YOLO v1
2016年发表于CVPR,448×448图像输入,达到45FPS,63.4mAP,比SSD效果差,相比Faster R-CNN,速度快但准确率低
论文思想
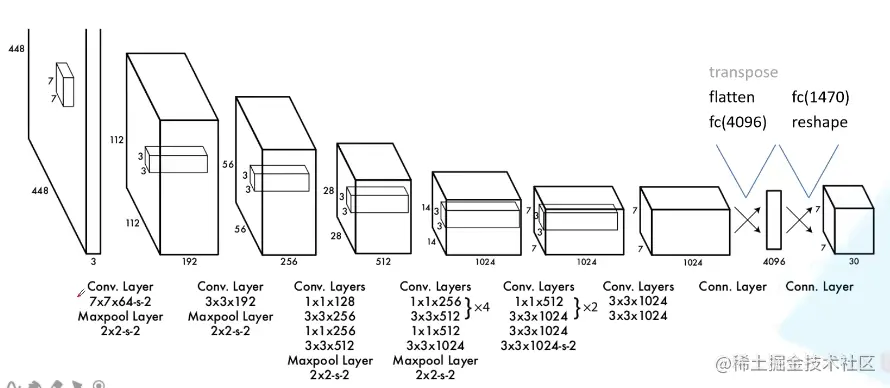
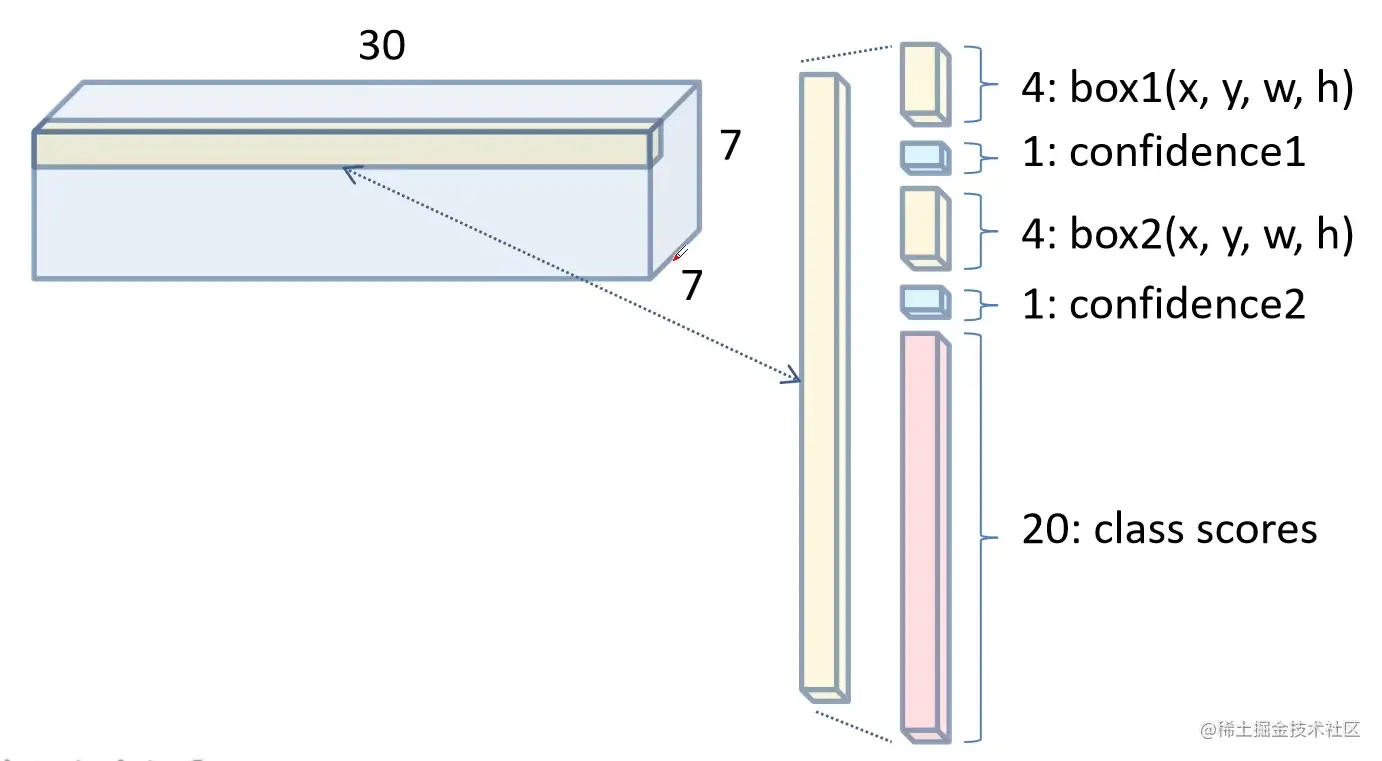
- 将一幅图像分成S×S个网格(grid cell),如果某个object的中心落在这个网格中,则这个网格就负责预测这个object
- 每个网格要预测B个bounding box和C个类别的分数,每个bounding box除了要预测位置之外,还要附带预测一个confidence值
网络结构
损失函数

局限
- 群体小目标检测效果差
- 目标尺寸对检测结果有影响
- 定位不准确
YOLO v2
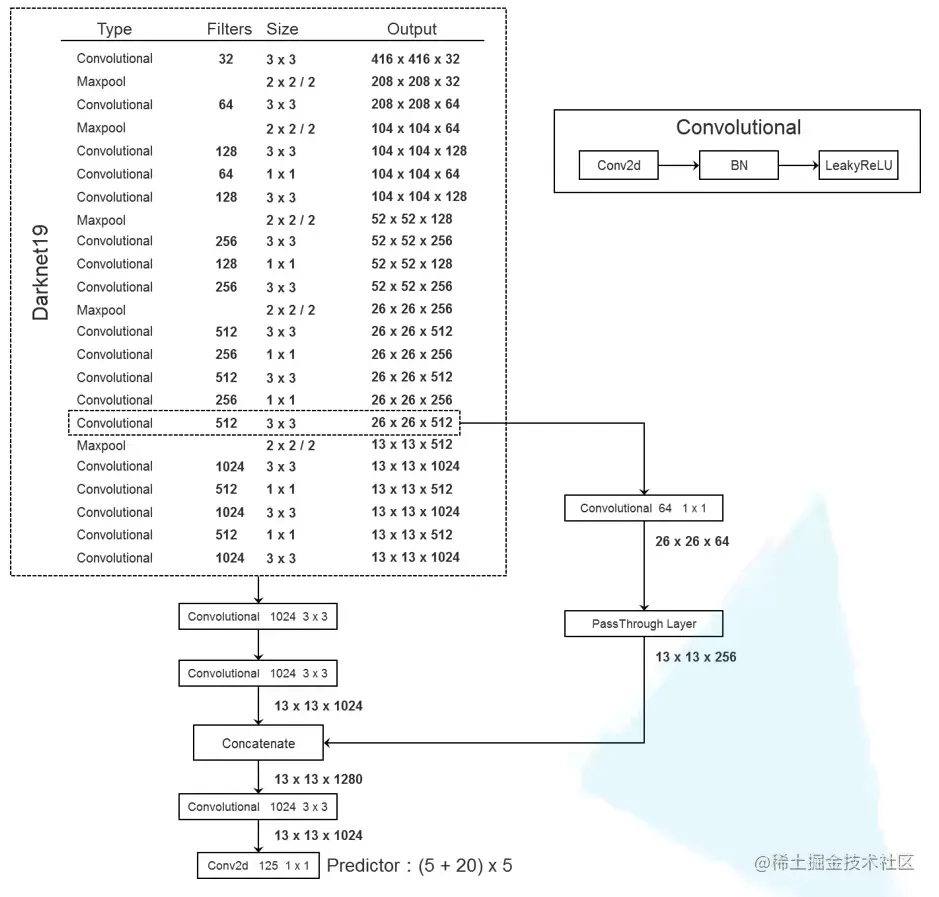
2017年发表于CVPR,采用Darknet-19作为backbone
各种尝试
- Batch Normalization。能够正则化模型,避免过拟合,有了BN层,可以移除dropout操作,mAP提升2%
- 高分辨率分类器。输入图像尺寸为448×448,使mAP提升4%
- Anchor Boxes。使用Anchor Boxes偏移量,而不是像YOLO v1直接定位,能够简化目标边界框预测问题,便于网络学习。相比于不使用Anchor Boxes,mAP略微降低,但召回率能提升7%
- Dimension Cluster。使用k-means聚类根据训练集的bounding boxes自动找到合适的priors
- Direct location prediction。限制预测目标中心点的坐标范围,使网络训练更稳定
- Fine-Grained Feature。通过PassThrough Layer融合高维和低维的特征矩阵,提升检测小目标的能力
- 多尺度训练。提升鲁棒性
网络结构
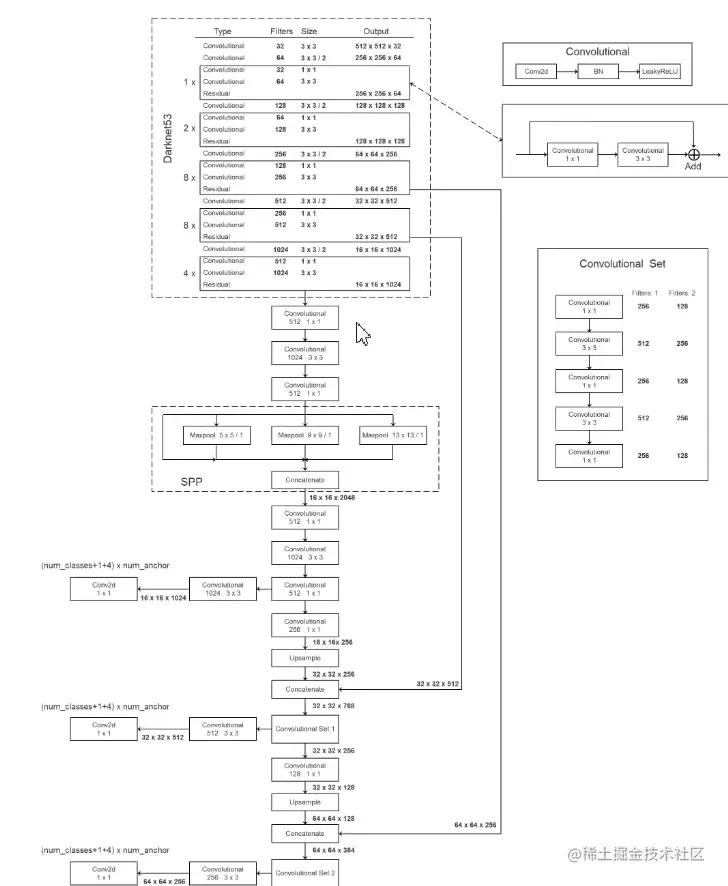
YOLO v3
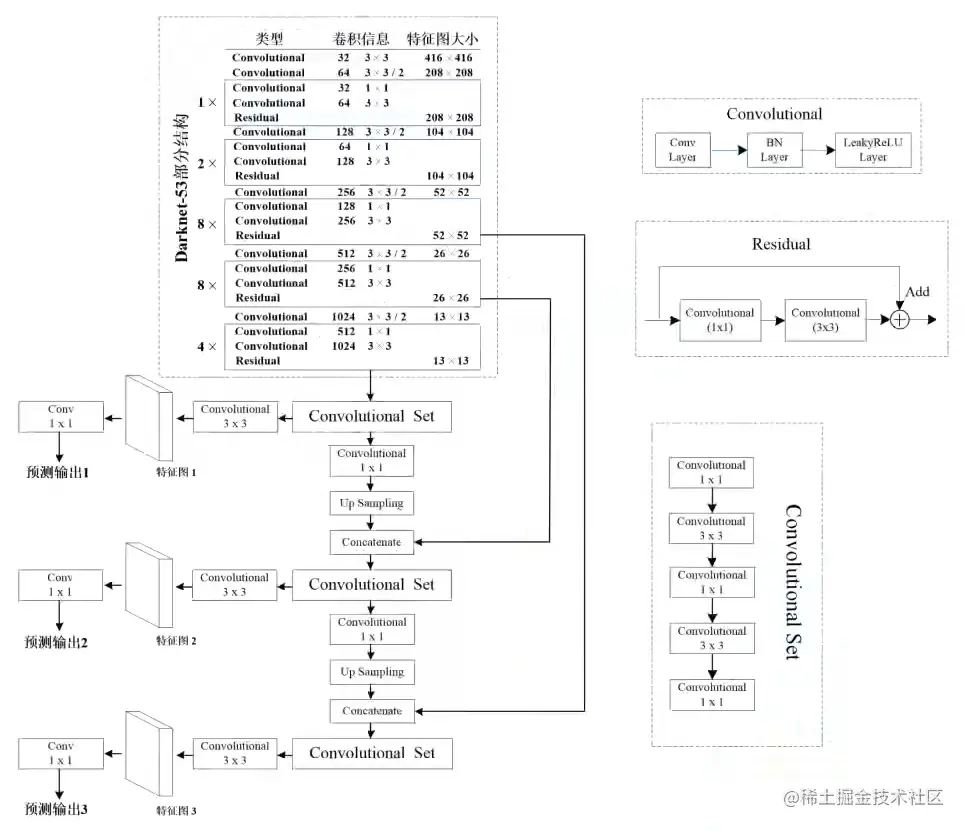
2018年发布于CVPR,采用Darknet-53作为backbone,用3×3卷积核步距为2的卷积层替代下采样池化层
网络结构
目标边界框的预测

正负样本的匹配
选取IoU最大的box作为正样本,IoU超过0.5但不是最大的box直接舍弃
损失计算



YOLO v3 SPP
Mosaic图像增强
将4张图像拼接为1张图像作为训练样本
- 增加数据的多样性
- 增加目标个数
- BN能一次性统计多张图片的参数
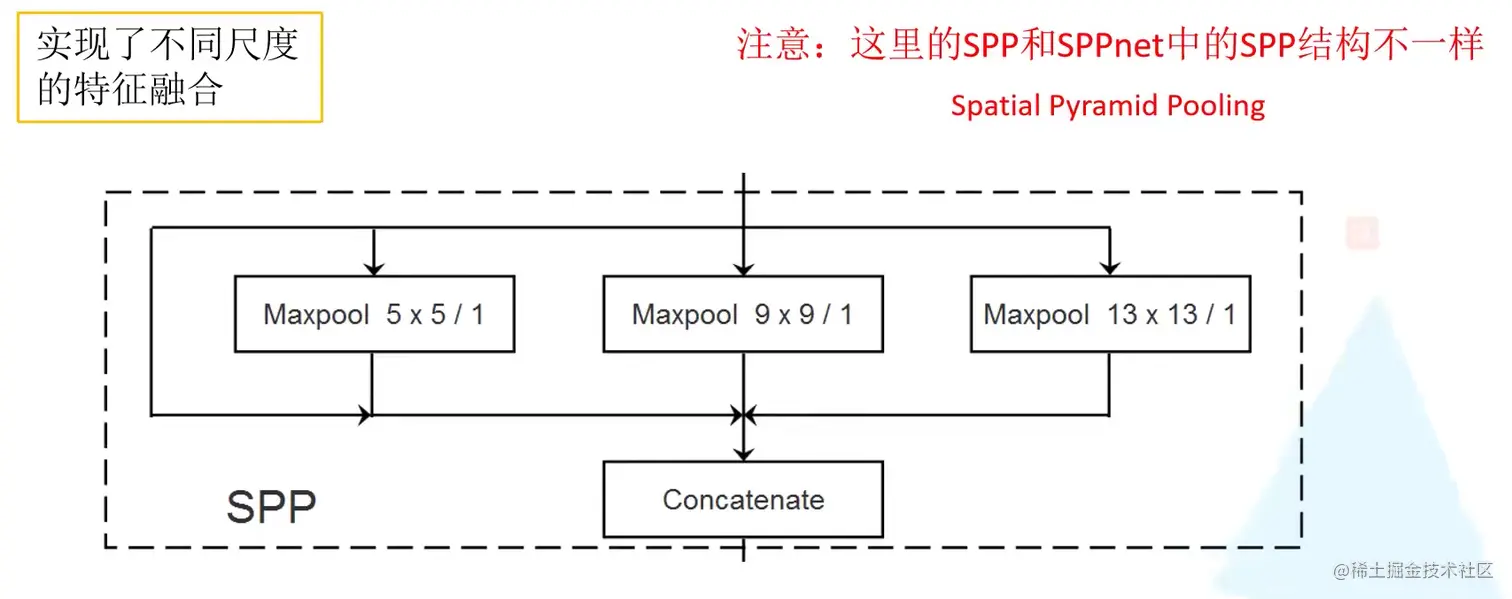
SPP模块
实现了不同尺度的特征融合
网络结构
回归定位损失
IoU Loss
IoU=Union(boxA,boxB)Intersection(boxA,boxB)
LIoU=−ln(IoU)
优点:
缺点:
GIoU Loss
GIoU=IoU−AcAc−u,−1<=GIoU<=1
LGIoU=1−GIoU,0<=LGIoU<=2
其中Ac为boxA和boxB的外接矩形面积,u为boxA和boxB的并集面积
DIoU Loss
LIoU和LGIoU的缺点:
DIoU损失能够直接最小化两个boxes之间的距离,因此收敛速度更快
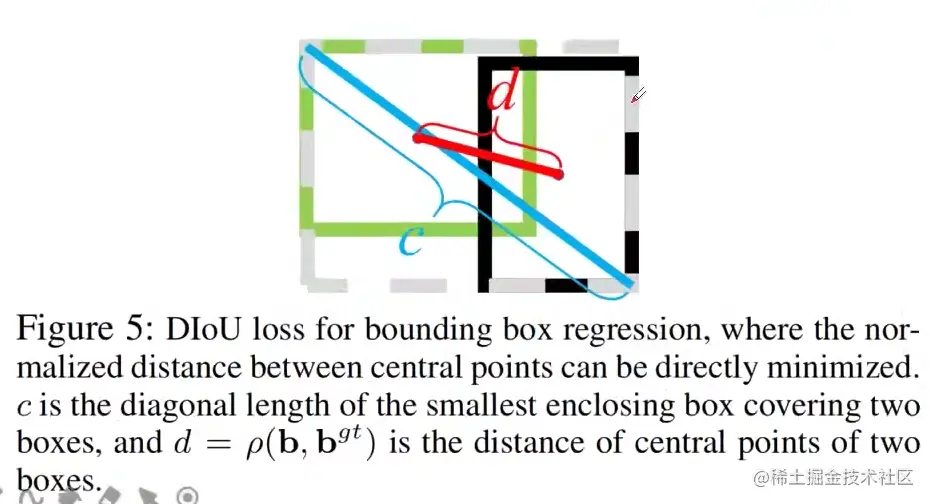
DIoU=IoU−c2ρ2(b,bgt)=IoU−c2d2
−1<=DIoU<=1
LDIoU=1−DIoU
0<=LDIoU<=2
CIoU Loss
一个优秀的回归定位损失应该考虑到3种几何参数:
CIoU=IoU−(c2ρ2(b,bgt)+αυ)
υ=π24(arctanhgtwgt−arctanhw)2
α=(1−IoU)+υυ
LCIoU=1−CIoU
Focal Loss
One-stage网络模型,正负样本不平衡
FL(pt)=−αt(1−pt)γln(pt)
更专注于难分的样本


