

- 原文地址:Top 5 Embedded Databases for JavaScript Applications
- 原文作者:Fernando Doglio
- 译文出自:掘金翻译计划
- 本文永久链接:github.com/xitu/gold-m…
- 译者:没事儿
- 校对者:finalwhy PassionPenguin
用于 JavaScript 应用的前 5 大嵌入式数据库

我们习惯于将数据库视为一个大型的存储平台,我们把我们需要的所有数据都丢进去,然后再通过使用一些查询语言检索它们。扩展这些数据库,保持信息的一致性以及容错性本身就是一个挑战。那么,当我们数据需求量非常少的时候会发生什么?
当 RedShift、BigQuery 甚至 MySQL 用于我们微量的数据存储需求又显得太重时应该怎么办?其实还有一类合适的应用。事实上,选项有很多,因此本文我将介绍适用于小型数据存储需求的前 5 个嵌入式数据库。
那么究竟什么是嵌入式数据库呢?
当读到『嵌入式』这个词时,90% 的人都会联想到我在谈论 IOT 或者移动设备,但并不是的。
至少这不是唯一的情况。诚然,这些系统的资源非常受限,使得大部分传统的数据库系统难以在其上配置和安装。
但还有另一些小型数据库的用例,即将它们作为软件产品的一部分嵌入其中。例如,想象一下通过 IDE 在大型代码存储库中进行搜索的场景。IDE 可以嵌入一个倒排索引数据库,该数据库允许你按关键字搜索,然后得到相关文件的快捷引用。或者在你最喜欢的邮件桌面客户端进行搜索时,该客户端很可能也有一个嵌入式数据库。所有的邮件都被存储且编入了索引,这样你可以简单快速地得到你想要的信息。
另一个使用嵌入式数据库的巨大好处是它并不需要网络通信来交互,相比于其它各类标准的数据库,这是一个巨大的性能提升。通常在一般的开发中,你可能会将你的数据库放在你自己的服务器(或者服务器集群)上,这样它的资源消耗就不会影响到你架构中的其他组件,而对嵌入式数据库,你可能希望它们能尽可能地靠近客户端。这可以减少它们之间的通信延迟以及避免了对通信渠道的依赖(即网络)。
现在嵌入式数据库有多种形式。从使用 JSON 文件作为主要存储的快速内存数据库,到可以使用类似 SQL 语言查询的高效的小型关系型数据库,
让我们先看看这五个选择。
LowDB
让我们从简单的开始,LowDB 是一个小型内存数据库,是非常基础的解决方案,但能解决非常简单的用例:在一个基于 JavaScript 的项目中对于存储以及使用类似 JSON 结构(即文档)的需要。
LowDB 主要好处之一是它旨在 JavaScript 中使用,这意味着它可以用在后端、桌面端或者其它可以跑浏览器代码的地方。
你可以用在 Node.js 中使用 LowDB,也可以集成到 Electron 项目中去开发桌面客户端,当然它也能直接在已集成 JS 运行环境的浏览器中运行.
LowDB 提供的 API 也非常简单和轻量,并且没有提供任何开箱即用的搜索功能。它仅限于将 JSON 文件的数据加载到一个数组变量中,然后让你自己(用户)去找你想要的数据。
看看下面这个实例:
import { LowSync, JSONFileSync } from 'lowdb'
const title = "This is a test"
const adapter = new JSONFileSync('file.json')
const db = new LowSync(adapter)
db.read() //将 JSON 文件内容读取到内存中
db.data ||= { posts: [] } //默认值
db.data.posts.push({ title }) // 数据添加
db.write() // 将数据保存到 JSON 文件中
// 任何类似查找的操作都靠用户自己发挥
let record = db.data.posts.find( p => p.title == "Hello world")
if(!record) {
console.log("No data found!")
} else {
console.log("== Record found ==")
console.log(record)
}
如你如见,有趣的并不是默认行为而是我在使用一个叫做 JSONFileSync 的接口。我可以轻松创建一个实例然后去使用,这才是这个数据库真正的强点,
LowDB 具有高度的扩展性并且兼容 TypeScript,后者为了数据存储提供了一种类似模式的行为(即不允许你添加不符合预设模式的数据)。
如果你混合这两种选项,LowDB 提供了一些有趣的基于 Promise 的 API 用于操作本地的类 JSON 数据。
LevelDB
LevelDB 是由 Google 创建的一个键值对的开源数据库。它是一种超快但非常有限的键值存储方案,其中的数据按键排序存储,开箱即用。
它只有三种基础的操作: Put,Get 以及 Delete —— 非常轻量的 API,这与 LowDB 很相似。
与 LowDB 更像的是,LevelDB 被封装成没有客户端-服务端,这表示任何语言都无法与它通信。要使用它必须使用 C/C++ 的库,如果你想要类似服务端那样的操作行为,需要你自己去封装它。
就如本文中介绍的大多数情况一样,LevelDB 功能非常基础,因为它只覆盖一个非常简单但实用的需求:靠近代码的数据存储,以及快速访问。
数据库的存储架构是围绕于 Log-structured Merge Tree(LSM),这表示最优的使用方法是用于大型连续性而非小型随机的书写操作。
LevelDB 主要的一个限制是,一旦启动,它就会获得一个系统级的锁,这意味着同一时间只能有一个进程可以与其交互。当然,你可以在一个进程内部使用多线程来并行化某些操作。但也仅限于此。
有趣的是,LevelDB 被 Chrome 的 IndexedDB 作为后端数据库使用,显然 Minecraft Bedrock 版使用它作为某些块和实体数据存储(尽管它们使用的是 Google 实现的轻微修改后的版本)。
Raima Database Manager
我有提到过物联网(IoT)不是吗?Raima 是最快的数据库管理器之一,并且对于在系统资源受限的 IoT 设备上运行做了特别优化。
我说的资源受限的环境指的是什么?Raima 运行只需要 RAM 350kb,这样我可以最简化资源使用。
这个方案有别于前面几个方案的最主要特点是,它完全支持 SQL。它提供关系型数据模型并且允许使用 SQL 语言查询。
与 LevelDB 不同,它允许通过客户端-服务端的架构多进程访问数据库(即相比其他的数据库,它允许你的数据库离源代码稍微更远一点)。如果你决定做一个贴近源代码的嵌入式应用,你也可以使用多线程并发访问多个数据库。
Raima 的灵活性使你可以从传统的客户端-服务端模式转到最有效的(当然也是受限的)单个客户端使用单个内存数据库的用例。但这不正是嵌入式数据库的一个非常有效的用例吗?。
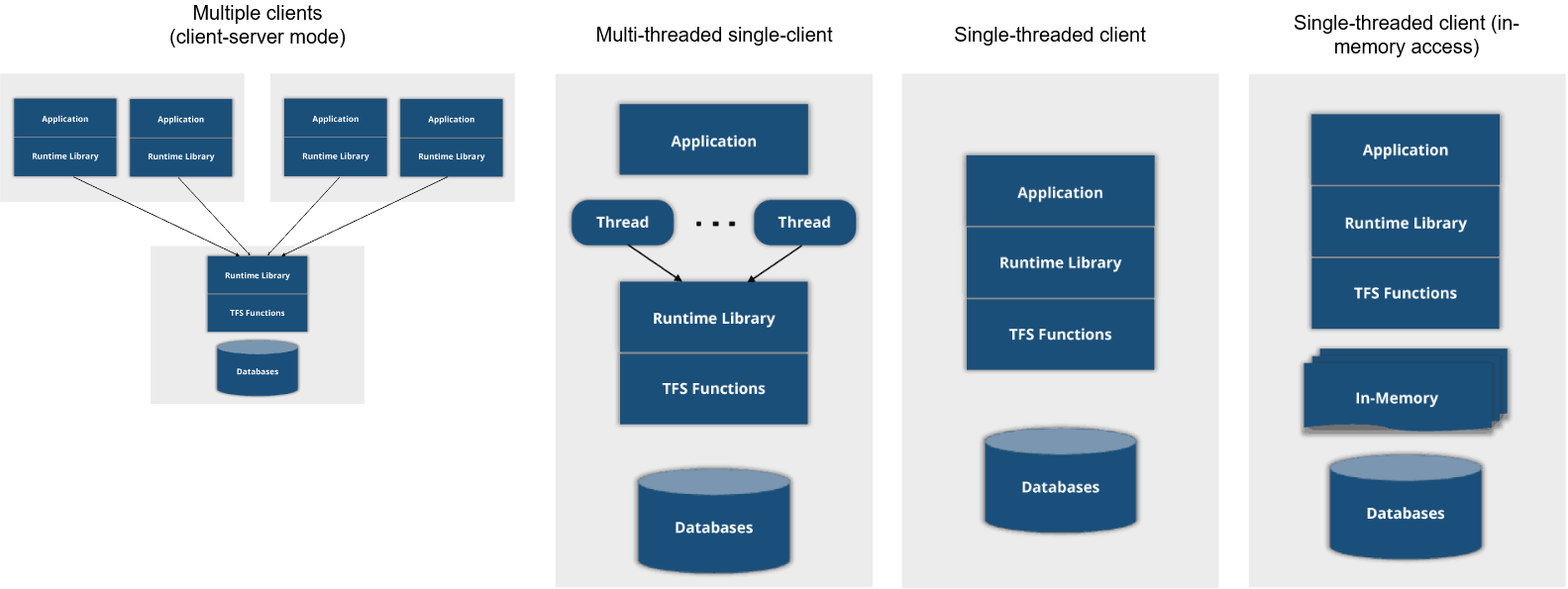
它的灵活性使它成为一个非常通用的解决方案。当然,每一种部署模式都有自己的好处和限制,但也会有最适合的特殊用例。所以请确保你选择了最适合自己的,然后将其发挥出最大的价值。
Apache Derby
如果你在寻找另一个小型的,类似 SQL 的数据库,Apache Derby 很可能就是你想要的。
Derby 完全是用 JAVA 写的,它声称只占用 3.5MB 内存,这可能有点不太贴合实际。毕竟,不在主系统安装 JVM,你无法运行或使用它。
但是,如果你的使用案例里有 JVM,那很棒,你可以继续考虑使用 Derby,不然你可能需要更原生的解决方案比如 LevelDb 或者 Raima。
但像我说的,如果你已经在做一个 JAVA 项目,且需要集成一个小型可靠且基于 SQL 的数据库,那 Derby 绝对是一个潜在的候选选项。
它集成了 JDBC 驱动器,所以不需要额外的依赖。它既能以嵌入式的模式在你的 JAVA 应用中工作,也可以作为一个独立的服务器与多个应用同时互动(与 Raima 做的类似,但是没有那么多的变量),
老实说,这个项目最大的缺点是它的文档。这可能是 JAVA 社区的一个标准,但对用户并不友好,而且大部分官方链接都指向一个私有的合并页面。其他的解决方案,大部分的都有流畅的文档体验,这有助于用户适应产品。
solidDB
最后一个,但绝对相当重要的一个,solidDB 覆盖一个非常有趣的案例,在提供一个内存关系型数据库的同时也可以提升模型的持续性。口气不小,它声称自己可以保持两种数据存储选项的实时同步。
本质上和前面几个一样,solidDB 能通过 ODBC 或 JDBC 使用,使 JAVA 或者 C 的应用可以通过 SQL 与之交互。
和前面几个一样,可以通过几种方式部署:
- 高度可用模式。这涉及到拥有重复数据的多个服务器。当然,这个模式并不太符合我们考虑的用例。
- 共享内存访问。这个非常有趣,因为它并不只将数据存储在内存中(比如前面几个)还允许多个应用使用这个内存(共享内存部分)。当然,只有在相同节点内的应用才可以直接使用共享内存,但是,来自外部节点的基于 JDBC/ODBC 的也可以访问相同的数据。将共享内存转变为有外部访问权限的内存数据库。
多个大型公司,比如 Cisco,Alcatel,Nokia,或者 Siemens 都声称在关键任务操作时使用这个数据库,因为其快如闪电般的数据访问速度。
考虑到它的所有部署方案,广泛的文档以及高要求的客户列表,我认为它是本文中最可靠的,稳定以及快速的嵌入式数据库之一。
嵌入式数据库旨在处理非常特殊的使用场景,要么是通过提供最低延时的可靠快速的数据存储,要么是快速安全的数据访问。这里列出的解决方案通过不同的方法来实现这些目标,哪一个适合你这取决于你和你的环境。
你曾经有尝试过这些解决方案中的任何一个吗?你的项目中曾有过嵌入式数据库的需要吗?你选的是哪一个呢?
如果发现译文存在错误或其它需要改进的地方,欢迎到 掘金翻译计划 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 本文永久链接 即为本文在 GitHub 上的 MarkDown 链接。
掘金翻译计划 是一个翻译优质互联网技术文章的社区,文章来源为 掘金 上的英文分享文章。内容覆盖 Android、iOS、前端、后端、区块链、产品、设计、人工智能等领域,想要查看更多优质译文请持续关注 掘金翻译计划、官方微博、知乎专栏。
