在项目中遇到了树形数据的处理展示和筛选,觉得这个思路和处理方法很有必要记录下来一下,其中还出现了深拷贝相关的一些知识,记下来加深印象,防止忘记哦。
1.树形数据的介绍
首先,什么是树形数据呢,这其实是我自己不知道在哪看来的名字,不具有权威性,其实就是当一个数据需要有层级的表示出来的时候,就需要利用树形数据的形式。比如说如图:

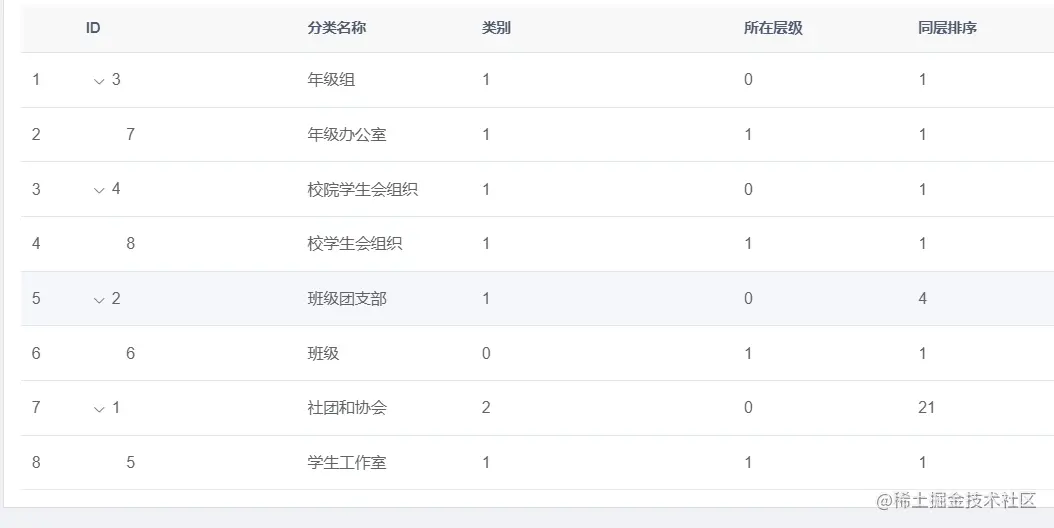
这是一个形容课程分类的数据,最上面一层的数据显然是name从“社团和协会”到“校院学生会组织”,可以看到他们的id依次从1-4,然后他们的pid为0,意思他们没有父亲节点了。
然后我们再往下看一层,也就是id从5-8,然后他们的pid可以看到分别是1-4,什么意思呢?也就是说他们的父亲节点分别是id为1-4的数据。也就是说id=1的“社团和协会”下面有一个子节点,是id=5的"学生工作室"(因为"学生工作室"的pid=1),然后id=5的"学生工作室"肯定也会有其他的子节点,这些子节点的pid=5。
到这里应该就可以理解树形数据的概念了吧,就是每个存在数据库的数据不仅仅有自己的id,也有他父节点的id(pid),这样就可以方便清晰的表示父子之间的层级关系了!
2.树形数据的展示
那么拿到这些数据之后,我们应该怎么把他以层级的形式展示出来呢?
我们可以使用Element组件里面的table表格组件,如图:
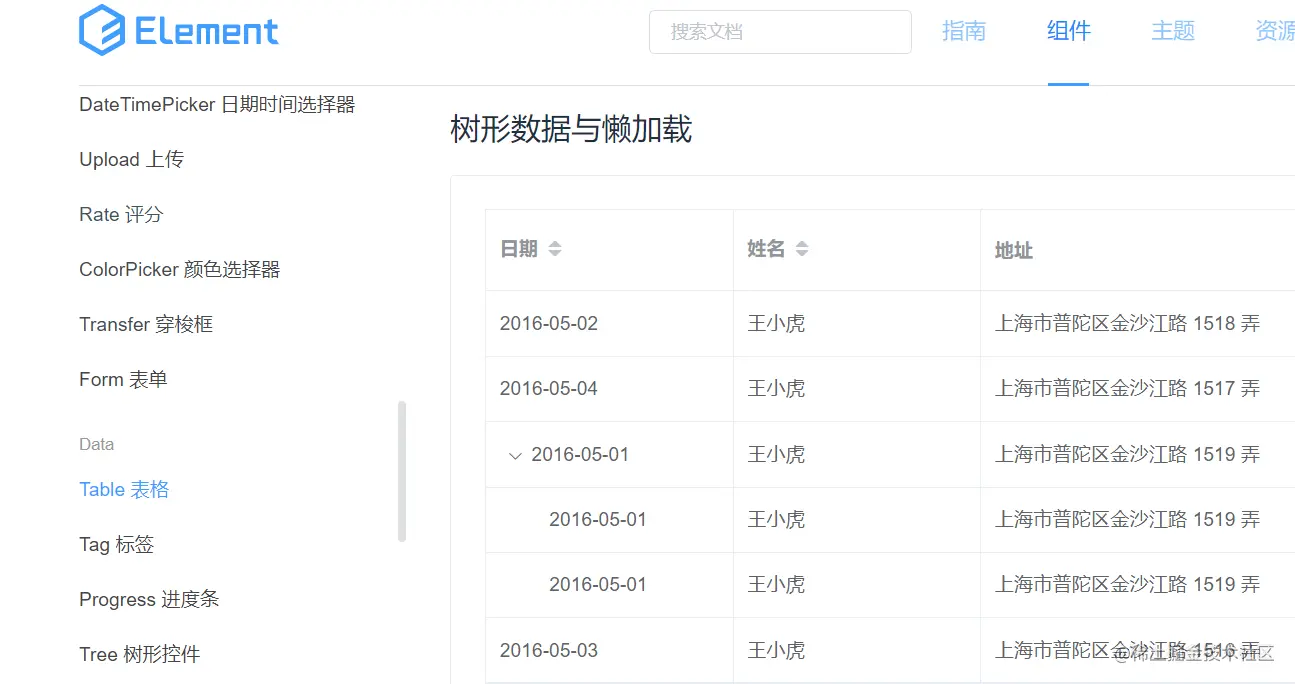
我们点开看看他是怎么用的,发现他需要数组的形式是这样的,如图:

显然和我们收到的数据格式不符合,他需要把每个数据的孩子节点装在children数组里面,而不是之间用pid来表示父子之间的关系,所以我们需要动手来讲原来的扁平数据转换成真正的树形数据(有多层)。
所以需要我们写个算法来转换一下,显然是递归。代码如下:
export function filterGroupClassificationList(data)
{
let filter = (father_id) => {
let array = []
data.forEach(item => {
if (item.parentId === father_id) {
array.push(item)
}
})
array.forEach(item => {
let temp = filter(item.id)
if (temp.length != 0) {
item.children = temp
}
})
return array
}
let filterArray = filter(0)
return filterArray
}
我相信我这个注释已经写的很清楚了,算法是好兄弟想出来的,我精简了一下,好兄弟真的厉害!
但是不仅仅是这个,因为数据中有个sort字段要用来排序,而我们还只是把这个数据变成了树形的,但是还没排序,所有我们还得写一个排序函数来给这个树形排序,同样也是递归了,代码如下:
let sortWay = array => {
array.sort(function(a, b) {
(a.sort-b.sort意思是按sort从小到大排序)
return a.sort - b.sort
})
array.forEach(item => {
item.children && sortWay(item.children)
})
return array
}
所以把他们合起来之后代码如下:
export function filterGroupClassificationList(data)
{
let filter = (father_id) => {
let array = []
data.forEach(item => {
if (item.parentId === father_id) {
array.push(item)
}
})
array.forEach(item => {
let temp = filter(item.id)
if (temp.length != 0) {
item.children = temp
}
})
return array
}
let sortWay = array => {
array.sort(function(a, b) {
(a.sort-b.sort意思是按sort从小到大排序)
return a.sort - b.sort
})
array.forEach(item => {
item.children && sortWay(item.children)
})
return array
}
let filterArray = filter(0)
return sortWay(filterArray);
}
排序完成之后我们就可以在项目中引入这个函数然后用来过滤,之后得到的数据如下了:

可以看出来现在的数据第一层为0,1,2,3,然后0里面还有个children对象,里面装的就是pid=3的数据(因为0数据里面的id=3),所以到现在我们就过滤成功了!
然后让我们来展示出来吧!
element里面的table参数如下:
<el-table
:data="treeData"
row-key="id"
v-loading="loading"
default-expand-all
:tree-props="{
children: 'children',
hasChildren: 'hasChildren'
}"
>
效果如图:
3.其他需求的扩展
你以为到这里就结束了吗?nonono,项目中还有一个需求,就是要能修改同层的所有数据的排序,这是什么意思呢,其实核心问题就是要你找到该数据的所有兄弟们(同一个pid的数组),然后更改他们的排序就ok,那怎么找一个数据的兄弟们呢?有几种方案:
1.第一种是我一瞬间想到了,直接遍历我们这个树,然后找到id等于该数据pid的数据(也就是该元素的父亲),然后父亲的children对象里面装的就是所有兄弟们的信息了。但是这样肯定不好,又要递归遍历整个数,性能可能不太行。pass!
2.然后我仔细一思考,为啥要遍历树呢,为什么我们不能遍历扁平数据呢?也就是一开始没有过滤的数据,他们都在一个对象数组里面装着呢,我们只要遍历这个数组,找到所有pid相等的数据,把他们push到一个数组里面即可了。这样就比遍历数要省事情一些了。
3.然后好兄弟又想到个更省时间复杂度的办法,我堪称奇妙,就是借鉴了vue里面父子组件存储信息的方式,子组件里面还包含一个_parent_对象来存储父亲的数据,这样的话我们找兄弟的数据不只要找该数组的_parent_对象的children对象就可以了吗?
那么有好兄弟想问了:那么顶层的数据呢?他们又没有父亲?
顶层的数据不就是过滤之后的那个数组?他们没有父亲就给他们的_parent_对象赋个null就好了。
所以问题的关键又在于怎么给每个数组都加一个_parent_对象来存储他父节点的数据呢?其实不难,直接在原来递归的算法中加个一个步骤就ok了,代码如下(其实就是传参的时候多传一个父亲对象,然后递归的时候给当前数据赋值他的父亲对象即可):
export function filterGroupClassificationList(data)
{
let filter = (father,father_id) => {
let array = []
data.forEach(item => {
if (item.parentId === father_id) {
array.push(item)
}
})
array.forEach(item => {
let temp = filter(item,item.id)
if (temp.length != 0) {
item.children = temp
}
item._parent_ = father;
})
return array
}
let filterArray = filter(null,0)
return filterArray
}
这样下来,我们每个数据都有他们的父亲对象了也就是_parent_对象了,效果如图:

我们可以看到id=7,parentId=3的孩子数据中有个_partent_对象,里面存着id=3(和子数据的parentId相同)的数据,显然这就是该孩子数据的父亲了,所以我们就成功啦!
4.又带来了新的问题
你以为又结束了?其实没有。这种方法虽然可以极大的节省时间复杂度,但是他又带来了新的问题!
当你需要对这个树形数组筛选(比如就是按名字搜索数据,也就是通过用户在搜索框输入的名字进行筛选)时,当然你可以让后端写好筛选,你只要发条件就好了,但是如果为了减少请求次数,我们要在前端对这个数据进行过滤的时候,我们就需要把这个数组深拷贝之后(因为筛选不能改变初始数组的值)和要筛选的条件(搜索的条件)传进一个函数然后再处理,那问题出在那里呢?重点来了:
问题就出在这个深拷贝!无论怎么深拷贝肯定是要遍历这个对象的,但是我们这个每个数据都有他的children(最底层没有children)和_parent_对象(第一层没有_parent_对象)的数组其实是个环!所以递归遍历的时候一定会报错,因为他是一个环!他遍历不完,因为可以从children对象往下遍历,也可以从_parent_对象往上遍历,所以递归就没有底了!所以这种方法的缺点就在这里,如果是前面几种方法只有children对象的话就可以自由使用递归遍历深拷贝,但是这种还需要在深拷贝时不让他走_parent_对象这条路:如果是用JSON.parse(JSON.stringify(data))的方法那就要在JSON.stringify中增加一个判断的函数,代码如下:
let filterArray = filterName(JSON.parse(JSON.stringify(data,((key,val) => {
if(key != '__parent__')
return val
}))),name)
return filterArray;
filterName为筛选函数,name为要筛选的名字条件参数,前面的那一串为深拷贝data之后返回的新数组,作为filterName函数的第一个参数传入,name是第二个参数。
深拷贝之后就在filterName里面写筛选函数就好了,思路就是遍历这个数,然后看数据中的name是否include的传入的name就ok,如果是的则push到数组就ok,然后返回这个数组就是筛选的结果了。
结束: 总的来说,其实方法都有他的好处和坏处,就看你怎么灵活使用了,还是老规矩,如果看到这里,且这个对你有帮助的话,记得点个赞点个关注再走吧,谢谢!


