

此文章仅用于记录面试中遇到的问题,计算类的会贴出我自己的解题方案,也许不是最优的,但是我尽力写好;理论类的我会搜集网上比较好的解答。并且此文章会长期更新和维护。
1、已知一个大数据量的简易数组,其中有很多元素是重复的,也有元素是唯一的,需要找出唯一的元素,并返回(2021.07.26)
答:
const findUnique = function(source){
console.time()
let map = {};
let unique = [];
source.forEach(ele=>{
if(!map[ele]){
map[ele] = true;
unique.push(ele);
}else{
let uniqueIndex = unique.findIndex(item=>{
return item ===ele
})
if(uniqueIndex!=-1){
unique.splice(uniqueIndex,1);
}
}
})
console.timeEnd();
return unique
}
2、常用的设计模式有哪些并列举使用场景(2021.09.08)
答:
(1)工厂模式-传入参数即可创建实例 虚拟DOM根据参数不同返回基础标签的Vnode和组件Vnode
(2)单例模式-整个程序有且仅有一个实例 vuex和vue-router的插件注册方式install判断,如果系统存在实例就直接返回
(3)发布订阅模式(vue事件机制)
(4)观察者模式(响应数据原理)
(5)装饰模式(@装饰器的用法)
(6)策略模式 策略模式是指对象有某个行为,但是在不同的场景中,该行为有不同的实现方案---比如说选项的合并策略(同组件和混入)
3、tree shaking是什么,原理是什么? (2021.09.08)
答:
tree shaking是一种通过清除多余代码的方式来优化项目打包体积的技术;
原理:ES6 Moudule引入进行静态分析,故而编译的时候正确判断到底加载了哪些模块;静态分析程序流,判断那些模块和变量未被使用或者引用,进而删除对应代码
4、common.js 和 es6 中模块引入的区别? (2021.09.08)
答:
CommonJS 是一种模块规范,最初被应用于 Nodejs,成为 Nodejs 的模块规范。运行在浏览器端的 JavaScript 由于也缺少类似的规范,在 ES6 出来之前,前端也实现了一套相同的模块规范 (例如: AMD),用来对前端模块进行管理。自 ES6 起,引入了一套新的 ES6 Module 规范,在语言标准的层面上实现了模块功能,而且实现得相当简单,有望成为浏览器和服务器通用的模块解决方案。但目前浏览器对 ES6 Module 兼容还不太好,我们平时在 Webpack 中使用的 export 和 import,会经过 Babel 转换为 CommonJS 规范。在使用上的差别主要有:
(1)CommonJS 模块输出的是一个值的拷贝,ES6 模块输出的是值的引用。
(2)CommonJS 模块是运行时加载,ES6 模块是编译时输出接口。
(3)CommonJs 是单个值导出,ES6 Module可以导出多个
(4)CommonJs 是动态语法可以写在判断里,ES6 Module 静态语法只能写在顶层
(5)CommonJs 的 this 是当前模块,ES6 Module的 this 是 undefined
5、cookie 和 token 都存放在 header 中,为什么不会劫持 token?(2021.09.08)
答:
(1)cookie:登录后服务端生成的sessionid,并在http请求里返回到客户端,同时服务端保存sessionid,以后客户端的每次http请求都带上cookie(sessionid),服务端会获取cookie(sessionid)然后验证用户的身份。所以拿到cookie就拿到了sessionid,就可验证通过。同时浏览器会自动携带cookie;
(2)token:同样是登录后服务端返回一个token,客户端保存起来,在以后http请求里手动的加入到请求头里,服务端根据token 进行身份的校验。浏览器不会自动携带token。
(4) CSRF 跨站点请求伪造:通过浏览器会自动携带同域cookie的特点。cookie的传递流程是用户在访问站点时,服务器端生成cookie,发送给浏览器端储存,当下次再访问时浏览器会将该网站的cookie发回给服务器端 如果用户登陆了A网站,拿到了cookie,又点击了恶意的网站B。 B收到请求以后,返回一段攻击代码,并且发出一个请求给网站A。 浏览器会在用户不知情的情况下,根据B的请求,带着cookie访问A。 由于HTTP是无状态的,A网站不知道这个请求其实是恶意网站B发出的,就会根据cookie来处理请求,从而执行了攻击代码。 而浏览器不会自动携带 token,所以不会劫持 token。
(5)XSS:跨站脚本工攻击是指通过存在安全漏洞的Web网站注册用户的浏览器内运行非法的HTML标签或者JavaScript进行的一种攻击。就是说,cookie和token都可能被拿到,所以都废了。
6、babel 是什么,原理了解吗? (2021.09.08)
答:
Babel 是一个 JavaScript 编译器。他把最新版的 javascript 编译成当下可以执行的版本,简言之,利用 babel 就可以让我们在当前的项目中随意的使用这些新最新的 es6,甚至 es7 的语法。
Babel 的三个主要处理步骤分别是: 解析(parse),转换(transform),生成(generate)。 解析 将代码解析成抽象语法树(AST),每个 js 引擎(比如 Chrome 浏览器中的 V8 引擎)都有自己的 AST 解析器,而 Babel 是通过 Babylon 实现的。
(1)在解析过程中有两个阶段:词法分析和语法分析,词法分析阶段把字符串形式的代码转换为令牌(tokens)流,令牌类似于 AST 中节点;而语法分析阶段则会把一个令牌流转换成 AST 的形式,同时这个阶段会把令牌中的信息转换成 AST 的表述结构。
(2)转换 在这个阶段,Babel 接受得到 AST 并通过 babel-traverse 对其进行深度优先遍历,在此过程中对节点进行添加、更新及移除操作。这部分也是 Babel 插件介入工作的部分。
(3)生成 将经过转换的 AST 通过 babel-generator 再转换成 js 代码,过程就是深度优先遍历整个 AST,然后构建可以表示转换后代码的字符串。
7、flex:1 到底代表什么? (2021.09.08)
答:
flex: 1 1 0;
flex-grow:定义项目的的放大比例; 默认为0,即 即使存在剩余空间,也不会放大; 所有项目的flex-grow为1:等分剩余空间(自动放大占位); flex-grow为n的项目,占据的空间(放大的比例)是flex-grow为1的n倍。
flex-shrink:定义项目的缩小比例; 默认为1,即 如果空间不足,该项目将缩小; 所有项目的flex-shrink为1:当空间不足时,缩小的比例相同; flex-shrink为0:空间不足时,该项目不会缩小; flex-shrink为n的项目,空间不足时缩小的比例是flex-shrink为1的n倍。
flex-basis: 定义在分配多余空间之前,项目占据的主轴空间(main size),浏览器根据此属性计算主轴是否有多余空间, 默认值为auto,即 项目原本大小; 设置后项目将占据固定空间。
8、HTTP缓存之协商缓存和强制缓存 (2021.09.08)
答:
(1)强制缓存: 强制缓存就是直接从浏览器缓存查找该结果,并根据结果的缓存规则来决定是否使用该缓存的过程。 不存在该缓存结果和标识,强制缓存失效,则直接向服务器发起请求(跟第一次发起请求一致) 存在缓存结果和标识,但结果已失效,强制缓存失效,则使用协商缓存 存在缓存结果和标识,并且结果未失效,强制缓存生效,直接返回该结果 控制强制缓存的字段分别是Expires和Cache-Control,其中Cache-Control优先级比Expires高。
(2)协商缓存 协商缓存就是强制缓存失效后,浏览器携带缓存标识向服务器发起请求,有服务器根据缓存标识决定是否使用缓存的过程,主要有以下两种情况: 协商缓存生效,返回304,服务器告诉浏览器资源未更新,则再去浏览器缓存中访问资 源 协商缓存失效,返回200和请求结果 同样,协商缓存的标识也是在响应报文的HTTP头和请求结果一起返回给浏览器的,控制协商缓存的字段分别有: Last-Modified/If-Modified-Since Etag/If-None-Match 其中Etag/If-None-Match优先级比Last-Modified/If-Modified-Since高
目前的项目大多使用这种缓存方案的: HTML: 协商缓存; css、js、图片:强缓存,文件名带上hash。
9、Doctype作用?严格模式和混杂模式如何区分?他们有何意义?(2021.09.08)
答:
(1)声明位于文档中的最前面,处于html标签之前,告知浏览器的解析器,用什么文档类型规范来解析这个文档。
(2)严格模式的排版和js运作模式是以改浏览器支持的最高标准运行的
(3)在混杂模式中,页面以宽松的向后兼容的方式显示。模拟老式浏览器的行为以防止站点无法工作。
(4)Doctype不存在或者格式不正确会导致文档以混杂模式呈现
10、浏览器事件循环执行顺序;浏览器和node的循环的区别(2021.09.13)
答:
浏览器事件循环执行顺序:
(1)执行全局script同步代码,这些同步代码有一些是同步语句,有一些是异步语句
(2)全局script代码执行完毕之后,调用栈stack会清空。
(3)从微队列microtask queue中取出位于队首的回调任务,放入调用栈stack中执行,执行完后microtask queue长度减1。
(4)继续取出位于队首的任务,放入调用栈stack中执行,以此类推,直到将microtask queue中所有任务执行完毕。如果在执行microtask 的过程中又产生microtask,那么会加入到队列的末尾,也会在这个周期被调用执行。
(5)microtask queue中所有任务执行完毕,此时microtask queue为空队列,调用栈stack也为空。
(6)取出宏队列macrotask queue中位于队首的任务,放入stack中执行。
(7)执行完毕后,调用栈stack为空
(8)重复3-7的步骤
……
浏览器和node的循环的区别:
node11以下版本:先执行所有宏任务,在执行微任务,node11与浏览器一致
11、vue的父组件和子组件生命周期执行顺序(2021.09.13)
答:
(1)父组件:beforeCreate->created->beforeMount
(2)子组件:->beforeCreate->created->beforeMount->mounted
(3)父组件:->mounted
12、HTTP1.0 HTTP1.1 HTTP2.0 主要特性对比(2021.09.13)
答:
HTTP1.0
早先1.0的HTTP版本,是一种无状态、无连接的应用层协议。
HTTP1.0规定浏览器和服务器保持短暂的连接,浏览器的每次请求都需要与服务器建立一个TCP连接,服务器处理完成后立即断开TCP连接(无连接),服务器不跟踪每个客户端也不记录过去的请求(无状态)。
这种无状态性可以借助cookie/session机制来做身份认证和状态记录。而下面两个问题就比较麻烦了。
首先,无连接的特性导致最大的性能缺陷就是无法复用连接。每次发送请求的时候,都需要进行一次TCP的连接,而TCP的连接释放过程又是比较费事的。这种无连接的特性会使得网络的利用率非常低。
其次就是队头阻塞(head of line blocking)。由于HTTP1.0规定下一个请求必须在前一个请求响应到达之前才能发送。假设前一个请求响应一直不到达,那么下一个请求就不发送,同样的后面的请求也给阻塞了。
为了解决这些问题,HTTP1.1出现了。
HTTP1.1
对于HTTP1.1,不仅继承了HTTP1.0简单的特点,还克服了诸多HTTP1.0性能上的问题。
首先是长连接,HTTP1.1增加了一个Connection字段,通过设置Keep-Alive可以保持HTTP连接不断开,避免了每次客户端与服务器请求都要重复建立释放建立TCP连接,提高了网络的利用率。如果客户端想关闭HTTP连接,可以在请求头中携带Connection: false来告知服务器关闭请求。
其次,是HTTP1.1支持请求管道化(pipelining)。基于HTTP1.1的长连接,使得请求管线化成为可能。管线化使得请求能够“并行”传输。举个例子来说,假如响应的主体是一个html页面,页面中包含了很多img,这个时候keep-alive就起了很大的作用,能够进行“并行”发送多个请求。(注意这里的“并行”并不是真正意义上的并行传输,具体解释如下。)
需要注意的是,服务器必须按照客户端请求的先后顺序依次回送相应的结果,以保证客户端能够区分出每次请求的响应内容。
也就是说,HTTP管道化可以让我们把先进先出队列从客户端(请求队列)迁移到服务端(响应队列)。
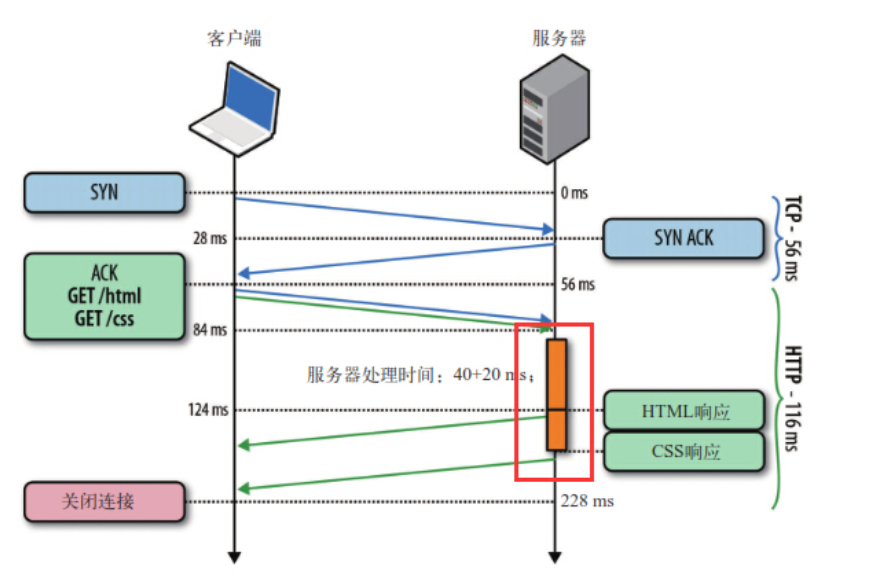
如图所示,客户端同时发了两个请求分别来获取html和css,假如说服务器的css资源先准备就绪,服务器也会先发送html再发送css。
换句话来说,只有等到html响应的资源完全传输完毕后,css响应的资源才能开始传输。也就是说,不允许同时存在两个并行的响应。
可见,HTTP1.1还是无法解决队头阻塞(head of line blocking)的问题。同时“管道化”技术存在各种各样的问题,所以很多浏览器要么根本不支持它,要么就直接默认关闭,并且开启的条件很苛刻...而且实际上好像并没有什么用处。
那我们在谷歌控制台看到的并行请求又是怎么一回事呢?
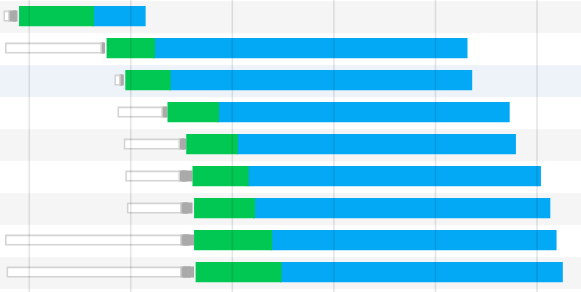
如图所示,绿色部分代表请求发起到服务器响应的一个等待时间,而蓝色部分表示资源的下载时间。按照理论来说,HTTP响应理应当是前一个响应的资源下载完了,下一个响应的资源才能开始下载。而这里却出现了响应资源下载并行的情况。这又是为什么呢?
其实,虽然HTTP1.1支持管道化,但是服务器也必须进行逐个响应的送回,这个是很大的一个缺陷。实际上,现阶段的浏览器厂商采取了另外一种做法,它允许我们打开多个TCP的会话。也就是说,上图我们看到的并行,其实是不同的TCP连接上的HTTP请求和响应。这也就是我们所熟悉的浏览器对同域下并行加载6~8个资源的限制。而这,才是真正的并行!
此外,HTTP1.1还加入了缓存处理(强缓存和协商缓存[传送门])新的字段如cache-control,支持断点传输,以及增加了Host字段(使得一个服务器能够用来创建多个Web站点)。
HTTP2.0
HTTP2.0的新特性大致如下:
二进制分帧
HTTP2.0通过在应用层和传输层之间增加一个二进制分帧层,突破了HTTP1.1的性能限制、改进传输性能。
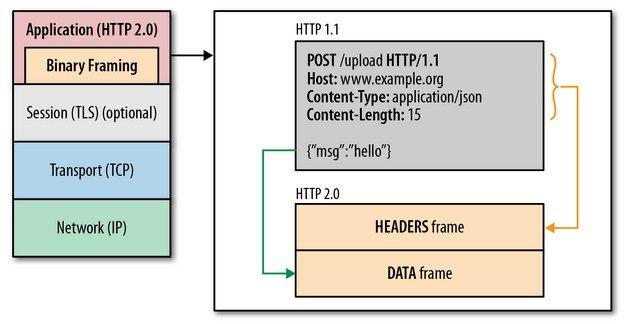
可见,虽然HTTP2.0的协议和HTTP1.x协议之间的规范完全不同了,但是实际上HTTP2.0并没有改变HTTP1.x的语义。
简单来说,HTTP2.0只是把原来HTTP1.x的header和body部分用frame重新封装了一层而已。
多路复用(连接共享)
下面是几个概念:
- 流(
stream):已建立连接上的双向字节流。 - 消息:与逻辑消息对应的完整的一系列数据帧。
- 帧(
frame):HTTP2.0通信的最小单位,每个帧包含帧头部,至少也会标识出当前帧所属的流(stream id)。
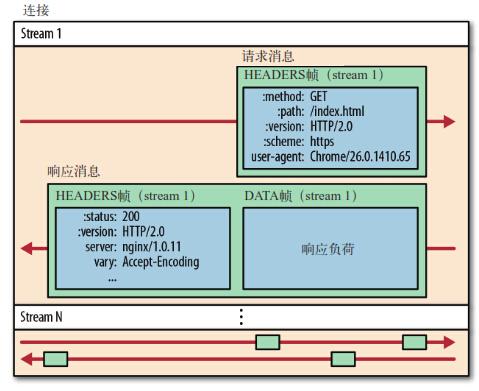
从图中可见,所有的HTTP2.0通信都在一个TCP连接上完成,这个连接可以承载任意数量的双向数据流。
每个数据流以消息的形式发送,而消息由一或多个帧组成。这些帧可以乱序发送,然后再根据每个帧头部的流标识符(stream id)重新组装。
举个例子,每个请求是一个数据流,数据流以消息的方式发送,而消息又分为多个帧,帧头部记录着stream id用来标识所属的数据流,不同属的帧可以在连接中随机混杂在一起。接收方可以根据stream id将帧再归属到各自不同的请求当中去。
另外,多路复用(连接共享)可能会导致关键请求被阻塞。HTTP2.0里每个数据流都可以设置优先级和依赖,优先级高的数据流会被服务器优先处理和返回给客户端,数据流还可以依赖其他的子数据流。
可见,HTTP2.0实现了真正的并行传输,它能够在一个TCP上进行任意数量HTTP请求。而这个强大的功能则是基于“二进制分帧”的特性。
头部压缩
在HTTP1.x中,头部元数据都是以纯文本的形式发送的,通常会给每个请求增加500~800字节的负荷。
比如说cookie,默认情况下,浏览器会在每次请求的时候,把cookie附在header上面发送给服务器。(由于cookie比较大且每次都重复发送,一般不存储信息,只是用来做状态记录和身份认证)
HTTP2.0使用encoder来减少需要传输的header大小,通讯双方各自cache一份header fields表,既避免了重复header的传输,又减小了需要传输的大小。高效的压缩算法可以很大的压缩header,减少发送包的数量从而降低延迟。
服务器推送
服务器除了对最初请求的响应外,服务器还可以额外的向客户端推送资源,而无需客户端明确的请求。
HTTP1.1的合并请求是否适用于HTTP2.0
首先,答案是“没有必要”。之所以没有必要,是因为这跟HTTP2.0的头部压缩有很大的关系。
在头部压缩技术中,客户端和服务器均会维护两份相同的静态字典和动态字典。
在静态字典中,包含了常见的头部名称以及头部名称与值的组合。静态字典在首次请求时就可以使用。那么现在头部的字段就可以被简写成静态字典中相应字段对应的index。
而动态字典跟连接的上下文相关,每个HTTP/2连接维护的动态字典是不尽相同的。动态字典可以在连接中不听的进行更新。
也就是说,原本完整的HTTP报文头部的键值对或字段,由于字典的存在,现在可以转换成索引index,在相应的端再进行查找还原,也就起到了压缩的作用。
所以,同一个连接上产生的请求和响应越多,动态字典累积得越全,头部压缩的效果也就越好,所以针对HTTP/2网站,最佳实践是不要合并资源。
另外,HTTP2.0多路复用使得请求可以并行传输,而HTTP1.1合并请求的一个原因也是为了防止过多的HTTP请求带来的阻塞问题。而现在HTTP2.0已经能够并行传输了,所以合并请求也就没有必要了。
总结
HTTP1.0
- 无状态、无连接
HTTP1.1
- 持久连接
- 请求管道化
- 增加缓存处理(新的字段如
cache-control) - 增加
Host字段、支持断点传输等
HTTP2.0
- 二进制分帧
- 多路复用(或连接共享)
- 头部压缩
- 服务器推送
13、vue中scoped的实现原理(2021.09.13)
答:
Vue中的scoped属性的效果主要是通过PostCss实现的。
<style scoped>
.example{
color:red;
}
</style>
<template>
<div>scoped测试案例</div>
</template>
转译后:
.example[data-v-6cc577df] {
color: red;
}
<template>
<div class="example" data-v-6cc577df>scoped测试案例</div>
</template>
PostCSS给一个组件中的所有dom添加了一个独一无二的动态属性,给css选择器额外添加一个对应的属性选择器,来选择组件中的dom,这种做法使得样式只作用于含有该属性的dom元素(组件内部的dom)。
总结:
(1)给HTML的dom节点添加一个不重复的data属性(例如: data-v-6cc577df)来唯一标识这个dom 元素
(2)在每句css选择器的末尾(编译后生成的css语句)加一个当前组件的data属性选择器(例如:[data-v-6cc577df])来私有化样式
14、常用跨浏览器窗口通讯有哪些(2021.09.15)
(1)postMessage
(2)StorageEvent,监听localstorage变化,window.addEventListener("storage", function(e) { console.log(e.key, e.newValue, e.oldValue) });
(3)Broadcast Channel
创建BroadcastChannel并监听事件,Channel名称要一致。
发送方:
var channel = new BroadcastChannel("channel-BroadcastChannel");
channel.postMessage('Hello, BroadcastChannel!')
接收方:
var channel = new BroadcastChannel("channel-BroadcastChannel");
channel.addEventListener("message", function(ev) {
console.log(ev.data)
});
Channel Messaging API的**MessageChannel** 接口允许我们创建一个新的消息通道,并通过它的两个MessagePort 属性发送数据。
属性
返回channel的port1。
返回channel的port2。
示例:
var channel = new MessageChannel();
var para = document.querySelector('p');
var ifr = document.querySelector('iframe');
var otherWindow = ifr.contentWindow;
ifr.addEventListener("load", iframeLoaded, false);
function iframeLoaded() {
otherWindow.postMessage('Hello from the main page!', '*', [channel.port2]);
}
channel.port1.onmessage = handleMessage;
function handleMessage(e) {
para.innerHTML = e.data;
}
15、vue路由钩子执行顺序(2021.09.28)
答:
16、route-link和a标签的区别(2021.09.30)
答:
<router-link> 组件支持用户在具有路由功能的应用中 (点击) 导航。 通过 to 属性指定目标地址,默认渲染成带有正确链接的 <a> 标签,可以通过配置 tag 属性生成别的标签.。另外,当目标路由成功激活时,链接元素自动设置一个表示激活的 CSS 类名。
<router-link> 比起写死的 <a href="..."> 会好一些,理由如下:
- 无论是 HTML5 history 模式还是 hash 模式,它的表现行为一致,所以,当你要切换路由模式,或者在 IE9 降级使用 hash 模式,无须作任何变动。
- 在 HTML5 history 模式下,
router-link会守卫点击事件,让浏览器不再重新加载页面。 - 当你在 HTML5 history 模式下使用
base选项之后,所有的to属性都不需要写 (基路径) 了。
17、解析地址栏中的参数,返回对象,举例:www.examples.com/s?ie=utf-8&…
答:
function parsePathParams(path) {
if (!path){
return
};
let paramsStr = path.split('?');
if (paramsStr[1]){
paramsStr = paramsStr[1];
}else{
return false;
};
let paramsArr = paramsStr.split('&');
return paramsArr.reduce((paramsObj,paramsKeyAndValue)=>{
const [ key, value] = paramsKeyAndValue.split('=');
if(!value) {
return paramsObj;
};
let deepSetParam = deepSet(paramsObj,key.split(/[\[\]]/g).filter(x => x),value);
return paramsObj;
},{});
};
function deepSet(paramsObj,key,value) {
let i = 0;
for(; i < key.length - 1;i++){
if(paramsObj[key[i]] == undefined){
if(key[i+1].match(/^\d+$/)){
paramsObj[key[i]] = [];
}else{
paramsObj[key[i]] = {};
}
};
paramsObj = paramsObj[key[i]];
}
paramsObj[key[i]] = decodeURIComponent(value);
return paramsObj;
};
console.log(parsePathParams("https://www.examples.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu"));
console.log(parsePathParams("https://www.baidu.com/s?ie=utf-8&f[0]=8&f[1]=9&rsv_bp=1&rsv_idx=1&tn=baidu&aa[a]=1&flow_name=jack%20li"));
打印结果:
{ie: "utf-8", f: "8", rsv_bp: "1", rsv_idx: "1", tn: "baidu"}
f: "8"
ie: "utf-8"
rsv_bp: "1"
rsv_idx: "1"
tn: "baidu"
__proto__: Object
{ie: "utf-8", f: Array(2), rsv_bp: "1", rsv_idx: "1", tn: "baidu", …}
aa: {a: "1"}
f: (2) ["8", "9"]
flow_name: "jack li"
ie: "utf-8"
rsv_bp: "1"
rsv_idx: "1"
tn: "baidu"
__proto__: Object
