


一、nodejs之events模块
1、事件驱动模型
Nodejs 使用了一个事件驱动、非阻塞 IO 的模型(有兴趣的同学可以回去看一下系列一),events模块是事件驱动的核心模块。很多内置模块都继承了events.EventEmitter。自己无需手动实现这种设计模式,直接继承EventEmitter即可。代码如下:
const { EventEmitter } = require("events");
class MyEmitter extends EventEmitter {}
const ins = new MyEmitter();
ins.on("test", () => {
console.log("emit test event");
});
ins.emit("test");
2、API全解
(1)API解释
在events模块中,需要一个哈希表来存储监听事件和对应回调函数的,形式大概如下:
{
事件A: [回调函数1,回调函数2,回调函数3],
事件B: 回调函数1
}
所有的API都是围绕这个哈希表来进行增删查改
- emitter.addListener(eventName, listener):对应事件增加一个回调函数
- emitter.on(eventName, listener):同1,别名
- emitter.once(eventName, listener):同1,在事件被多次触发下只执行一次
- emitter.prependListener(eventName, listener):同1,添加在监听器数组开头
- emitter.prependOnceListener(eventName, listener):同1,添加在监听器数组开头 && 单次监听器
- emitter.removeListener(eventName, listener):移除指定的事件中的某个监听器
- emitter.removeAllListeners([eventName]):移除全部监听器或者指定的事件的监听器
- emitter.emit(eventName[, ...args]):按照监听器注册的顺序,同步地调用对应事件的监听器,并提供传入的参数
- emitter.eventNames():获得哈希表中所有的键值(包括Symbol)
- emitter.listenerCount(eventName):获得哈希表中对应键值的监听器数量
- emitter.listeners(eventName):获得对应键的监听器数组的副本
- emitter.rawListeners(eventName):同上,只不过不会对once处理过后的监听器还原
- emitter.setMaxListeners(n):设置当前实例监听器最大限制数的值
- emitter.getMaxListeners():返回当前实例监听器最大限制数的值
- EventEmitter.defaultMaxListeners:它是每个实例的监听器最大限制数的默认值,修改它会影响所有实例
(2)events的错误处理
下面先看一个例子:
const ins = new MyEmitter();
ins.on("error", error => {
console.log("error msg is", error.message);
});
注册error事件后,我原本的理解是,所有事件回掉逻辑中的错误都会在 EventEmitter 内部被捕获,并且在内部触发 error 事件。也就是说下面代码,会打印:"error msg is a is not defined"。
ins.on("test", () => {
console.log(a);
});
ins.emit("test");
然而,错误并没有捕获,直接抛出了异常。由此可见,EventEmitter 在执行内部逻辑的时候,并没有try-catch。
如果按照正常想法,不想每一次都在外面套一层try-catch,那应该怎么做呢?我的做法是在 EventEmitter 原型链上新增一个safeEmit函数。
EventEmitter.prototype.safeEmit = function(name, ...args) {
try {
return this.emit(name, ...args);
} catch (error) {
return this.emit("error", error);
}
};
(3)监听器队列顺序处理
对于同一个事件,触发它的时候,函数的执行顺序就是函数绑定时候的顺序。官方库提供了emitter.prependListener()和 emitter.prependOnceListener() 两个接口,可以让新的监听器直接添加到队列头部。
但是如果想让新的监听器放入任何监听器队列的任何位置呢?在原型链上封装了 insertListener 方法。
const { EventEmitter } = require("events");
EventEmitter.prototype.insertListener = function(
name,
index,
callback,
once = false
) {
// 如果是once监听器,其数据结构是 {listener: Function}
// 正常监听器,直接是 Function
const listeners = ins.rawListeners(name);
const that = this;
// 下标不合法
if (index > listeners.length || index < 0) {
return false;
}
// 绑定监听器数量已达上限
if (listeners.length >= this.getMaxListeners()) {
return false;
}
listeners.splice(index, 0, once ? { listener: callback } : callback);
this.removeAllListeners(name);
listeners.forEach(function(item) {
if (typeof item === "function") {
that.on(name, item);
} else {
const { listener } = item;
that.once(name, listener);
}
});
return true;
};
const ins = new EventEmitter();
ins.on("test", () => {
console.log("test 1");
});
ins.on("test", () => {
console.log("test 2");
});
// 监听器队列中插入新的监听器,一个是once类型,一个不是once类型
ins.insertListener(
"test",
0,
() => {
console.log("once test insert");
},
true
);
ins.insertListener("test", 1, () => {
console.log("test insert");
});
ins.emit('test');
ins.emit('test');
最终输出结果为:
once test insert
test insert
test 1
test 2
test insert
test 1
test 2
下面还有一个有趣的问题:在一个事件监听器中监听同一个事件会死循环吗?
const { EventEmitter } = require("events");
const test = new EventEmitter();
test.on('repeat', function repeatFn() {
console.log('123')
test.on('repeat', repeatFn);
})
test.emit('repeat');
test.emit('repeat');
test.emit('repeat');
输出结果为:
123
123
123
123
123
123
123
从结果来看,在一个事件监听器中监听同一个事件不会死循环,但是随着emit的次数增加,该事件下对应的listener越来越多,触发同一个函数的次数也越来越多,所以应该尽量避免不必要的重复回调。
(4)调整最大listeners
默认情况下针对单一事件的最大listener数量是10,如果超过10个的话listener还是会执行,只是控制台会有警告信息,告警信息里面已经提示了操作建议,可以通过调用emitter.setMaxListeners()来调整最大listener的限制
const { EventEmitter } = require("events");
const test = new EventEmitter();
console.log(test.getMaxListeners()); // 获取当前事件的最大listeners数量,默认值为10
test.on('repeat', function repeatFn() {
console.log('123')
test.on('repeat', repeatFn);
})
test.setMaxListeners(5);
console.log('afterChange', test.getMaxListeners()
)
test.emit('repeat');
test.emit('repeat');
test.emit('repeat');
上面的打印结果为:
beforeChange: 10
afterChange: 5
123
123
123
123
123
123
123
(node:48024) MaxListenersExceededWarning: Possible EventEmitter memory leak detected. 6 repeat listeners added to [EventEmitter]. Use emitter.setMaxListeners() to increase limit
上面的警告信息的粒度不够,并不能告诉我们是哪里的代码出了问题,可以通过process.on('warning')来获得更具体的信息(emitter、event、eventCount)
MaxListenersExceededWarning: Possible EventEmitter memory leak detected. 6 repeat listeners added to [EventEmitter]. Use emitter.setMaxListeners() to increase limit
at _addListener (events.js:385:17)
at EventEmitter.addListener (events.js:401:10)
at EventEmitter.repeatFn (C:\Users\XJY\Desktop\test\nodejs\events\events.js:30:10)
at EventEmitter.emit (events.js:322:22)
at Object.<anonymous> (C:\Users\XJY\Desktop\test\nodejs\events\events.js:36:6)
at Module._compile (internal/modules/cjs/loader.js:1156:30)
at Object.Module._extensions..js (internal/modules/cjs/loader.js:1176:10)
at Module.load (internal/modules/cjs/loader.js:1000:32)
at Function.Module._load (internal/modules/cjs/loader.js:899:14)
at Function.executeUserEntryPoint [as runMain] (internal/modules/run_main.js:74:12) {
name: 'MaxListenersExceededWarning',
emitter: EventEmitter {
_events: [Object: null prototype] { repeat: [Array] },
_eventsCount: 1,
_maxListeners: 5,
[Symbol(kCapture)]: false
},
type: 'repeat',
count: 6
}
二、nodejs之process模块
在开始这个模块的介绍时,我们需要了解一下并发和并行、进程和线程的知识
1、并发和并行
(1)并发
并发(concurrency):指在同一时刻只能有一条指令执行,但多个进程指令被快速的轮换执行,使得在宏观上具有多个进程同时执行的效果,但在微观上并不是同时执行的,只是把时间分成若干段,使多个进程快速交替的执行。如下图所示:
(2)并行
并行(parallel):指在同一时刻,有多条指令在多个处理器上同时执行。所以无论从微观还是从宏观来看,二者都是一起执行的。如下图所示:
(3)并发和并发在不同处理器系统
并行在多处理器系统中存在,而并发可以在单处理器和多处理器系统中都存在。
并发能够在单处理器系统中存在是因为并发是并行的假象,并行要求程序能够同时执行多个操作,而并发只是要求程序假装同时执行多个操作(每个小时间片执行一个操作,多个操作快速切换执行)。
当有多个线程在操作时,如果系统只有一个 CPU,则它根本不可能真正同时进行一个以上的线程,它只能把 CPU 运行时间划分成若干个时间段,再将时间段分配给各个线程执行,在一个时间段的线程代码运行时,其它线程处于挂起状态.这种方式我们称之为并发(Concurrent)。
当系统有一个以上 CPU 时,则线程的操作有可能非并发。当一个 CPU 执行一个线程时,另一个 CPU 可以执行另一个线程,两个线程互不抢占 CPU 资源,可以同时进行,这种方式我们称之为并行(Parallel)。
2、进程和线程
早期在单核 CPU 的系统中,为了实现多任务的运行,引入了进程的概念,不同的程序运行在数据与指令相互隔离的进程中,通过时间片轮转调度执行,由于 CPU 时间片切换与执行很快,所以看上去像是在同一时间运行了多个程序。
由于进程切换时需要保存相关硬件现场、进程控制块等信息,所以系统开销较大。为了进一步提高系统吞吐率,在同一进程执行时更充分的利用 CPU 资源,引入了线程的概念。线程是操作系统调度执行的最小单位,它们依附于进程中,共享同一进程中的资源,基本不拥有或者只拥有少量系统资源,切换开销极小。
(1)进程
进程(Process)是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础,进程是线程的容器。
我们启动一个服务、运行一个实例,就是开一个服务进程,例如 Java 里的 JVM 本身就是一个进程,Node.js 里通过 node app.js 开启一个服务进程,多进程就是进程的复制(fork),fork 出来的每个进程都拥有自己的独立空间地址、数据栈,一个进程无法访问另外一个进程里定义的变量、数据结构,只有建立了 IPC 通信,进程之间才可数据共享。
下面以一个简单的例子来说明一下:
// index.js
const http = require('http');
http.createServer().listen(3000, () => {
process.title = '自定义进程名称' // 进程进行命名
console.log(`process.pid: `, process.pid);
});
在node index.js后,可以在任务管理器(windows)看到该进程的一些信息,证明该进程正在运行中<br />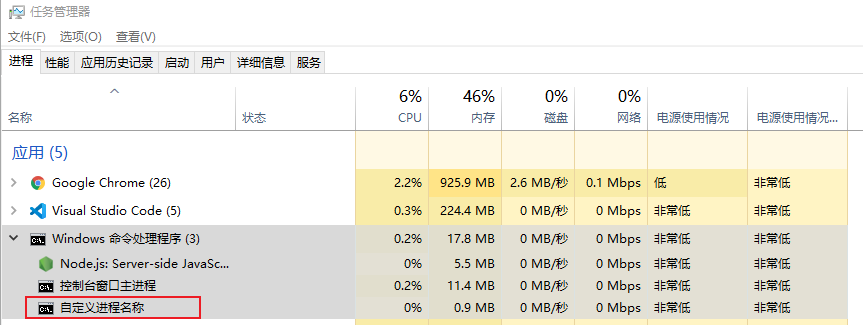<br />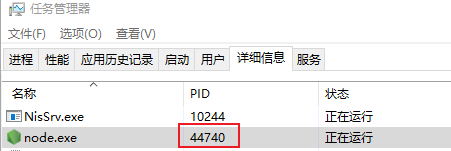
(2)线程
线程是操作系统能够进行运算调度的最小单位,首先我们要清楚线程是隶属于进程的,被包含于进程之中。一个线程只能隶属于一个进程,但是一个进程是可以拥有多个线程的。
同一块代码,可以根据系统CPU核心数启动多个进程,每个进程都有属于自己的独立运行空间,进程之间是不相互影响的。同一进程中的多条线程将共享该进程中的全部系统资源,如虚拟地址空间,文件描述符和信号处理等。但同一进程中的多个线程有各自的调用栈(call stack),自己的寄存器环境(register context),自己的线程本地存储(thread-local storage),线程又有单线程和多线程之分,具有代表性的 JavaScript、Java 语言。
a、单线程
单线程就是一个进程只开一个线程,想象一下一个痴情的少年,对一个妹子一心一意用情专一。
Javascript 就是属于单线程,程序顺序执行,可以想象一下队列,前面一个执行完之后,后面才可以执行,当你在使用单线程语言编码时切勿有过多耗时的同步操作,否则线程会造成阻塞,导致后续响应无法处理。你如果采用 Javascript 进行编码,尽可能的使用异步操作。
下面是一个同步阻塞的例子:
// compute.js
const http = require('http');
const [url, port] = ['127.0.0.1', 3000];
const computation = () => {
let sum = 0;
console.info('计算开始');
console.time('计算耗时');
for (let i = 0; i < 1e10; i++) {
sum += i
};
console.info('计算结束');
console.timeEnd('计算耗时');
return sum;
};
const server = http.createServer((req, res) => {
if(req.url == '/compute'){
const sum = computation();
res.end(`Sum is ${sum}`);
}
res.end(`ok`);
});
server.listen(port, url, () => {
console.log(`server started at http://${url}:${port}`);
});
浏览器执行 http://127.0.0.1:3000/compute ,大约每次需要 11496.275ms,也就意味下次用户请求需要等待 11496.275ms:<br />
b、多线程
多线程就是没有一个进程只开一个线程的限制,好比一个风流少年除了爱慕自己班的某个妹子,还在想着隔壁班的漂亮妹子。Java 就是多线程编程语言的一种,可以有效避免代码阻塞导致的后续请求无法处理。
对于多线程的说明 Java 是一个很好的例子,看以下代码示例
public class TestApplication {
Integer count = 0;
@GetMapping("/test")
public Integer Test() {
count += 1;
return count;
}
public static void main(String[] args) {
SpringApplication.run(TestApplication.class, args);
}
}
运行结果,每次执行都会修改count值,所以,多线程中任何一个变量都可以被任何一个线程所修改。<br />我现在对上述代码做下修改将 count 定义在 test 方法里
public class TestApplication {
@GetMapping("/test")
public Integer Test() {
Integer count = 0; // 改变定义位置
count += 1;
return count;
}
public static void main(String[] args) {
SpringApplication.run(TestApplication.class, args);
}
}
运行结果每次都是 1,因为每个线程都拥有了自己的执行栈
c、nodejs是单线程吗?
Node 严格意义讲并非只有一个线程,通常说的 “Node 是单线程” 其实是指 JS 的执行主线程只有一个。
我们以一个简单的例子来看一下:
require('http').createServer((req, res) => {
res.writeHead(200);
res.end('Hello World');
}).listen(8000);
console.log('process id', process.pid);
终端打印结果如下:<br /><br />这样我们根据pid可以在任务管理器(windows)找到对应的进程和线程数<br /><br />上图可以证实node进程中的线程并不是只有一个,事实上一个node进程通常包含以下线程:
- 1 个 Javascript 执行主线程
- 1 个 watchdog 监控线程用于处理调试信息
- 1 个 v8 task scheduler 线程用于调度任务优先级,加速延迟敏感任务执行
- 4 个 v8 线程,主要用来执行代码调优与 GC 等后台任务
- 用于异步 I/O 的 libuv 线程池
如果执行程序中不包含 I/O 操作如文件读写等,则默认线程池大小为 0,否则 Node 会初始化大小为 4 的异步 I/O 线程池,当然我们也可以通过process.env.UV_THREADPOOL_SIZE 自己设定线程池大小,需要注意的是在 Node 中网络 I/O 并不占用线程池。
下图为node的进程结构图:
既然 JS 执行线程只有一个,那么 Node 为什么还能支持较高的并发(异步调用函数)?
1、从上文异步 I/O 我们也能获得一些思路,Node 进程中通过 libuv 实现了一个事件循环机制(uv_event_loop),当执行主线程发生阻塞事件,如 I/O 操作时,主线程会将耗时的操作放入事件队列中,然后继续执行后续程序。
2、uv_event_loop 尝试从 libuv 的线程池(uv_thread_pool)中取出一个空闲线程去执行队列中的操作,执行完毕获得结果后,通知主线程,主线程执行相关回调,并且将线程实例归还给线程池。通过此模式循环往复,来保证非阻塞 I/O,以及主线程的高效执行。
相关流程可参照下图:
d、线程池
1、线程池是预先创建好的吗?
线程池中的线程是按需创建的,在上面的例子中加入文件读取的代码段:
const http = require('http');
const fs = require('fs');
http.createServer((req, res) => {
fs.readFile('./compute.js', err => {
if (err) {
console.log(err);
process.exit();
} else {
console.log(Date.now(), 'Read File I/O');
}
});
res.writeHead(200);
res.end('Hello World');
}).listen(8000);
console.log('process id', process.pid);
在没进行访问前,node的线程数为8,一旦访问8000端口,线程数就会变为12,如下图所示,这说明了大小为4的线程池被创建<br /><br /><br />
2、异步I/O都要占用线程池吗?
并不是,网络IO不会占用线程池。无论多少次访问都不会创建线程,代码如下:
const http = require('http');
http.createServer((req, res) => {
http.get('https://www.baidu.com/');
res.end('hello');
}).listen(8000, () => {
console.log('server is listening: ' + 8000);
});
console.log('process id', process.pid);
3、文件I/O一定会占用线程池吗?
并不是,*Sync会阻塞主线程所以不会占用线程池,另外fs.FSWatcher也不会占用线程池。
4、线程池只能用于异步IO?
并不是,除了一些IO密集操作外,Node.js对一些CPU密集的操作也会放到线程池里面执行(Crypto、Zlib模块)
3、process的相关API
Node.js 中的进程 Process 是一个全局对象,无需 require 直接使用,给我们提供了当前进程中的相关信息,官方文档提供了详细的说明,下面罗列一些常用的变量、方法和事件。
- process.env:环境变量,例如通过 process.env.NODE_ENV 获取不同环境项目配置信息
- process.nextTick:这个在系列(2)中详细介绍过,有兴趣的小伙伴可以回去看一下,这主要是运用在事件循环中
- process.pid:获取当前进程id
- process.ppid:当前进程对应的父进程
- process.cwd():获取当前进程工作目录
- process.platform:获取当前进程运行的操作系统平台
- process.title:指定进程名称,有的时候需要给进程指定一个名称
(1)process事件
a、beforeExit
当 Node.js 清空其事件循环并且没有额外的工作要安排时,则会触发 'beforeExit' 事件。 通常情况下,Node.js 进程会在没有工作调度时退出,但是注册在 'beforeExit' 事件上的监听器可以进行异步调用,从而导致 Node.js 进程继续。
对于导致显式终止的条件,例如调用 process.exit() 或未捕获的异常,则不会触发 'beforeExit' 事件
process.on('beforeExit', (code) => {
console.log('Process beforeExit event with code: ', code);
});
process.on('exit', (code) => {
console.log('Process exit event with code: ', code);
});
console.log('This message is displayed first.');
// 打印:
// This message is displayed first.
// Process beforeExit event with code: 0
// Process exit event with code: 0
b、disconnect
如果 Node.js 进程是通过 IPC 通道衍生的(参考子进程和集群文档),则在 IPC 通道关闭时将触发 'disconnect' 事件。
c、exit
当 Node.js 进程由于以下任一原因即将退出时,则会触发 'exit' 事件:
- process.exit() 方法被显式调用;
- Node.js 事件循环不再需要执行任何额外的工作。
此时没有办法阻止事件循环的退出,一旦所有 'exit' 监听器都运行完毕,则 Node.js 进程将终止
监听器函数必须只执行同步操作。 Node.js 进程将在调用 'exit' 事件监听器后立即退出,从而导致任何仍在事件循环中排队的额外工作被放弃。 例如,在以下示例中,永远不会发生超时:
process.on('exit', (code) => {
setTimeout(() => {
console.log('This will not run');
}, 0);
});
d、mesage
如果 Node.js 进程是通过 IPC 通道衍生的(参考子进程和集群文档),则每当子进程收到父进程使用 childprocess.send() 发送的消息时,就会触发 'message' 事件
e、异常事件监听
nodejs使用rejectionHandled、uncaughtException、uncaughtExceptionMonitor、unhandledRejection、warning等事件来监听异常情况,有兴趣的小伙伴可以根据官网例子尝试一下
三、nodejs之child_process模块
1、为什么使用多进程
上面说到,通过事件循环机制,Node 实现了在 I/O 密集型(I/O-Sensitive)场景下的高并发,但是如果代码中遇到 CPU 密集场景(CPU-Sensitive)的场景,那么主线程将长时间阻塞,无法处理额外的请求。为了应对 CPU-Sensitive 场景,以及充分发挥 CPU 多核性能,Node 提供了 child_process 模块进行子进程的创建、通信、销毁等等。
父进程与子进程之间是一种 master/worker 的工作模式。通常会阻塞的操作分发给 worker 来执行(查 db,读文件,进程耗时的计算等等),master 上尽量编写非阻塞的代码。
2、CPU密集型和IO密集型
(1)CPU密集型(CPU-bound)
CPU密集型也叫计算密集型,指的是系统的硬盘、内存性能相对CPU要好很多,此时,系统运作大部分的状况是CPU Loading 100%,CPU要读/写I/O(硬盘/内存),I/O在很短的时间就可以完成,而CPU还有许多运算要处理,CPU Loading很高。
在多重程序系统中,大部份时间用来做计算、逻辑判断等CPU动作的程序称之CPU bound。例如一个计算圆周率至小数点一千位以下的程序,在执行的过程当中绝大部份时间用在三角函数和开根号的计算,便是属于CPU bound的程序。
CPU bound的程序一般而言CPU占用率相当高。这可能是因为任务本身不太需要访问I/O设备,也可能是因为程序是多线程实现因此屏蔽掉了等待I/O的时间。
(2)IO密集型(I/O bound)
IO密集型指的是系统的CPU性能相对硬盘、内存要好很多,此时,系统运作,大部分的状况是CPU在等I/O (硬盘/内存) 的读/写操作,此时CPU Loading并不高。
I/O bound的程序一般在达到性能极限时,CPU占用率仍然较低。这可能是因为任务本身需要大量I/O操作,而pipeline做得不是很好,没有充分利用处理器能力。
(3)CPU密集型 vs IO密集型
我们可以把任务分为计算密集型(CPU密集型)和IO密集型。
- 计算密集型
计算密集型任务的特点是要进行大量的计算,消耗CPU资源,比如计算圆周率、对视频进行高清解码等等,全靠CPU的运算能力。这种计算密集型任务虽然也可以用多任务完成,但是任务越多,花在任务切换的时间就越多,CPU执行任务的效率就越低,所以,要最高效地利用CPU,计算密集型任务同时进行的数量应当等于CPU的核心数。
计算密集型任务由于主要消耗CPU资源,因此,代码运行效率至关重要。Python这样的脚本语言运行效率很低,完全不适合计算密集型任务。对于计算密集型任务,最好用C语言编写。
- IO密集型
涉及到网络、磁盘IO的任务都是IO密集型任务,这类任务的特点是CPU消耗很少,任务的大部分时间都在等待IO操作完成(因为IO的速度远远低于CPU和内存的速度)。对于IO密集型任务,任务越多,CPU效率越高,但也有一个限度。常见的大部分任务都是IO密集型任务,比如Web应用。
IO密集型任务执行期间,99%的时间都花在IO上,花在CPU上的时间很少,因此,用运行速度极快的C语言替换用Python这样运行速度极低的脚本语言,完全无法提升运行效率。对于IO密集型任务,最合适的语言就是开发效率最高(代码量最少)的语言,脚本语言是首选,C语言最差。
3、child_process的相关API
child_process提供了4个方法,用于新建子进程,这4个方法分别为spawn、execFile、exec和fork。所有的方法都是异步的,可以用一张图来描述这4个方法的区别。
- spawn : 子进程中执行的是非node程序,提供一组参数后,执行的结果以流的形式返回。
- execFile:子进程中执行的是非node程序,提供一组参数后,执行的结果以回调的形式返回。
- exec:子进程执行的是非node程序,传入一串shell命令,执行后结果以回调的形式返回,与execFile,不同的是exec可以直接执行一串shell命令。
- fork:子进程执行的是node程序,提供一组参数后,执行的结果以流的形式返回,与spawn不同,fork生成的子进程只能执行node应用。接下来的小节将具体的介绍这一些方法。
(1)execFile 和 exec
这两者的相同点为:执行的是非node应用,且执行后的结果以回调函数的形式返回;
不同点为:exec是直接执行的一段shell命令,而execFile是执行的一个应用;
举例来说,echo是UNIX系统的一个自带命令,我们直接可以在命令行执行:
echo hello world
结果,在命令行中会打印出hello world<br />通过exec来实现:
let cp=require('child_process');
cp.exec('echo hello world',function(err,stdout){
console.log(stdout);
});
执行这段代码,结果会输出hello world。我们发现exec的第一个参数,跟shell命令完全相似。<br />通过execFile来实现:
let cp=require('child_process');
cp.execFile('echo',['hello','world'],function(err,stdout){
console.log(stdout);
});
在windows上运行这段代码,却告诉我们出了错误:
Error: spawn echo ENOENT
at Process.ChildProcess._handle.onexit (internal/child_process.js:267:19)
at onErrorNT (internal/child_process.js:469:16)
at processTicksAndRejections (internal/process/task_queues.js:84:21) {
errno: 'ENOENT',
code: 'ENOENT',
syscall: 'spawn echo',
path: 'echo',
spawnargs: [ 'hello', 'world' ],
cmd: 'echo hello world'
}
这是因为在windows上执行时,execlFile和spawn都是脱离cmd.exe这一解释器去单独执行的,为此,我们可以根据操作系统设置shell:true以隐式调用cmd
const childProcess = require('child_process');
childProcess.execFile('echo', ['hello', 'world'], {
shell: process.platform === 'win32'
}, function(err,stdout){
console.log(stdout);
});
(2)spawn
spawn同样是用于执行非node应用,且不能直接执行shell,与execFile相比,spawn执行应用后的结果并不是执行完成后,一次性的输出的,而是以流的形式输出。
// index.js
const childProcess = require('child_process');
const newRead = childProcess.spawn('type', ['..\\txt\\spawn.txt'], {
shell: process.platform === 'win32',
});
newRead.stdout.on("data", (result) => {
const str = result.toString('utf-8');
console.log(str);
})
// txt/spawn.txt
// 文件内容为:acdgetadgh
通过控制台可以看到,输出内容正是txt文件的内容
(3)fork
在javascript中,在处理大量计算的任务方面,HTML里面通过web work来实现,使得任务脱离了主线程。在node中使用了一种内置于父进程和子进程之间的通信来处理该问题,降低了大数据运行的压力。node中提供了fork方法,通过fork方法在单独的进程中执行node程序,并且通过父子间的通信,子进程接受父进程的信息,并将执行后的结果返回给父进程。
使用fork方法,可以在父进程和子进程之间开放一个IPC通道,使得不同的node进程间可以进行消息通信。
在子进程中:通过process.on('message')和process.send()的机制来接收和发送消息。
在父进程中:通过child.on('message')和child.send()的机制来接收和发送消息
// father.js
const { fork } = require('child_process');
const child = fork('./fib.js'); // 创建子进程
child.send({ num: 44 }); // 将任务执行数据通过信道发送给子进程
child.on('message', message => {
console.log('receive from child process, calculate result: ', message.data);
child.kill();
});
child.on('exit', () => {
console.log('child process exit');
});
setInterval(() => { // 主进程继续执行
console.log('continue excute javascript code', new Date().getSeconds());
}, 1000);
// fib.js
function fib(num) {
if (num === 0) return 0;
if (num === 1) return 1;
return fib(num - 2) + fib(num - 1);
}
process.on('message', msg => { // 获取主进程传递的计算数据
console.log('child pid', process.pid);
const { num } = msg;
const data = fib(num);
process.send({ data }); // 将计算结果发送主进程
});
最后的输出结果是:
child pid 39974
continue excute javascript code 41
continue excute javascript code 42
continue excute javascript code 43
continue excute javascript code 44
receive from child process, calculate result: 1134903170
child process exit
(4)同步执行的子进程
exec、execFile、spawn和fork执行的子进程都是默认异步的,子进程的运行不会阻塞主进程。除此之外,child_process模块同样也提供了execFileSync、spawnSync和execSync来实现同步的方式执行子进程。
(5)单进程 vs 多进程
下面我们通过两次计算斐波那契数列某一项的数值来验算:
- 单进程
function fib(num) {
if (num === 0 || num === 1) return num;
return fib(num - 2) + fib(num - 1);
}
const startTime = Date.now();
const calcNumArr = [41, 42, 43, 44, 45, 46];
const totalcount = calcNumArr.length;
let completedCount = 0;
for (let i = 0; i < totalcount; i++) {
const result = fib(calcNumArr[i]);
completedCount++;
console.log(`process: ${completedCount}/${totalcount}, result is:${result}`);
}
console.log(`访问完成:用时:${Date.now() - startTime}ms`);
最后终端输出结果如下:
process: 1/6, result is:165580141
process: 2/6, result is:267914296
process: 3/6, result is:433494437
process: 4/6, result is:701408733
process: 5/6, result is:1134903170
process: 6/6, result is:1836311903
访问完成:用时:60215ms
- 多进程
//father.js
const { fork } = require('child_process');
const numCPUs = require("os").cpus().length;
console.log('cpu为' + numCPUs + '核');
const startTime = Date.now();
const fibNumArr = [41, 42, 43, 44, 45, 46];
const totalTask = fibNumArr.length;
let completedTask = 0;
for(let i = 0; i < totalTask; i++) {
const child = fork('./child.js');
child.send({ num: fibNumArr[i] });
child.on('message', message => {
completedTask++;
child.kill();
console.log('receive from child process, calculate result: ' + message + '\n' + 'process: ' + completedTask + '/' + totalTask);
if(completedTask >= totalTask) {
console.log('访问完成,用时:' + (Date.now() - startTime) + 'ms')
}
})
}
//child.js
function fib(num) {
if (num === 0 || num === 1) return num;
return fib(num - 2) + fib(num - 1);
}
process.on('message', message => {
const { num } = message;
const result = fib(num);
process.send(result);
})
最后终端输出结果如下:
cpu为6核
receive from child process, calculate result: 165580141
process: 1/6
receive from child process, calculate result: 267914296
process: 2/6
receive from child process, calculate result: 433494437
process: 3/6
receive from child process, calculate result: 701408733
process: 4/6
receive from child process, calculate result: 1134903170
process: 5/6
receive from child process, calculate result: 1836311903
process: 6/6
访问完成,用时:24861ms
通过上面的比较可以看到多进程情况下,cpu完成计算的速度要快得多。
END
欢迎大家踊跃投稿,提出建议帮助前端周刊做得更好。 投稿方式:直接分享文章的链接给周刊组成员 邮箱:spyro426@163.com;
关于我们:我们是晓教育集团大教学前端团队,是一个年轻的团队。我们支持了集团几乎所有的教学业务。现伴随着事业群的高速发展,团队也在迅速扩张,欢迎各位前端高手加入我们~ 我们希望你是:技术上基础扎实、某领域深入;学习上善于沉淀、持续学习;性格上乐观开朗、活泼外向。 如有兴趣加入我们,欢迎发送简历至邮箱:
