉,只有“手动”地 掉才会被回收。关于堆的使用最常见的两个函数莫过于 和 :
void *malloc(size_t size);
void free(void *ptr);
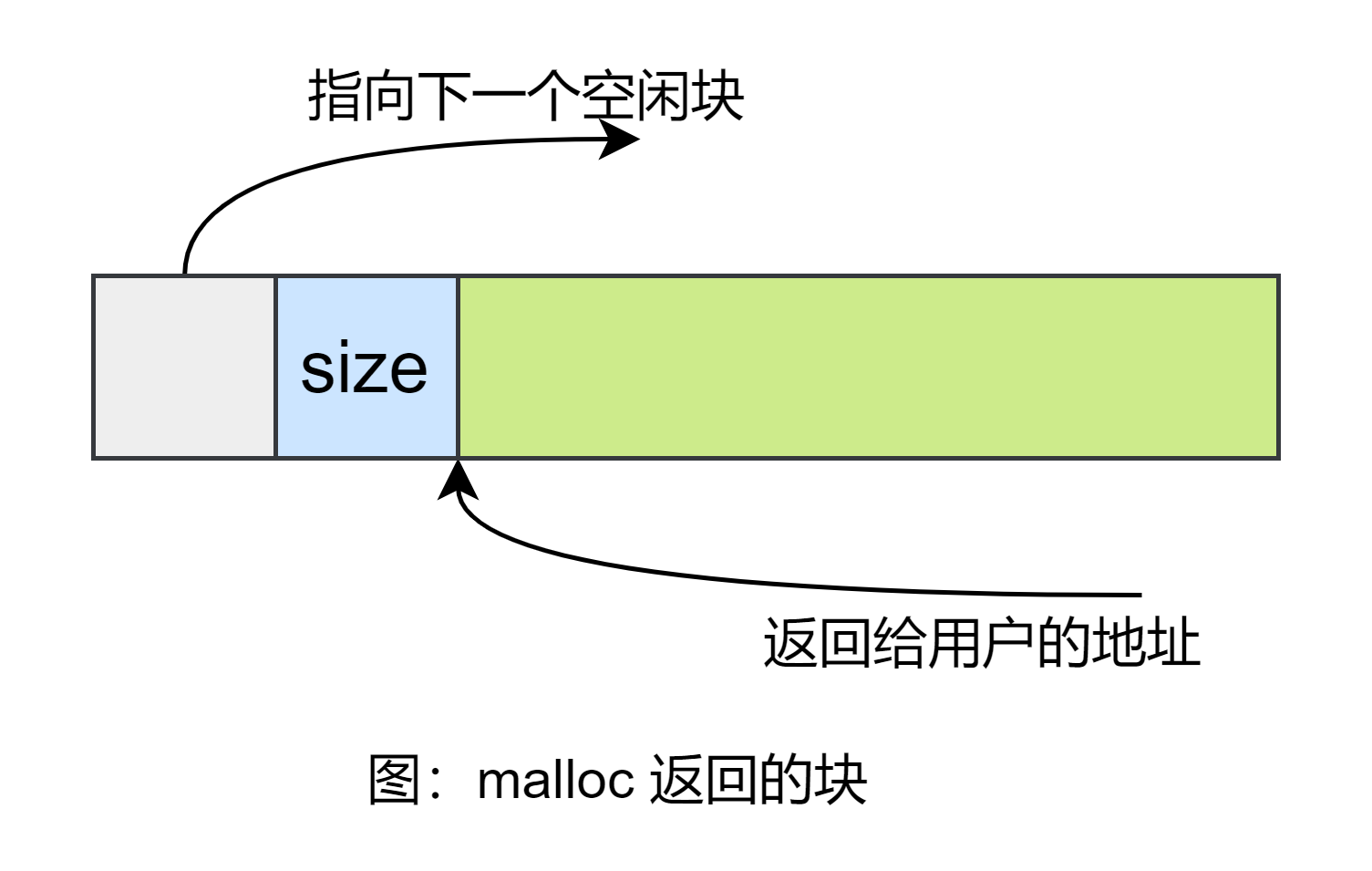
在堆中分配 字节,并返回其首地址,而 释放掉该空间。这两个函数平时应该用的很顺溜,但有没有想过这个问题,假如我使用 分配了 64 字节空间,返回的是这 64 字节空间的首地址 ,当我调用 时释放掉这部分空间的时候,它怎么就知道应该释放 64 字节的空间?
这个问题我在这儿简述一下,后面实现 的时候再详述:使用 请求分配 字节数的时候,首先 字节数会被舍入以满足对其要求,接着实际分配空间的时候还会多分配一个单元作为头部,用来记录这块空间的位置大小信息,最后实际返回的地址不是头部地址而是紧跟头部后面的空闲空间首地址。所以 free 的时候就可以根据头部信息,正确地释放掉这块空间。
就是直接操作上述的那么一大块区域吗?当然不是的,其实我认为上述用户空间布局图关于堆稍稍有些问题,栈的上方到内核这一大片区域可以用作堆,但还不一定是堆。准确点来说应该是下图这样:
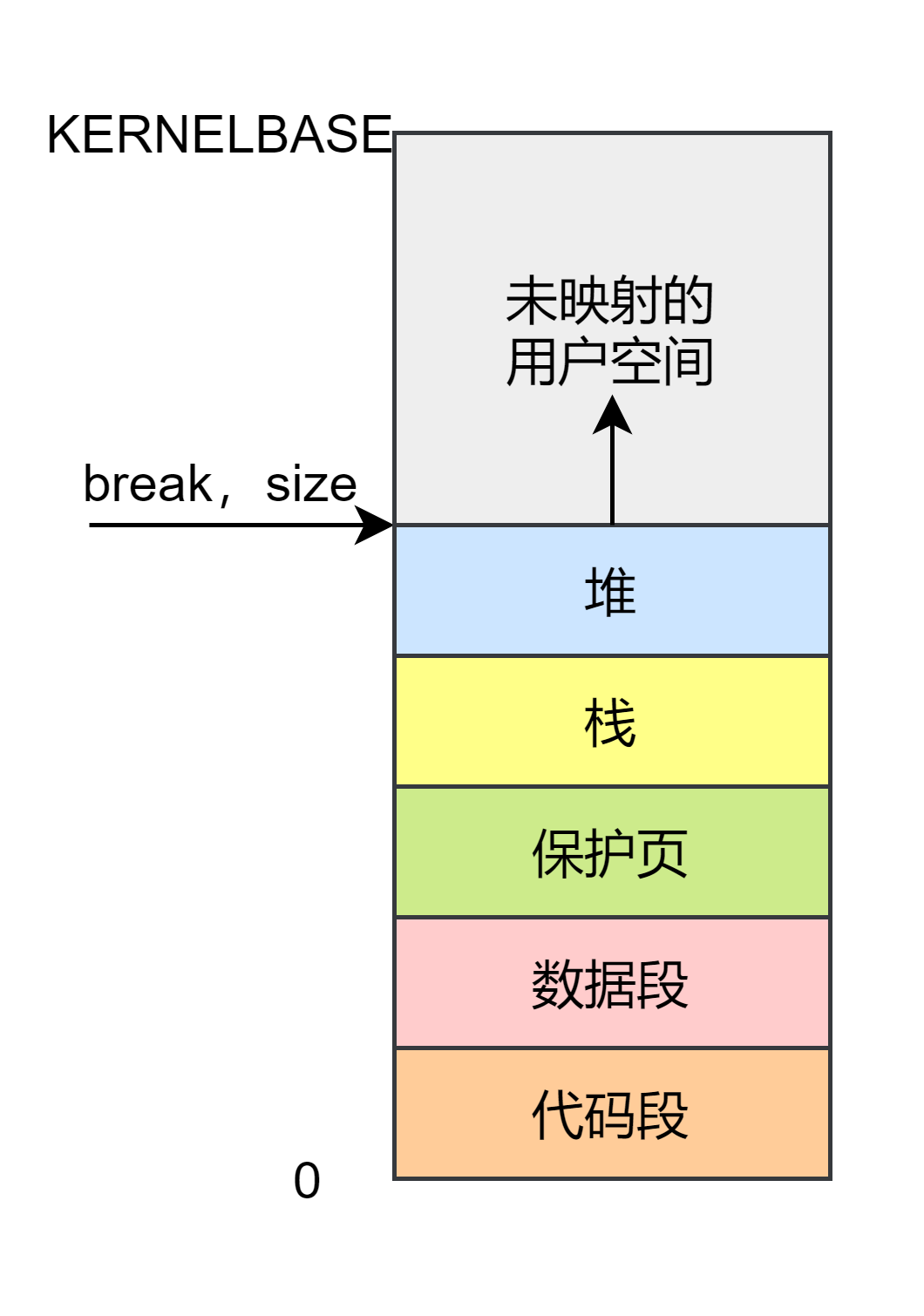
图中有鲜明显色的区域都是实际映射到了物理内存的区域,其中蓝色部分才是 作用的区域,在 中程序在内存中的映像有个属性叫做 , 就是数据段的末尾。使用系统调用 或 可以调整 的位置,如果将 的位置向上移,那么扩大的那部分空间就可以作为堆来使用。而在 里类似,只不过 位于用户栈栈底。因为栈是向下扩展,而堆是向上扩展的,所以不会冲突,没得问题。
另外任务结构体有个 属性表示用户程序的大小,因为程序是加载到的 0 地址,所以这个值在 也就等于 ,程序的大小就等于程序的末尾地址。
关于移动 要注意,不是说简单的向上移动一下 的位置,扩大的这部分区域就可以使用了。扩大的这部分虚拟内存区域需要分配才能使用,或者说需要映射到实际的物理内存才能使用,要知道,虚拟内存不映射到物理内存那就是摆设,不可用。
而所谓的分配虚拟内存或者说虚拟内存映射到实际的物理内存可以简单的看作两步:
- 一内核分配物理内存
- 二填写页表项建立映射关系。
虽然现在的操作系统一般会有延迟分配的机制,到真正使用触发缺页机制的时候再做实际分配,但我这想表达的意思应该也是没什么问题的,通过 和 系统调用在移动 之后肯定会有个分配物理内存建立映射关系的一个过程,随后这部分对空间才能够使用。
内核分配的这一部分堆空间是需要管理的,方便 分配与 回收。管理内存空间或者说管理其他什么空间比如说磁盘空间,通常来说常见的就两种方法:
- 一链表
- 二位图。
这两种方法应该很熟悉了吧,我们在文件系统那一块聊过,在内存管理那一块也谈过,这里就不赘述了。而具体的管理方法比如说有 等等,或者根据每次请求的大小动态使用不同的算法,这里就不展开了。
到此关于堆、、、,应该是有个很清晰的认识了,这里有个生动的比喻: 向内核进一批货作为堆, 再来零售。
关于向内核申请空间作为堆来使用还有一个函数,,这个函数最初的作用是将虚拟地址空间映射到某个文件,但是如果不将这部分空间映射到某个文件,则称这部分空间为匿名空间,匿名空间就可以作为堆空间使用。关于 点到为止,它涉及的东西比较多,比如零拷贝之类的,有机会的话后面详述。
最后再说说堆资源的释放,这里所说的堆资源的回收是说回收整个堆空间,而不是说将使用 分配出去的空间回收回来,同样还是在进程退出之后由父进程来回收整个堆空间,用户空间的所有资源都是由父进程来回收的。
上下文
用户态上下文 trapframe
用户态的上下文大家应该很熟悉,就是那个中断栈帧结构。当用户程序进入内核时(中断,系统调用)需要保存当前进程的现场,也就是将中断前一刻进程的所有寄存器压栈到内核栈,这些寄存器加上一些其他信息比如向量号就形成中断栈帧。
这个中断栈帧可称之为进程在用户态下的上下文,其具体结构参考多处理器下的中断机制一文,这里不再赘述。
内核态上下文 context
内核态的上下文大家可能不太熟悉,它主要用于进程的切换。虽然我们还没讲述进程的切换过程,但是可以先来简单捋捋。
首先明确两件事:
- 每个进程都有用户部分和内核部分,就算进入内核执行内核代码也还是在当前进程,进程并没有切换。
- 进程切换一定是在内核中进行的,不论是因为时间片到头了还是因为某些事情阻塞主动让出 都是如此。
因此,假设现在进程 因为时间片到了要切换到进程 ,因为时钟中断的发生 会先保存它当前用户态下的上下文到内核栈,接下来就会执行切换进程的代码。这里要注意什么叫做进程切换,就是说 执行了切换进程的代码之后就应该去执行 了,不会再返回 了,就相当于 的内核部分被 “中断” 了,既然被 “中断” 了,那么我们就要保存 内核部分的上下文,这就是内核态上下文的由来。示意图如下:
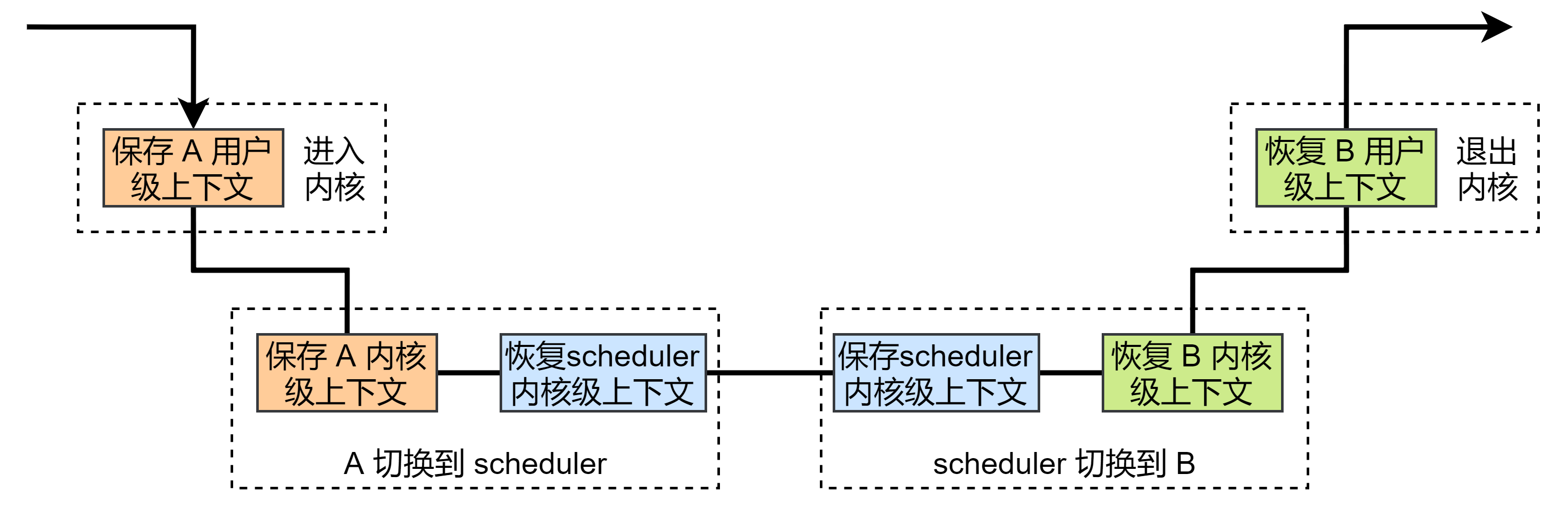
有关切换的细节第二篇再讲述,这里先来看 结构
struct context {
uint edi;
uint esi;
uint ebx;
uint ebp;
uint eip;
};
同样是上下文,为什么内核态的就只用保存这么几个寄存器?我前面说的内核好像被“中断”了,这个中断是打了引号的,实际不是中断,进程切换就是切换函数的调用,整个过程类似于 ,而根据函数调用约定, 为调用者保存寄存器,不需要保存,需要保存的是被调用者保存寄存器,就是上面那 5 个寄存器,也就是内核态的上下文。
其他与总结
进程结构体里面其他的信息就比较简单了,这里统一说明:
是进程号, 是进程名字, 是父进程的进程结构体指针。
打开文件描述符表 ,当前工作路径 ,有关文件的部分可以参考前面文件系统系列文章
这个属性表示休眠对象的指针,一个进程在执行过程中可能需要休眠等待,直到某个对象产生一定条件后才继续执行,所以 chan 就来表示这个对象的指针,如果有多个进程在 上休眠,它们就组成了一个休眠 “队列”
顾名思义,表示这个进程是否已经被杀死,如果已被杀死,就会执行 使进程退出。
以上内容就是与进程相关的数据结构部分,下篇讲述进程的一生:创建,加载,休眠,唤醒,等待,退出,第一个进程,运行环境。好了,本文就到这里了,有什么错误还请批评指正,也欢迎大家来同我交流学习进步。
