

这是我参与8月更文挑战的第31天,活动详情查看:8月更文挑战
软硬件环境
- ubuntu 18.04 64bit
- numpy 1.12.1
欧几里得距离
欧几里得距离,又称欧氏距离,是最常见的距离度量,衡量的是多维空间中各个点之间的绝对距离。在计算相似度(比如人脸识别)的场景下,欧几里得距离是比较直观、比较常见的一种相似度算法。欧氏距离越小,相似度越大;欧氏距离越大,相似度越小。
来自中文版维基百科的定义
在数学中,欧几里得距离或欧几里得度量是欧几里得空间中两点间“普通”(即直线)距离。使用这个距离,欧氏空间成为度量空间。相关联的范数称为欧几里得范数。较早的文献称之为毕达哥拉斯度量。
欧几里得距离的数学公式
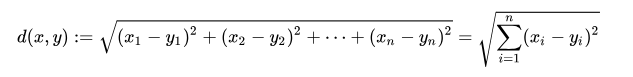
代码实现
我们使用 numpy 这个科学计算库来计算欧几里得距离,代码也非常简单
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Date : 2018-08-17 16:31:07
# @Author : xugaoxiang (djstava@gmail.com)
# @Link : link
# @Version : 1.0.0
import numpy as np
def get_edclidean_distance(vect1,vect2):
dist = np.sqrt(np.sum(np.square(vect1 - vect2)))
# 或者用numpy内建方法
# dist = numpy.linalg.norm(vect1 - vect2)
return dist
if __name__ == '__main__':
vect1 = np.array([1,2,3])
vect2 = np.array([4,5,6])
print(get_edclidean_distance(vect1, vect2))
执行结果显示
5.19615242271
曼哈顿距离
维基百科上给的定义
计程车几何(Taxicab geometry)或曼哈顿距离(Manhattan distance or Manhattan length)或方格线距离是由十九世纪的赫尔曼·闵可夫斯基所创辞汇,为欧几里得几何度量空间的几何学之用语,用以标明两个点上在标准坐标系上的绝对轴距之总和。
想象你在曼哈顿,要从一个十字路口开车到另外一个十字路口,实际驾驶距离就是这个“曼哈顿距离”。而这也是曼哈顿距离名称的来源,曼哈顿距离也称为城市街区距离。
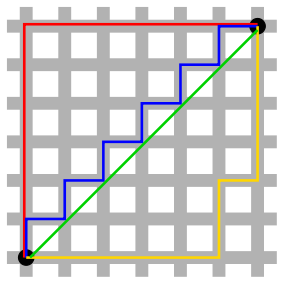
在上图中,绿线是欧几里得距离,红线是曼哈顿距离,蓝线和黄线是等价的曼哈顿距离。
二维平面两点a(x1,y1)与b(x2,y2)间的曼哈顿距离
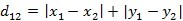
两个n维向量a(x11,x12,…,x1k)与 b(x21,x22,…,x2k)间的曼哈顿距离
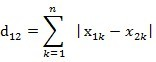
代码实现
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Date : 2018-08-20 16:10:23
# @Author : xugaoxiang (djstava@gmail.com)
# @Link : link
# @Version : 1.0.0
import os
import numpy as np
def get_manhattan_distance(vect1, vect2):
dist = np.sum(np.abs(vect1 - vect2))
# 或者使用内建方法
# dist = np.linalg.norm(vect1 - vect2, ord=1)
return dist
if __name__ == '__main__':
vect1 = np.array([1, 2, 3])
vect2 = np.array([4, 5, 6])
dist = get_manhattan_distance(vect1, vect2)
print(dist)
输出结果
9
K近邻算法
K-近邻即K Nearest Neighbor,简写为KNN,它是一种分类和回归算法,是最简单的机器学习算法之一。它的思路是:在特征空间中,如果一个样本附近的k个最近(即特征空间中最邻近)样本的大多数属于某一个类别,则该样本也属于这个类别。
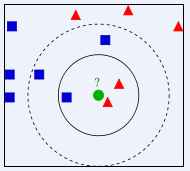
看上面的图,已知有2个类别,红色的三角形和蓝色的正方形,现在我们要判断中间的那个绿色的圆是属于哪一类?使用KNN,就从它的邻居下手,但需要看多少个邻居呢?
K=3,绿色圆点的最近的3个邻居是2个红色三角形和1个蓝色正方形,少数从属于多数,基于统计的方法,就认为绿色的圆属于红色三角形这一类K=5,绿色圆点的最近的5个邻居是2个红色三角形和3个蓝色正方形,还是少数从属于多数,基于统计的方法,就认为绿色的圆属于蓝色正方形这一类
可以看到,K值的选择,对我们最后的结果影响很大。K值越小,很容易受到单个个体的影响,K值太大,很容易受到较远的特殊距离的影响。这里讲到的距离,常见的计算方法如上面的欧几里得距离和曼哈顿距离
那K值应该如何设定呢?
很不幸,这里没有一个明确的结论。K的取值受到问题本身和数据集大小的影响,很多时候,需要自己进行多次的尝试,然后选择最佳的值。
KNN的缺点
KNN需要计算与所有样本之间的距离,这样的话,计算量就很大,效率很低,很难应用到较大的数据集当中。
代码示例
sklearn这个库,提供了完整的KNN实现,使用起来也非常简单,通过pip install scikit-learn安装
from sklearn.neighbors import KNeighborsClassifier
...
# n_neighbors就是K值
knn_classifier = KNeighborsClassifier(n_neighbors=5)
knn_classifier.fit(x_train, y_train)
# X_test是待分类的数据
pred = knn_classifier.predict(X_test)
