1/高密数据开发(presto && dolphinscheduler)
涉及到专业职级,管理职级,绩效,薪酬等敏感的数据,属于高密数据,需在presto中开发。
还有涉及到身份证号码,银行卡号码,手机号,家庭住址,紧急联系人姓名等,也是敏感数据。
往is_hrds库写数据,以及大宽表(及往clickhouse数据库中写),都是在prestos上开发。
kdb(mysql数据库的集群形式),存储引擎是innoDB
clickhouse数据库的存储引擎是mergeTree
insert into clickhouse_'!{db_env}'.l_gifshow.emp_basic_info()
insert into kdb_hrds_'!{db_env}'.is_hrds.dept_remain_analysis_mi()
刷历史数据的时候:
delete节点
where data_month = '${this_month}'
update节点
dt = '${yesterday}'
每天例行调度的时候
delete节点
where data_month =
substr( date_sub( '${yesterday}', interval 1 month ) ,1,7 )
update节点
dt > '2020-08-31'
and (
(substring('${yesterday}', 1, 7) <= '2020-11' and dt in ( cast(last_day_of_month(date_add('month', -2, cast('${yesterday}' as date))) as varchar),
cast(last_day_of_month(date_add('month', -1, cast('${yesterday}' as date))) as varchar) ))
or (substring('${yesterday}', 1, 7) > '2020-11' and dt in (cast(last_day_of_month(date_add('month', -1, cast('${yesterday}' as date))) as varchar)))
)
###################
###################
###################
###################
对于专业线dept,每天都更新,每月末一个分区
所以刷历史数据和每天例行调度是一样的。。
delete 节点
where data_month = '${this_month}'
update节点
dt = '${yesterday}'
####################
####################
####################
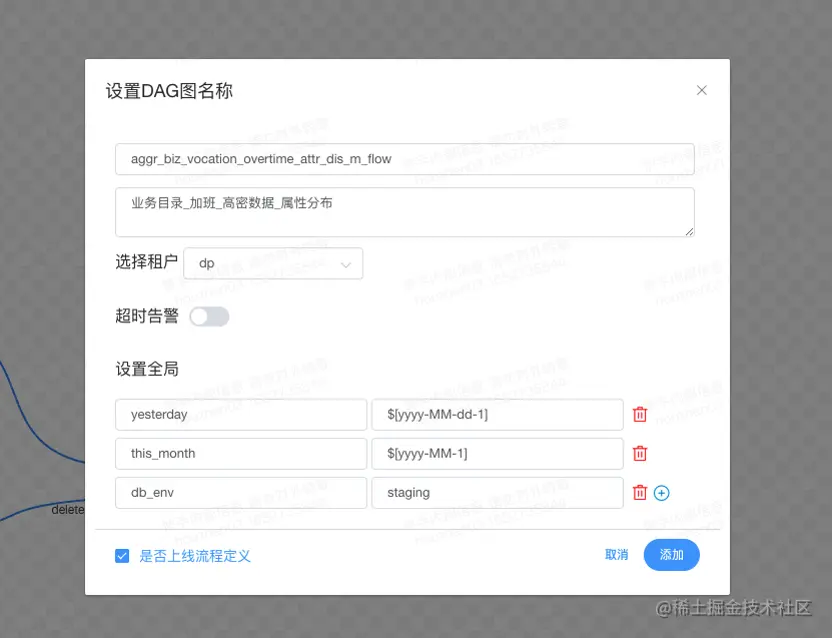
一般的参数'${yesterday}'
'${this_month}'
这里的this_month和yesterday是对应的。
及this_month是yesterday所在的月份。
环境参数 '!{db_env}'
目前我们自己搭建的presto集群,只有以下2个变量
yesterda $[yyyy-MM-dd-1]
this_month $[yyyy-MM-1]
在presto开发,sql代码中读取hive表的时候,
需要在hive表前面加hive,比如:
from hive.ks_hr.xxxxx
专业线 dept 从2018年开始有数据
业务线 biz 从2019-11月开始有数据
在海豚调度系统中,任务流必须上线之后,才能在linux中执行下面的命令
几种不同的时间模式
period: week | month | quarter | half_year | year
每周的最后一天
每月的最后一天
每个季度的最后一天
每个半年的最后一天
每年的最后一天
# 在沙箱环境
python DolphinschedulerUtils.py http://172.29.6.171:12345 houzheng houzheng123 wanxiang-staging 2018-01-01 2021-10-31 dept_remain_analysis_mi_flow month 5 staging
# 在线上环境
python DolphinschedulerUtils.py http://172.29.6.171:12345 houzheng-online houzheng123 wanxiang-online 2018-01-01 2021-10-31 dept_remain_analysis_mi_flow month 5 online
账号
密码 这里的密码是海豚调度的账号密码,不是presto开发的账号密码
项目名称
开始时间(格式xxxx-xx-xx,不管是week,还是month,还是季度,还是半年,时间格式都是xxxx-xx-xx)
结束时间(格式xxxx-xx-xx)
任务流的名称(提前搭建好任务流)
时间颗粒度 month 代表是月,half_year是半年
5代码每个月份之间间隔5秒
staing代表沙箱环境,online是线上环境
presto设置定时任务,
staing环境,一般是8点以后
online环境,一般是7点以后
第一步:检测依赖的hive表是否准备就绪check_ks_hr.xxxx
如果是同时依赖多个hive表,则在搭建任务流的时候,并行多个检测节点(并行模式)
脚本是:
/data/software/anaconda3/bin/python3 /data/software/check_hive_table_partition.py ks_hr.xxxxxxx '${yesterday}'
第二步:删除旧数据delete_xxxxx
脚本是:
delete from is_hrds.xxx
where data_month = '${this_month}'
或者
where data_month = substr( date_sub( '${yesterday}', interval 1 month ) ,1,7 )
注意:xxx是is_hrds库中的数据表,,
data_month是该表中的字段,注意该字段是表示时间切片的字段。
'${xxx}'是定义的参数
这里是mysql的语法
第三步:更新新的数据
update_xxxx. # xxxx是数据库的表名
脚本是:
把更新数据sql脚本粘贴进去,,,注意,不包括建表的代码。
这里是presto的语法
参数设置
解密函数
'!{db_env}'_kc_decrypt( level_name ) as profession_level
注意:
我们通过解密函数解出来的字段也是字符串类型的,
如果需要变成数值型的,还需要cast()
加密函数:
'!{db_env}'_kc_encrypt( profession_level ) as profession_level
注意:不能对数值型字段进行加密,
如果需要对数值型字段进行加密,则需要先通过cast()函数
修改该数值型字段的类型
比如:
'!{db_env}'_kc_encrypt( cast(a as varchar) ) as a
该函数计算2个日期(xxxx-xx-xx)之间相差的天数
start_date,end_date必须是date类型的数据
date_diff('day',start_date,end_date)
应用:
date_diff( 'day',
cast('2021-01-01' as date),
cast('2021-09-09' as date) )
substr('xxxxxx',n,m)函数是截取字符串,n是起始位置,m是位数。切记substr()是从1开始的
比如substr('shandong_linyi',10,5) 得到的是'linyi',l是第10位
2/非高密数据数据(hive开发 && hive2mysql)
idp开发平台的hive表任务上线,及每天例行调度执行,有报警机制。
在presto中开发高密数据的时候,把is_density字段去掉,
因为已经是高密数据了,不需要再通过该字段提示了。
表中统一用parent_org_code,而不是parent_department_code
hive任务发布:
每天例行调度,0点之后开始进入调度,排队等待资源执行任务,
具体啥时候可以执行,要看资源。
可以设置9个小时还没有执行则报警。
可执行性检测,,跳过审查,kim和电话
报警组hrds_alert
p0级别
先把历史数据写入history分区,然后同步到kdb.
然后再把hive调度执行的代码改成写入到‘{{ds+0}}’昨日分区的形式。
每天例行调度。
hive2mysql:
在往kdb同步数据的时候,需先在gifshow或者is_hrds库上创建数据表。
创建新表的时候,需提交工单,不能自己创建。
如果是修改表,比如是增加字段,删除字段,修改字段的数据类型,修改comment等,
如果影响行数没有超过50000行,则只需要在kdb_sql审核平台上提交工单即可。
如果影响行数超过5w行,则需要走流程中心,最好在下午6点之前提交,实例是13575
流程中心网址:
https://bpm.corp.kuaishou.com/agile-designer/pc/submit/CPSGR4DzHy
删除hive表步骤:
1/先在数据地图中,查看要删除的表是否有下游依赖
如果有下游依赖,则谨慎操作
2/如果没有下游依赖,则可以删除
3/直接在idp中操作
先确定好开发组,然后编写下面的sql,然后执行
set drop_enable_toggle=on;
drop table ks_hr.xxxxx
修改hive表步骤:
直接在idp中去操作
没有set设置
ALTER TABLE ks_hr_dev.tmp_fact_training_ksxt_lecturer_df
ADD COLUMNS (column1 string comment 'xxx',
column2 string comment 'xxx') cascade;
别忘了括号()最后cascade 作用是对所有分区都生效
hive开发新增字段,刷历史数据的步骤
1/先修改hive表结构,直接在idp中操作
新增字段 alter table xxx add columns
默认字段是加在最后的
2/然后对hive表刷历史数据
有的时间需要刷历史数据,但是有的时候只需刷最新分区数据
3/然后更改hive的例行调度任务
不需要下线,直接点击更多,然后更新内容,然后再次上线即可。
4/更改数据同步任务
需要先提工单,给gifshow库的数据表的数据结构,
然后更改数据同步任务
####################
####################
####################
####################
加班休假明细表:
ks_hr.fact_person_vocation_overtime_hierarchy_info
ks_hr.fact_person_vocation_vocation_hierarchy_info
这2张hive表,
每天更新,
每天存一个分区,每个分区都是全量数据,及包括历史数据。
所以如果你需要选择某个月的加班休假数据,则需要where data_month = xxxx
data_month是加班休假所在的月份
####################
####################
hive表开发:
1/hive表开发
开发完之后测试,检查数据是否正确。
如果没有问题,发布(上线)每天例行调度。
零点之后开始调度,具体执行时间看资源的分配情况。
9个小时之后如果还没调度则报警。
2/数据同步,
hive2mysql,及数据同步到gifshow库中的对应的表,表名自己指定。
如果是data_month时间颗粒度,则数据同步的时候,需要先执行一些sql.
比如先删除yesterday所在的月份数据,再insert新的数据。
delete from @table
where data_month = date_format('@ds','%Y-%m')
###################
###################
hive2mysql:
一般需要写写入数据之前需执行的sql
如果需要刷gifshow中表的历史数据,则:
delete from @table
如果是每天增量更新的话,则
delete from @table where data_month = date_format('@ds','%Y-%m')
创建2个数据同步任务,hive2mysql:
<1>第一个是同步历史数据
不例行调度,一次性任务,dt="history"
同步前执行sql:
delete from @table
<2>第二个同步最新分区数据
例行调度,每天例行,dt="{{ds+0}}"
同步前执行sql:
delete from @table
where data_month = date_format('@ds','%Y-%m')
###################################
###################################
修改hive表的数据结构,比如添加字段
步骤:
1/先在idp中修改hive表的数据结构,然后在数据地图中看一下字段是否添加成功
有的时候会出现一种情况,就是字段添加进去了,但是字段的描述没有。
这是正常的情况,可能是idp平台的bug,无需在意。
添加字段的sql例子:
ALTER TABLE ks_hr.xxx
ADD COLUMNS (col_a string comment 'xxx',
col_b string comment 'xxx',
col_c string comment 'xxx') cascade;
最后的cascade表示对所有的分区都生效(前提这是一张分区表)
2/然后跑最新一个分区的数据dt='{{ds+0}}',执行成功后,
到数据地图中去看看数据有没有写进去。
这个时候会出现一种情况,就是数据地图的数据预览中,新添加的字段还是空值,
这是一种正常的情况。
为了证明数据确实已经写进去了,
可以在idp中查一下,select xxx from xxxx
如果可以查到,说明数据已经写进去了,这就是成功了。
3/该刷历史数据的就刷历史数据,不该刷历史数据的就不用刷了
dt in (last_day(dt), date_add(current_date(),-1))
# 每个月的最后一天,以及昨天的日期
4/hive表的数据是需要同步的gifshow的,
所以还需要修改gifshow中表的数据结构,
这个操作需要提交工单。
在mysql中添加字段的sql例子:
写上数据库的名称
ALTER TABLE gifshow.xxx
ADD col_a varchar(50) COMMENT 'xxx' AFTER xxx,
ADD col_b varchar(50) COMMENT 'xxx' AFTER xxx,
ADD col_c varchar(50) COMMENT 'xxx' AFTER xxx;
# sql语句和hive中的语句是不同的
5/提交完工单,审批完毕执行之后,就可以同步数据了。
#####################################
#####################################
执行hive任务的时候,报错,提示第几行,第几个字符报错。
这里的行数,是从整个脚本的第一行非注释的代码开始的。
<10>补充历史数
如果是新开发的一张表,
开发测试完之后,我们需要补充历史数据,
因为在万相产品中,有关于时间的下拉框,用户也可以查看之前日期的历史数据。
历史数据分为多种情况,
比如天颗粒度(每天一个分区),
周颗粒度(每周一个分区),
月颗粒度(每月一个分区)。
1)如果每天存一个分区,假如从2021-01-01开始补数据,
则select xxx from xxx
where dt >= '2021-01-01'
'history' as dt
把所有的历史数据写入‘history’分区,
然后数据同步的时候,把dt='history'这个分区的数据同步到gifshow即可。
2)如果每个月末存一个分区,假如从2021-01-31开始,
则
select xxx from xxx
where dt in (last_day(dt), date_add(current_date(),-1))
'history' as dt
把所有的历史数据写入‘historu’分区,
然后数据同步的时候,把dt='history'这个分区的数据同步到gifshow即可。
3)每周存一个分区,这种需求比较少。
<11>idp集成开发平台的补数据功能
该功能的作用是:
被执行的任务,已经
mysql2hive
把kdb中的数据,同步到hive
步骤:
1/打开idp,点击数据同步tab
2/项目组选择ihr_db
3/左侧任务概览,选择mysql2hive,新建任务
4/目录是houzhen03,是自己的邮箱前缀
5/填写各种具体的参数,比如端口号,mysql的数据库名称,表的民称等。如下所示: