

这是我参与8月更文挑战的第16天,活动详情查看:8月更文挑战
软硬兼环境
- windows 10 64bit
- anaconda with python 3.7
- nivdia gtx 1066
- opencv 4.4.0
- tesseract 5.0.0 alpha
简介
tesseract的OCR(Optical Character Recognition)引擎最先由HP实验室于1985年开始研发,后来转交给了google继续开发,现在项目托管在了github,在3.0版本后开始支持中文识别,目前已经发展到了5.0,支持多种操作系统。本文就来看看tesseract-ocr的基本安装、使用以及如何在python中去调用。
tesseract-ocr安装
官方的下载地址: tesseract-ocr.github.io/tessdoc/Dow…,这里下载的是windows的最新版 digi.bib.uni-mannheim.de/tesseract/t…
下载好后直接安装,在安装组件的时候将中文包也选上,因为我们要进行中文的文字识别
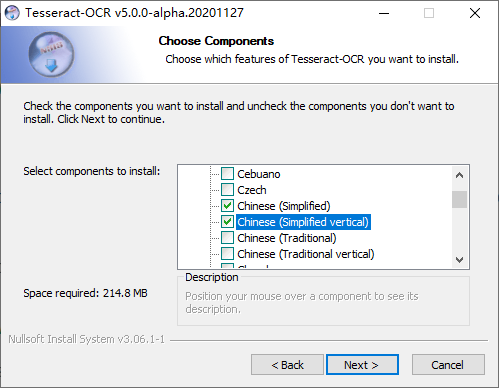
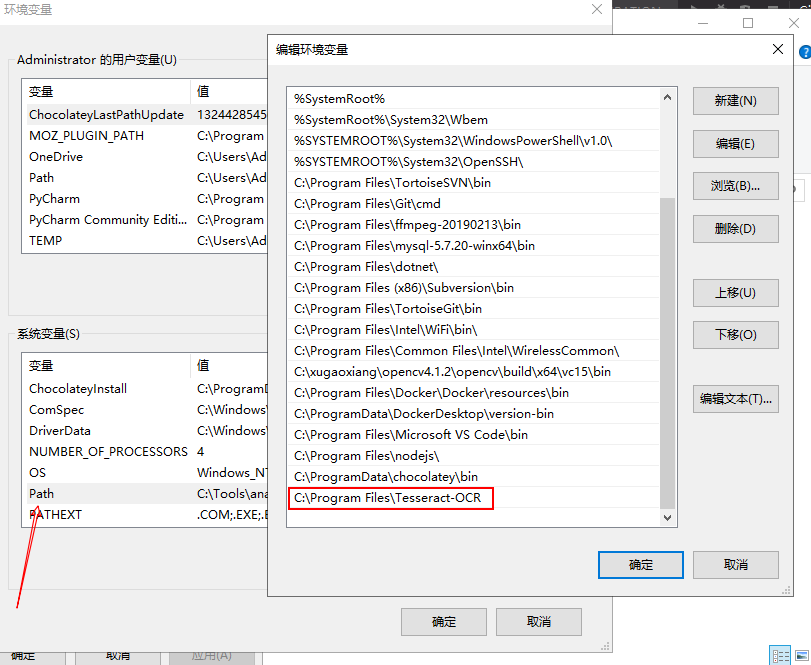
接下来设置2个系统环境变量,将tesseract-ocr的安装目录加入到PATH中,默认的安装路径是C:\Program Files\Tesseract-OCR
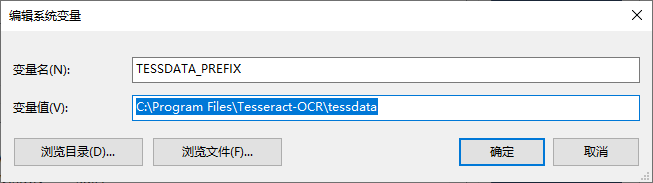
然后新建一个新的环境变量TESSDATA_PREFIX,其值是C:\Program Files\Tesseract-OCR\tessdata
如果自定义过安装路径的话,就对应着修改。
验证环境
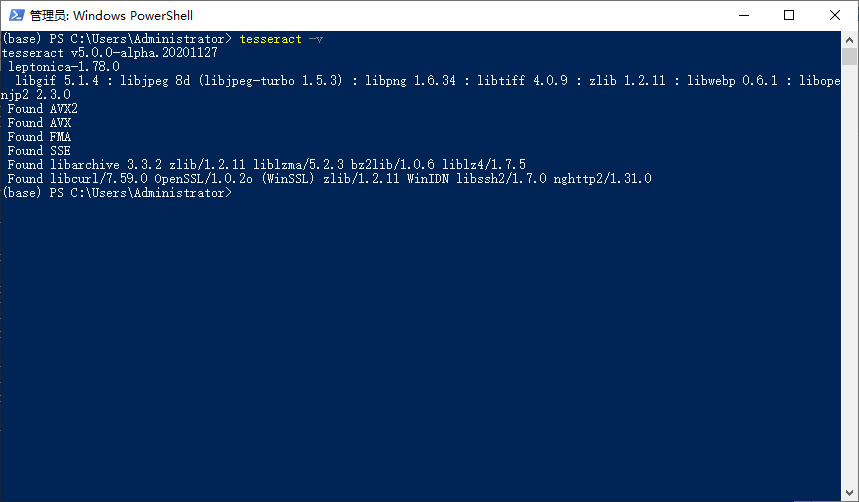
通过命令tesseract -v查看版本号
通过tesseract --list-langs,查看支持识别的语言
(base) PS C:\Users\Administrator> tesseract --list-langs
List of available languages (4):
chi_sim
chi_sim_vert
eng
osd
测试效果
找张包含中文的图片来测试下
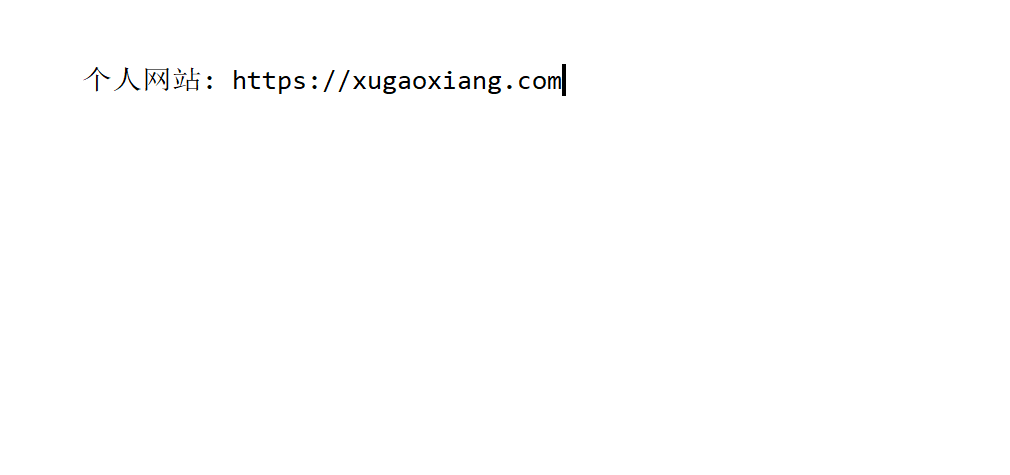
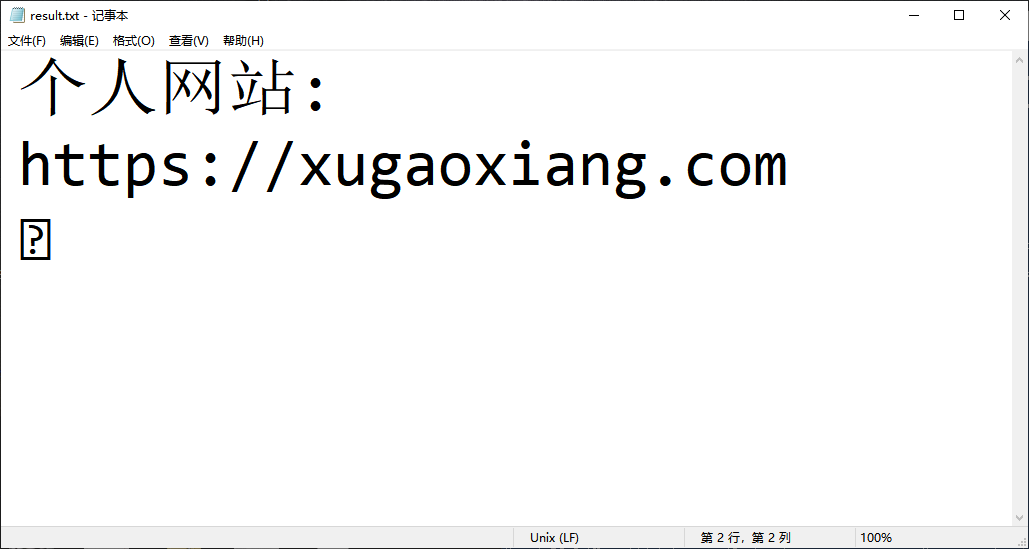
tesseract test.png result -l chi_sim
识别的结果会保存在一个result.txt文件中
在python中使用
这里需要用到一个第三方的库pytesseract,首先安装
pip install pytesseract
下面看个示例代码
import cv2
import sys
import pytesseract
if __name__ == '__main__':
if len(sys.argv) < 2:
print('Usage: python ocr_demo.py image.jpg')
sys.exit(1)
# 使用命令行参数
imPath = sys.argv[1]
# -l 识别中文
# --oem 使用LSTM作为OCR引擎,可选值为0、1、2、3;
# 0 Legacy engine only.
# 1 Neural nets LSTM engine only.
# 2 Legacy + LSTM engines.
# 3 Default, based on what is available.
# --psm 设置Page Segmentation模式为自动
config = ('-l chi_sim --oem 1 --psm 3')
im = cv2.imread(imPath, cv2.IMREAD_COLOR)
# 进行识别,本质上是调用tesseract命令行工具
text = pytesseract.image_to_string(im, config=config)
# 打印结果
print(text)
使用上面的测试图片运行代码,可以得到
(demo) PS C:\xugaoxiang\gogs\learnopencv\OCR> python .\ocr_demo.py C:\Users\Administrator\Desktop\test.png
个人网站: https://xugaoxiang.com
