Multimodal Learning with Incomplete Modalities by Knowledge
Distillation
论文链接
简介
模态的定义为从不同的领域采集或从不同的特征提取器中提取的异构特征集合。由于异构数据的迅猛增长,多模态学习近些年获得巨大的关注。
模态特征集描述了相同的主体并提供了主体的共享和补充信息。多模态学习通过整合不同模态的预测信息来提高学习模型的性能。不同的模态是从不同的域或特征提取器中提取出来的,因此模态彼此间的表示可能会有很大的差距。
这篇文章提出了一个新的多模态学习框架,用来整合多模态中的补充信息,这个方法基于知识蒸馏(Knowledge Distillation),可以使用包括不完整模态样本在内的所有样本。该方法的主要步骤如下:
- 首先对每个模态及其所有可用数据分别训练模型。
- 然后将训练出的这些模型当做教师来训练一个学生模型,这个学生模型就是多模态学习模型,它融合了来自多种模态的补充信息。
学生模型的训练中使用来自教师模型标注的软标签和实数独热标签(one-hot label)。这个方法的特点是即不舍弃不完整模态样本也不填充它们,而是使用这些样本训练教师模型并保证教师模型为专家。
研究方法
知识蒸馏简介
知识蒸馏用于将教师的“dark knowledge”传授给学生,为了实现知识传授,首先需要基于数据集训练教师。将训练出的教师模型定义为Te(ϕ),其中ϕ是教师模型的参数。然后基于训练数据集训练学生模型,其训练目的在于可以模仿教师的输出。
给定数据集 D={{X1,y1},{X2,y2},...,{XN,yN}},用于训练学生,教师首先应用于这些数据并标记这些数据和logits。假设总共有C个类型,可以得到标注集:zi=Te(Xi;ϕ),此处zi∈RC×1为被教师模型对样本Xi标记的logits。学生模型通过实数独热标签{y1,y2,...,yN}和logits{z1,z2,...,zN}进行训练。
假设学生模型为一个带参数θ深度神经网络f(θ),其输入为Xi输出为一个C×1 logit向量。然后,给logit向量添加一个softmax函数来输出Xi被分类为C类的概率。
PS:logits在深度学习中指神经网络的一层输出结果,该输出一般会再接一个softmax layer输出normalize后的概率,用于多分类,来自链接。
训练学生网络的损失函数为:
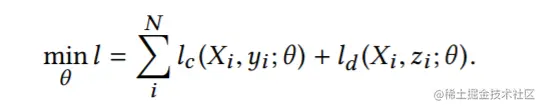
其中lc为分类损失:
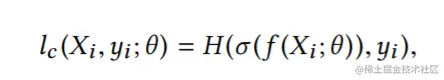
此处的H为负交叉熵损失(negative cross-entropy loss),且σ(x):RC→RC为softmax函数:
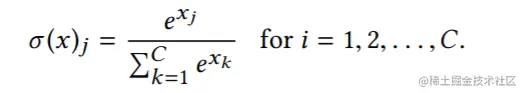
ld(Xi,zi;θ)为蒸馏损失,蒸馏损失的例子有负交叉熵损失和KL-divergence,这篇文章使用KL-divergence作为蒸馏损失:
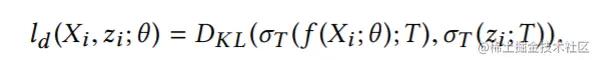
此处的σ(x;T)为带温度系数T的softmax函数(具体参考:深度学习中的temperature parameter是什么):
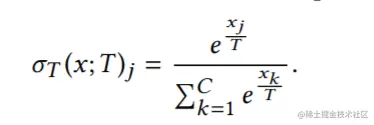
通过 T,输出概率被重新调整并平滑,T值越大概率值越平滑。σT(zi;T)称为软标签,它通过教师模型基于样本Xi标注,软标标签相比独热标签会包含更多的信息。
带缺失模态的多模态学习
首先用两个模态举例说明,然后拓展至多模态。
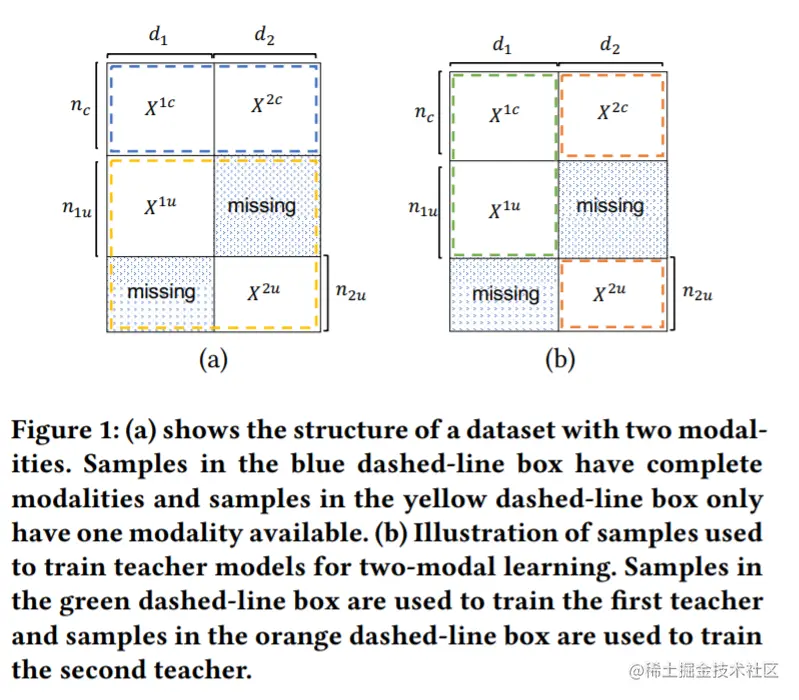
给定两个带标签的模态{X1∈Rn1×d1,X2∈Rn2×d2}:
- 假定拥有完整模态的样本为:{X1c∈Rnc×d1,X2c∈Rnc×d2,yc∈Rnc}。
- 假定仅拥有第一个模态的样本为:{X1u∈Rn1u×d1,y1u∈Rn1u}。
- 假定仅拥有第二个模态的样本为:{X2u∈Rn2u×d2,y2u∈Rn2u}。
此时,n1=nc+n1u,n2=nc+n2u。
如图1(a)所示,蓝色虚线框中的样本是具有完整模态的,而黄色虚线框中的样本只有一种模态。
为了利用所有的样本,首先使用包括缺失模态样本的所有可用数据来训练出两个单模态模型,这两个模型在本文设计的框架中为教师模型。假设两个教师为两个神经网络g1(ϕ1)和g2(ϕ2),其中ϕ1,ϕ2为输入的参数。g1(ϕ1)的将[X1c,X1u]中的样本作为输入,输出为logits,同理g2(ϕ2)。教师通过最小化下面的损失函数进行训练:
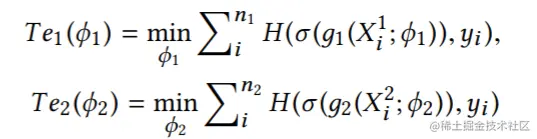
之后使用两个教师来标注{X1c和X2c}中的样本,样本i−th的logits为:
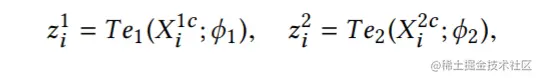 此处的zij为教师j对样本i−th标记的logit。
此处的zij为教师j对样本i−th标记的logit。
为了聚合不同模态的补充信息,通过多模态深度学习网络(multimodal DNN, M-DNN)训练出一个学生模型。两个模态的M-DNN包括两个分支,每个分支将一个模态作为输入,后面接着几个非线性全连接层。所有分支的输出被链接起来合成一个联合表示。然后这个联合表示和一个线性层连接并输出logit z。
定义学生网络为f(θ),其中θ为参数,其损失函数为:
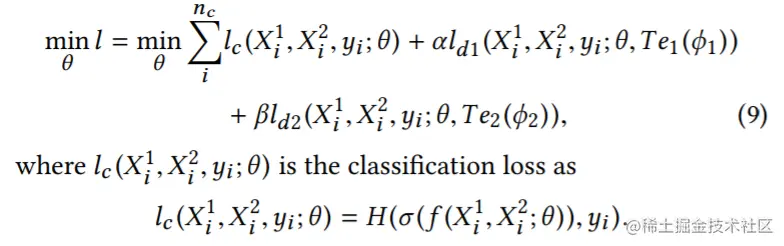
其中,ld1,ld2为蒸馏损失,α,β为控制学生模型从教师模型学习知识多少的两个可调参数,如果参数值很大,则表示学生模型需要更多的知识。
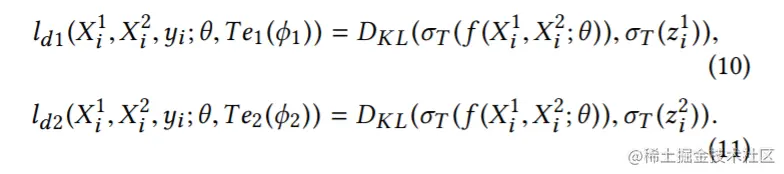
图2给出了整个框架的总览,这篇文章提出方法的伪码如算法1所示。

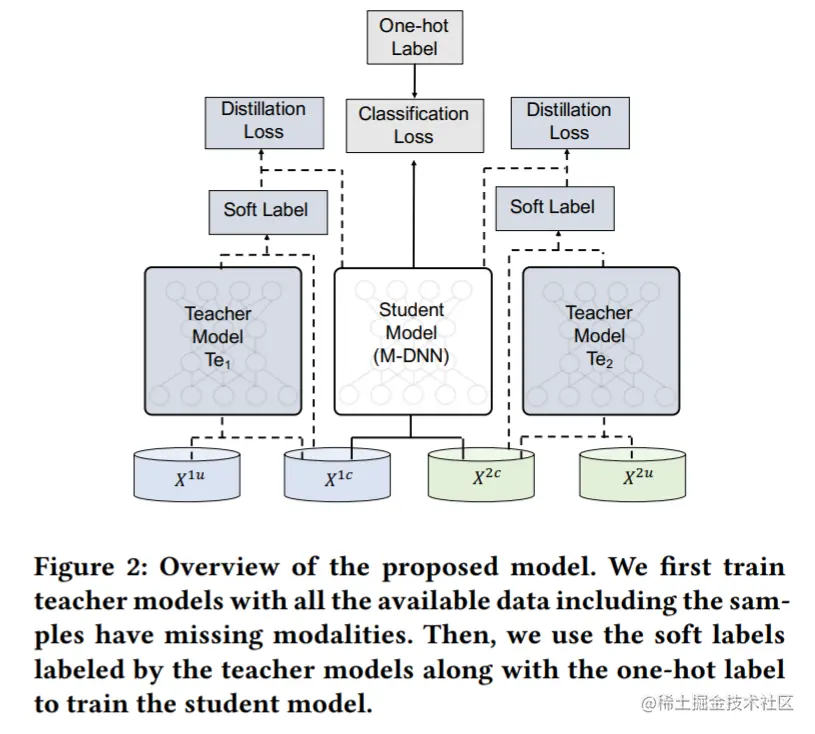
将两个模态的方法推广到多模态
给定m个模态,X1∈Rn1×d1,X2∈Rn2×d2,...,Xm∈Rnm×dm。这个数据集可以被分成n个部分:
- 带全模态的样本:Xic∈Rnc×di,i={1,2,...,m}。
- 带单模态的样本:Xiu∈Rnui×di,i={1,2,...,m}。
- 带两个模态的样本:Xku{ij}∈Rnu{ij}×dk,i,j = {1,2,...,n},k={i,j},Xku{ij}为包括第i个模态和第j个模态的样本的子集中的第k个模态。
- 带n-1个模态的样本:Xku{M∖i}∈Rn{M∖i}×dk,i={1,2,...,m}。
使用{M}表示所有m个模态的索引集,{M}={1,2,...,m},则{M∖i}表示没有索引i的集合,k是{M∖i}中的一个索引。Xku{M∖i}为包含{M∖i}模态的样本构成的子集中的第k个模态。
通过分层的方式训练教师模型们:
- 对每个模态分别训练教师模型,获得Tei,i={1,2,...,m}。
- 用这些教师模型来教授带两个模态的教师模型,得到教师模型Teij,i,j={1,2,...,m}。
- 使用所有的Teij来教授带三个模态的教师模型……以此类推,最后通过分层的方法得到所有的教师。
定义带h个模态训练的教师为h-level教师。{Ch}表示从集合M采样的h个索引的所有组合组成的集合。{Ch}的规模为(hm)。H-level教师模型根据{Ch}中的元素索引的模态式进行训练。将h-level教师中的第t个教师模型定义为 TeCht(ϕht),ϕht为网络参数,Cht为集合{Ch}的第t个元素。TeCht(ϕht)通过最小化下面的损失函数训练:
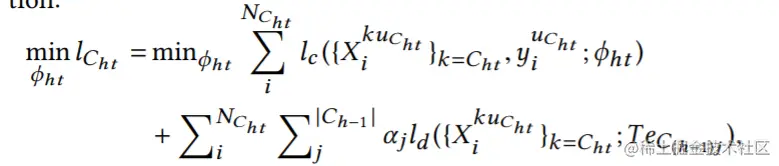
其中∣Ch−1∣为集合Ch−1的大小,NCht为以Cht为索引的模态的样本的大小。在得到所有教师后,通过它们可以训练处最后的学生模型。
一个隐含的问题在于在模态量很大时,可能需要大量的教师模型,对于m个模态,教师模型的数量最大为2m−1。因此训练所有教师模型需要很大的算力成本。未来解决这个问题,这篇文章提出通过修剪教师模型来提升框架的可伸缩性,只选取那些拥有高性能的教师们来训练第二级教师,并以同样的方式训练剩下几级的教师。


