


为有监督的文本分类问题创建一个NLP管道
这篇文章是基于Adi Shalev和我为2021年CodeFest创建的一个研讨会。
在数据科学领域,特别是在NLP领域迈出第一步时,我们经常会遇到一系列全新的术语和短语;_"拟合"、"转换"、"推理"、"度量 "_等等。虽然现有的信息来源允许理解这些术语,但并不总是清楚这些不同的工具最终是如何结合在一起,形成一个我们能够用于新数据的基于机器学习的生产系统。
从一个标记的数据集到创建一个可以应用于新样本的分类器(又称有监督的机器学习分类),应该经历的一组有序的阶段被称为NLP管道。
在这篇文章中,我们将为一个有监督的分类问题创建这样一个管道:根据描述对一部电影是否是一部戏剧电影进行分类。完整的代码可以在这里找到。
监督下的机器学习分类的NLP管道--它到底是什么?
我们以一个数据集开始我们的旅程,这是一个已知分类的文本记录表。我们的数据就像我们想用来创造产品的水流。为了做到这一点,我们将创建一个管道:一个多级系统,每一级都从上一级获得输入,并将其输出作为输入转给下一级。
我们的管道将由以下几个阶段组成。
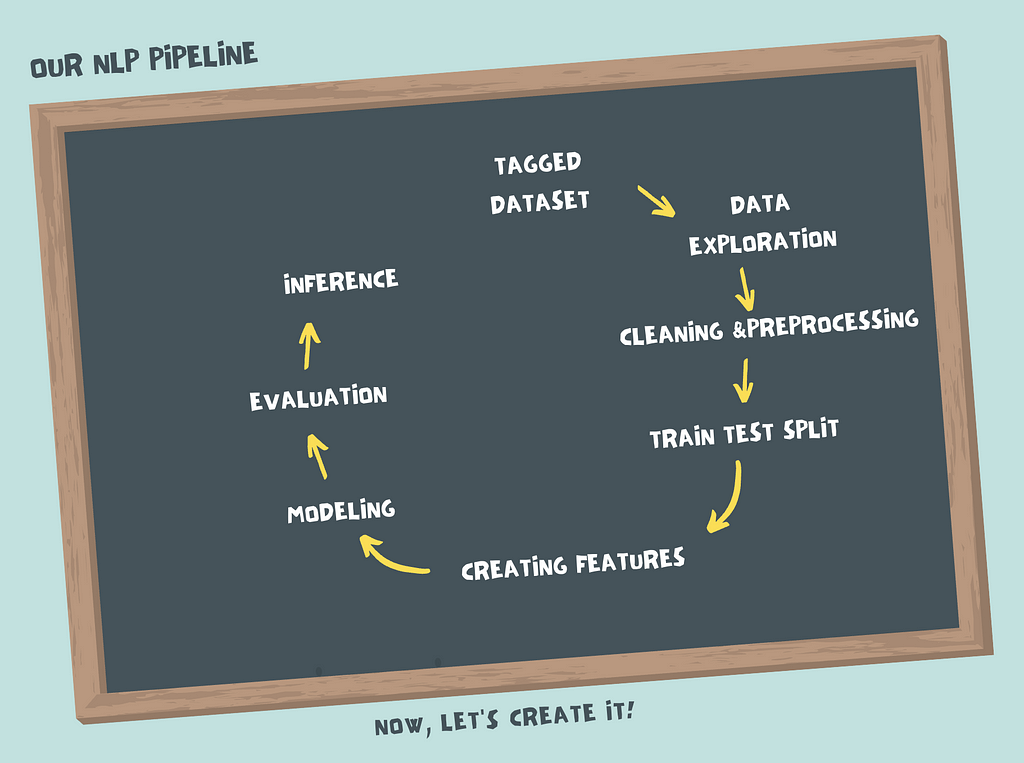
图片来源:作者
虽然我们构建每个阶段的方式在不同的问题中会有所不同,但这些阶段中的每一个都在我们的最终产品--一个闪亮的文本分类器中发挥作用
数据
我们将使用的数据是基于Kaggle的这个电影数据集。我们将使用这些数据来确定一部电影的类型是否为戏剧,是或不是,这是一个二元分类问题。我们的数据是一个有45466条记录的pandas Dataframe,去除NULL条目后是44512条。

1.探索数据
每当我们开始处理一个新的数据集时,在我们继续做出设计决策和创建模型之前,我们必须了解我们的数据。让我们来回答一些关于我们的数据集的问题。
- 概览是什么样子的?
由于我们希望利用概览来确定一部电影是否是一部戏剧电影,让我们看看一些概览。

- 这些概览有多长?最长的概述?最短的概述?
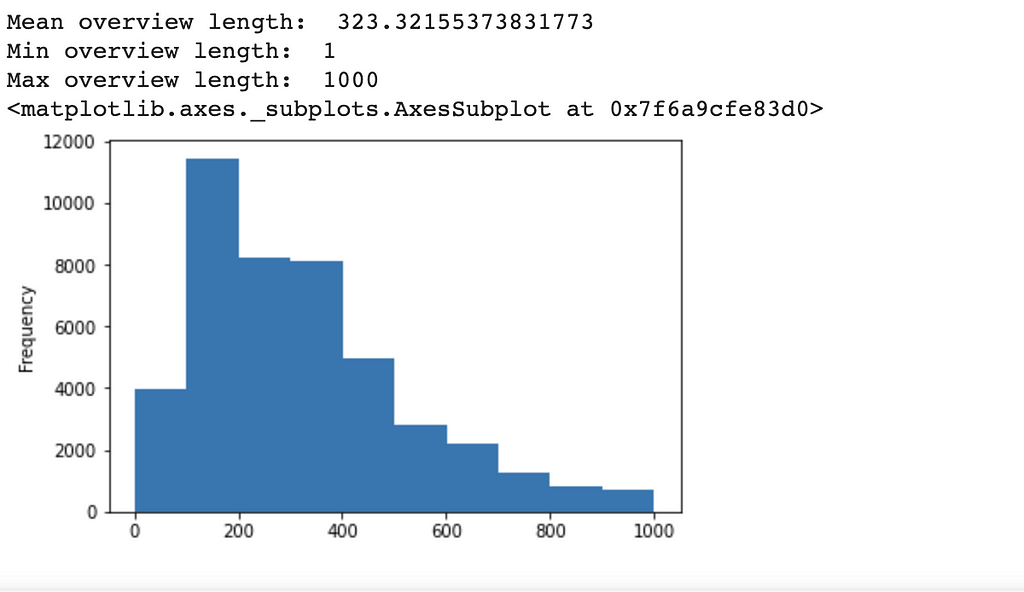
- 我们有多少部戏剧电影?

- 在综述中最常出现的词是什么?在某一特定类型的概述中?

探索数据的阶段对于接下来的阶段很重要,因为它可以让我们获得在接下来的步骤中做决定所需要的信息。
- 其他任何可以帮助我们更好地理解我们的数据集的东西!
2.清洗和预处理数据
现在,我们对手中的数据有了更好的了解,我们可以继续清理数据。这个阶段的目标是在我们使用数据创建模型之前,去除数据中不相关的部分。不相关部分 "的定义在不同的问题和数据集之间是不同的,在现实世界的问题中可以通过实验来找到最佳的方法。
- 删除短于10的条目
在数据探索过程中,我们注意到有些概述的长度很短。由于我们想用描述来对体裁进行分类,我们可以删除长度短于15的记录,因为包含如此少的字符的概述可能不会有什么信息。
- 删除标点符号
由于我们想捕捉描述戏剧电影的词语与描述其他电影的词语之间的差异,我们可以删除标点符号。
- 词组化
Lemmatization是用来将一个词的不同转折形式组合在一起,以便将它们作为一个单一的项目进行分析。让我们看一个例子。
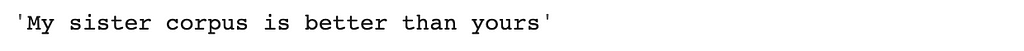
我们现在可以对我们的数据进行词法处理。
经过清洗和预处理,我们的文本已经准备好转换为特征。
3.培训 测试 分割
在创建一个模型之前,我们应该将我们的数据分成训练集和测试集。训练集将被用来 "教导 "模型,而测试集将被我们用来评估我们的模型有多好。在现实世界的场景中,我们通常也会分割出一个验证集,我们可以用它来调整超参数。
下面的代码是分割的。更多的例子可以[在这里](scikit-learn.org/stable/modu… scikit-learn.org/stable/modu…
4.特征工程
在建立管道的这一点上,我们已经熟悉了我们的文本数据,它是 "干净的",并经过了预处理。不过,它仍然是文本。由于我们的最终目标是为我们的数据训练一个分类器,现在是时候把我们的文本转换成机器学习算法可以处理和学习的格式,这种格式也被称为_"向量"_。
将文本数据编码为向量的方法有很多:从基本的、直观的方法到最先进的基于神经网络的方法。让我们来看看其中的一些。
计数向量
将文本描述为一个向量,在这个向量中,我们保存了我们词汇表中每个词的出现次数。我们可以选择向量的长度,这也将是我们词汇的大小。
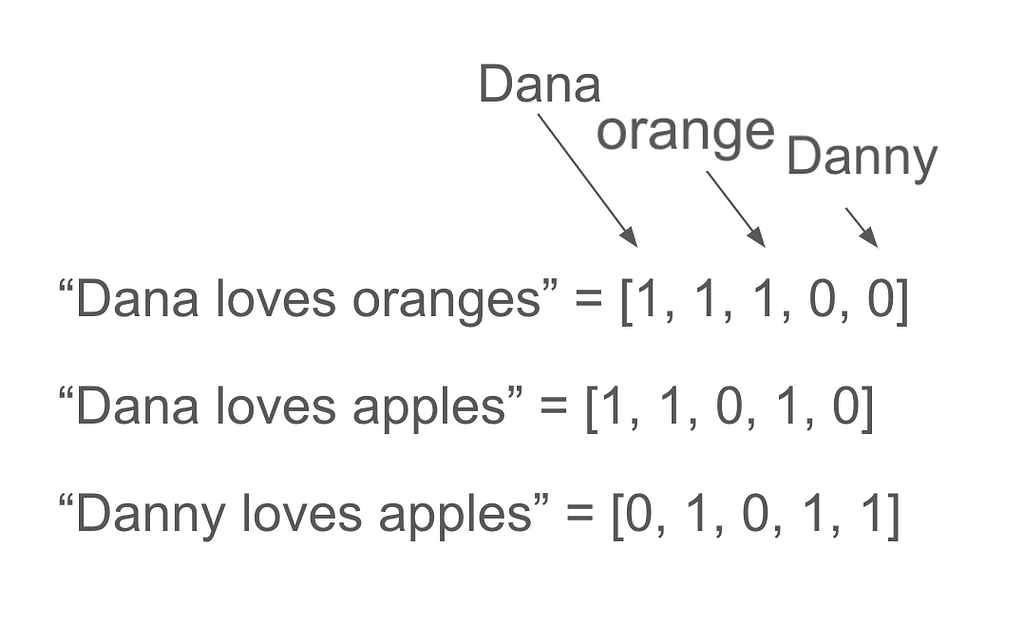
你可以在这里阅读更多关于计数向量和创建它们时使用的不同参数。
TF-IDF向量
使用TF-IDF向量,我们可以解决使用计数向量时遇到的一个问题:在文本数据中多次出现的无意义的词。在创建TFIDF向量时,我们将词汇表中每个词的出现次数与一个标志着该词在我们语料库中其他文件中出现频率的因素相乘。这样一来,在我们的语料库中的许多文档中出现的词将在我们的特征向量中得到较小的值。
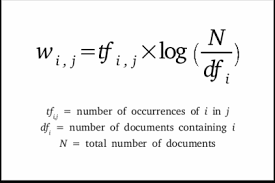
你可以在这里阅读更多关于TF-IDF向量和创建它们时使用的不同参数。
5.建模
在使用向量器之后,我们的电影概览不再以文本形式表示,而是以向量形式表示,这使得我们可以使用我们的数据来训练一个模型。
我们现在可以使用我们的训练集来训练一个模型。这里我们训练 多叉奈何贝叶斯,但 Scikit-Learn中的许多其他算法也可以类似地应用,当解决一个新问题时,我们往往会研究不止一种算法。
6.评估
训练完一个模型后,我们要评估它在新数据上的表现如何。出于这个原因,我们划分了我们的数据并预留了一个测试集。现在我们将使用我们的模型对测试集的预测来评估我们的模型。
我们将根据正确答案和模型所犯的错误创建一个混淆矩阵。

二元分类的混淆矩阵

现在我们可以使用混淆矩阵创建的值来计算其他一些指标。

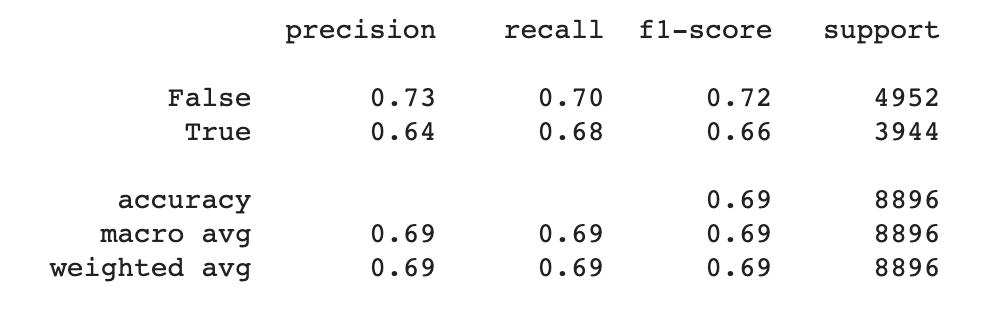
通常情况下,我们建立模型的第一次尝试不会有惊人的指标。这是一个很好的时机,可以回到早期阶段,尝试用不同的方式做一些。
7.推断--对新样本使用我们的模型
在使用我们的数据创建一个模型来解决我们的问题,即根据电影的概况来分类是否是一部戏剧电影,并评估我们的模型,我们可以使用它来确定新的样本--戏剧或没有戏剧?

由于我们的原始概览在用来训练/评估我们的模型之前已经有了一个历程,我们需要以同样的方式处理我们的新样本。
我们现在可以用我们的模型来预测我们新样本的类型。

我们的预测是正确的!
总结
在这篇文章中,我们为一个有监督的文本分类问题创建了一个管道。我们的管道是由几个部分组成的,这些部分是相互联系的(就像一个真正的管道!)。我们希望这篇文章能帮助你了解这个过程的每一部分在创建最终产品--文本分类器中的作用。
