这是我参与8月更文挑战的第7天,活动详情查看:8月更文挑战。
原文地址:Simplest artificial neural network
原文作者:Givi Odikadze(已授权)
译者 & 校正:HelloGitHub-小熊熊 & 卤蛋

导言
我不会机器学习,但上个月我在 GitHub 上发现了一个极简、入门级的神经网络教程。它简洁易懂能用一行公式说明白的道理,不多写一句废话,我看后大呼过瘾。
这么好的东西得让更多人看到,但原文是英文的无法直接分享,所以得先联系作者拿到翻译的授权,然后由小熊熊翻译了这个项目,最后才有您看到的这篇文章。过程艰辛耗时一个月实属不易,如果您看完觉得还不错,欢迎点赞、分享给更多人。
内容分为两部分:
- 第一部分:最简单的人工神经网络
- 第二部分:最基础的反向传播算法
人工神经网络是人工智能的基础,只有夯实基础,才能玩转 AI 魔法!
温馨提示:公式虽多但只是看起来唬人,实际耐下心读并不难懂。下面正文开始!
一、最简单的人工神经网络
通过理论和代码解释和演示的最简单的人工神经网络。
示例代码:github.com/gokadin/ai-…
理论
模拟神经元
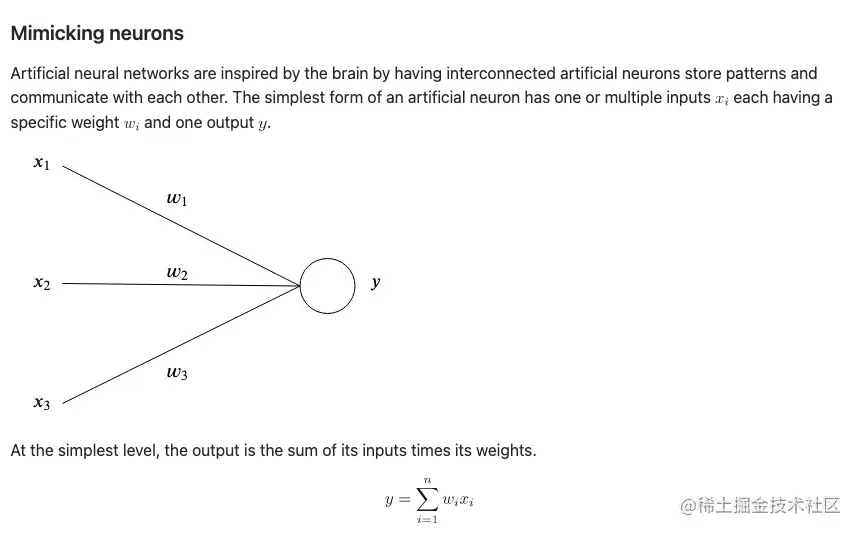
受人脑工作机制的启发,人工神经网络有着相互连接的模拟神经元,用于存储模式和相互沟通。一个模拟神经元最简单的形式是有一个或多个输入值 xi和一个输出值 y ,其中每个 xi 有一个权重 wi 。
拿最简单的来说,输出值就是输入值乘以权重之后的总和。
y=i=1∑nwixi
一个简单的例子
网络的作用在于通过多个参数 w 模拟一个复杂的函数,从而可以在给定一系列输入值 x 的时候得到一个特定的输出值 y ,而这些参数 w 通常是我们自身难以拟定的。
假设我们现在的一个网络有两个输入值 x1=0.2 , x2=0.4,它们对应两个权重值 w1 和 w2 。
现在我们需要调整权重值,从而使得它们可以产生我们预设的输出值。
在初始化时,因为我们不知晓最优值,往往是对权重随机赋值,这里我们为了简单,将它们都初始化为 1 。

这种情况下,我们得到的就是
y=x1w1+x2w2=0.2∗1+0.4∗1=0.6
误差值
如果输出值 y 与我们期望的输出值不一致,那就有了误差。
例如,如果我们希望目标值是 t=0.5 ,那么这里相差值就是
y−t=0.6−0.5=0.1
通常我们会采用方差(也就是代价函数)来衡量误差:
E=21(y−t)2
如果有多套输入输出值,那么误差就是每组方差的平均值。
E=2n1(yi−ti)2
我们用方差来衡量得到的输出值与我们期望的目标值之间的差距。通过平方的形式就可以去除负偏离值的影响,更加凸显那些偏离较大的偏差值(不管正负)。
为了纠正误差,我们需要调整权重值,以使得结果趋近于我们的目标值。在我们这个例子中,将 w1 从 1.0 降到 0.5 就可以达到目标,因为
y=t=0.2∗0.5+0.4∗1.0=0.5
然而,神经网络往往涉及到许多不同的输入和输出值,这种情况下我们就需要一个学习算法来帮我们自动完成这一步。
梯度下降
现在是要借助误差来帮我们找到应该被调整的权重值,从而使得误差最小化。但在这之前,让我们了解一下梯度的概念。
什么是梯度?
梯度本质上是指向一个函数最大斜率的矢量。我们采用 ▽ 来表示梯度,简单说来,它就是函数变量偏导数的矢量形式。
对于一个双变量函数,它采用如下形式表示:
▽f(x,y)=[fx,fy]=[ðxðf(x,y),ðyðf(x,y)]
让我们用一些数字来模拟一个简单的例子。假设我们有一个函数是 f(x,y)=2x2+3y3,那么梯度将是
▽f(x,y)=[4x,9y2]
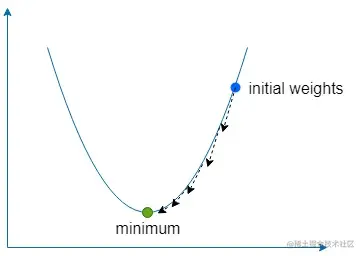
什么是梯度下降?
下降则可以简单理解为通过梯度来找到我们函数最大斜率的方向,然后通过反方向小步幅的多次尝试,从而找到使函数全局(有时是局部)误差值最小的权重。
我们采用一个称为学习率的常量来表示这个反方向的小步幅,在公式中我们用 ε 来进行表征。
如果 ε 取值太大,那有可能直接错过最小值,但如果取值太小,那我们的网络就会花费更久的时间来学习,而且也有可能陷入一个浅局部最小值。
对于我们例子中的两个权重值 w1 和 w2 ,我们需要找到这两个权重值相较于误差函数的梯度
▽wE=<ðw1ðE,ðw2ðE>
还记得我们上面的公式 E=21(y−t)2 和 y=x1w1+x2w2 吗?对于 w1 和 w2 ,我们可以将其带入并通过微积分中的链式求导法则来分别计算其梯度
ðwiðE=ðyðEðwiðy=ðyð(21(y−t)2)ðwið(xiwi)=(y−t)xi
简洁起见,后面我们将采用 δ 这个术语来表示 ðyðE=y−t 。
一旦我们有了梯度,将我们拟定的学习率 ε 带入,可以通过如下方式来更新权重值:
w1=w1−ε▽w1E=w1−εδx1
w2=w2−ε▽w2E=w2−εδx2
然后重复这个过程,直到误差值最小并趋近于零。
代码示例
附带的示例采用梯度下降法,将如下数据集训练成有两个输入值和一个输出值的神经网络:
x=[1.01.01.00.0]y′=[0.01.0]
一旦训练成功,这个网络将会在输入两个 1 时输出 ~0,在输入 1 和 0 时,输出 ~1 。
怎么运行?
Go
PS D:\github\ai-simplest-network-master\src> go build -o bin/test.exe
PS D:\github\ai-simplest-network-master\bin> ./test.exe
err: 1.7930306267024234
err: 1.1763080417089242
……
err: 0.00011642621631266815
err: 0.00010770190838306002
err: 9.963134967988221e-05
Finished after 111 iterations
Results ----------------------
[1 1] => [0.007421243532258703]
[1 0] => [0.9879921757260246]
Docker
docker build -t simplest-network .
docker run --rm simplest-network
二、最基础的反向传播算法
反向传播(英语:Backpropagation,缩写为 BP)是“误差反向传播”的简称,是一种与最优化方法(如梯度下降法)结合使用的,用来训练人工神经网络的常见方法。
反向传播技术可以用来训练至少有一个隐藏层的神经网络。下面就来从理论出发结合代码拿下反向传播算法。
示例代码:github.com/gokadin/ai-…
理论
感知机介绍
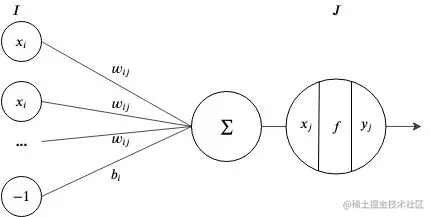
感知机是这样一个处理单元:它接受输入 x, 采用激活函数 f 对其进行转换,并输出结果 y 。
在一个神经网络,输入值是前一层节点输出值的权重加成总和,再加上前一层的误差:
xj=i=1∑Ixiwij+bi
如果我们把误差当作层中另外的一个常量为 -1 的节点,那么我们可以简化这个公式为
xj=i=1∑I+1xiwij
激活函数
为什么我们需要激活函数呢?如果没有,我们每个节点的输出都会是线性的,从而让整个神经网络都会是基于输入值的一个线性运算后的输出。因为线性函数组合仍然是线性的,所以必须要引入非线性函数,才能让神经网络有区别于线性回归模型。
针对 x=∑xw,典型的激活函数有以下形式:
Sigmoid 函数 : y=1+e−x1
线性整流函数:y=max(0,x)
tanh 函数: y=tanh(x)
反向传播
反向传播算法可以用来训练人工神经网络,特别是针对具有多于两层的网络。
原理是采用 forward pass 来计算网络输出值和误差,再根据误差梯度反向更新输入层的权重值。
术语
- xi,xj,xk 分别是 I, J, K 层节点的输入值。
- yi,yj,yk 分别是 I, J, K 层节点的输出值。
- yk′ 是 K 输出节点的期望输出值。
- wij,wjk 分别是 I 到 J 层和 J 到 K 层的权重值。
- t 代表 T 组关联中当前的一组关联。
在下面的示例中,我们将对不同层节点采用以下激活函数:
- 输入层 -> 恒等函数
- 隐藏层 -> Sigmoid 函数
- 输出层 -> 恒等函数
The forward pass
在 forward pass 中,我们在输入层进行输入,在输出层得到结果。
对于隐藏层的每个节点的输入就是输入层输入值的加权总和:
xj=i=1∑Iwijyi
因为隐藏层的激活函数是 sigmoid,那么输出将会是:
yj=fj(xj)=1+e−xj1
同样,输出层的输入值则是
xk=j=1∑Jwjkyj
因为我们赋予了恒等函数做为激活函数,所以这一层的输出将等同于输入值。
yk=fk(xk)=xk
一旦输入值通过网络进行传播,我们就可以计算出误差值。如果有多套关联,还记得我们第一部分学习的方差吗?这里,我们就可以采用平均方差来计算误差。
E=i=1∑IEt=2T1t=1∑T(ykt−ykt′)2
The backward pass
现在我们已经得到了误差,就可以通过反向传输,来用误差来修正网络的权重值。
通过第一部分的学习,我们知道对权重的调整可以基于误差对权重的偏导数乘以学习率,即如下形式
Δwjk=−ε∂wjk∂E
我们通过链式法则计算出误差梯度,如下:
∂wjk∂E=∂xk∂E∂wjk∂xk
∂xk∂E=∂yk∂E∂xk∂yk=∂yk∂(21(yk−yk′)2)∂xk∂(xk)=yk−yk′=δk
∂wjk∂xk=∂wjk∂(yjwjk)=yj
因此,对权重的调整即为 Δwjk=−εδkyj
对于多个关联,那么对权重的调整将为每个关联的权重调整值之和 Δwjk=−ε∑t=1Tδkyjt
类似地,对于隐藏层之间的权重调整,继续以上面的例子为例,输入层和第一个隐藏层之间的权重调整值为
Δwij=−ε∂wij∂E
∂wij∂E=∂xj∂E∂wij∂xj=δjyi
那么,基于所有关联的权重调整即为每次关联计算得到的调整值之和 Δwij=−ε∑t=1Tδjtyit
δj 计算
这里, 我们对 δj 可以再做进一步的探索。上文中,我们看到 ∂wij∂E=∂xj∂E∂wij∂xj 。
对前半部分的 ∂xj∂E ,我们可以有
∂xj∂E=∂yj∂Edxjdyj
∂yj∂E=k=1∑K∂xk∂E∂yj∂xk=k=1∑Kδkwjk
对后半部分的 dxjdyj ,因为我们在这一层采用了 sigmoid 函数,我们知道,sigmoid 函数的导数形式是 f(x)(1−f(x)) ,因此,有
dxjdyj=f′(xj)=f(xj)(1−f(xj))=yj(1−yj)
综上,便可以得到 δj 的计算公式如下
δj=yj(1−yj)k=1∑Kδkwjk
算法总结
首先,对网络权重值赋予一个小的随机值。
重复以下步骤,直到误差为0 :
- 对每次关联,通过神经网络向前传输,得到输出值
- 计算每个输出节点的误差 (δk=yk−yk′)
- 叠加计算每个输出权重的梯度 (▽wjkE=δkyj)
- 计算隐藏层每个节点的 δ (δj=yj(1−yj)∑k=1Kδkwjk)
- 叠加计算每个隐藏层权重的梯度 (▽wijE=δjyj)
- 更新所有权重值,重置叠加梯度 (w=w−ε▽E)
图解反向传播
在这个示例中,我们通过真实数据来模拟神经网络中的每个步骤。输入值是[1.0, 1.0],输出期望值为 [0.5]。为了简化,我们将初始化权重设为 0.5 (虽然在实际操作中,经常会采用随机值)。对于输入、隐藏和输出层,我们分别采用恒等函数、 sigmoid 函数 和恒等函数作为激活函数,学习率 ε 则定为 0.01 。
Forward pass
运算一开始,我们将输入层的节点输入值设为 x1=1.0,x2=1.0 。
因为我们对输入层采用的是恒等函数作为激活函数,因此有 yi=xi=1.0 。
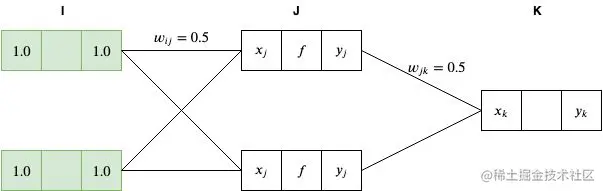
接下来,我们通过对前一层的加权总和将网络向前传递到 J 层,如下
xj=i=1∑Iyiwij=1.0∗0.5+1.0∗0.5=1.0

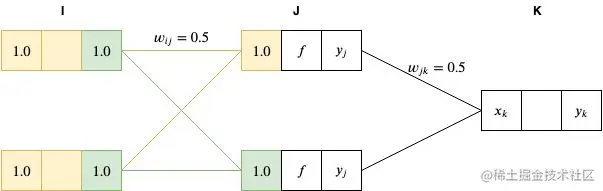
然后,我们将 J 层节点的值输入到 sigmoid 函数(f(x)=1+e−x1,将 x=1 代入,得到 0.731)进行激活。
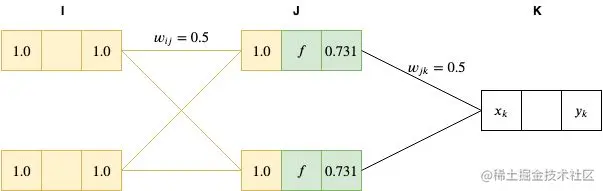
最后,我们将这个结果传递到最后的输出层。
xk=0.731∗0.5+0.731∗0.5=0.731
因为我们输出层的激活函数也是恒等函数,因此 yk=xk=0.731
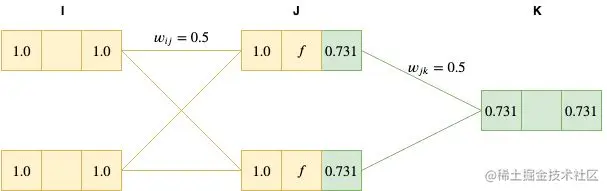
Backward pass
反向传播的第一步,是计算输出节点的 δ ,
δk=yk−yk′=0.731−0.5=0.231
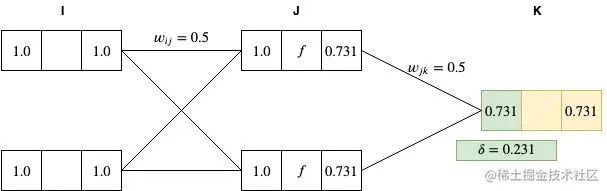
采用 δ 计算 J 和 K 两层节点间的权重梯度:▽wjkE=δkyj=0.231∗0.731=0.168861
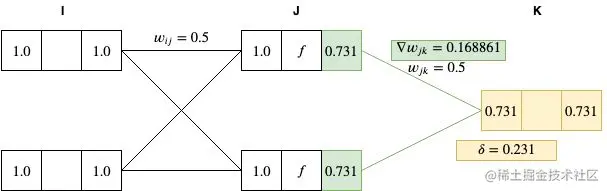
接下来,以同样的方法计算每个隐藏层的 δ 值(在本示例中,仅有一个隐藏层):
δj=yj(1−yj)k=1∑Kδkwjk=0.731∗(1−0.731)∗(0.5∗0.231)≈0.0227
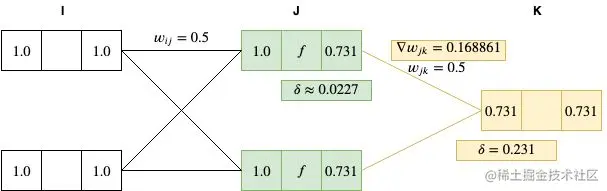
针对 I 和 J 层节点权重计算其梯度为:
▽wijE=δjyi=0.0227∗1=0.0227
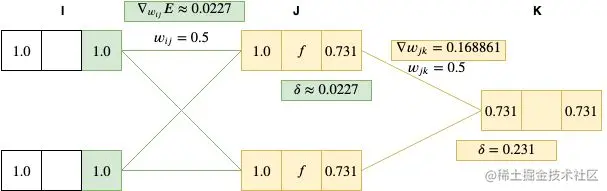
最后一步是用计算出的梯度更新所有的权重值。注意这里如果我们有多于一个的关联,那么便可以针对每组关联的梯度进行累计,然后更新权重值。
wij=wij−ε▽wijE=0.5−0.01∗0.0227=0.499773
wjk=wjk−ε▽wjkE=0.5−0.01∗0.168861=0.49831139
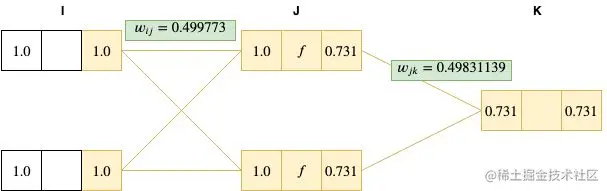
可以看到这个权重值变化很小,但如果我们用这个权重再跑一遍 forward pass,一般来说将会得到一个比之前更小的误差。让我们现在来看下……
第一遍我们得到的 y1=0.731,采用新的权重值计算得到 y2≈0.7285。
由此,y1−y1′=0.231,而 y2−y2′=0.2285。
可见,误差得到了减小!尽管减少值很小,但对于一个真实场景也是很有代表性的。按照该算法重复运行,一般就可以将误差最终减小到0,那么便完成了对神经网络的训练。
代码示例
本示例中,将一个 2X2X1 的网络训练出 XOR 运算符的效果。
x=[1.01.01.00.00.01.00.00.0]
y′=[0.01.01.00.0]
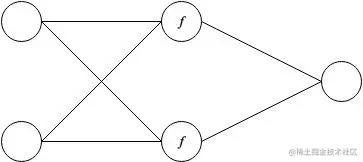
这里,f 是针对隐藏层的 sigmoid 激活函数。
注意,XOR 运算符是不能通过第一部分中的线性网络进行模拟的,因为数据集分布是非线性的。也就是你不能通过一条直线将 XOR 的四个输入值正确划分到两类中。如果我们将 sigmoid 函数换为恒等函数,这个网络也将是不可行的。
讲完这么多,轮到你自己来动手操作啦!试试采用不同的激活函数、学习率和网络拓扑,看看效果如何?
最后
恭喜看完本文!你学会了吗?
关注 HelloGitHub 公众号 第一时间收到更新。
还有更多开源项目的介绍和宝藏项目等待你的发现。


