译/ 阿里淘系商家团队 - 革新
本文是技术图书“Deep Learning with Python, Second Edition”的翻译和补充。发布者:François Chollet(Keras作者,Google深度学习工程师)
由于目标是开发一些可以成功泛化到新数据的模型,因此,对模型泛化能力的评估就变得非常重要。在本文中,我们将正式介绍评估机器学习模型的不同方法。
培训,验证和测试集
评估模型总是归结为将可用数据分为三组:训练,验证和测试。您根据训练数据进行训练,并根据验证数据评估模型。一旦模型准备就绪,就可以在测试数据上进行最后一次测试,这意味着与生产数据尽可能相似。然后,您可以在生产中部署模型。
您可能会问,为什么没有两套:训练套和测试套?您将根据训练数据进行训练,并根据测试数据进行评估。简单得多!
原因是开发模型总是要调整其配置:例如,选择层数或层大小(称为模型的超参数,以将其与网络权重的参数区分开)。您可以通过使用验证数据上模型的性能作为反馈信号来进行此调整。从本质上讲,这种调整是一种学习形式:在某些参数空间中寻找良好的配置。因此,即使从未对模型进行过直接训练,根据其在验证集上的性能来调整模型的配置也可能很快导致对验证集的过度拟合。
这种现象的核心是信息泄漏的概念。每次根据模型在验证集中的性能调整模型的超参数时,一些有关验证数据的信息都会泄漏到模型中。如果仅对一个参数执行一次此操作,那么将泄漏很少的信息,并且您的验证集将保持可靠以评估模型。但是,如果您重复多次(运行一个实验,对验证集进行评估并最终修改模型),那么您将把与验证集有关的越来越多的信息泄漏到模型中。
归根结底,您将获得一个模型,该模型在验证数据上人为地表现良好,因为这是您对其进行优化的目的。您关心的是全新数据而不是验证数据的性能,因此需要使用一个完全不同的,从未见过的数据集来评估模型:测试数据集。您的模型不应访问任何有关测试集的信息,即使是间接访问也是如此。如果已根据测试集性能对模型进行了任何调整,那么您的概括性度量将存在缺陷。
将数据分为训练,验证和测试集看似很简单,但是当数据很少时,有几种先进的方法可以派上用场。让我们回顾一下三种经典的评估方法:简单的保留验证,K折验证和带混洗的迭代K折验证。我们还将讨论常识基线的使用,以检查您的培训是否在进行中。
简单的保留验证
将部分数据分开作为测试集。训练剩余的数据,并评估测试集。如前几节所述,为了防止信息泄漏,您不应基于测试集来调整模型,因此,您还应该保留验证集。
示意性地,保持验证类似于图TODO。以下清单显示了一个简单的实现。
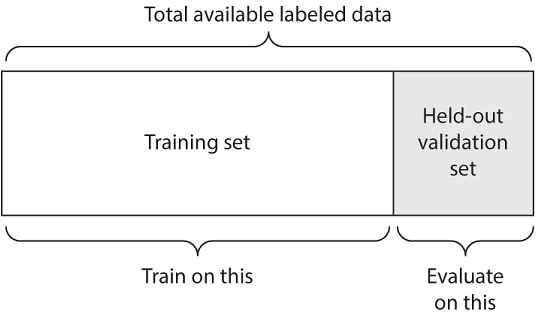
这是最简单的评估协议,并且存在一个缺陷:如果没有可用的数据,则您的验证和测试集可能包含的样本太少,无法从统计学上代表手头的数据。这很容易辨认:如果在拆分之前对数据进行了不同的随机混洗,最终得出的模型性能的测量方法大不相同,那么您就遇到了这个问题。 K-fold验证和迭代K-fold验证是解决此问题的两种方法,如下所述。
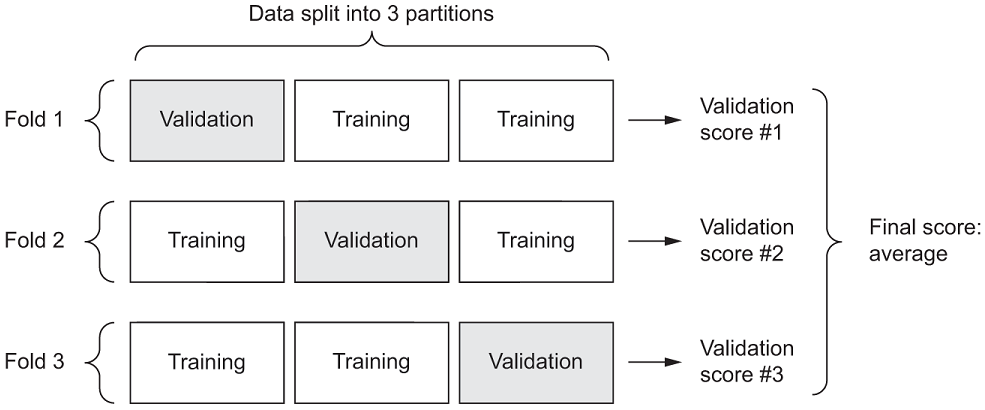
K折验证
使用这种方法,您可以将数据分成大小相等的K个分区。对于每个分区i,在剩余的K – 1个分区上训练模型,并在分区i上进行评估。这样,您的最终分数就是所获得的K分数的平均值。当模型的性能显示出基于训练测试拆分的显着方差时,此方法很有用。与保留验证一样,此方法也不能免除您使用不同的验证集进行模型校准的麻烦。 示意图中,K折交叉验证看起来像图TODO。列出TODO显示了一个简单的实现。
num_validation_samples = 10000
np.random.shuffle(data)
validation_data = data[:num_validation_samples]
data = data[num_validation_samples:]
training_data = data[:]
model = get_model()
model.train(training_data)
validation_score = model.evaluate(validation_data)
# At this point you can tune your model,
# retrain it, evaluate it, tune it again...
model = get_model()
model.train(np.concatenate([training_data,
validation_data]))
test_score = model.evaluate(test_data)
通过改组进行迭代的K折验证
这是针对您可用数据相对较少并且需要尽可能精确地评估模型的情况。我发现它在Kaggle比赛中非常有用。它包括多次应用K倍验证,在将数据拆分为K方式之前,每次都要对数据进行改组。最终分数是在每次K折验证中获得的分数的平均值。请注意,您最终需要训练和评估P×K模型(其中P是您使用的迭代次数),这可能会非常昂贵。
打破常识性基准
除了可用的不同评估协议之外,您还应该了解的最后一件事是使用常识性基准。 训练深度学习模型有点像按下按钮以在并行世界中发射火箭。您听不到或看不到它。您无法观察到多种学习过程-它是在具有数千个维度的空间中发生的,即使将其投影到3D,也无法解释它。唯一的反馈就是您的验证指标,例如隐形火箭上的高度计。
尤为重要的一点是,要能够分辨出您是否正在起步。您开始的海拔高度是多少?您的模型的准确度似乎为15%,这有什么好处吗?在开始使用数据集之前,应始终选择一个简单的基准,然后尝试将其击败。如果您超过该阈值,您就会知道自己做对了:您的模型实际上是在使用输入数据中的信息进行广泛的预测-您可以继续。该基准可以是随机分类器的性能,也可以是您可以想象的最简单的非机器学习技术的性能。
例如,在MNIST的数字分类示例中,简单的基线将是验证精度大于0.1(随机分类器);在IMDB示例中,验证精度将大于0.5。在路透社的例子中,由于阶级的不平衡,它将在0.18-0.19左右。如果您遇到二进制分类问题,其中90%的样本属于A类,而10%的样本属于B类,则始终预测A的分类器的验证精度已经达到0.9,因此您需要做得更好。
当您开始解决以前没有人解决过的问题时,拥有一个常识性基准是至关重要的。如果您无法解决一个简单的解决方案,那么您的模型将一文不值-也许您使用了错误的模型,或者也许刚开始使用机器学习无法解决您要解决的问题。是时候回到绘图板上了。
关于模型评估的注意事项
选择评估协议时,请注意以下几点:
- 数据代表性—您希望训练集和测试集都可以代表手头的数据。例如,如果您尝试对数字图像进行分类,并且从样本数组开始,按样本的类别对样本进行排序,则将数组的前80%作为训练集,其余的20%作为训练集因为您的测试集将导致您的训练集仅包含课程0–7,而您的测试集仅包含课程8–9。这似乎是一个荒谬的错误,但出奇的普遍。因此,您通常应在将数据分为训练集和测试集之前将数据随机洗牌。
- 时间之箭—如果您要根据给定的过去来预测未来(例如,明天的天气,股票走势等),则在分割数据之前不要随意洗牌,因为这样做会产生时间上的变化泄漏:您的模型将有效地接受来自未来数据的培训。在这种情况下,您应始终确保测试集中的所有数据都在训练集中的数据之后。
- 数据中的冗余-如果数据中的某些数据点出现两次(与实际数据相当普遍),则将数据混排并将其分为训练集和验证集将导致训练和验证集之间的冗余。实际上,您将对部分训练数据进行测试,这是您最糟糕的事情!确保训练集和验证集不相交。
评估模型性能的可靠方法是,您将能够监控机器学习的核心压力-在优化与泛化,欠拟合与过拟合之间。