

本文亮点
随着智能手机和信息通信技术的不断发展和普及,大规模的轨迹数据存储已经比较普遍,成为挖掘用户行为模式的重要来源,工作地和居住地是用户行为模式的重要表现,可以用于辅助智能城市的建设,比如优化通勤路线、产业布局、分析人口流动情况等等,从而减少交通拥堵、提高市民生活便利性和满意度等。但是现有的工作地居住地计算方法存在不同程度的问题,本文提出一种改进方案。
01 现有方法
目前的工作地居住地定位方法主要有两种,一是基于规则,一是基于模型;
基于规则的方法是通过业务经验设计逻辑,根据设定的统计指标选择工作地居住地。
比如基于汽车的数据会基于用户每天的起始点和终点,来统计频次、时长等指标,选择排名最高的作为工作地居住地;
基于基站的数据会统计用户连接每个基站的时间,选择工作时间连接时间最长且月度工作日连接次数/休息日连接次数最高的作为工作地;
基于模型的方法是通过聚类+有监督模型来定位工作地居住地,通过聚类来剔除噪声点,然后通过规则来生成特征,通过人工对工作地居住地进行标注,最后通过有监督模型来预测工作地和居住地。
02 现有方法局限性
基于规则的方法局限性比较大,不同行业都有自己的规则和特定结构的数据,不够通用;且难以穷尽所有规则,对于异常情况的适应性不够好,复杂且不够精确;
基于模型的方法需要进行人工标注,成本较高且整个计算流程比较复杂;准确率对特征的代表性和样本覆盖的广度依赖较大;
现有方法计算出的工作地居住地经常不符合业务逻辑,如正常的工作地应该大部分分布在写字楼、工业园区等 poi,少部分分布在餐厅、商场等其他各种类型的 poi;正常的居住地应该大部分分布在小区、别墅、公寓等 poi,少部分分布在其他各种类型的 poi;但是现有方法计算的结果受数据源影响较大,并不能保证这一点,导致可能大量的工作地出现在小区里,大量的居住地出现在写字楼或商场里等情况,导致业务不可用。
本文提出了一种更通用的计算方法,降低整个流程的复杂性并提高准确性;设计一种更贴近业务的计算方法,提高工作地居住地的可用性。
03 背景知识介绍
粗体
1、DBSCAN 聚类简介:
首先设定一个阈值 a,对于样本集中的每个点,以这个点为圆心,a 为半径划一个圆,被包含在这个圆中的点的个数记为 b(包括圆心);
然后再设定一个阈值 c,如果 b>=c,则把这个圆心叫做核心对象;
如果一个核心对象 A 被包含在另一个核心对象 B 的圆中,核心对象 B 被包含在另一个核心对象 C 的圆中,则称 A 到 C 是密度可达的;
如果核心对象 X 到核心对象 Y 密度可达,核心对象 Z 也密度可达,则 Y 和 Z 密度相连,找到最大的密度相连的样本集合,就是聚类的一个簇,如下图所示:
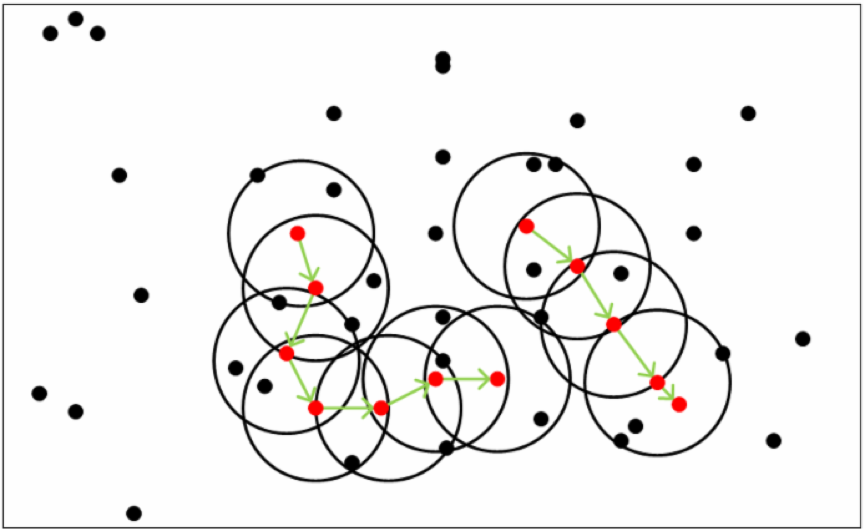
其优点在于:
可以对任意形状的稠密数据集进行聚类,适用于地理位置数据;相对的,K-Means 之类的聚类算法一般只适用于凸数据集;
可以在聚类的同时发现异常点,对数据集中的异常点不敏感;
聚类结果没有偏倚,相对的,K-Means 之类的聚类算法,初始值对聚类结果有很大影响。
2、加权几何平均数:
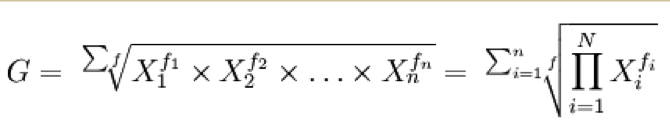
3、经纬度求中心点
Lat_i = lat_i * pi/180,i= 1,2,…,n
Lon_i = lon_i * pi/180,i= 1,2,…,n
xi = cos(Lat_i) * cos(Lon_i),i= 1,2,…,n
yi = cos(Lat_i) * sin(Lon_i) ,i= 1,2,…,n
zi = sin(Lat_i) ,i= 1,2,…,n
x = (x1 + x2 + ... + xn) / n
y = (y1 + y2 + ... + yn) / n
z = (z1 + z2 + ... + zn) / n
Lon = atan2(y, x)
Hyp = sqrt(x
x + y
y)
Lat = atan2(z, hyp)
lon_center = Lon * 180/pi
lat_center = Lat * 180/pi
04 具体方法
-
对用户近 X 个月的轨迹数据做预处理,清洗掉其中的异常数据和节假日数据(大小长假,但不包括周末);
-
划分工作时间和休息时间;
-
爬取 poi 数据数据,并对 poi 数据进行清洗;
-
判断用户的轨迹数据是否落在某类 poi 中:
有 poi 边界的直接使用 poi 边界判断;
没有 poi 边界的,使用 poi 点经纬度所在 geohash8 及周围一圈 geohash8 判断(九宫格);
地铁站以各出口经纬度点为中心点,生成边长 100m 的正方形,即 poi 点的经纬度加减 0.0005 做判断;
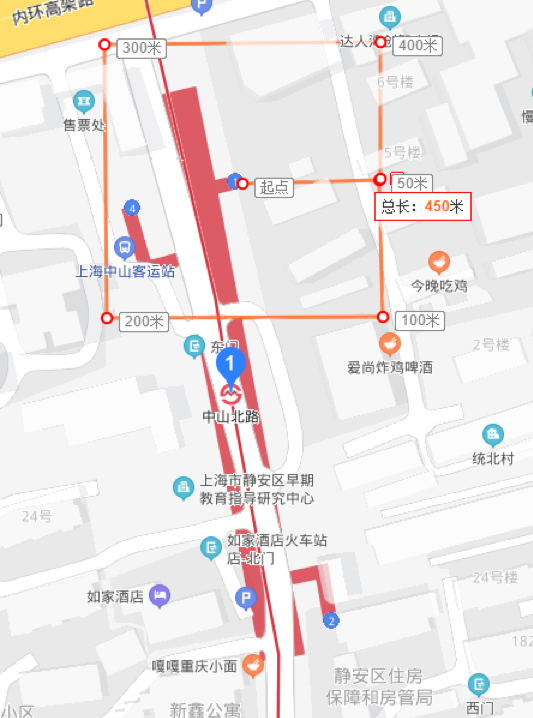
- 根据计算工作地还是计算居住地,给落在不同类别 poi 中的点以不同的权重;
比如计算工作地时,如果点落在写字楼中,给一个较高的权重;
- 对于落入不同的时间段的轨迹点,同样给不同的权重;
比如计算工作地时,工作时间会给一个比较高的权重;
-
根据 5、6 点中给出的权重,分别对每个用户的工作时间和居住时间轨迹数据进行加权 DBSCAN 聚类,并调优参数;
-
计算每个簇内的工作/休息时间点数、工作/休息时间天数,
计算每个用户的工作/休息时间总点数,
计算用户的每个簇内工作/休息时间点数,占该用户工作/休息时间总点数比例,
计算用户的每个簇内工作/休息时间天数,占该用户工作/休息时间总天数比例,
对总点数的比例和总天数的比例计算加权几何平均数,得到每个簇的得分,工作时间得分第一的簇为工作地,休息时间得分第一的簇为居住地;
举例:第一个例子最终选择的 B 类,第二个例子是 C 类
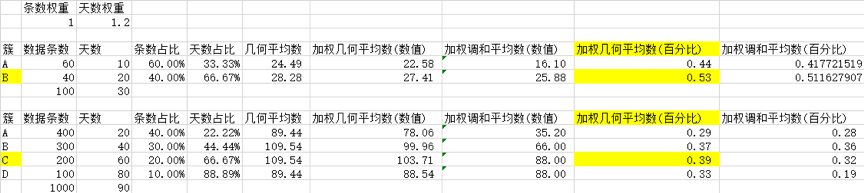
-
对工作地簇和居住地簇根据公式分别计算其地理中心点,得到工作地居住地的最终位置;
-
根据工作地居住地簇中的活跃天数和点数,给出相应的工作地居住地置信度,活跃天数越多,置信度越高,点数越多,置信度越高;
-
因为即使采用了上述加权聚类的方法,也不能保证结果完全符合业务逻辑,所以给出工作地/居住地一定范围内各类 poi 的类型及与工作地/居住地的距离,以便于业务方自己根据距离来对工作地/居住地进行筛选。
欲知更多精彩内容,关注官网

