

大数据实践第一篇,面向小白编程
Ubuntu的操作
1.下载文件
1.1下载ubuntu镜像文件
注:推荐使用16.04或是18.04版本
下载地址链接pub.mirrors.aliyun.com
进入下载页面,如下图,选择版本进入选择 ubuntu-X.X.X-desktop-amd64.iso 下载即可
1.2 下载及安装VMware
百度搜索随便安装即可,建议安装到磁盘比较大的地方,其他选择默认就可以了,网上找找破解码即可。
1.3在VMware安装Ubuntu
选择下载的iso文件
然后随便搞搞这个,密码最好简单一点,我是用root
虚拟机名字可以整成Hadoop,位置最好不要放C盘,放其他大一点的盘,
然后一直按下一步就行了
然后等待安装完就行了。
进去之后
继续就可了
选择城市
密码就随便搞搞吧
然后就可以了
1.4安装VMware Tools工具
点击虚拟机进行安装即可。然后重启一下就行了。
2.安装必要配置
2.1换源
我们先要换源
找到这个Software & Update
找到自己想要换的源头
即可
2.2 安装vim
sudo apt-get install vim
sudo apt-get update
2.3 安装net-tools 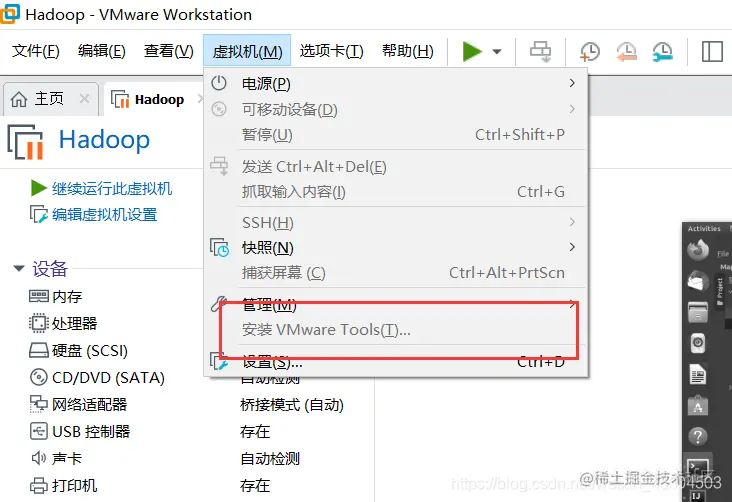
2.4 安装jdk1.8
2.4.1创建
创建一个文件将jdk包放入
2.4.2配置环境
vim ~/.bashrc
像这样配置环境即可
退出并保存.bashrc文件,用source命令使之生效,能在任意目录下查看Java版本号、或执行java命令表示JDPK配置成功
2.5 open-server
sudo apt-get install openssh-server
3 配置静态IP
3.1设置
Vmware 菜单栏“虚拟机”→“设置”→“网络适配器”→“桥接模式”
3.2 配置
虚拟网络编辑器中设置虚拟网络连接到的外部网络 Vmware 菜单栏“编辑”→“虚拟网络编辑器”
3.3修改配置文件
3.3.1 interfaces文件
sudo vim /etc/network/interfaces
3.3.2 DNS服务文件
sudo vim /etc/systemd/resolved.conf
3.4 重启网卡
sudo /etc/init.d/networking restart
出现ok即可
测试ping百度,发现可以就行了。
查看ip是否被修改了。
4 安装IDEA
找到下载中心安装即可。
运行hello world可以,即可
5 配置ssh免密登陆
5.1确认ssh服务安装并启动
使用
dpkg –l | grep ssh
ps –e | grep ssh
确认ssh服务安装并启动
在用户根目录输入指令
ssh-keygen -t rsa
免密登陆所以直接回车就可以了
id_rsa为私钥,id_rsa.pub为公钥
创建一个authorized_keys文件用于存放远程免密登录机器的公钥,再将本机公钥追加到authorized_keys文件中,实现本机免密登录。最后赋予authorized_keys文件有效权限。
最后
ssh localhost
免密登陆成功。
6 搭建Hadoop集群
6.1 克隆
按照指示就可以完成克隆了。建议命名成Hadoop1,Hadoop2
然后按照要求再将其中地址更改,防止一样的造成冲突。
我是主机Hadoop 192.168.43.200
Hadoop-Clone1192.168.43.201
Hadoop-Clone2 192.168.43.202
6.2 使用xftp6
使用xftp6辅助,将每台机器的公钥文件id_rsa.pub分别复制到其他两台机器上。
另外克隆的两台机子的也要进行步骤5的ssh免密登陆的操作。
6.3 将私钥放入其他两台机子当中
6.4 测试 ssh 是否成功
注意ssh 后面跟着是你的主机 我的是031904102 所以ssh 031904102 ,031904102是我主节点的名字。
成功Hadoop集群便搭建成功了!
